今回触るKaggleのコンテストはCosta Rican Household Poverty Level Predictionです。
どの世帯が社会福祉援助の必要性が最も高いのかを推論するのが目的のコンテストです。
playgroundとある通り、賞金などは出ないコンテストになります。
コンテストで試すこと(目的)
-
前回(#2)、色々あって結局submitの直前で止まってしまった(且つ、計算時間的にもう一回やるのがしんどい)ため、とりあえず今回はさくっとsubmitまでは対応します。
- ※Kaggle Kernelが必要なコンテストでの、submitまでの手順を知るのを目的とします。
- ※どうも、submit方法のUIの説明が古かったらしく、お問い合わせしたら丁寧に教えてくださいました。(なので、今回は大丈夫・・なはず)
- ※submitすることを目的とするため、一旦とても雑に対応します(データサイエンティストの方が見たら叱られそうなレベルで)。そのため、順位も恐らく最下位の方でしょう。
- LightGBMが良さそうと同僚の方に教えていただいたので、そちらを触ってみます。(本当に触ってみるだけで深掘りは今回しません)
- 一回submitまでいけたら、少しチューニングなどして、順位がどんな感じに遷移するのか試してみます。(時間が足りなければ、別の機会にする可能性も)
まずはデータの確認
- Kaggle Kernelを使っていきます。
- 前回初めて触ってみて、結構高いスペック・データセットの準備のしやすさなどを実感したのと、今回はカーネルの提出が必要なコンテストであるため、最初からKaggle Kernelで進めます。(ローカルのノートなどだと、再度提出時にKaggle Kernel上でコミットして計算し直さないといけないので手間です)
import os
import pandas as pd
import numpy as np
import lightgbm as lgb
import matplotlib.pyplot as plt
特にimport時にLightGBMも最初からインストールされている模様・・(とても楽ですね・・)
print(os.listdir("../input"))
['train.csv', 'sample_submission.csv', 'test.csv']
コンテスト参加ボタンを押して、そのまま新規カーネル追加ボタンを押すと、最初からinputディレクトリに必要なデータセットが配置されています。これもとても楽です。
train_df = pd.read_csv('../input/train.csv')
len(train_df)
9557
学習用のデータは約9500行。
train_df.head()
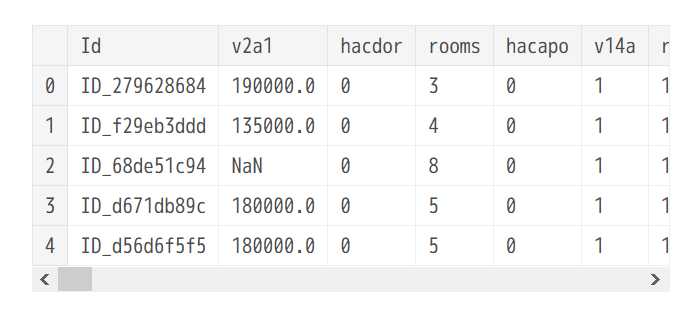
カラムはとても多い模様。
とても雑ですが、submitすることが目的なので、一旦欠損値のあるカラムを除外し、相関でソートしていくつかの特徴量だけに絞ってしまいます。
カラムが多いためか、info関数が省略された表示になってしまったので、さくっと欠損値があるカラムだけループで調べます。
for column_name in train_df.columns:
sliced_df = train_df.loc[:, [column_name]]
sliced_df = sliced_df[~sliced_df[column_name].isnull()]
if len(sliced_df) != len(train_df):
null_exists = True
else:
null_exists = False
if null_exists:
print('[%s]' % column_name)
print('nan value exists : %s / %s' % (len(sliced_df), len(train_df)))
print('-------')
[v2a1]
nan value exists : 2697 / 9557
-------
[v18q1]
nan value exists : 2215 / 9557
-------
[rez_esc]
nan value exists : 1629 / 9557
-------
[meaneduc]
nan value exists : 9552 / 9557
-------
[SQBmeaned]
nan value exists : 9552 / 9557
-------
delete_target_column_list = [
'v2a1', 'v18q1', 'rez_esc', 'meaneduc', 'SQBmeaned']
for delete_target_column in delete_target_column_list:
