世の中的には分析などをする際にはBigQueryのケースが多いと思いますが、仕事でAmazon Athenaを触るケースが出てきたので、入門としてまとめておきます。
Amazon Athenaとは
- BigQueryみたく、SQLで大きなデータを集計などできるAWSのサービスです。
- 分析の他にも他のAWSサービスのログ確認などでも使われたりしますが、今回は分析寄りの記事として進めます。
- BigQueryと比べて大きく異なる点として、「データをS3に配置する」という点があります(それによるメリットなどは後述)。
コストはどうなの?
基本的にスキャンサイズのみに課金されます。
Amazon Athena では、実行したクエリに対してのみ料金が発生します。クエリごとにスキャンされたデータの分量に基づいて料金が請求され、1 テラバイトごとに 5 USD が請求されます。
Amazon Athena
ディスクサイズに対してはS3に配置する都合、S3のコストとなります。
S3上にCSVなどが配置されていればAthenaを利用できるため、たとえばBigQuery専用とかAthena専用といったようにデータを引越ししてきたりしなくても使えます(ただし、ファイルフォーマットやディレクトリ名などは気をつけておく必要あり)。
また、S3に依存するため、S3で使えるコスト削減の設定などがそのまま使えます(例 : 新機能- Intelligent TieringによるAmazon S3の自動的なコスト最適化)。
gzipで圧縮されているCSVやJsonなどに対してもSQLを実行することができます。それによって、ディスクサイズ自体の削減やクエリのスキャンサイズによるコストを削減することができます。
データの圧縮、分割、列形式への変換を行うことにより、クエリに対するコストを 30%~90% 削減し、パフォーマンスを向上させることができます。
Amazon Athena
長いこと、検証せずに「あれ、これAthenaの方が安くならない?」という印象がしていましたが、他の方の記事でもそういったことが書かれているので、しっかり運用できればAthenaの方が安くなりそうな気配があります(ネット上のコストの表だけだと比較時に分かりづらい・・)。
一方、BigQueryではデータが圧縮されているかどうかは関係なく実際のデータサイズに基づいて計算されると記載されています。
BigQueryとAthenaの料金を比較したら意外にもAthenaのクエリ料金がお得だった
また、AthenaもBigQueryも1TBあたり5USDという価格であるため、同じデータに対して同じクエリを実行すればほぼ同じ費用になるという考えが間違っていることも分かります。AthenaはS3に置かれているファイルのデータ容量で勘定されるため、圧縮率の高い形式で保存すればそれだけ費用を抑えることができます。ただし、高い圧縮率はパフォーマンスの劣化をもたらすので、これらはトレードオフの関係にあります。
AthenaとBigQueryの比較をしてみた(2019年版)
Athenaの場合、ストレージのS3のコストが圧縮によって削減されるのに加えて、スキャンコスト自体も圧縮後のサイズで計算されるそうです(展開などする都合、圧縮前のサイズで計算されると思っていた・・)。
※リンク先の記事で、圧縮考慮しないスキャン自体もAthenaの方が安いという記載がありますが、どうやら現在BigQuery側もAthenaと同じ$5 per TBのようです。
スキャン時の最低サイズは10MB
スキャンサイズがとても小さいデータに対してクエリを実行しても、最低は10MBとしてカウントされます。
バイト数はメガバイト単位で切り上げられ、10 MB 未満のクエリは 10 MB と計算されます。
Amazon Athena の料金
1TBで$5なので、1GBで0.5円くらい。10MBで0.005円くらいでしょうか。
10MBのクエリを200回実行したら1円くらいになります。些細なクエリでも10MB分課金されてしまう!と思わなくても特に問題にならないレベルのコスト感です。
パフォーマンスは?
BigQueryと比べると結構遅めです(圧縮データで扱うというのも絡んでくるとは思いますが・・)。
とはいっても、なんだかんだ私の用途(仕事で必要な範囲)だと数秒~遅くても数十秒程度で終わるので今のところは特に気になっていません。
大きなデータセットに対してもインタラクティブなパフォーマンス
