BigQueryで検索すると、以下の記事が上位にヒットします。
なにそれ怖い。ということで(?)、チキンな私は実務で扱う前に先に書籍で体系立てて学んでおくことにしました。(Learning Google BigQuery: A beginner's guide to mining massive datasets through interactive analysis)
本に書いてあったコストを抑えたり、安全に使うためのTIPS(及びある程度基本的な操作)を、段階的に動かしながら書いていきます。
対象の読者の方
- BigQueryをこれから触る方
- なんとなく、BigQueryに怖い印象をお持ちの方
進める上での注意点
この記事を書く上で操作手順が問題なくても何回か原因が不明なエラーに見舞われました。
他の方でもぼちぼち遭遇することがあるようで、時間を少し置くと解決してくれるようです。参考 : 今年、遭遇したBigQueryのエラーログを愛でる
まずは登録などの準備
とりあえずアカウント登録をします。既に対応済みの方は次へスキップしてください。
無料トライアルをクリック。
「はい」を選択して続行します。
個人情報を入力して進みます。

入力が終わると上記のようなダイアログが出てきます。
書籍にも、無料トライアル分が終わった後は、承認するまで自動でサービスが止まったりすると書かれていたので、この辺りは安心して試せます。

プロジェクトの追加と切り替え
画面上部の「プロジェクトを選択」をクリックします。
ここでは、お試しということで、 test project という名前でプロジェクトを用意します。

右の方の + ボタンをクリックします。
作成したプロジェクトに切り替えます。