del train_df[delete_target_column]
長くても省略せずに表示したいため、Pandasの設定を調整します。(300行・列まで表示)
pd.set_option('display.max_rows', 300)
pd.set_option('display.max_columns', 300)
df_corr = train_df.corr()
df_corr.loc[['Target']].T.sort_values(
by='Target', ascending=False)
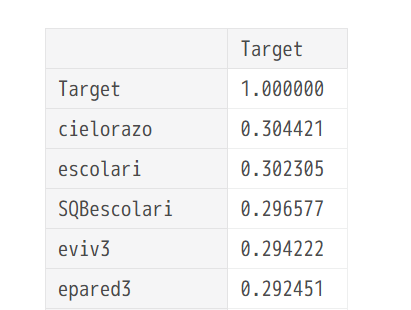
(とても)大雑把に確認したところ、正の相関も負の相関も、強い相関のものはないようです。
target_column_list = [
'cielorazo',
'escolari',
'SQBescolari',
'eviv3',
'epared3',
'pisomoscer',
'paredblolad',
'etecho3',
'SQBedjefe',
'v18q',
'Target',
]
train_df = train_df.loc[:, target_column_list]
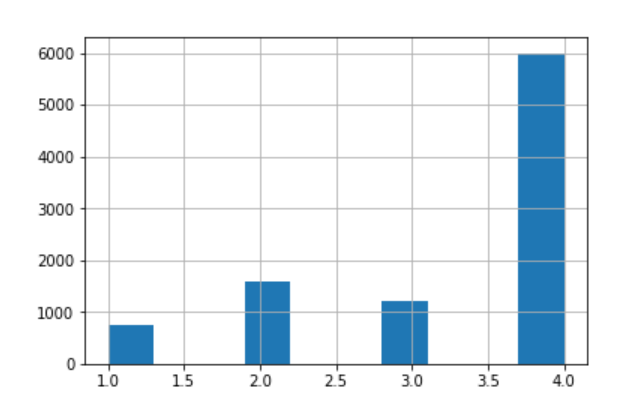
ついでに、学習データの答えのデータ(今回は1, 2, 3, 4の4つのクラス)の分布を確認しておきます。
_ = train_df.Target.hist(bins=10)
X = train_df.copy()
del X['Target']
X = X.values
X.shape
(9557, 10)
y = train_df.loc[:, ['Target']].values
y = y.reshape(y.shape[0])
y.shape
(9557,)
LGBMのクラス分類器を用意していきます。
scikit-learnに合わせたAPIも提供されているそうで、学習コストを抑えるためにそちらを利用します。(Prophet触ってみたときも思いましたが、とても楽です・・)
gbm = lgb.LGBMClassifier()
gbm.fit(X=X, y=y)
LGBMClassifier(boosting_type='gbdt', class_weight=None, colsample_bytree=1.0,
learning_rate=0.1, max_depth=-1, min_child_samples=20,
min_child_weight=0.001, min_split_gain=0.0, n_estimators=100,
n_jobs=-1, num_leaves=31, objective=None, random_state=None,
reg_alpha=0.0, reg_lambda=0.0, silent=True, subsample=1.0,
subsample_for_bin=200000, subsample_freq=0)
最後に、推論対象のデータ(test.csv)を読み込んで、推論して結果(submission.csv)を保存します。
test_df = pd.read_csv('../input/test.csv')
len(test_df)
23856
test_target_column_list = []
for target_column in target_column_list:
if target_column == 'Target':
continue
test_target_column_list.append(target_column)
X_test = test_df.loc[:, test_target_column_list].values
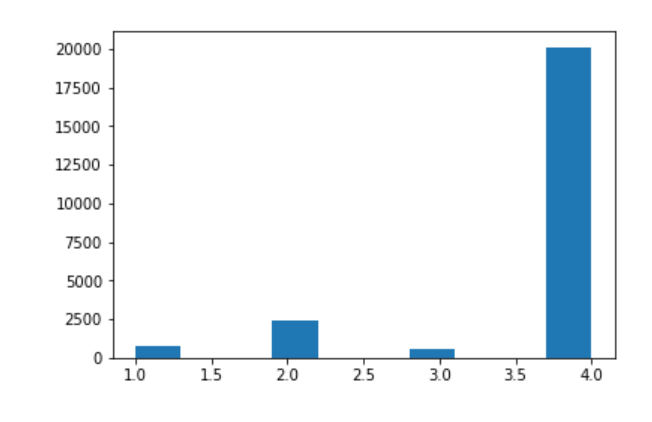
y_pred = gbm.predict(X=X_test)
_ = plt.hist(x=y_pred)
submission_df = test_df.loc[:, ['Id']]
submission_df['Target'] = y_pred
submission_df.to_csv('./submission.csv', encoding='utf-8', index=False)
これで保存の処理まで書けました。
コミットボタンを押して、計算が流れ終わるまで少し待ちます。
コンテストのカーネルのページに移動すると、submission.csvの表示が追加されているので、そちらの「Submit to Competition」をクリックします。
とりあえずこれで初submitは完了です!