Amazon Athena を使えば、高速で、インタラクティブなクエリパフォーマンスが得るために十分なコンピューティングリソースがあるかどうかを心配する必要はありません。Amazon Athena では、クエリが自動的に並列で実行されます。そのため、たいていは数秒で結果が出ます。
Amazon Athena
一度に数百GBのスキャンといった規模でクエリ投げないといけない、といった感じであれば普通にBigQueryでいいと感じています。
(Athenaでの10秒がBigQueryで3秒になる程度であれば正直普段作業する上でAthenaでも大して気にならないかなと。もっと規模が大きくなって5分が30秒になるとかであれば、BigQueryじゃないと作業していてい結構気になってきそうな気がしています)
最後にまとめると、速くて高いBigQueryと、遅くて安いAthenaという結果になりました。
AthenaとBigQueryの比較をしてみた(2019年版)
その他の点の比較など
現状、BigQueryのほうが利用されている方が多いですし、ネット上の情報も多めです。
また、細かいUXと言いますか、使いやすさとかはBigQueryのほうが扱いやすいな・・・と思うこともぼちぼちあります(Pandasみたくその辺りはよしなにやってくれたらいいのに・・・と感じるところが・・)。
まあでもある程度手間をかけてコストを下げたいとか、管理などの負担的にAWSに集中させたいといったケースではAthenaでもいいのではないでしょうか。
AWSのコンソールで実際に使ってみる
まずは普通のCSVで試す
Athenaで利用するために、データはS3上にアップしておく必要があります。
そのため、お試しとしてPythonを使って適当なCSVを作ってS3にアップします。
import pandas as pd
import numpy as np
df = pd.DataFrame(
columns=['date', 'user_id', 'point'],
index=np.arange(0, 3000000))
df['date'] = '2019-10-01'
df.user_id = np.arange(1, 3000001)
df.point = np.random.randint(low=50, high=101, size=(df.shape[0],))
df.to_csv('sample_data1.csv', encoding='utf-8', index=False)
df.head()
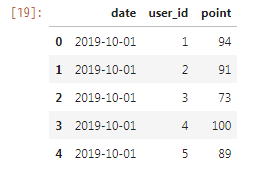
注意点として、カラムの順番がずれないように配慮する必要があります。
たとえば、Athena上で['date', 'user_id', 'point']というカラム順を想定して手作業でテーブルを作った際に、実際のCSVは['date', 'point', 'user_id']といったように定義と異なる順番になっていると、Athena上でそのままずれた順番で表示されてしまいます。
そのため、もしずれるケースがある(データ読み込み元でずれているなど)場合には、明示的にカラム順を整えてからCSVを保存するほうが無難です(Pandasであればdf.loc[:, ['date', 'user_id', 'point']]的な記述をto_csvメソッドの前に挟んでおくなど)。
また、CSVの文字コードがsjisなどになっていると少し面倒な感じになってくるため、基本的にutf-8で保存しておきます。
保存したCSVをS3のバケット上でsample_data1/というフォルダを追加して、そちらにアップロードしました。

続いてAthenaのサービスに移動します。

Get Startedを選択。

最初はテーブル作成でチュートリアル的なUIが表示されます。
もしくは左のメニューのAdd tableを選択してもテーブル作成の画面に移ります。
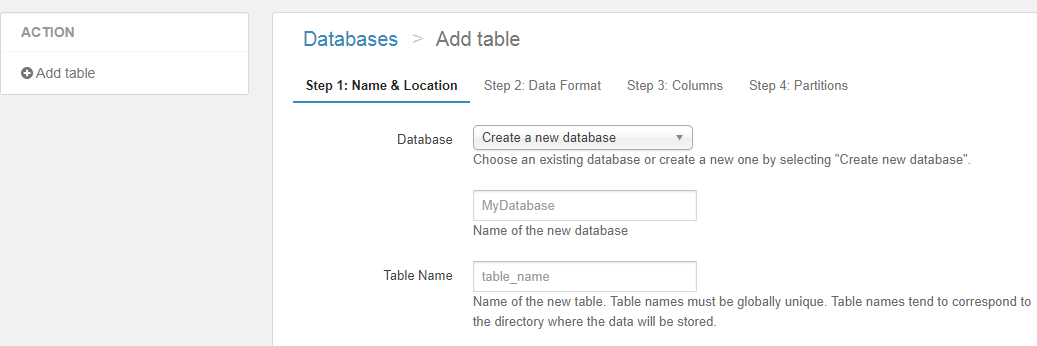
今回は新規でsample_datasetという名前でデータベースを作成(Create a new databaseを選択)し、Table Nameはsample_data1としました。
Location of Input Data Setには、S3に配置したデータの設置ディレクトリを指定します。このディレクトリ以下が1つのテーブル相当になります。
S3上でファイルにチェックを入れたりすると表示されるUIで、コピーパスというボタンがあるのでそちらを選択することで、以下のようなパス情報が取れます。
