前回の続きです。
今回は、k分割交差検証によるvalidationを行いました。
前回の記事はこちら。
the previous and today's result(前回と今回の結果)
| やったこと | score | |
|---|---|---|
| 前回 | ハイパーパラメータのチューニング | 0.13948 |
| 今回 | k分割交差検証によるvalidation | - |
今回は、精度改善は行っていません。
今回の変更点は以下の通り
| validation方法 | |
|---|---|
| これまで | ホールドアウト法で分割したtrainingデータとvalidationデータを用いてvalidation結果を算出 |
| 今回(今回以降) | validation結果を交差検証で算出できるようにした |
なので、スコアの変化はありません。
Why?
ホールドアウト法だと、どうしても検証に用いられるデータが偏ってしまうため、たまたま行われたデータ分割によって、損失が妙に改善したり全然改善しなかったり、、、ということが起こり得ます。実際起きてた(´;ω;`)
そこで、検証(validation)時におけるデータ分割の偏りを少しでも減らすために、k分割交差検証法を用いることにしました。
さて、実際にやったことを見ていきます。
1. source cord
1-1. same as the previous cord
この「1-0.」はこれまで同じことをしています(^ワ^*)
ただし、今後前処理などを追加しやすいように、関数化するなど少しリファクタリングしておきました。
内容としては以下の通り。
- モジュール読み込み
- データ読み込み
- 数値特徴量のカテゴリ変数化
- 特徴量の追加と削除
- 前処理
- One-hot encoding
- trainingデータとtestデータの用意
- ハイパーパラメータチューニング
#####################################################################
# 1. import modules
#####################################################################
from typing import Callable, Dict, List, Union
import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error
from sklearn.preprocessing import LabelEncoder
import xgboost as xgb
from xgboost import XGBRegressor, plot_importance
# 分析の下準備
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
#####################################################################
# 2. load data
#####################################################################
import os
for dirname, _, filenames in os.walk('/kaggle/input'):
for filename in filenames:
print(os.path.join(dirname, filename))
train = pd.read_csv('/kaggle/input/house-prices-advanced-regression-techniques/train.csv')
test = pd.read_csv('/kaggle/input/house-prices-advanced-regression-techniques/test.csv')
#####################################################################
# 3. cast columns
#####################################################################
train['MSSubClass'] = train['MSSubClass'].apply(str)
train['YrSold'] = train['YrSold'].astype(str)
train['MoSold'] = train['MoSold'].astype(str)
test['MSSubClass'] = test['MSSubClass'].apply(str)
test['YrSold'] = test['YrSold'].astype(str)
test['MoSold'] = test['MoSold'].astype(str)
#####################################################################
# 4. 特徴量の追加と削除
#####################################################################
# 4-1. add new column
train['totalRoomsSF'] = train['1stFlrSF'] + train['2ndFlrSF'] + train['TotalBsmtSF']
test['totalRoomsSF'] = test['1stFlrSF'] + test['2ndFlrSF'] + test['TotalBsmtSF']
# 4-2. drop ID column
train_ID = train['Id']
test_ID = test['Id']
train = train.drop(['Id'], axis=1)
test = test.drop(['Id'], axis=1)
#####################################################################
# 5. 前処理
#####################################################################
def one_hot_encoding(x: pd.DataFrame) -> pd.DataFrame:
"""
渡された DataFrame に One-Hot Encoding を行う
DataFrameからは目的変数を除外しておく
"""
encode_target_columns: List[str] = list(x.columns[x.dtypes == 'object'])
return pd.get_dummies(x, columns=encode_target_columns)
def preprocess_whole_data(
train: pd.DataFrame,
test: pd.DataFrame,
preprocessings: List[Callable[[pd.DataFrame], pd.DataFrame]],
) -> Dict[str, Union[pd.DataFrame, pd.Series]]:
"""
前処理をまとめて行う
"""
# trainとtestどちらかにしか存在しない値を考慮したencodingを行うために、いったん行方向に結合してget_dummiesにかける
train['for_train'] = True