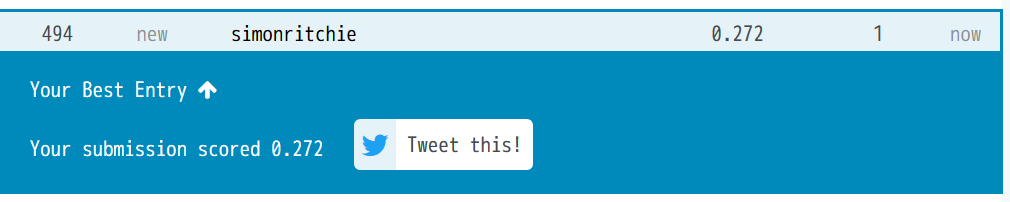
これだけ適当だと、最下位とまではいきませんでしたが、冒頭で予想した通りかなり下の方の順位になりました。(494/569)
とりあえず目標としていたsubmitとLightGBMを触るということはさくっと達成したので、色々いじって遊んでみます。(1日につき5回まで投稿できます。)
少し改善してみる
あまりに雑な対応だったため、精度が上がるのか少し色々試してみます。
※コンテスト締め切りが後数日しかない(次の土日になると期限が過ぎてしまう)ので、まだまだ仕事ではNGなくらいの雑な感じ(スピード重視)で進めます。(docstringなども省略し、コードは汚め)
import os
from datetime import datetime
import pandas as pd
import numpy as np
import lightgbm as lgb
import matplotlib.pyplot as plt
from sklearn.preprocessing import MinMaxScaler
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
import seaborn as sns
import numpy as np
import部分。若干scikit-learn周りなど追加してありますが、変わらずLightGBMをメインに使っていきます。
train_df = pd.read_csv('../input/train.csv')
test_df = pd.read_csv('../input/test.csv')
print('train data len :', len(train_df))
print('test data len :', len(test_df))
データ読み込み。
train_df.describe()
describe関数で確認してみると、訓練データでユニークな値が0の特徴量があったので、除外しておきます。
def drop_invalid_features(df):
for column_name in df.columns:
if str(df[column_name].dtype) == 'object':
continue
unique_arr = df[column_name].unique()
if len(unique_arr) == 1 and unique_arr[0] == 0:
del df[column_name]
print(column_name, 'dropped.')
return df
train_df = drop_invalid_features(df=train_df)
print('---')
test_df = drop_invalid_features(df=test_df)
elimbasu5 dropped.