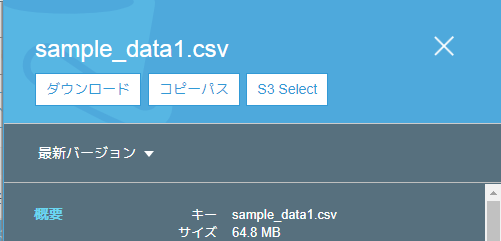
s3://<バケット名>/sample_data1/sample_data1.csv
今回指定するのはディレクトリまでなので、以下の部分をLocation of Input Data Setに指定します。
s3://<バケット名>/sample_data1/
Nextを押すとデータフォーマットを選ぶUIになるので、今回はCSVを選択します。
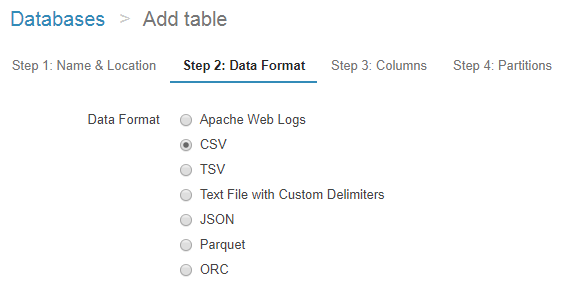
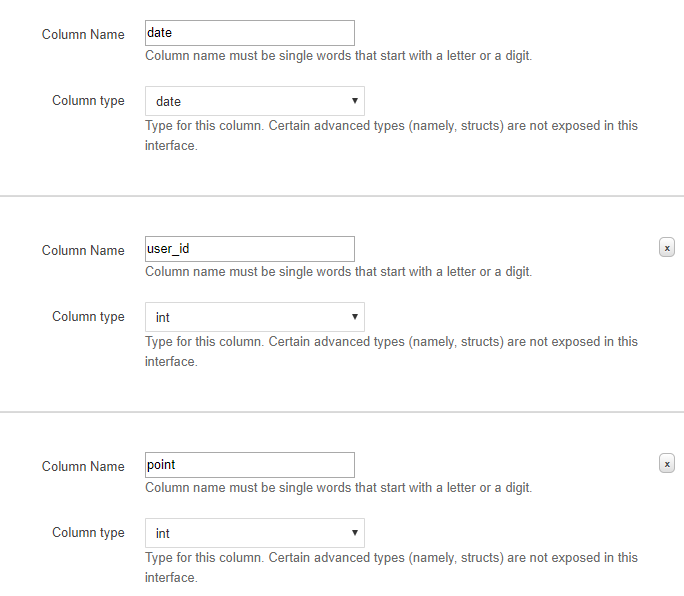
続いてカラムの定義をするUIになるので、記載していきます。
今回は以下のように設定しました。
最後のパーティション設定の画面が出ますが、今回はスキップします(後で触れます)。
Create Tableボタンを押すとテーブル作成に実行されたクエリなどが表示された画面になります。
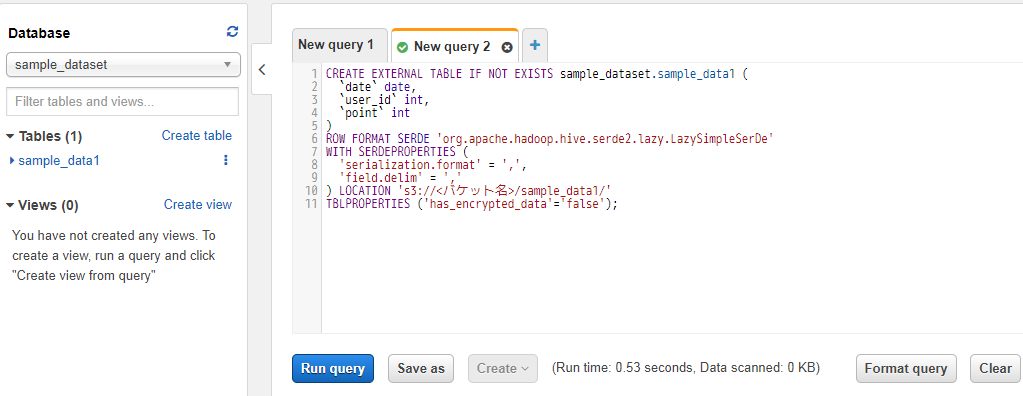
後で使うため、このクエリは閉じずに残しておきます。
左にあるメニューのテーブル部分にあるメニューをクリックすると、オプションが表示されます。

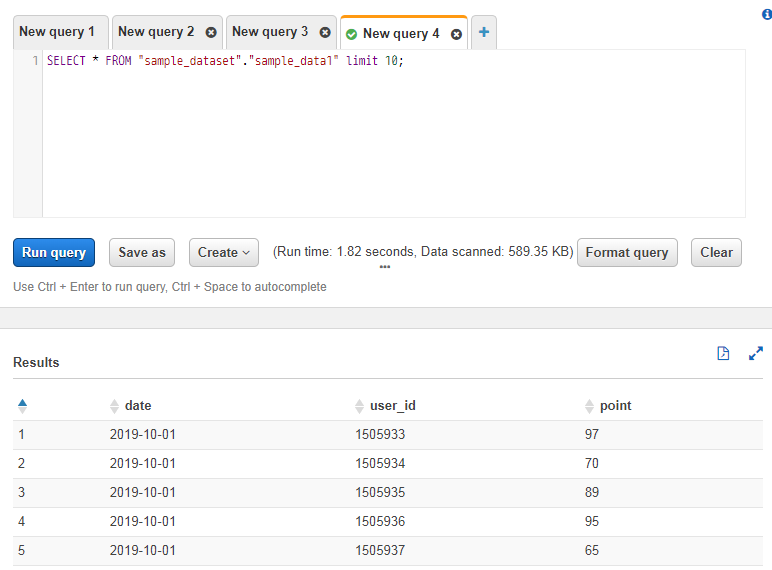
Preview tableをクリックするとテーブルの内容が確認できます。そうすると実行されたSELECT分と結果が下に表示されます。
スキャンサイズの制限を設けておく
次に進む前に、何度かクエリを実行したりしていくので、事前に安全のための設定をしておきます。
BigQueryでは事前にdry_runとしてスキャンする前にスキャンサイズを確認したり、比較的最近の機能としてはクエリでパーティションのWHERE文が無いとクエリが実行できないような、安全に使うためのオプションがいくつかあります。
例1 :
全件取得することがなければ「パーティションフィルタを要求」にチェックをつけます。
チェックをつけるとデータ取得時に日付で絞り込みをしないとエラーになります。
BigQuery 日付で自動的にパーティションを区切り有効期限を設定する
例2 :
BigQueryではクエリによるサイズによってコストがかかるので、この機能を使うことで事前に必要バイト数を見ることができ、うっかり膨大なサイズが必要になるクエリを実行してしまう、ということを高い確率で避けることができます
BigQueryを安全に使うためのTIPS集(+基本的な操作をステップバイステップで)
Athenaでも同様に、安全に運用できるようにするためのオプションが設けられています。
(一回のスキャンサイズの上限を設定できます)
普段実行しているクエリがパーティションを設定していると思ったらうまいことパーティションを利用できていなくて、全件スキャンされていていつの間にかコストがやばくなっていた・・・といったことを防ぐために、事前に設定しておきましょう。
参考 : データ使用量の制御制限の設定
Athenaの画面の上のほうのメニューに、Workgroupというメニューがあります(最初はprimaryとかになっていると思います)。そちらをクリックします。

すると以下のような画面になるので、制限を設定したいWorkgroup(今回はprimary)にチェックを入れて、「View details」ボタンを押します。

遷移後の画面でData usage controlsのタブをクリックします。

すると以下のように上限を設定できる画面になるので、任意の値を設定します(会社のデータ規模と必要な集計などを考慮し)。

これで時系列データでパーティションを参照していなくて、コストアラートが飛んできたり・・・を避けれます![]()
JSONのデータを試す
CSV以外にも、JSON形式のデータをAthenaで扱うことができます。
業務だと今のところCSVしか使っていないのですが、JSONのほうも実際に試してみましょう。
CSVの時と同じように、Pythonでさくっとサンプルデータを作ります。JSONは1行ずつの以下のようなフォーマットで設定してある必要があります。
{"date":"2019-10-01","user_id":1,"point":57}
{"date":"2019-10-01","user_id":2,"point":52}
{"date":"2019-10-01","user_id":3,"point":77}
{"date":"2019-10-01","user_id":4,"point":64}
...