上部のプロジェクト表記部分が、今回作成したプロジェクト(test project)になっていることを確認します。
もし複数プロジェクトある場合などに、なっていなければ選択して切り替えます。
画面の左側に、以下のようにメニューが表示されていると思います。

下の方にスクロールすると、BigQueryのメニューがあると思うのでクリックします。
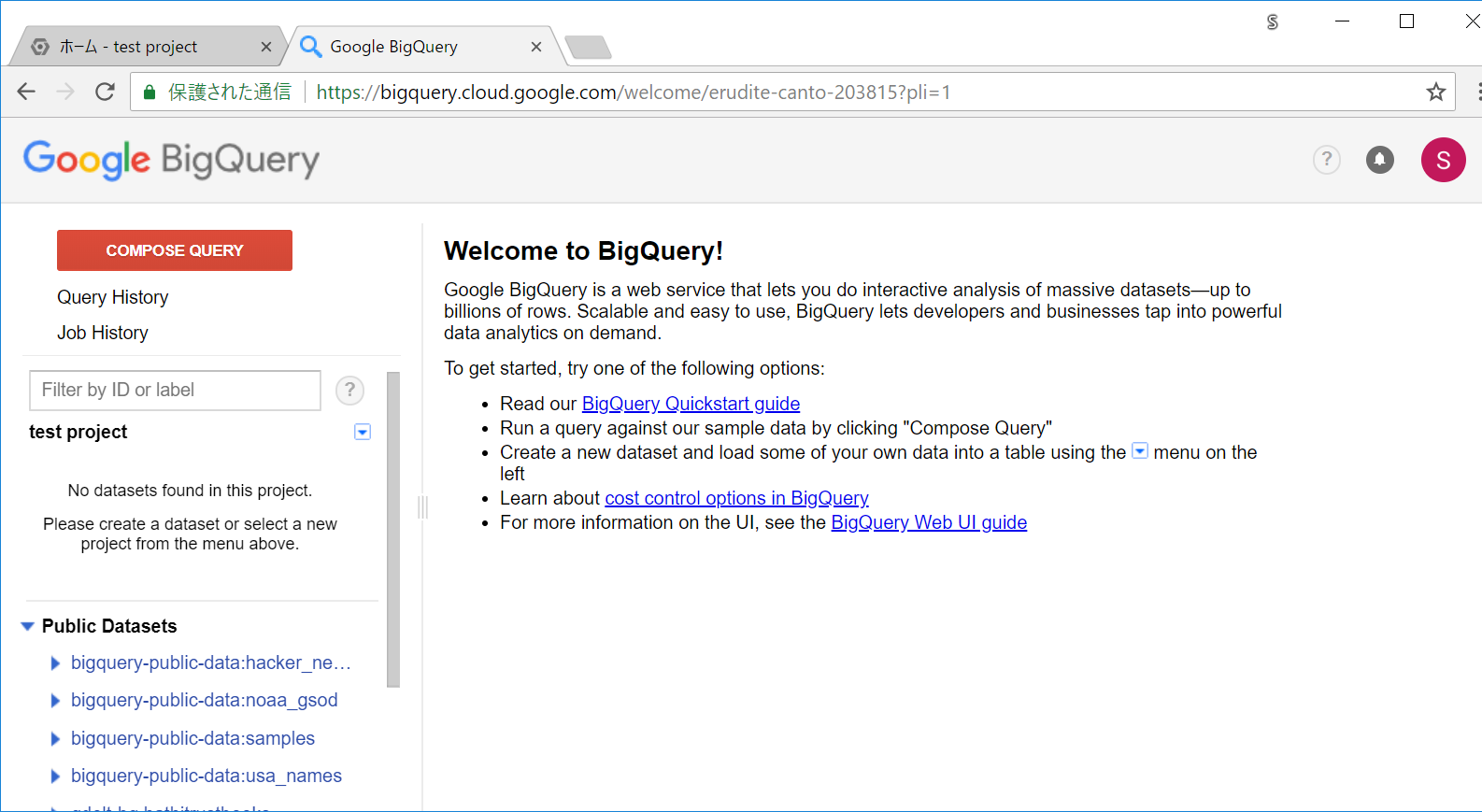
BigQueryの画面になりました。
試すためのデータセットとテーブルを作成する
作ったばかりのプロジェクトなので、まだテーブルなどがありません。テスト用に作成します。
ちなみに、BigQueryでは階層が「プロジェクト」→「データセット」→「テーブル」といった感じになっています。
MySQLでいうところの、データベースがデータセット、テーブルはそのままテーブル、というものに近い印象です。
各プロジェクトで、データのグループごとにデータセットを用意します。多くても特に不便にはならない(相互のアクセスなど)ので、データベースよりは多くのデータセットを用意して、管理しやすいようにグループ化しておくといいと思います。
左のメニューのプロジェクトの近くにある ▼ アイコンをクリックすると、データセット作成用のメニューが表示されるので、「Create new dataset」を選択します。
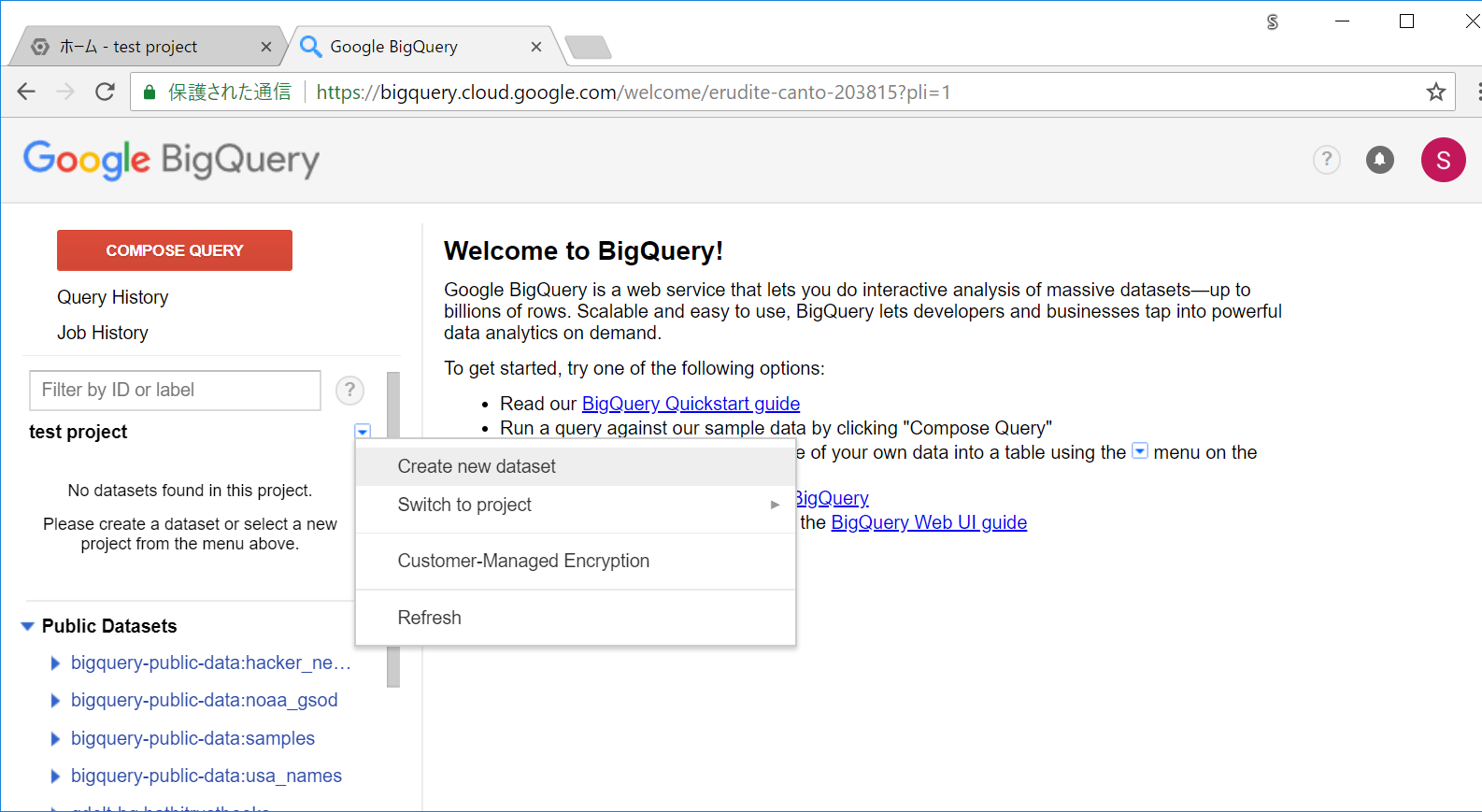
test_dataset という名前でデータセット名を設定します。
Data location は、最近アジアが追加されたようなので、最初そちらを選択してみましたが、その後謎のエラーに見舞われたため、今回は昔からあるUSを選択しました。(一時的なエラーだった印象も・・)