---
elimbasu5という特徴量で、train.csv側で削除されましたが、test.csv側は少し値が入っているようです。ただ、合わせるためにそちらも削除しておきます。
del test_df['elimbasu5']
極端な値(異常値気味)のところは、中央値に置換しておきました。
def replace_outlier_by_median(df):
for column_name in df.columns:
column_sr = df.loc[:, column_name].copy()
if str(column_sr.dtype) == 'object':
continue
median_val = column_sr.median()
q1 = column_sr.describe()['25%']
q3 = column_sr.describe()['75%']
iqr = q3 - q1
outlier_min = q1 - (iqr) * 1.5
outlier_max = q3 + (iqr) * 1.5
column_sr[column_sr < outlier_min] = median_val
column_sr[column_sr > outlier_max] = median_val
df[column_name] = column_sr
return df
train_df = replace_outlier_by_median(df=train_df)
test_df = replace_outlier_by_median(df=test_df)
欠損値を補正します。
def print_na_exists_column(df):
for column_name in df.columns:
sliced_df = df.loc[:, [column_name]]
sliced_df = sliced_df[~sliced_df[column_name].isnull()]
if len(sliced_df) != len(df):
null_exists = True
else:
null_exists = False
if null_exists:
print('[%s]' % column_name)
print('nan value exists : %s / %s' % (len(sliced_df), len(df)))
print('-------')
print_na_exists_column(df=train_df)
[v2a1]
nan value exists : 2697 / 9557
-------
[v18q1]
nan value exists : 2215 / 9557
-------
[rez_esc]
nan value exists : 1629 / 9557
-------
[meaneduc]
nan value exists : 9552 / 9557
-------
[SQBmeaned]
nan value exists : 9552 / 9557
-------
- v2a1
- v18q1
- rez_esc
の三つは中央値で補正することとしました。
残りの二つはほとんど欠損値なようで、今回は使わずに削除するようにします。
def replace_na_to_median(df):
TARGET_COLUMN_LIST = [
'v2a1',
'v18q1',
'rez_esc',
]
for target_column in TARGET_COLUMN_LIST:
median_val = df[target_column].median()
df[target_column].fillna(median_val, inplace=True)
return df
train_df = replace_na_to_median(df=train_df)
test_df = replace_na_to_median(df=test_df)
def delete_na_columns(df):
TARGET_COLUMN_LIST = [
'meaneduc',
'SQBmeaned',
]
for target_column in TARGET_COLUMN_LIST:
column_exists = target_column in df.columns
if not column_exists:
continue
del df[target_column]
delete_na_columns(df=train_df)
delete_na_columns(df=test_df)
特徴量で、型がobjectになっているものを調べます。
def print_object_dtype_columns(df):
for column_name, dtype in train_df.dtypes.items():
if str(dtype) == 'object':
print(column_name)
print_object_dtype_columns(df=train_df)
print('---')
print_object_dtype_columns(df=test_df)
Id
idhogar
dependency
edjefe
edjefa
---
Id
idhogar
dependency
edjefe
edjefa
Idとidhogarは識別用の値なのでいいとして、他の3つの特徴量を処理します。
train_df['dependency'].unique()
array(['no', '8', 'yes', '3', '.5', '.25', '2', '.66666669', '.33333334',
'1.5', '.40000001', '.75', '1.25', '.2', '2.5', '1.2', '4',
'1.3333334', '2.25', '.22222222', '5', '.83333331', '.80000001',
'6', '3.5', '1.6666666', '.2857143', '1.75', '.71428573',
'.16666667', '.60000002'], dtype=object)
特徴量の説明を読むと以下のように書いてあります。
dependency -> Dependency rate, calculated = (number of members of the household younger than 19 or older than 64)/(number of member of household between 19 and 64)
これだと、yesとnoを何に置換すればいいのか分かりませんが、他の特徴量から別途計算しなおせる印象なので、そちらで対応します。
他の2項目は以下のように書いてあります。0か1への置換で良さそうな記述ですが、ユニークな値を調べると、0と1での置換で本当に大丈夫なのか・・?という印象がありますが、一旦進めてしまいます。
edjefe -> years of education of male head of household, based on the interaction of escolari (years of education), head of household and gender, yes=1 and no=0
edjefa -> years of education of female head of household, based on the interaction of escolari (years of education), head of household and gender, yes=1 and no=0
train_df['edjefa'].unique()
array(['no', '11', '4', '10', '9', '15', '7', '14', '13', '8', '17', '6',