そういったデータにしたい場合には、Pandasではto_json関数でorient='records'と lines=Trueの引数を指定することで作成できます。
また、明示的にutf-8を指定する際にはwithステートメントでファイルを開いて保存する必要があるようです(to_json関数自体にencodingの引数が無い模様)。
import pandas as pd
import numpy as np
df = pd.DataFrame(
columns=['date', 'user_id', 'point'],
index=np.arange(0, 3000000))
df['date'] = '2019-10-01'
df.user_id = np.arange(1, len(df) + 1)
df.point = np.random.randint(low=50, high=101, size=(df.shape[0],))
with open('sample_data2.json', 'w', encoding='utf-8') as f:
df.to_json(f, orient='records', lines=True)
参考 : pandas.DataFrameをJSON文字列・ファイルに変換・保存(to_json)
Writing pandas DataFrame to JSON in unicode
S3上でsample_data2というフォルダを作って、そちらに保存したJSONを配置します。
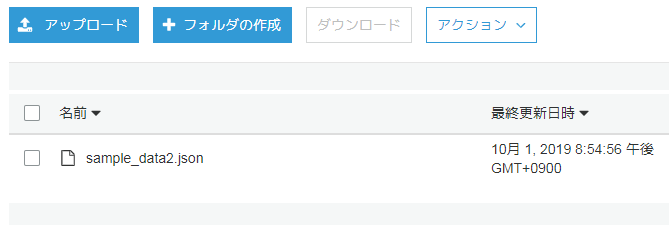
Athenaの画面でCreate tableを選択して、テーブルを作っていきます(from S3 bucket dataを選択)。
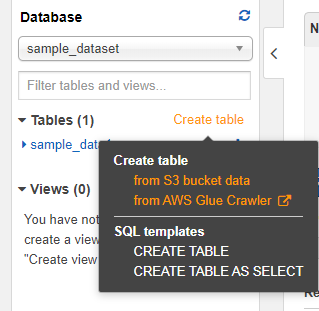
テーブル名やS3のディレクトリパスをCSVの時と同様に設定していきます。
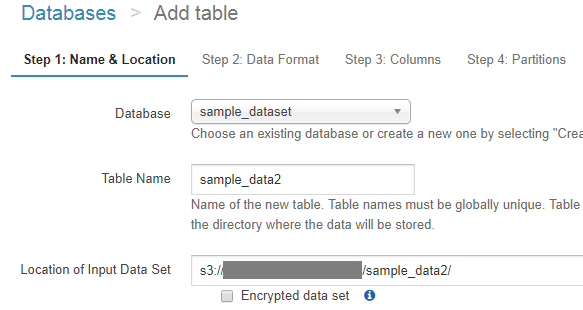
データフォーマットにはJSONを選択します。
カラム設定もCSVの時と同じです。
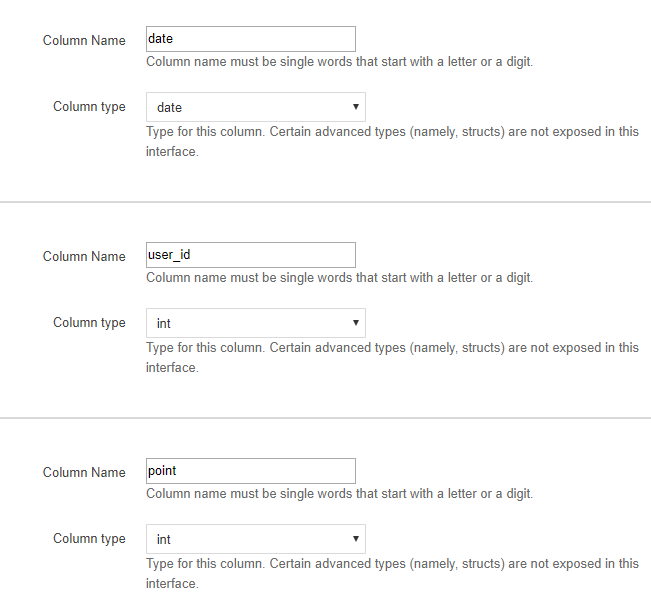
パーティション設定は今回もスキップし、テーブルを作成します。
作成されたテーブルでPreview tableを実行すると、JSON形式でも問題なく表示できたことが分かります。
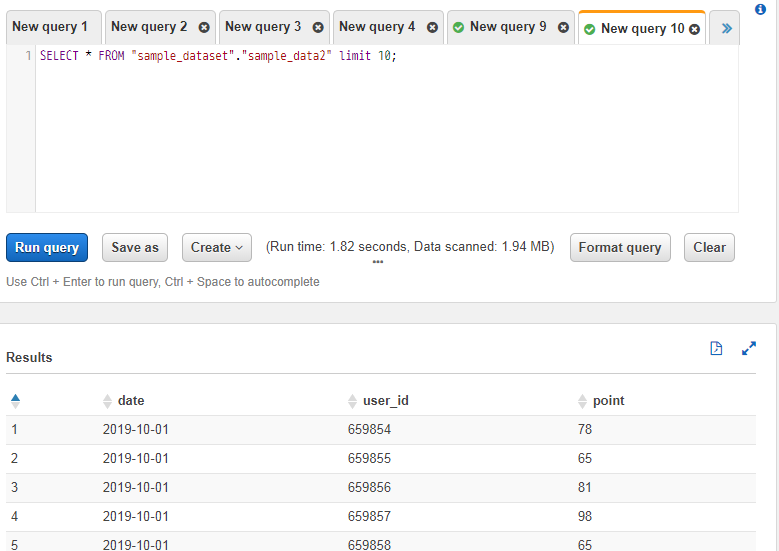
圧縮データ(gzip)を扱ってみる
ディスクコストやスキャンコストの削減を考えると、なるべくファイルを圧縮しておきたいところです(Athenaを使うメリットでもありますし)。
そのため、この節ではgzipによる圧縮データを扱っていってみます(いくつか注意点があります)。
Pandasでcompression='gzip'と指定し、ファイルの最後の拡張子をgzにしておきます。
import pandas as pd
import numpy as np
df = pd.DataFrame(
columns=['date', 'user_id', 'point'],
index=np.arange(0, 3000000))
df['date'] = '2019-10-01'
df.user_id = np.arange(1, len(df) + 1)
df.point = np.random.randint(low=50, high=101, size=(df.shape[0],))
df.to_csv(
'sample_data3.csv.gz', encoding='utf-8', compression='gzip', index=False)
なお、Athena側でファイルの拡張子に応じて自動で圧縮などを判定するとドキュメントに書かれていますが、.gzipなどではうまくいきませんでした。.gzとする必要があるようです。
CSV、TSV、および JSON のデータについては、Athena がファイル拡張子から圧縮タイプを判断します。
圧縮形式
なお、ファイルサイズとして、前述までの各コードで、生のCSVが66MB、生のJSONが151MB、gzip化されたCSVが約10MBとなっています。
S3にsample_data3というフォルダを作って、そちらにgzipファイルを配置します。

テーブル名やS3パスの指定などは今まで通りです。
データフォーマットはgzip化されていますが、CSVを選択します。
ただ、GUI上で作ると、以下のようなクエリが実行されてプレビューすると変な感じの結果になります。
CREATE EXTERNAL TABLE IF NOT EXISTS sample_dataset.sample_data3 (
`date` date,