Data expiration はNeverを選択します。データ保存後一定期間後に削除して欲しい場合はNever以外を選択します。(そちらはまだ使ったことがありません・・)
データセットが追加されました。
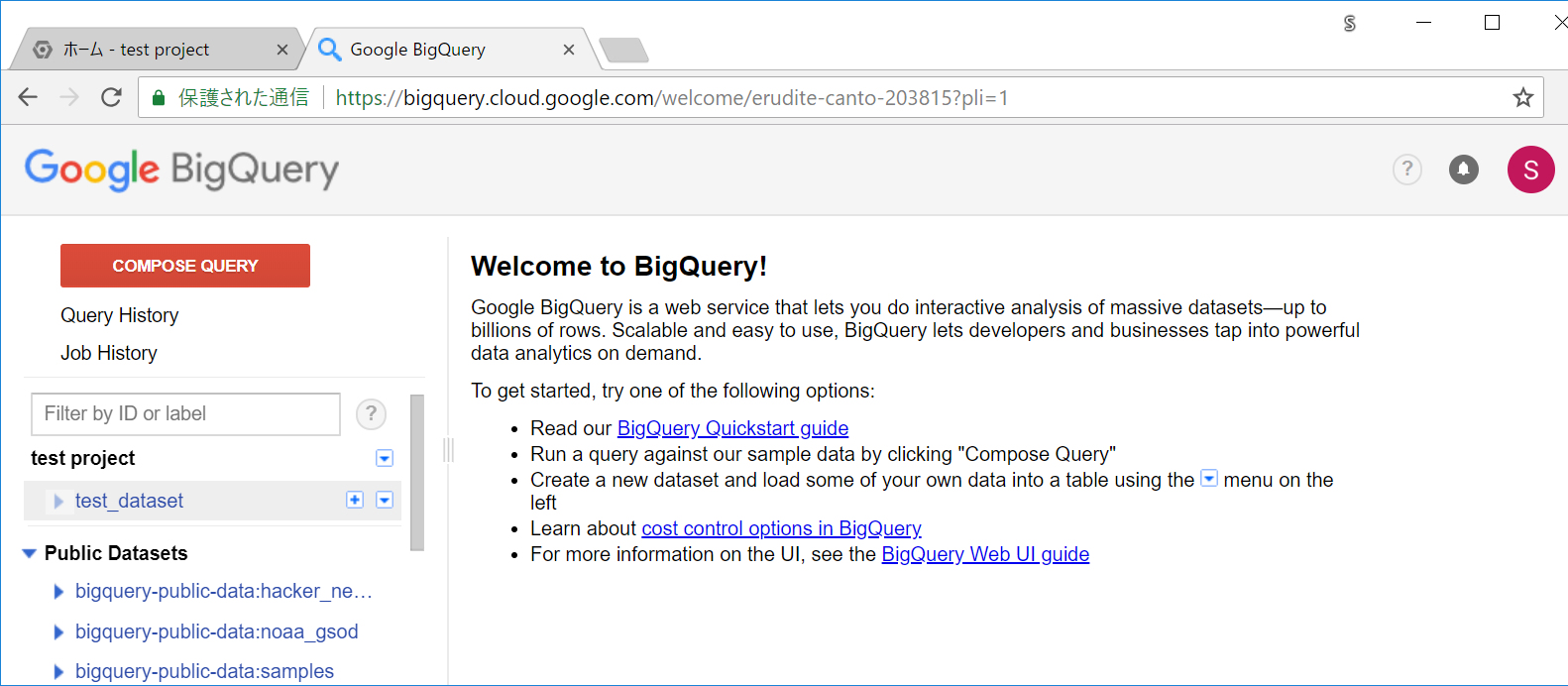
追加したデータセット(test_dataset)の右の方にある ▼ アイコンを押して、Create new tableをクリックしてテーブルを追加します。
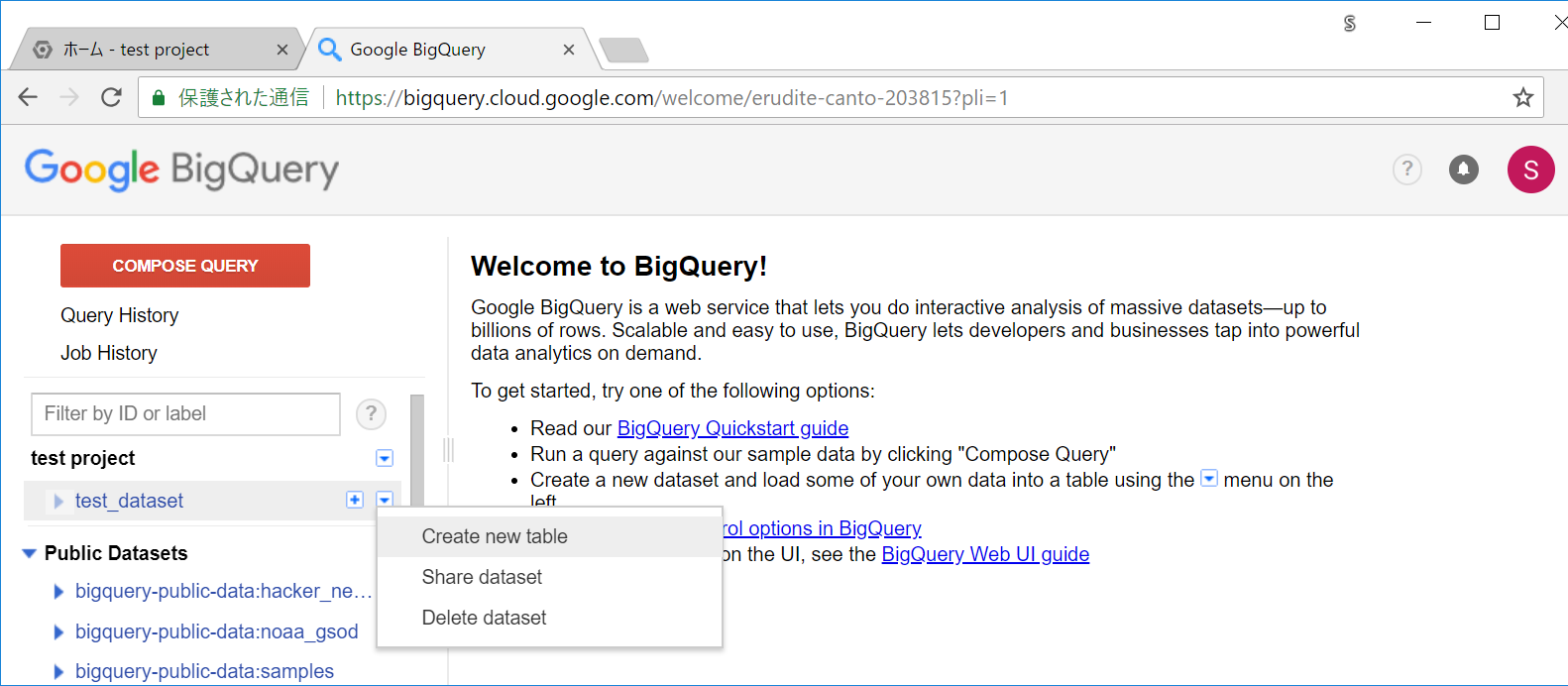
以下のようなテーブル作成の画面になります。
テーブル作成には、以下の方法が主にあります。
- 手動でスキーマを定義していく。
- CSVなどのファイルを読み込んで、スキーマ定義はそれらのCSVから判定して自動で作ってもらう。
とりあえず最初なので、シンプルな2の方を使います。
読み込み用のCSVを用意します。以下のCSVのデータを fruit_data.csv といった名前で保存してください。
[fruit_data.csv]
id,date,name,price
1,2018-05-01,apple,100
2,2018-05-02,orange,120
3,2018-05-03,melon,300

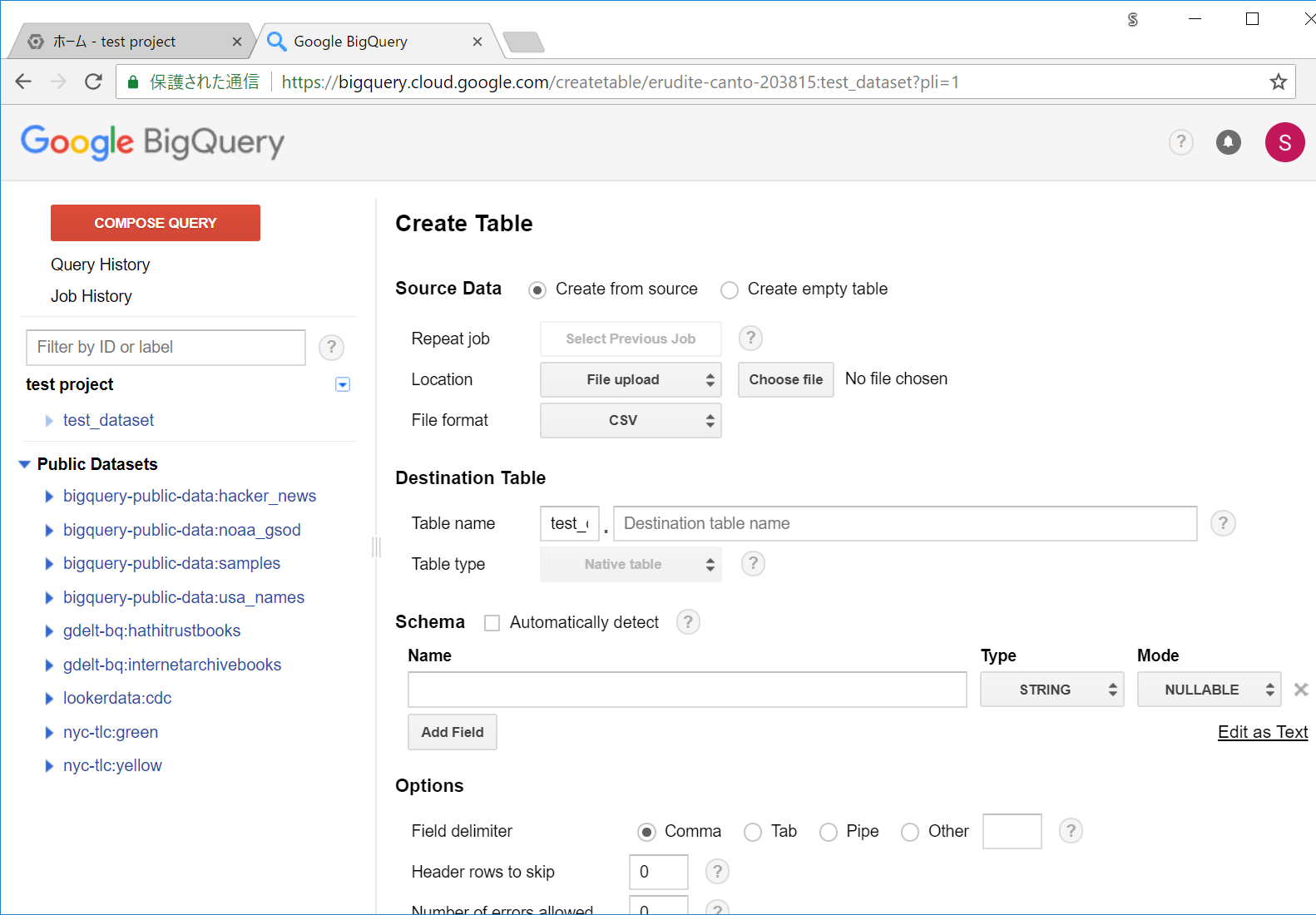
Source Data に Create from source、Location に File uploadが選択されている状態で、Choose fileボタンを押すとファイル選択ダイアログが出るので先ほどのCSVを選択します。