'5', '3', '16', '19', 'yes', '21', '12', '2', '20', '18'],
dtype=object)
train_df['edjefa'].unique()
array(['no', '11', '4', '10', '9', '15', '7', '14', '13', '8', '17', '6',
'5', '3', '16', '19', 'yes', '21', '12', '2', '20', '18'],
dtype=object)
def cast_and_replace_edjefe_and_edjefa_columns_val(df):
TARGET_COLUMN_LIST = ['edjefe', 'edjefa']
for target_column in TARGET_COLUMN_LIST:
df[target_column].replace(to_replace='yes', value=1, inplace=True)
df[target_column].replace(to_replace='no', value=0, inplace=True)
df[target_column] = df[target_column].astype(np.int64, copy=False)
return df
train_df = cast_and_replace_edjefe_and_edjefa_columns_val(df=train_df)
test_df = cast_and_replace_edjefe_and_edjefa_columns_val(df=test_df)
def add_dependency_columns(df):
del df['dependency']
df['dependency_num'] = df['hogar_nin'] + df['hogar_mayor']
df['dependency_rate'] = df['dependency_num'] / df['hogar_total']
return df
train_df = add_dependency_columns(df=train_df)
test_df = add_dependency_columns(df=test_df)
他にも、組み合わせで作れる特徴量を少し足しておきます。
def add_more_features(df):
df['tablets_per_individual'] = df['v18q1'] / df['hogar_total']
df['younger_child_rate'] = df['r4t1'] / df['r4t2']
return df
train_df = add_more_features(df=train_df)
test_df = add_more_features(df=test_df)
0~1に正規化した特徴量を追加しておきます。
def apply_scaler(df):
for column_name in df.columns:
if str(df[column_name].dtype) == 'object':
continue
if column_name == 'Target':
continue
min_ = df[column_name].min()
max_ = df[column_name].max()
if min_ == 0 and max_ == 1:
continue
scaler = MinMaxScaler()
df[column_name + '_scaled'] = df[column_name].astype(np.float64)
df[column_name + '_scaled'] = scaler.fit_transform(
X=df.loc[:, [column_name + '_scaled']])
return df
train_df = apply_scaler(df=train_df)
test_df = apply_scaler(df=test_df)
訓練用のデータセットを用意していきます。
X = train_df.copy()
del X['Target'], X['Id'], X['idhogar']
X_feature_name_arr = X.columns
X = X.values
y = train_df.loc[:, ['Target']].values
y = y.reshape(y.shape[0])
どの特徴量を選択すべきか・・ですが、安直に、一旦テストデータを分割してみて、ランダムに選択して精度が高いリストで進めてみようと考えました。書いていて、途中で「あ、クロスバリデーションにすべきだった・・」と思いましたが、そのまま進めてしまいます。
なお、途中のLGBMClassifierの引数も、今回は少し調整を加えてあります。
X_train, X_val, y_train, y_val = train_test_split(
X, y, test_size=0.33, random_state=42)
def get_feature_name_arr_from_idx(selected_feature_idx):
feature_name_arr = X_feature_name_arr[selected_feature_idx]
return feature_name_arr
highest_accuracy = 0
highest_accuracy_feature_name_arr = None
accuracy_and_feature_names_data_list = []
for i in range(50):
print(datetime.now(), 'iteration %s started.' % i)
overall_feature_num = len(X_train[1])
select_features_num = np.random.randint(low=3, high=20)
selected_feature_idx = np.random.permutation(
range(overall_feature_num - 1))[:select_features_num]
X_train_target = X_train[:, selected_feature_idx]
X_val_target = X_val[:, selected_feature_idx]
gbm = lgb.LGBMClassifier(
objective='multiclass',
random_state=42,
silent=True,
n_jobs=4,
n_estimators=5000,
class_weight='balanced',
colsample_bytree=0.93,
min_child_samples=95,
num_leaves=14,
subsample=0.96
)
selected_feature_name_arr = get_feature_name_arr_from_idx(
selected_feature_idx=selected_feature_idx)
print('choosed features :', selected_feature_name_arr)
gbm.fit(X=X_train_target, y=y_train)
y_pred = gbm.predict(X=X_val_target)
accuracy = accuracy_score(y_true=y_val, y_pred=y_pred)
print('accuracy :', accuracy)
if accuracy > highest_accuracy:
print('highest accuracy was updated.')