`user_id` int,
`point` int
)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe'
WITH SERDEPROPERTIES (
'serialization.format' = ',',
'field.delim' = ','
) LOCATION 's3://<バケット名>/sample_data3/'
TBLPROPERTIES ('has_encrypted_data'='false');
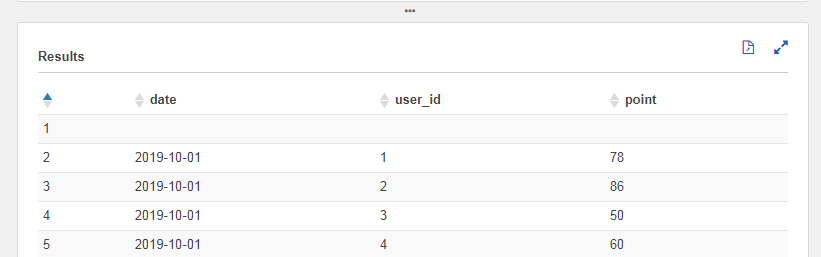
なにやら最初の行に空の値があります。
どうやら、現状CSVでgzip化すると、ヘッダーの行を除外してくれないようです・・(圧縮しないCSVなら問題なく動作してくれる一方で)
Pandasなどでも扱うことを考えると、CSVにヘッダーは残しておきたいところです。そういった場合は以下のようにTBLPROPERTIESの属性に'skip.header.line.count'='1'の属性を追加することで動作してくれます。
CREATE EXTERNAL TABLE IF NOT EXISTS sample_dataset.sample_data3_2 (
`date` date,
`user_id` int,
`point` int
)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe'
WITH SERDEPROPERTIES (
'serialization.format' = ',',
'field.delim' = ','
) LOCATION 's3://<バケット名>/sample_data3/'
TBLPROPERTIES (
'has_encrypted_data'='false',
'skip.header.line.count'='1');
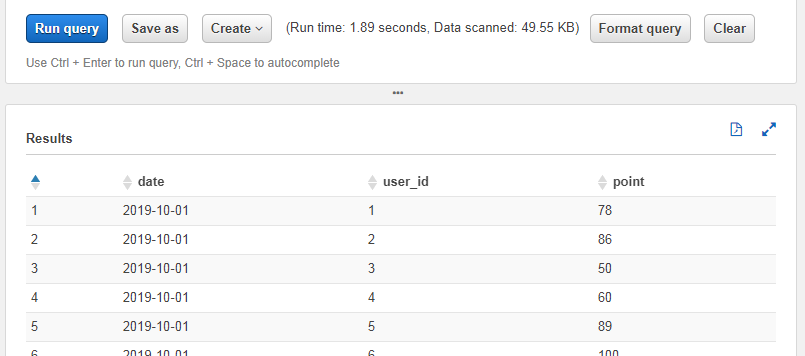
想定していた結果になってくれました。
CSVへのインデックス設定に注意
うっかりPandasでto_csv関数を実行する際に、index=Falseと指定しないと、インデックス分列が増えてしまい、Athena上でなんだかデータが一部しか入らなかったり、ずれて入ったりしてしまいます。出力結果のCSVとAthenaのGUI上で設定するカラム数は一致している必要があるため注意です(うっかりデフォルト値のままto_csv関数を使っていて、Athenaに正常にデータが反映されず悩むこと数分・・・)。
パーティションを試してみる
BigQuery同様、パーテーションを設定することで時系列データなどでのスキャンコストを下げたり速度を上げたりすることができます。
時系列データでパーティションを設定しないと、WHERE文とかを指定しても全期間でスキャンされたりします。コストが跳ね上がらないためにも、時系列データでは極力設定しておきたいところです(設定を忘れていてもスキャンサイズの上限設定などをしていれば気づくとは思いますが・・)。
特殊な点として、BigQueryと異なり、ファイル設置時の時点でパーティションを考慮する必要があります(パーティションを加味した名前のフォルダを挟む必要があります)。
まずはデータを準備します。時系列データを想定して、CSVを三つに分けます。
import pandas as pd
import numpy as np
df = pd.DataFrame(
columns=['date', 'user_id', 'point'],
index=np.arange(0, 3000000))
df['date'] = '2019-10-01'
df.user_id = np.arange(1, len(df) + 1)
df.point = np.random.randint(low=50, high=101, size=(df.shape[0],))
df.point = np.random.randint(low=50, high=101, size=(df.shape[0],))
df.to_csv(
'sample_data4_1.csv.gz', encoding='utf-8', compression='gzip', index=False)
df['date'] = '2019-10-02'
df.to_csv(
'sample_data4_2.csv.gz', encoding='utf-8', compression='gzip', index=False)
df['date'] = '2019-10-03'
df.to_csv(
'sample_data4_3.csv.gz', encoding='utf-8', compression='gzip', index=False)