テーブル名を決めます。今回は、test_tableという名前でTable nameのフォームに入力します。
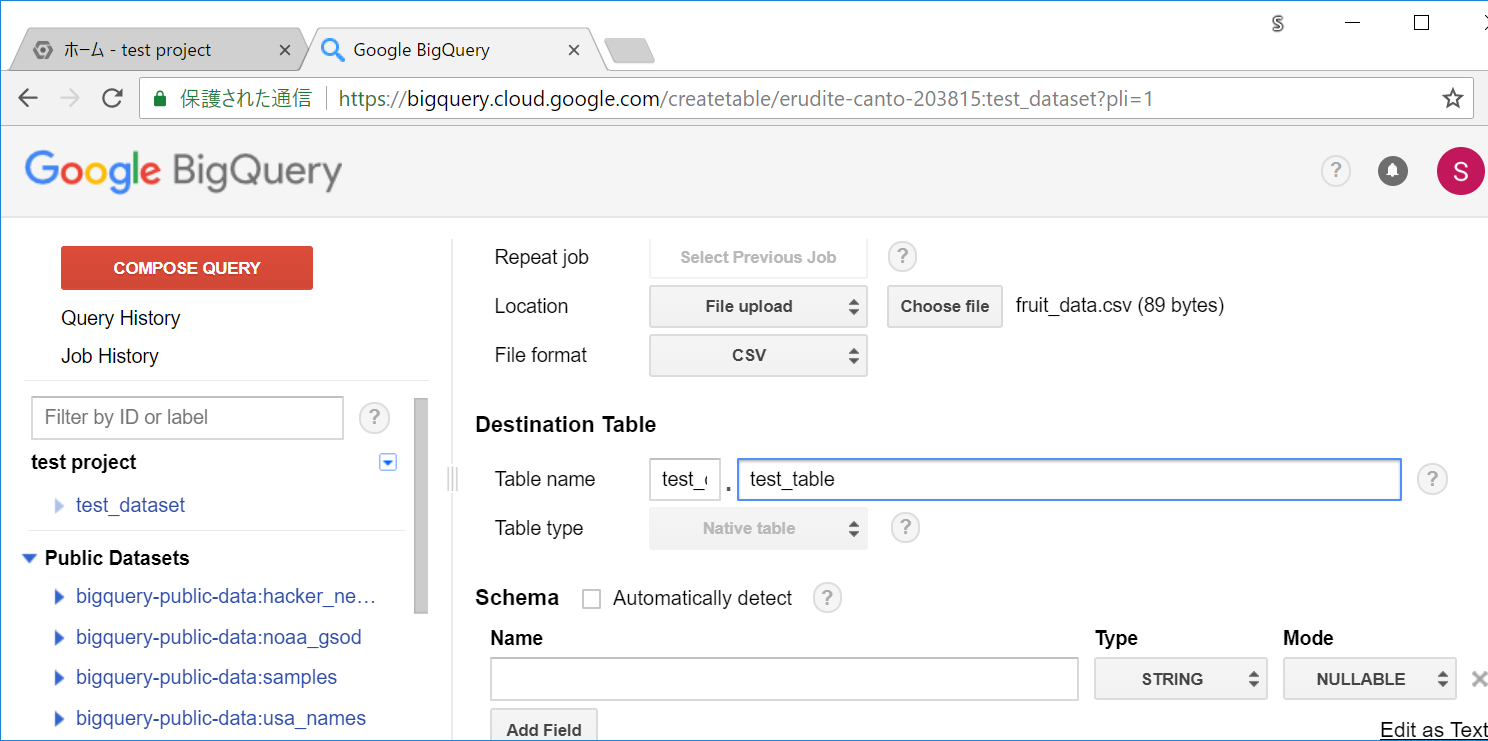
Schema の部分の Automatically detect にチェックを入れると、CSVの構造に応じて、テーブルのスキーマを自動で判別してくれるので、今回はチェックを入れます。
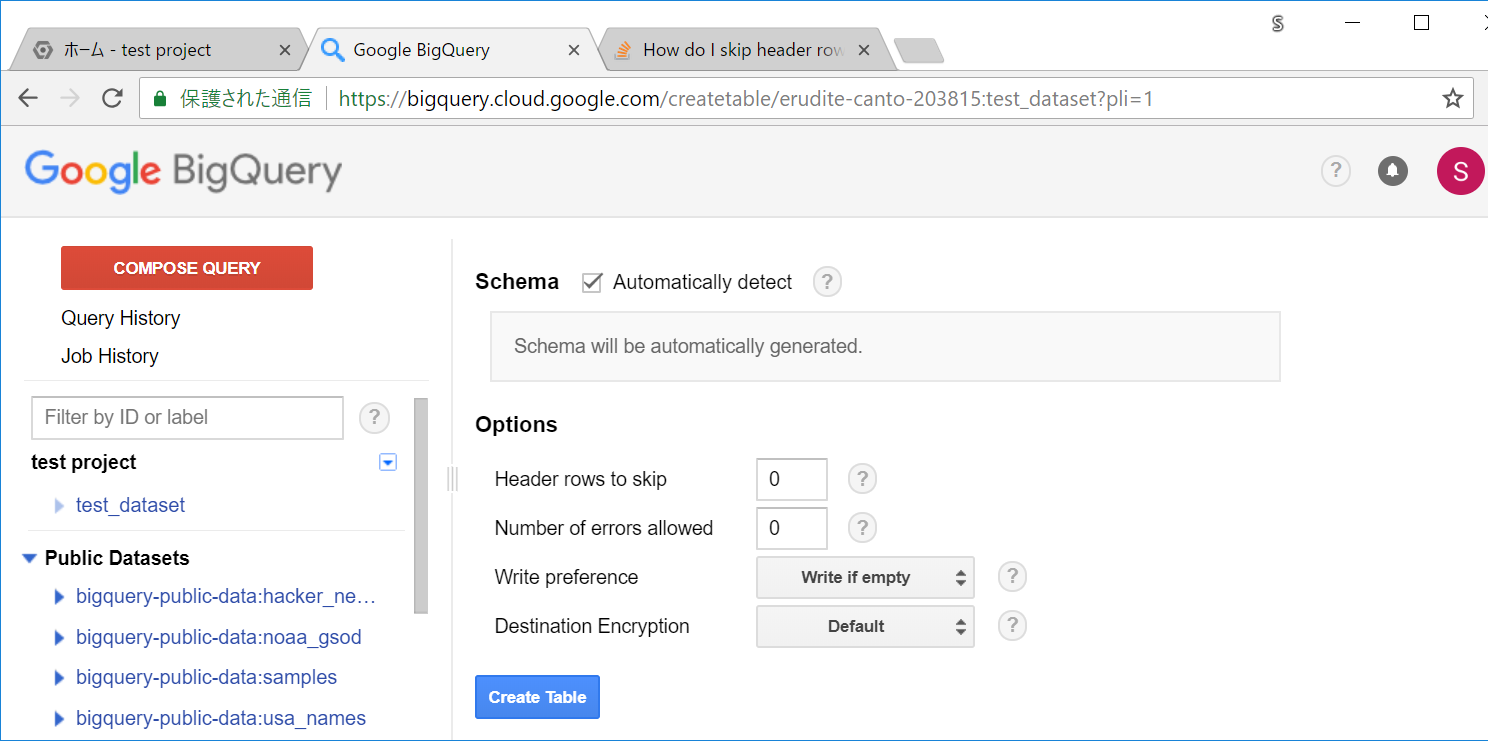
他の設定はそのまま、Create Tableを押します。
数秒待つと、テーブルの作成が完了します。左のメニューから、作成されたテーブルのリンクをクリックします。

以下のようなスキーマの画面になります。整数値型や日付、文字列などが認識できていることが分かります。
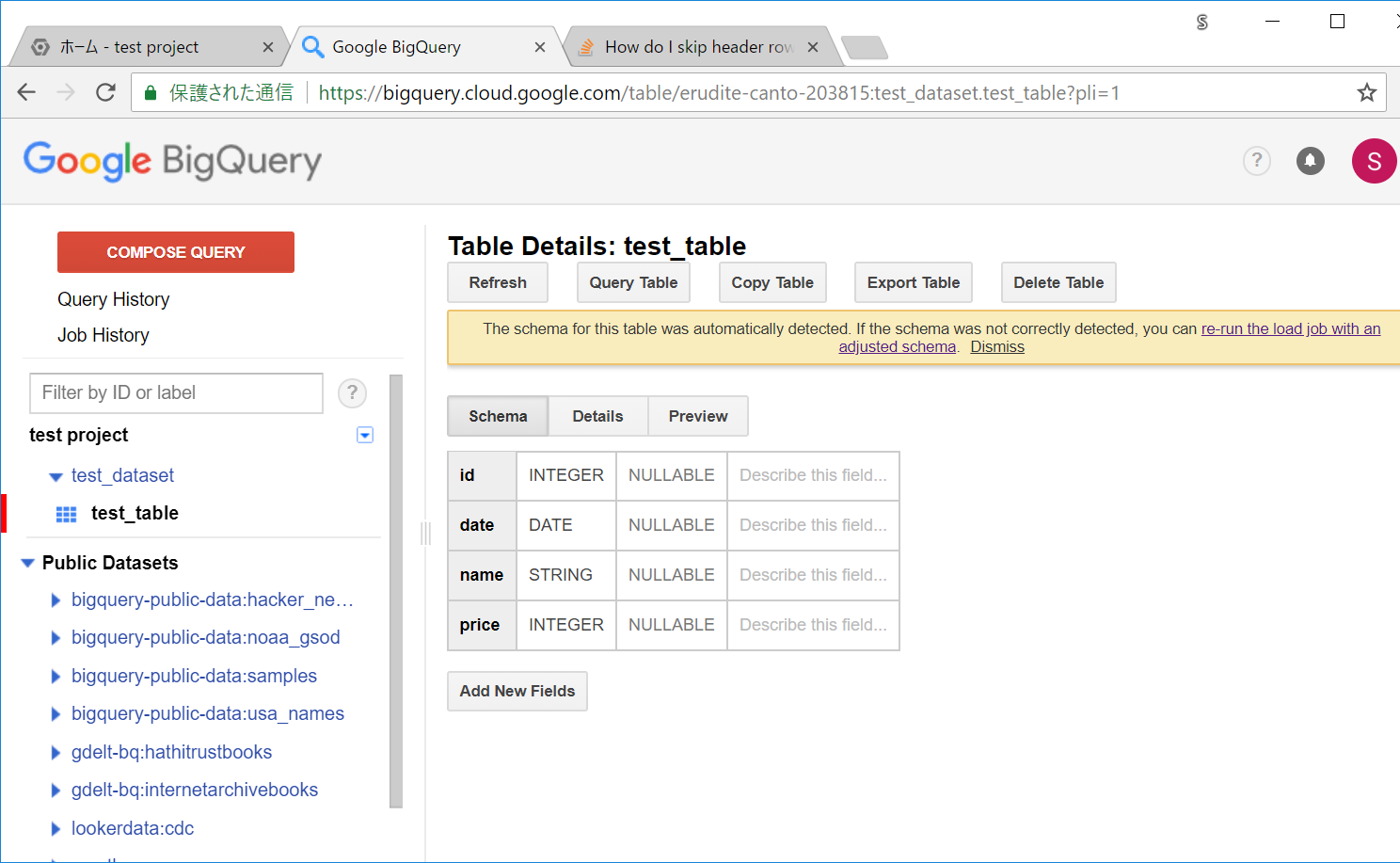
Previewボタンを押すと、入っているデータの一部が確認できます。
なお、BigQueryではSELECTなどのクエリでコストがかかりますが、このプレビューは無料で行えます。
ここまでで一旦準備ができたので、TIPSに移ります。
TIPS 1 : クエリ実行前に必要なサイズを確認する
テーブルの画面で、Query Table ボタンを押して対象テーブルに対してのクエリ実行画面に移ります。
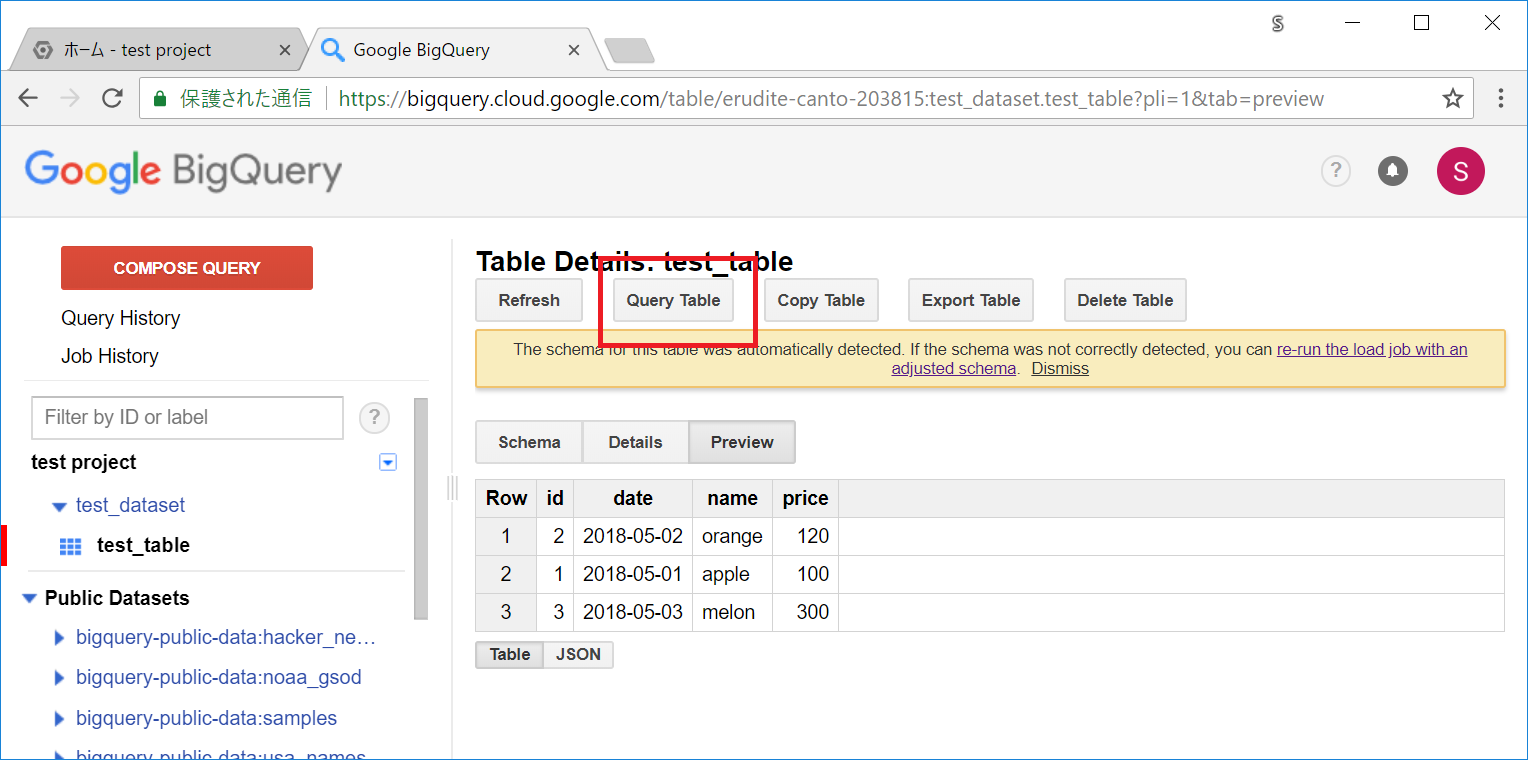
クエリ入力画面になります。
まずは以下のような、シンプルなクエリを入力してみます。
SELECT id, name FROM [test_dataset.test_table] LIMIT 3