test['for_train'] = False
df_all_data = pd.concat([train, test])
for preprocess in preprocessings:
df_all_data = preprocess(df_all_data)
preprocessed_train = df_all_data.loc[df_all_data['for_train'], :]
preprocessed_test = df_all_data.loc[~df_all_data['for_train'], :]
preprocessed_train_y = preprocessed_train['SalePrice']
preprocessed_train_x = preprocessed_train.drop(['for_train', 'SalePrice'], axis=1)
preprocessed_test = preprocessed_test.drop(['for_train', 'SalePrice'], axis=1)
return {
'train_x': preprocessed_train_x,
'train_y': preprocessed_train_y,
'test': preprocessed_test,
}
# NOTE: 実行する前処理関数をまとめておく
preprocessings: List[Callable[[pd.DataFrame], pd.DataFrame]] = [
one_hot_encoding,
]
result: Dict[str, Union[pd.DataFrame, pd.Series]] = preprocess_whole_data(
train, test, preprocessings
)
#####################################################################
# 6. trainingデータとtestデータの用意
#####################################################################
# NOTE: 前処理済みのデータ達
preprocessed_train_x = result['train_x']
preprocessed_train_y = result['train_y']
preprocessed_test = result['test']
#####################################################################
# 7. ハイパーパラメータのチューニング
#####################################################################
# NOTE: ハイパーパラメータチューニング用のデータ分割
x_train, x_test, y_train, y_test = \
train_test_split(preprocessed_train_x, preprocessed_train_y, test_size=0.20, random_state=0)
x_train.head()
# NOTE: ハイパーパラメータチューニングに必要なものたちを用意
import time
from sklearn.model_selection import KFold, cross_val_score
import optuna
seed = 42 # 乱数シード
model = XGBRegressor(n_estimators=20, random_state=0)
cv = KFold(n_splits=3, shuffle=True, random_state=seed)
scoring = 'neg_mean_squared_error'
# 学習時fitパラメータ指定
fit_params = {
'verbose': 0, # 学習中のコマンドライン出力
'early_stopping_rounds': 5, # 学習時、評価指標がこの回数連続で改善しなくなった時点でストップ
'eval_metric': 'rmse', # early_stopping_roundsの評価指標
'eval_set': [(x_test, y_test)], # early_stopping_roundsの評価指標算出用データ
}
start = time.time()
# ベイズ最適化時の評価指標算出メソッド
def bayes_objective(trial):
params = {
# 'n_estimators': trial.suggest_int('n_estimators', 10, 100),
'learning_rate': trial.suggest_float('learning_rate', 0.01, 0.3, log=True),
'min_child_weight': trial.suggest_int('min_child_weight', 2, 8),
'max_depth': trial.suggest_int('max_depth', 1, 4),
'colsample_bytree': trial.suggest_float('colsample_bytree', 0.2, 1.0),
'subsample': trial.suggest_float('subsample', 0.2, 1.0),
'reg_alpha': trial.suggest_float('reg_alpha', 0.001, 0.1, log=True),
'reg_lambda': trial.suggest_float('reg_lambda', 0.001, 0.1, log=True),
'gamma': trial.suggest_float('gamma', 0.0001, 0.1, log=True),
}
# モデルにパラメータ適用
model.set_params(**params)
# cross_val_scoreでクロスバリデーション
scores = cross_val_score(
model, x_train, y_train, cv=cv,
scoring=scoring, fit_params=fit_params,
n_jobs=-1
)
val = scores.mean()
return val
# ベイズ最適化を実行
study = optuna.create_study(
direction='maximize',
sampler=optuna.samplers.TPESampler(seed=seed)
)
study.optimize(bayes_objective, n_trials=200)
# 最適パラメータの表示と保持
best_params = study.best_trial.params
best_score = study.best_trial.value
print(f'最適パラメータ {best_params}\nスコア {best_score}')
print(f'所要時間{time.time() - start}秒')
結構ソースが書き変わりましたが、実行結果は前回までの結果と同じです。
1-2. Newly added lines
今回はここからk分割交差検証を行っていきます。
といっても、これだけです!