S3上にsample_data4というフォルダを作って、中にさらにパーティション用のフォルダを作ります(ルールはHiveに準じる形となります)。
<パーティションのカラム名>=<日付などの値>というフォーマットで設定します(例 : date=2019-10-03)。
今回はdtという名前のパーティションで進めます(dateとか任意の名前でも問題なく動作します。ただし、CSV内に同名のカラムがあると怒られます。今回はdateというカラムがCSV内にあるので、dtとしました。)。
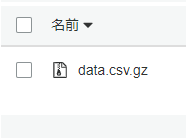
また、それらのフォルダ内に先ほど作ったgzip化されたCSVをアップロードして、data.csv.gzという名前にしておきます。
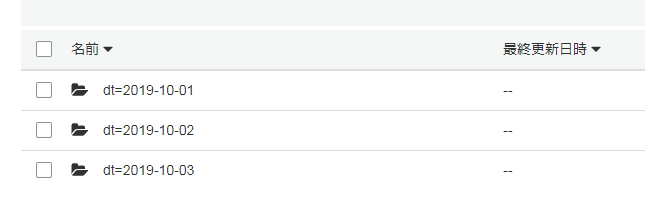
こんな感じのフォルダ構成になっています。
- sample_data4
- dt=2019-10-01
- data.csv.gz
- dt=2019-10-02
- data.csv.gz
- dt=2019-10-03
- data.csv.gz
- dt=2019-10-01
Athenaでテーフルを追加していきます。
Configure Partitionsのステップで、Add a partitionボタンを押します。
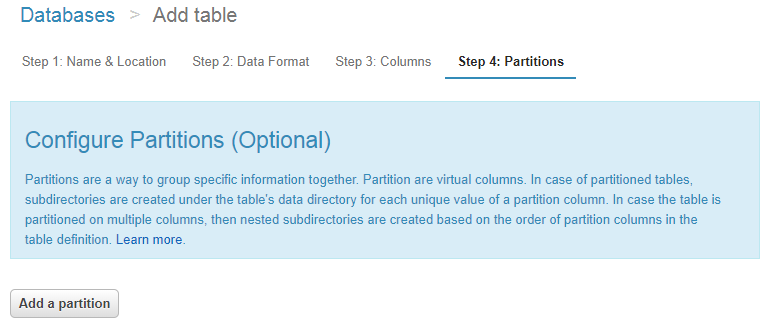
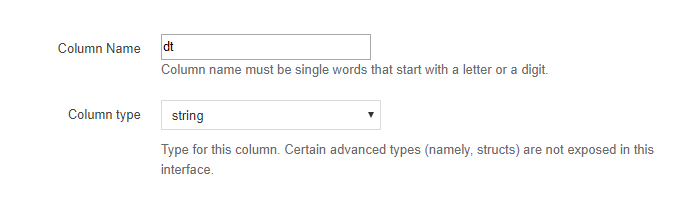
パーティションのカラム名を指定するUIが出てくるので、先ほどフォルダに指定したカラム名(今回はdt)を指定します。
型はなんだか記事を調べているとdateではなくstringを指定している記事が多く見受けられます。日付などのカラムに対してdateを使うかstringを使うかは後述する節で少し補足します。
参考 : Amazon Athenaのパーティションを理解する #reinvent
Create tableボタンを押してテーフルを作成します。
以下のようなクエリが実行され、テーブルが作成されます(今回はskip.header周りの設定を省略しましたが、前述の通り実際にはgzipのCSVを扱う場合には必要になるのでGUI経由ではなく直接SQLを実行したりして調整ください)。
CREATE EXTERNAL TABLE IF NOT EXISTS sample_dataset.sample_data4 (
`date` date,
`user_id` int,
`point` int
) PARTITIONED BY (
dt string
)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe'
WITH SERDEPROPERTIES (
'serialization.format' = ',',
'field.delim' = ','
) LOCATION 's3://<バケット名>/sample_data4/'
TBLPROPERTIES ('has_encrypted_data'='false');
見てみると、PARTITIONED BYという記述が増えているのが分かります。
また、テーブル作成後以下のようなSQLを実行しないと、パーティションを利用できず、クエリ結果が空になってしまったりするようです。
MSCK REPAIR TABLE <テーブル名>
今回は以下のようなクエリを実行します。
MSCK REPAIR TABLE sample_data4
結果の出力を見ていると、なんだかデータ追加のたびに必要なのかな?という印象があります(この辺りは実務で使う場合には自動化しておきたい)。
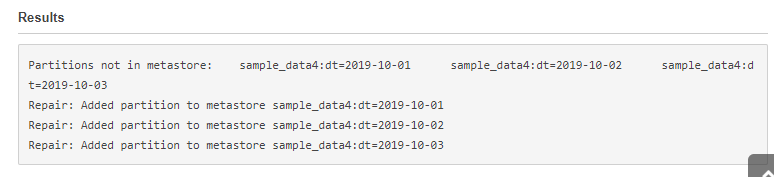
左の一覧で、作成されたテーブルを見てみるとパーティション設定したテーブルにはPartitionedという記述が追加されます。すぐ分かっていいですね。

試しにパーティションを参照してWHERE文を書いてみます。
WHERE文で文字列などを指定したい場合にはシングルクォートなどを使います。テーブル名の部分のようにダブルクォートなどを使うとエラーで怒られます。
SELECT * FROM "sample_dataset"."sample_data4" WHERE dt = '2019-10-02'
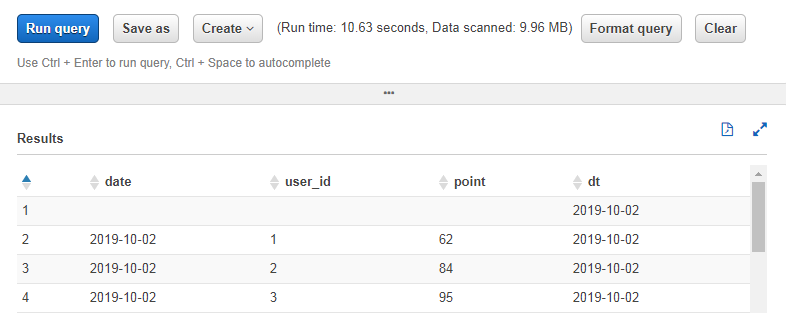
無事値が取れました。スキャンサイズもCSV1つ分になっています。
試しにdtのパーティションを指定せずに、dateカラムをWHEREに指定してクエリを投げてみます。
SELECT * FROM "sample_dataset"."sample_data4" WHERE date = CAST('2019-10-02' AS DATE)