右のほうにある、! もしくは チェック記号のアイコンを押すと、入力したクエリのチェックがされるようになるので、クリックします。(Open Validator)

※クエリにエラーがある場合は!マークのアイコンになります。
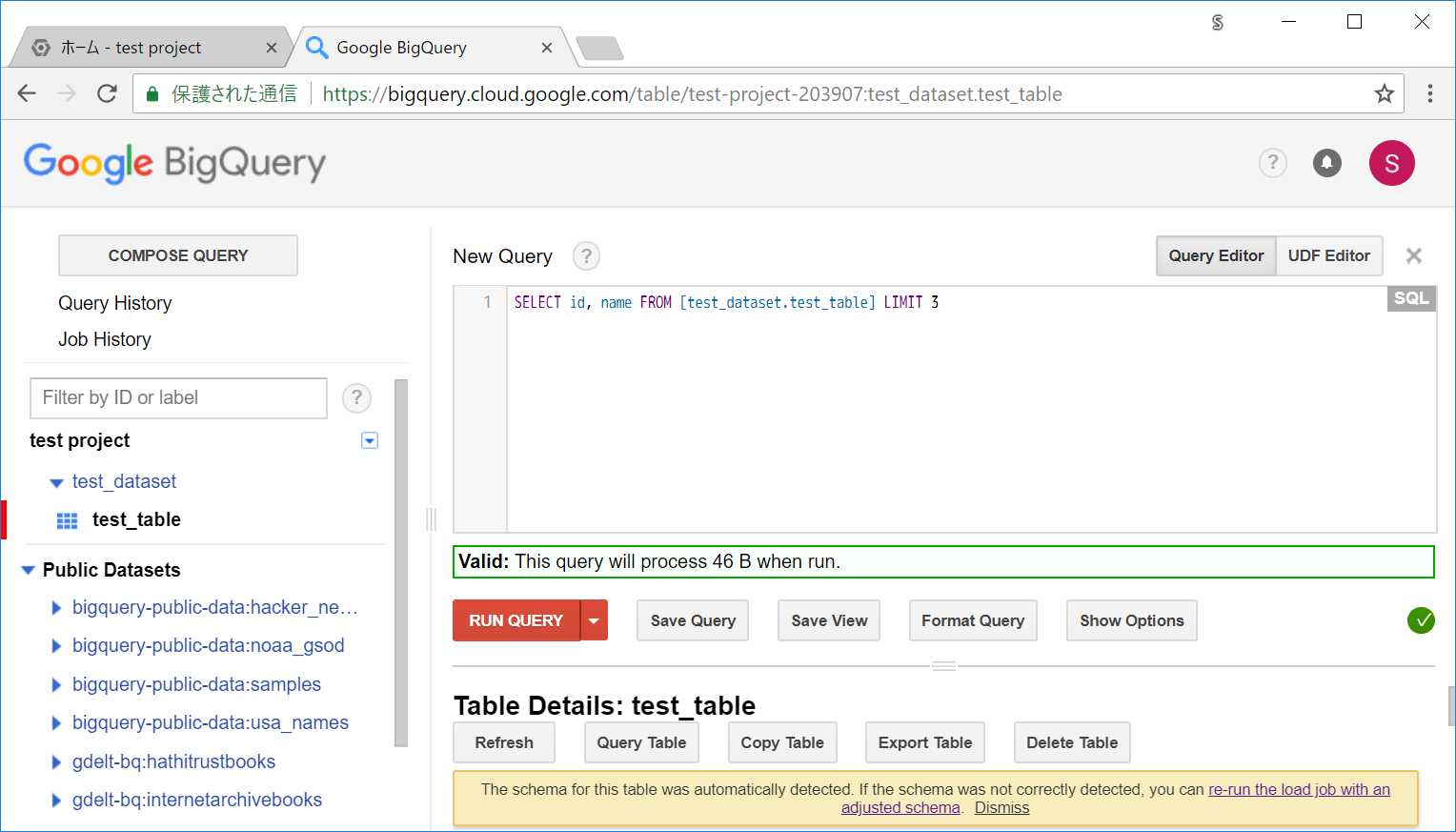
Valid: This query will process 46 B when run.
そうすると上記のように、クエリ内容に応じたメッセージが表示されます。クエリにエラーがなければそのクエリでどのくらいのバイト数が必要になるのかが表示され、エラーがある場合はそのエラーが表示されます。
BigQueryではクエリによるサイズによってコストがかかるので、この機能を使うことで事前に必要バイト数を見ることができ、うっかり膨大なサイズが必要になるクエリを実行してしまう、ということを高い確率で避けることができます
書籍でも、基本てきにこのチェックのUIは常に表示しておくことが好ましいと書かれています。便利なので積極的に使っていきましょう。
TIPS 2 : SELECTでアスタリスクは使わない
前述のとおり、クエリのサイズがコストに絡んできます。
不要なカラムの指定があるとその分サイズが膨れ上がるので、SELECTを実行する際には必要最低限のカラムに制限しましょう。全カラムを対象とするアスタリスク指定も推奨されていません。
下記のように、カラムの指定によって必要バイト数が変動していることが確認できます。
SELECT * FROM [test_dataset.test_table] LIMIT 3
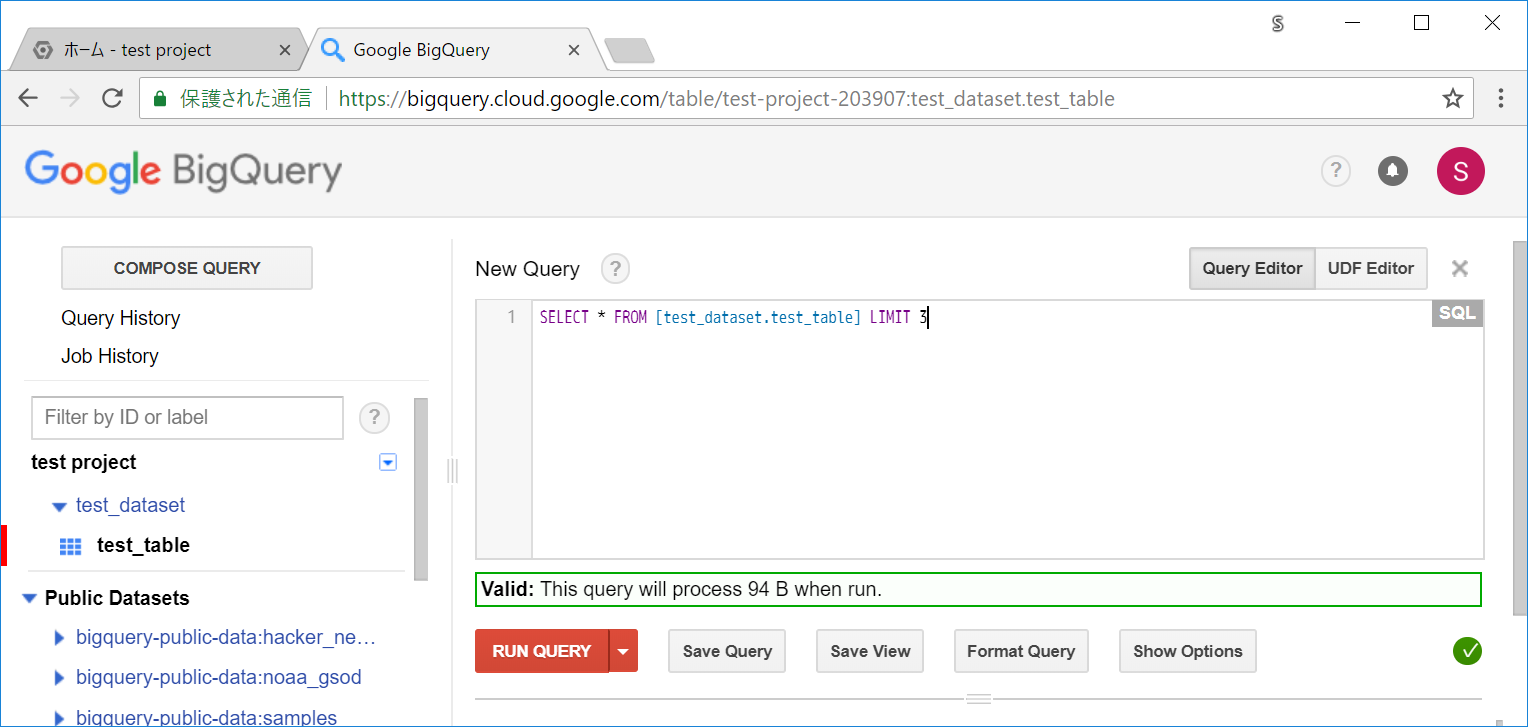
Valid: This query will process 94 B when run.