# NOTE: これからも使い回したいので、関数として定義しました
def cross_validation_with_xgb(x: pd.DataFrame, y: pd.Series, best_params: dict = None) -> pd.DataFrame:
"""
Args:
x (pd.DataFrame): explanatories
y (pd.Series): target
best_params (dict): best parameters gotten by tuning
Returns:
pd.DataFrame: the result of cross validation
"""
# NOTE: データをXGBoost用のデータフォーマットに変換しておく
dtrain = xgb.DMatrix(x, label=y)
params = {
'silent': 1,
'objective': 'reg:linear',
'eval_metric': 'rmse',
'random_state': 0,
}
if best_params is not None:
params.update(best_params)
df_result = xgb.cv(
params,
dtrain,
num_boost_round=100,
nfold=5,
early_stopping_rounds=10,
metrics={'rmse'},
verbose_eval=True,
)
return df_result
df_result: pd.DataFrame = cross_validation_with_xgb(
x=preprocessed_train_x,
y=preprocessed_train_y,
best_params=best_params,
)
print(df_result.tail())
# 出力
train-rmse-mean train-rmse-std test-rmse-mean test-rmse-std
68 10691.215820 396.209062 27220.047266 5123.965290
69 10599.747461 405.167838 27194.023047 5111.387485
70 10548.596875 390.021197 27175.182031 5097.015552
71 10472.419727 373.892243 27197.732422 5068.619820
72 10413.960547 387.915821 27165.434375 5075.691233
ということで、前回までの改善結果をk分割交差検証で検証したら、
| RMSE | |
|---|---|
| train | 10413.960547 |
| test | 27165.434375 |
という結果になりました。
さて、次回以降はこの交差検証で求めたRMSEを元にして改善していきます。
ホールドアウト法による検証よりもRMSEが安定してくれたら嬉しい(´^ω^`)
1-3. 学習曲線を確認
※ここは、正直言ってやる必要はないです。
個人的に、遊びたくてグラフ描画してみました。
こういう遊びが開発の時間を潤してくれてます(´^ω^`)ブフォ
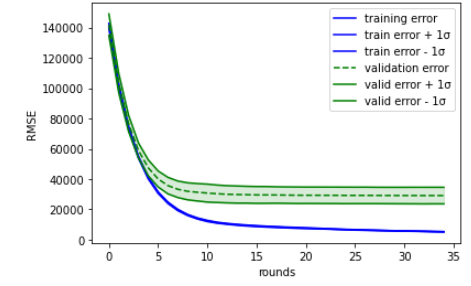
さて、k分割交差検証での学習曲線はこんな感じで描画しました。
def plot_xgb_cv_result(df_result: pd.DataFrame) -> None:
x = df_result.index
train_mean = df_result['train-rmse-mean']
train_std = df_result['train-rmse-std']
valid_mean = df_result['test-rmse-mean']
valid_std = df_result['test-rmse-std']
# plot training error
plt.plot(x, train_mean, color='blue', label='training error')
plt.fill_between(x, train_mean + train_std, train_mean - train_std, alpha=0.15, color='blue')
plt.plot(x, train_mean + train_std, color='blue', label='train error + 1σ')
plt.plot(x, train_mean - train_std, color='blue', label='train error - 1σ')
# plot validation error
plt.plot(x, valid_mean, color='green', linestyle='--', label='validation error')
plt.fill_between(x, valid_mean + valid_std, valid_mean - valid_std, alpha=0.15, color='green')
plt.plot(x, valid_mean + valid_std, color='green', label='valid error + 1σ')
plt.plot(x, valid_mean - valid_std, color='green', label='valid error - 1σ')
# specify label and legend
plt.xlabel('rounds')
plt.ylabel('RMSE')
plt.legend(loc='best')
# グラフを描画
plt.show()
plot_xgb_cv_result(df_result)
こんなのが表示された(((o(*゚▽゚*)o)))
2. Next step
今度こそ、目的変数を対数変換して学習させ、精度改善を試みた結果を記事にしていきます。(既に結果は出ている)
3. References
今回参考にした記事です。
cross validationのやり方について
matplotlib での mean + std の描画方法
平均(mean)と標準偏差(std)の考え方について
4. シリーズ一覧
| No | New Trial | Score | Link | Note |
|---|---|---|---|---|
| 1 | xgboost | 0.15663 | こちら | |
| 2 | Label Encoding | 0.15160 | こちら | |
| 3 | Add and delete column | 0.15140 | こちら | |
| 4 | Make integer into categorical | 0.14987 | こちら | |
| 5 | One hot Encoding | 0.14835 | こちら | |
| 6 | Hyper parameters tuning | 0.13948 | こちら | |
| 7 | k fold cross validation | - | 本記事 | submitせず |
| 8 | Logarithimic transformation | 0.13347 | 記事未作成 |