highest_accuracy = accuracy
highest_accuracy_feature_name_arr = selected_feature_name_arr
accuracy_and_feature_names_data_list.append(
{'accuracy': accuracy, 'selected_feature_name_arr': selected_feature_name_arr})
print(datetime.now(), 'iteration %s ended.' % i)
print('---')
accuracy_and_feature_names_df = pd.DataFrame(
data=accuracy_and_feature_names_data_list)
accuracy_and_feature_names_df.sort_values(
by='accuracy', ascending=False, inplace=True)
for index, sr in accuracy_and_feature_names_df[:3].iterrows():
print('accuracy', sr['accuracy'], '\nfeature_names',
str(sr['selected_feature_name_arr'].tolist()))
print('---')
ものすごいオーバーフィットしていそうな気配がしますが、上位3つの組み合わせは以下のカラムとなりました。
['estadocivil2', 'abastaguadentro', 'SQBdependency', 'male', 'hogar_adul_scaled', 'abastaguano', 'v2a1_scaled', 'energcocinar4', 'public', 'techoentrepiso', 'overcrowding', 'estadocivil5', 'edjefe_scaled', 'paredblolad', 'tamhog_scaled', 'parentesco4', 'r4h3', 'tipovivi3', 'paredmad']
---
['r4t1', 'SQBhogar_nin', 'instlevel9', 'tipovivi1', 'SQBedjefe', 'r4t2_scaled', 'instlevel6', 'instlevel4', 'r4h1_scaled', 'lugar1', 'v2a1_scaled', 'parentesco1', 'SQBhogar_total', 'rez_esc_scaled', 'epared3', 'hhsize_scaled', 'v18q1_scaled', 'energcocinar2']
---
['area1', 'instlevel5', 'r4t2_scaled', 'edjefe_scaled', 'cielorazo', 'abastaguadentro', 'techoentrepiso', 'r4h1', 'pareddes', 'escolari_scaled', 'r4h2', 'SQBdependency_scaled', 'hhsize_scaled', 'r4h2_scaled', 'escolari', 'edjefa_scaled', 'parentesco6']
それらの特徴量の組み合わせを使って、試してみます。
feature_name_list_1 = [
'estadocivil2', 'abastaguadentro', 'SQBdependency', 'male', 'hogar_adul_scaled',
'abastaguano', 'v2a1_scaled', 'energcocinar4', 'public', 'techoentrepiso',
'overcrowding', 'estadocivil5', 'edjefe_scaled', 'paredblolad', 'tamhog_scaled',
'parentesco4', 'r4h3', 'tipovivi3', 'paredmad']
feature_name_list_2 = [
'r4t1', 'SQBhogar_nin', 'instlevel9', 'tipovivi1', 'SQBedjefe', 'r4t2_scaled',
'instlevel6', 'instlevel4', 'r4h1_scaled', 'lugar1', 'v2a1_scaled', 'parentesco1',
'SQBhogar_total', 'rez_esc_scaled', 'epared3', 'hhsize_scaled', 'v18q1_scaled',
'energcocinar2']
feature_name_list_3 = [
'area1', 'instlevel5', 'r4t2_scaled', 'edjefe_scaled', 'cielorazo', 'abastaguadentro',
'techoentrepiso', 'r4h1', 'pareddes', 'escolari_scaled', 'r4h2', 'SQBdependency_scaled',
'hhsize_scaled', 'r4h2_scaled', 'escolari', 'edjefa_scaled', 'parentesco6']
feature_name_multi_dim_list = [
feature_name_list_1,
feature_name_list_2,
feature_name_list_3,
]
for i, feature_name_list in enumerate(feature_name_multi_dim_list):
X_train = train_df.copy()
del X_train['Target'], X_train['Id'], X_train['idhogar']
X_train = X_train.loc[:, feature_name_list]
X_train = X_train.values
X_test = test_df.copy()
del X_test['Id'], X_test['idhogar']
X_test = X_test.loc[:, feature_name_list]
X_test = X_test.values
X_train, _, y_train, _ = train_test_split(
X_train, y, test_size=0.33, random_state=42)
gbm = lgb.LGBMClassifier(
objective='multiclass',
random_state=42,
silent=True,
n_jobs=4,
n_estimators=5000,
class_weight='balanced',
colsample_bytree=0.93,
min_child_samples=95,
num_leaves=14,
subsample=0.96
)
gbm.fit(X=X_train, y=y_train)
y_pred = gbm.predict(X=X_test)
_ = plt.hist(x=y_pred)
plt.show()
submission_df = test_df.loc[:, ['Id']]
submission_df['Target'] = y_pred
index = i + 1
submission_df.to_csv('./submission_v3_%s.csv' % index, encoding='utf-8', index=False)
アーリーストッピング的な設定も、LightGBMでさくっとできるようなので、それらも使うべきだったかな・・と思いつつも、処理が通ったのでコミットしてsubmitしてみます。
結果のscoreは0.343でした。前の0.272と比べると流石に上がりましたが、0.448(エントリー回数140回)であり、且つランキング下の方なのでまだまだですね!(雑ですし、検証回数も少ないので当たり前ですが・・)
クロスバリデーションにして、一番精度の高い特徴量で試してみる
ほかにも、試行回数を50から100に増やしてみるなどの微調整を加えつつ・・・
from sklearn.model_selection import cross_val_score
...