TIPS 3 : WHERE や LIMIT などの指定ではサイズは基本減らない
BigQueryは、後述するパーティションテーブルなどを利用しない限り、WHEREやLIMITなどで対象の行を絞っても必要サイズは減りません。実際に試してみます。
LIMIT 指定する場合 :
SELECT id, name FROM [test_dataset.test_table] LIMIT 1
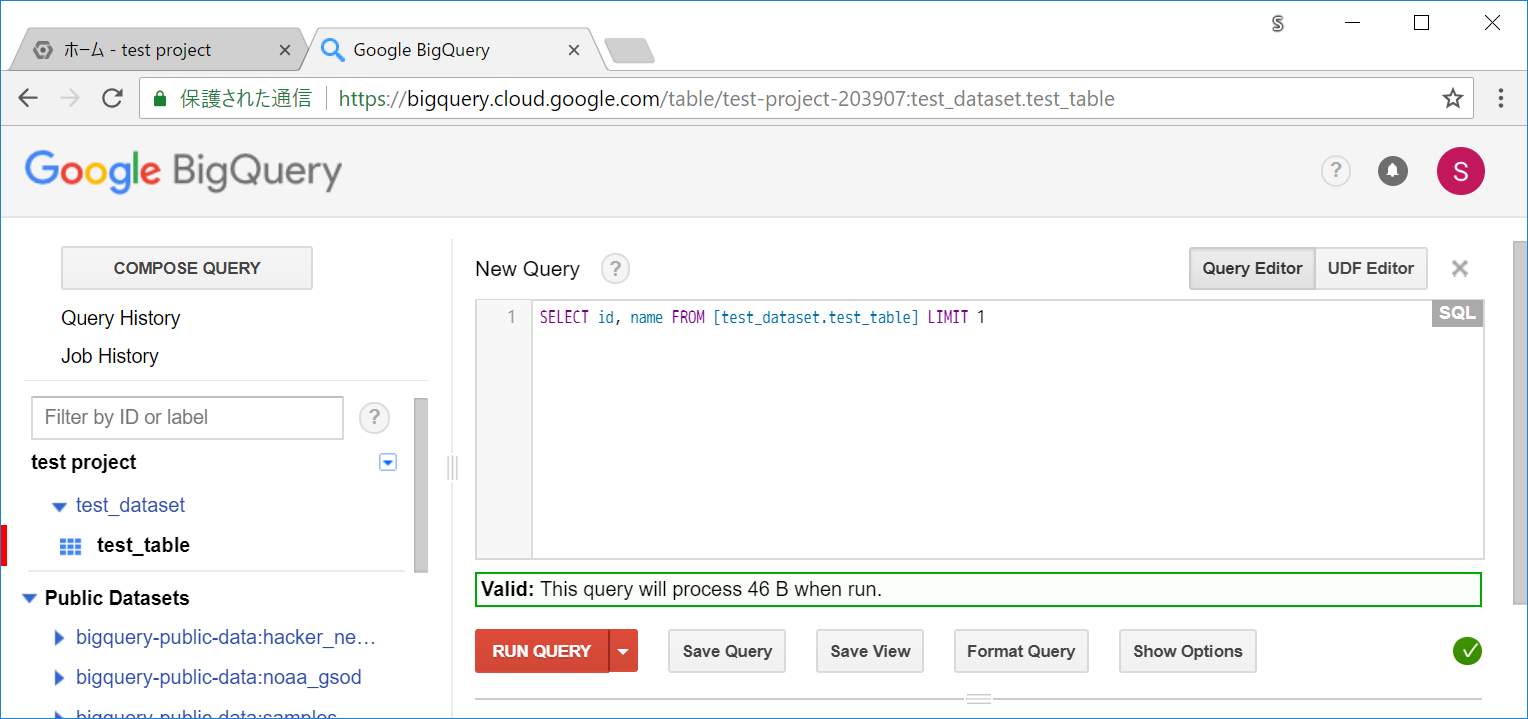
Valid: This query will process 46 B when run.
LIMIT を3にしても変わらないことが確認できます。(このテーブルは3行データを格納しています。)
SELECT id, name FROM [test_dataset.test_table] LIMIT 3
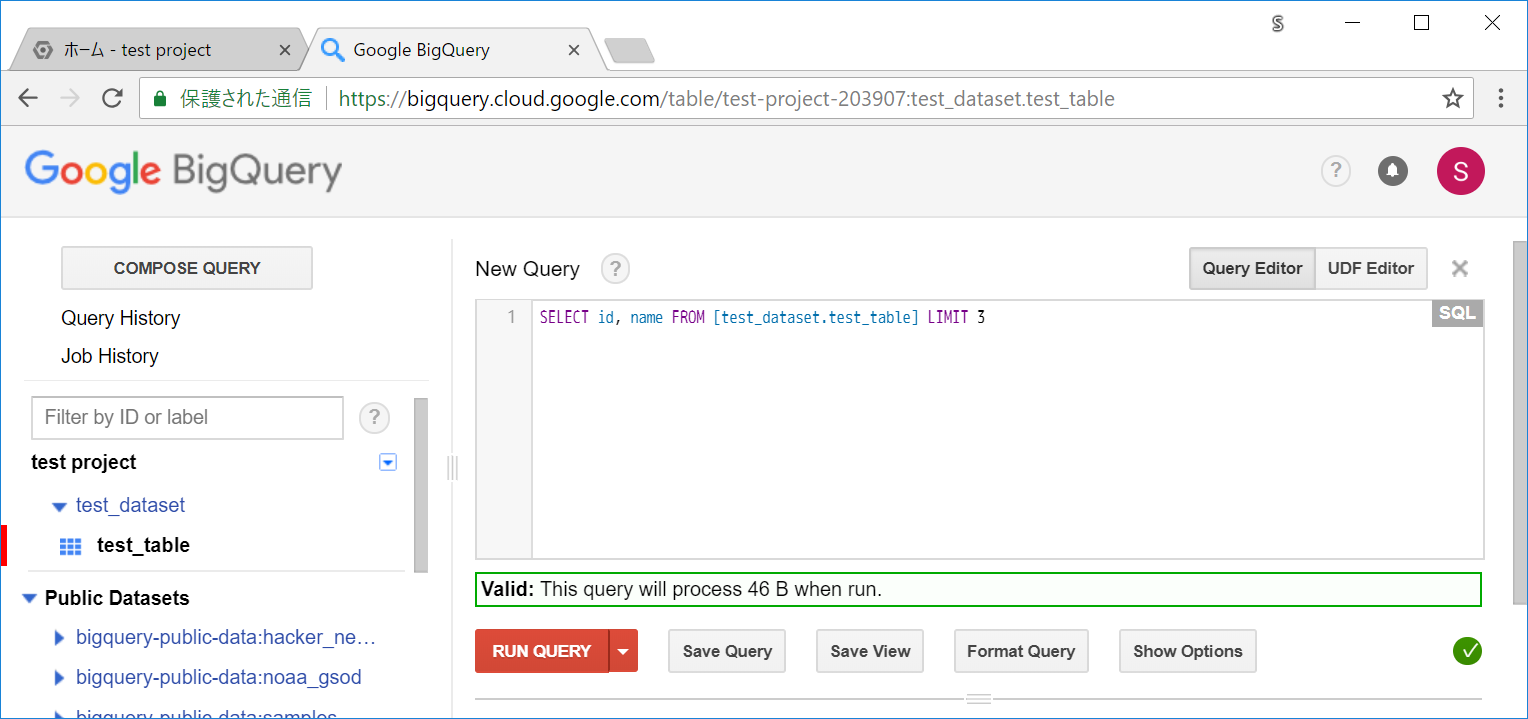
Valid: This query will process 46 B when run.