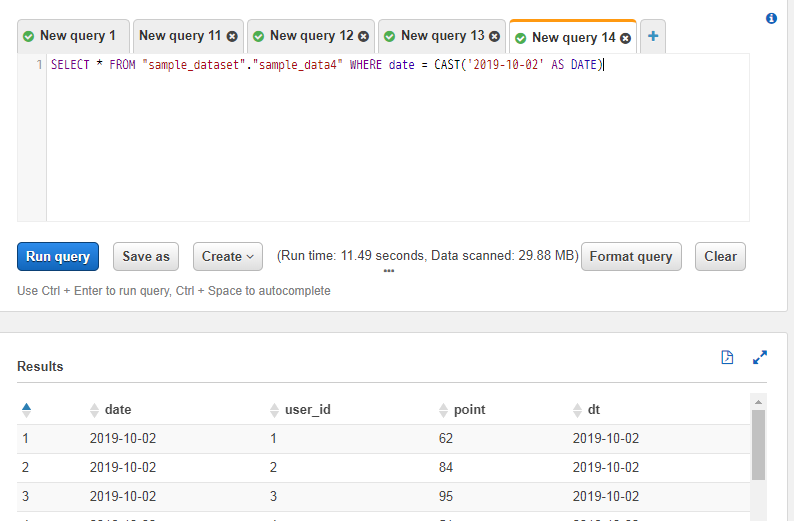
クエリ結果は一緒ですが、スキャンサイズが約30MBと増えており、全ての日付のデータに対してスキャンが走っていることが分かります。
補足 : AthenaのDATE型に関して
ネット上の記事を見ていた感じ、日付などのカラムやパーティションに対して、DATE型ではなくSTRING型を使っているケースがぼちぼち見受けられました。
MySQLだと普通はDATEとかDATETIMEとかで扱うことが多いと思いますが、MySQLの感覚でdate >= '2019-10-03'みたいな書き方をAthenaですると怒られます。
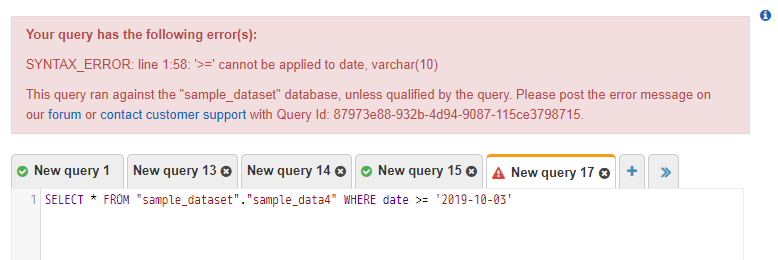
DATE型のカラムに対してWHERE文を使う場合にはキャストする必要があります。
SELECT * FROM "sample_dataset"."sample_data4" WHERE date >= CAST('2019-10-03' AS DATE)
参考 : Amazon Athena ( Presto 0.172 ) で日付の比較をして先月以降のデータを取得する
この点が、初見の時分かりづらい(特に、Athenaを普段触っておらず、MySQLやBigQueryを普段触っているプランナーさんやデータサイエンティストさん達にとって)可能性があります。
一方で、日付などをSTRING型で持つとMySQLやBigQueryなどと同じ感覚のSQLで書くことができます。大なり小なり的な記述も行えます。
SELECT * FROM "sample_dataset"."sample_data4" WHERE dt >= '2019-10-03'
そのため、MySQLやBigQuery、Athenaなどを入ったり来たりする必要がある方達にとってのスイッチングコストを下げたりするためにも、日付などのカラムはAthenaではDATE型ではなくSTRING型でもいいんじゃないだろうか・・・と少し思っています(パーティションなど含め、型でSTRINGを使っている記事も結構見かけるというのもそうですが・・)。
Amazon Glueに関して
書籍などでAthenaとセットで出てきたりするAmazon Glue。
Athenaで楽ができるように、様々な機能が用意されています。
テーブルのスキーマを手作業ではなく自動で判定してくれたり(BigQueryでもCSVなどからスキーマを判定する機能があったりしますが)、スキーマが変わった時の制御、ETL作業、それらのスケジューリング・・などなど、様々な機能が用意されています。
Glueまで触れだすと記事がかなり長くなっていきそうなのと、キャッチアップがまだ微妙なので、別の記事でGlue関係は触れていきたいと思います。
参考 : Glueの使い方的な
他のファイルフォーマット : Parquetに関して
CSVやJSONのほかにも、AthenaではParquetというフォーマットがよく出てきます(元々はHadoop関係に関連したデータフォーマットで、Daskのドキュメントなどでも推奨のフォーマットとして結構出てきました)。
こちらのフォーマットでは、フォーマットの性質上CSVなどよりもさらにスキャンサイズを減らしたりできるようです。変換の手間などはありますが、クエリを大量に実行される方は検討してみてもいいかもしれません。
データ分析では大福帳フォーマットのテーブルデータに対して、特定の列の値を集計したり、フィルタリングすることが多いため、カラム毎にデータが連続して格納されていると必要なデータのみをピンポイントで読み込むことができるからです
また、列方向には同じ種類のデータが並んでいるため、圧縮アルゴリズムも効きやすくなることが期待できます。
Amazon Athena: カラムナフォーマット『Parquet』でクエリを試してみた #reinvent
少し仕事で使ってみた所感
AWSメインのプロジェクトで、AWSのインスタンスにgoofysでS3をマウントしてファイルシステム上で扱っていたりするので、他の記事で言われているようなS3へのアップロードが手間・・・というのは今のところ感じていません(Pandasなどで直接CSVの保存ができる)。
PandasやらDaskやらでETLなどを扱って、そのままPandasなどでS3上に保存、そしてAthenaで扱えるようにする・・・といった感じで、シンプルにPythonでさばけています(専門のインフラ屋さんではないので、この辺りの易しめの領域でもとりあえずいいでしょう・・)。
参考 : s3fsよりも高速に使えるgoofysを試してみた
なお、キャッチアップできていませんが、最近出たData Wranglerなるものも結構気になっています(機会があれば触ってみたい)。