highest_accuracy = 0
highest_accuracy_feature_name_arr = None
accuracy_and_feature_names_data_list = []
for i in range(100):
iter_start_dt = datetime.now()
overall_feature_num = len(X[1])
select_features_num = np.random.randint(low=3, high=40)
selected_feature_idx = np.random.permutation(
range(overall_feature_num - 1))[:select_features_num]
X_target = X[:, selected_feature_idx]
gbm = lgb.LGBMClassifier(
objective='multiclass',
random_state=42,
silent=True,
n_jobs=4,
n_estimators=5000,
class_weight='balanced',
colsample_bytree=0.93,
min_child_samples=95,
num_leaves=14,
subsample=0.96
)
selected_feature_name_arr = get_feature_name_arr_from_idx(
selected_feature_idx=selected_feature_idx)
cross_validation_scores = cross_val_score(
estimator=gbm, X=X_target, y=y, cv=5)
accuracy = np.mean(cross_validation_scores)
if accuracy > highest_accuracy:
print('highest accuracy was updated.')
highest_accuracy = accuracy
highest_accuracy_feature_name_arr = selected_feature_name_arr
accuracy_and_feature_names_data_list.append(
{'accuracy': accuracy, 'selected_feature_name_arr': selected_feature_name_arr})
print('accuracy', accuracy, iter_start_dt, 'started.', datetime.now(),
'iteration %s ended.' % i)
print('---')
accuracy_and_feature_names_df = pd.DataFrame(
data=accuracy_and_feature_names_data_list)
accuracy_and_feature_names_df.sort_values(
by='accuracy', ascending=False, inplace=True)
for index, sr in accuracy_and_feature_names_df[:20].iterrows():
print('accuracy', sr['accuracy'], '\nfeature_names',
str(sr['selected_feature_name_arr'].tolist()))
print('---')
...
['eviv2', 'parentesco12', 'hogar_mayor_scaled', 'r4h1_scaled', 'estadocivil3', 'television', 'tipovivi3', 'v18q', 'estadocivil6', 'instlevel8', 'hogar_nin_scaled', 'estadocivil1', 'eviv1', 'overcrowding_scaled', 'parentesco6', 'edjefa_scaled', 'rooms_scaled', 'parentesco3', 'parentesco1', 'techootro', 'elimbasu4', 'paredzinc', 'mobilephone', 'parentesco2', 'r4t3_scaled', 'edjefe_scaled', 'elimbasu2', 'tipovivi5', 'qmobilephone_scaled', 'dis']
...
上記のものでsubmitしてみたところ、0.354のスコア。若干の精度向上。
メモ
- ほかにも少し調整してみたところ、あまりよい結果になりませんでした。
- 自分で雑に対応していると、あまり改善しないので、後日他の方のカーネル(スコアが0.4台のものも公開されているため)を読み進めたりしてみようと思います。
- なんども試してみる作業が結構楽しいものの、まとまった時間の確保が少し課題だな・・と感じました。
- 次回以降は、もう少し締め切りに余裕のあるコンテストで色々試してみようかな、という印象。