WHERE に関しても同様です。1行しか、該当する行がない条件でも必要サイズは変わっていません。
SELECT id, name FROM [test_dataset.test_table] WHERE id = 2 LIMIT 3
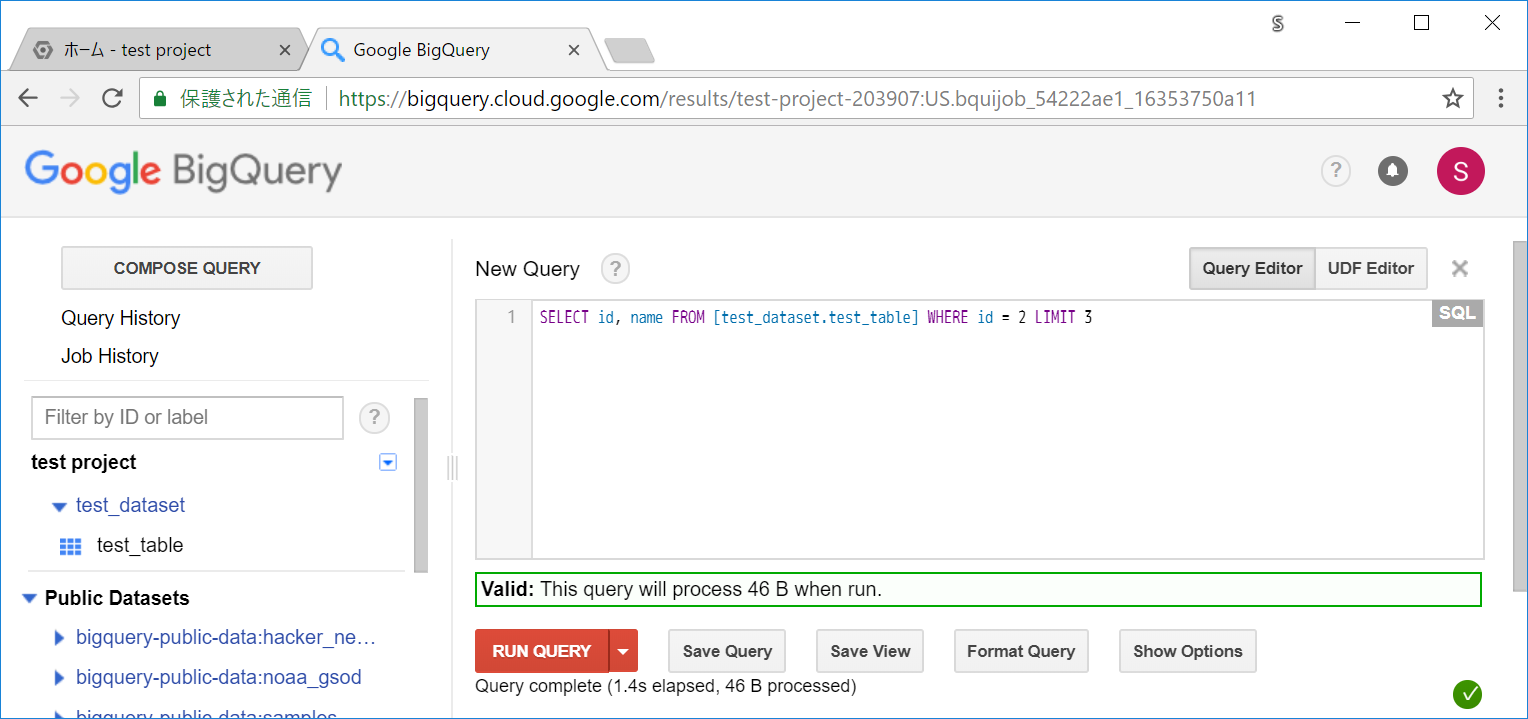
Valid: This query will process 46 B when run.
これは、BigQueryが「指定のテーブル・指定のカラムを一旦すべて読み込んでから、条件などによるフィルターを行う」という挙動によります。(読み込み自体はGoogleの大量のリソースによって一気に実行され非常に高速に処理されるため、結果的に膨大なデータでの高速な処理を実現しています。そのため、BigQueryではインデックスを貼ったりといった作業が不要になっています)
MySQLとは結構挙動が異なるので、MySQL感覚で「WHEREやLIMITでうまく制限しているから大丈夫だよね」といった風にデータサイズも確認せずに使ってしまうと悲しい結果になる可能性があります。
TIPS 4 : 予算とアラートを設定する
BigQueryでは、使いすぎやクエリミスなどによる高額請求を避けるために、予算の設定とアラートを設定することができます。
書籍によると、予算を超えた場合はそれ以上の請求が発生しないようにサービスが停止するそうです。(そこまで使ったことがないため、将来予算超過を経験したら追記します)
プロジェクト単位と、全体のそれぞれで予算を設定しておくことが推奨されています。
たとえば、部署ごとにプロジェクトを分けたり、非エンジニアの、プランナーやディレクターの方達のプロジェクトとエンジニア側でcronなどでのアクセスでプロジェクトを分けたりすることで、別の部署に予算分を大きく使われて喧嘩になったり、プランナーの方が重いクエリを投げて、分析基盤のcronなどで支障が出る、といったことを避けることができます。
また、全体の予算設定を行っておくことで、会社全体で確実にこの金額以下に収める、といったことができて安心感が増します。
予算を設定しておくことで、エンジニア以外の方がデータサイズを減らすことに意識を向けてくれる、というメリットもあるかもしれません。(迂闊なクエリを投げると自分の部署の首を絞める形になるため)
cronなどで扱うプロジェクトでは、「明らかに設定やクエリミスをしなければ超えない」というような、結構余裕をもった予算を設定しておくなど調整してください。(ある程度、アクセスが増えたりログが増えた場合などでも、特に問題にならないように)
(パーティションテーブルの設定がしたと思ったらうまくできていなかった、などのケースを避けるように)
実際に設定してみます。
GCPの画面の左のメニューのお支払いをクリックします。

予算とアラート のメニューをクリックします。
予算を作成 ボタンをクリックします。

対象とするプロジェクトや予算金額・アラートの通知が飛ぶ閾値指定などができる画面になります。
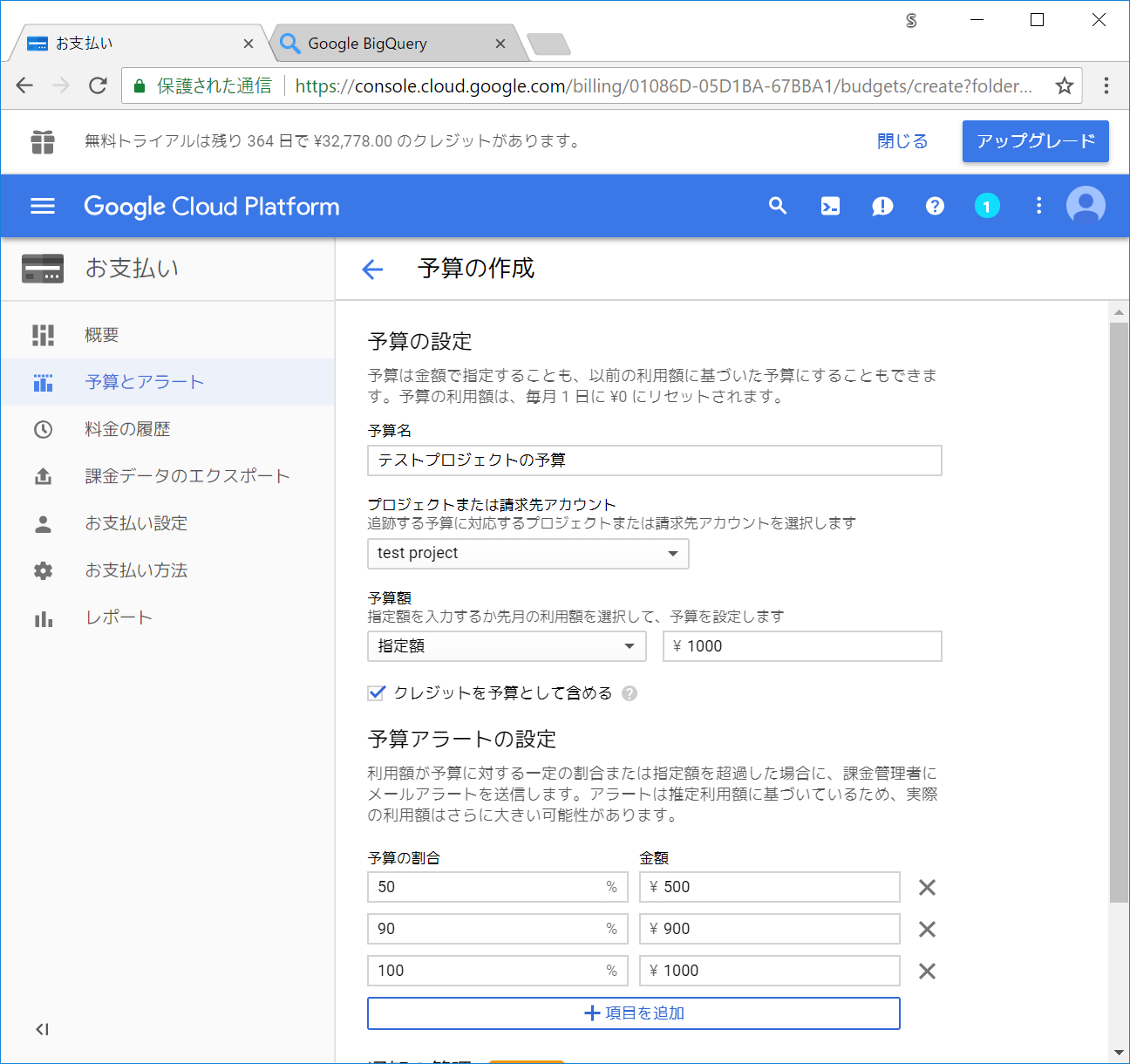