現在、Pythonを用いて、Amazon Athena(以下、Athena)やAmazon Redshift(以下、Redshift)からデータを取得して、ETL処理を行う際、PyAthenaやboto3、Pandasなどを利用して行うことが多いかと思います。その際、本来実施したいETLのコーディングまでに、接続設定を書いたり、各種コーディングが必要でした。Data Wraglerを利用することで、AthenaやAmazon S3(以下、S3)上のCSVからPandasを利用するのが、数行で実施できたり、PySparkからRedshiftに連携できるなど、お客様側はETLの処理の記述内容に集中することができます。
AWS Data Wranglerを使って、簡単にETL処理を実現する
世の中的にはAWSメイン・BigQueryだけGCPといったプロジェクトもそれなりにあると思いますが、Athenaを使ってAWSに統一するというのも、転送やらを考えなくて済みますし、アカウント管理などの手間も減らせそうに感じます(多分少人数チームでAWSとGCP両方扱うよりかは負担的に)。
逆に、既にGCPメインのプロジェクトであれば、BigQueryのほうが便利だなーと感じるところもあるので、わざわざAthenaを使うメリットは少ないかな・・・という印象はあります(コスト面を除けば)。
コスト面に関しては、ちゃんと圧縮やパーティションなどを適切に運用していけば、最近の各記事を見ていた感じ結構安くなる印象を受けたため、期待です(まだAthenaを使い始めたばかりで、データ量も少ないので、段々利用が進んでデータ量が増えてきてからじゃないとどんなコスト感に落ち着くのか分かりませんが・・)。
ライブラリ対応状況的なもの
この辺りのサードパーティーのライブラリなどは、やっぱりBigQueryのほうがシェアが高い分よく対応されている感があります。
redashであればBigQueryとAthena両方対応されているようです。
Redash が Amazon Athena を正式サポートしたので試してみた
MetabaseはBigQueryは対応しているものの、Athenaはissueが出ていますがクローズしていないのでまだ対応していない?のか、別のリポジトリで対応しているのか、なんとも言えない感じがあります。
Athena driver #8637
Metabase Athena Driver
PandasなどもBigQuery用の直接のインターフェイスが用意されています(BigQuery側で用意されているライブラリとは別に、to_gbqなど)。
Pandasの直接のAthenaインターフェイスは無く、Athena側で用意されているライブラリもしくはboto3などを通したりが必要になります。
参考文献まとめ
- Amazon Athena
- Serverless Architectures with AWS: Discover how you can migrate from traditional deployments to serverless architectures with AWS
- 新機能- Intelligent TieringによるAmazon S3の自動的なコスト最適化
- BigQueryとAthenaの料金を比較したら意外にもAthenaのクエリ料金がお得だった
- AthenaとBigQueryの比較をしてみた(2019年版)
- Amazon Athena の料金
- BigQuery 日付で自動的にパーティションを区切り有効期限を設定する
- BigQueryを安全に使うためのTIPS集(+基本的な操作をステップバイステップで)
- pandas.DataFrameをJSON文字列・ファイルに変換・保存(to_json)
- (https://stackoverflow.com/questions/39612240/writing-pandas-dataframe-to-json-in-unicode)
- s3fsよりも高速に使えるgoofysを試してみた
- AWS Data Wranglerを使って、簡単にETL処理を実現する
- Redash が Amazon Athena を正式サポートしたので試してみた
- Athena driver #8637
- Metabase Athena Driver
- AWS Data Wranglerを使って、簡単にETL処理を実現する
- Amazon Athenaのパーティションを理解する #reinvent
- Amazon Athena ( Presto 0.172 ) で日付の比較をして先月以降のデータを取得する
- Glueの使い方的な
- Amazon Athena: カラムナフォーマット『Parquet』でクエリを試してみた #reinvent