プロジェクトまたは請求先アカウント の個所で、個別のプロジェクトを選択したり、もしくは会社全体での予算設定であれば請求先アカウントを選択します。
設定が終わったら保存ボタンをクリックします。
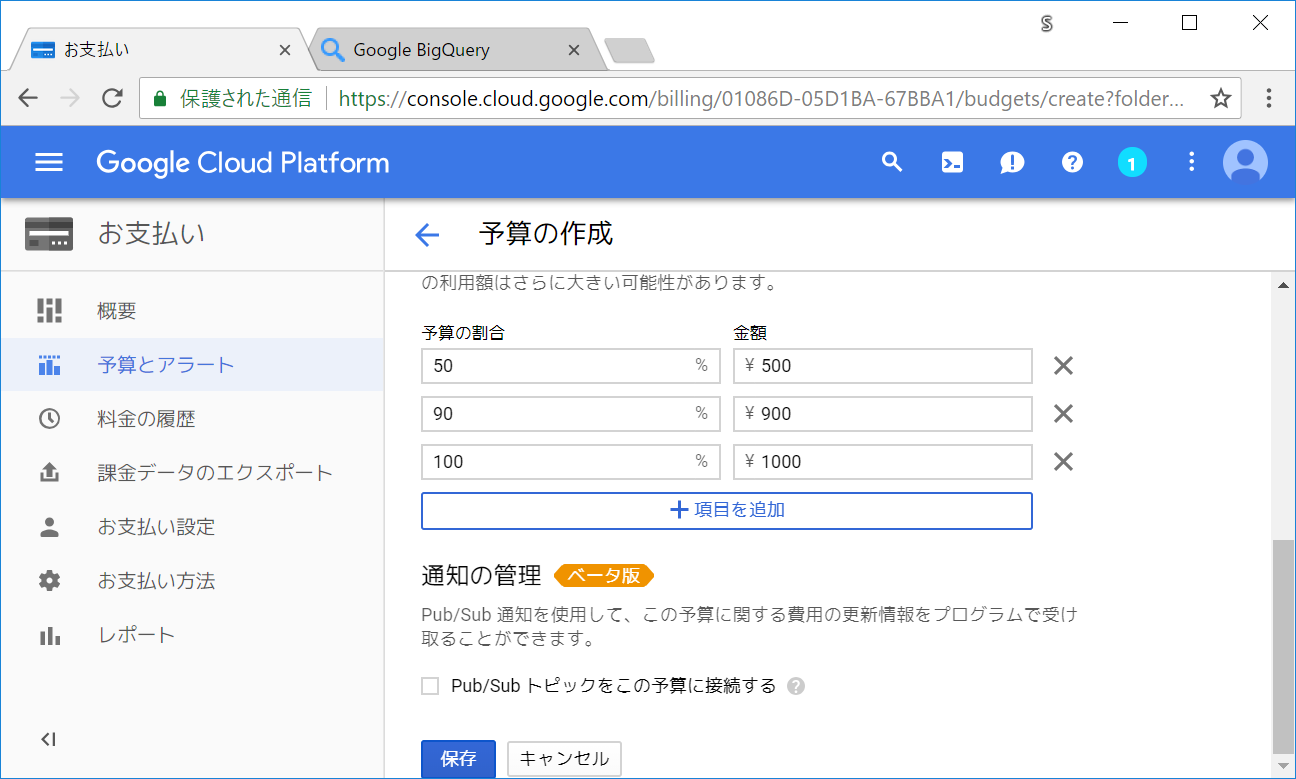
設定が追加されました。
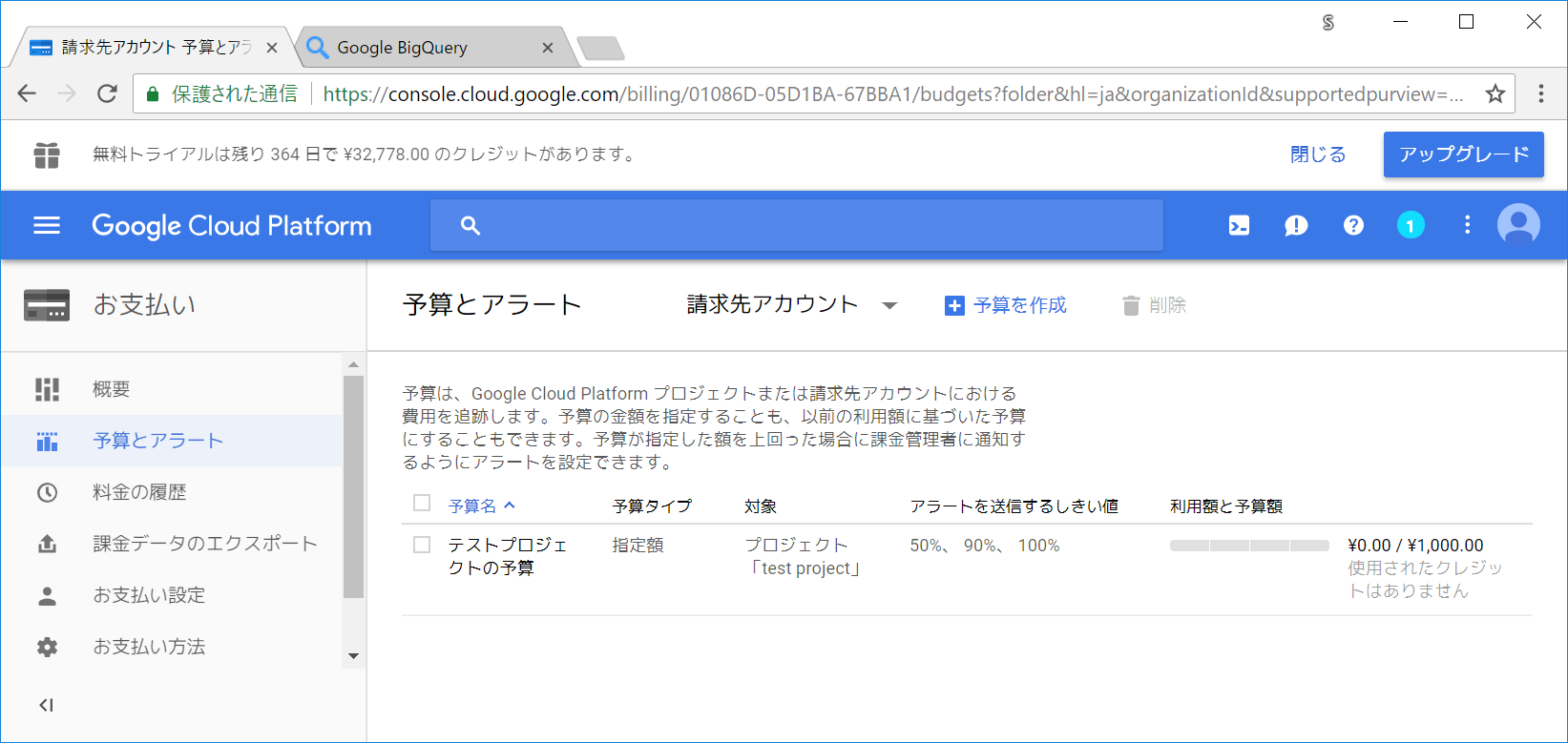
※利用額の個所は、リアルタイムではなく、反映にある程度時間がかかるかもしれません。
TIPS 5 : SDKなどでも、dry_runのオプションを指定することで、必要なサイズ数が確認できる
前述のweb上でクエリを実行するケースでは、クエリ実行前に必要なデータサイズを表示してくれる機能がありました。
しかしながら、普段の業務ではcronでPythonなどのコードからデータを扱ったり、フロント環境(JupyterだったりTableauだったり)でアドホックに集計を行ったりと、web上での操作だけでは完結せず、SDKやAPIを利用する機会が多く発生します。
それらSDK経由などでも、web上でやったように実行前に必要なサイズを確認する術が用意されています。(dry_runオプション)
SDKでのdry_runオプションの使い方
SDK周りの設定含め、見ていきましょう。(インストール周りは今触れる環境のWindowsメインで書いてあります。MacやUbuntuなどの方はお手数ですがグーグルなどで検索ください。)
Windows 用のクイックスタートにアクセスします。
「Google Cloud SDK のインストーラをダウンロードします。」のリンクをクリックします。
インストーラーを起動して、規約などに同意していきます。
以下の設定画面で出るので、「Bundled Python」「Cloud Tools for PowerShell」にチェックが入っている状態で次に進みます。

※内部でPython2.7が使われているので、Pythonが必要になります。基本的にBundled Pythonにチェックが入っていた方が余計な環境依存のエラーなどに悩まされないと思われます。
※Python2.7の都合なのか、Cloud Tools for PowerShell以外を使った際にエンコーディング関係でエラーになったことがあるので、基本的にこちらもチェックが入っていると楽です。
※Beta Commandsは、まだβ版の機能となります。将来実装される機能を試したい、といったことがなければ、エラーなどに遭遇するかもしれないためチェックを外したままでいいと思われます。
少し時間がかかりますが、しばらく待っているとインストールが終わります。

インストール後、コマンドプロンプトが立ち上がりますが、前述の通り、エンコーディングの都合、エラーになる条件があったので、コマンドプロンプトは終了して、別途スタートメニューやデスクトップショートかっとから、Cloud Tools for PowerShellを起動します。
PowerShell :
PowerShell上で、まずはプロジェクト選択などのために初期化のコマンドを実行する必要があります。
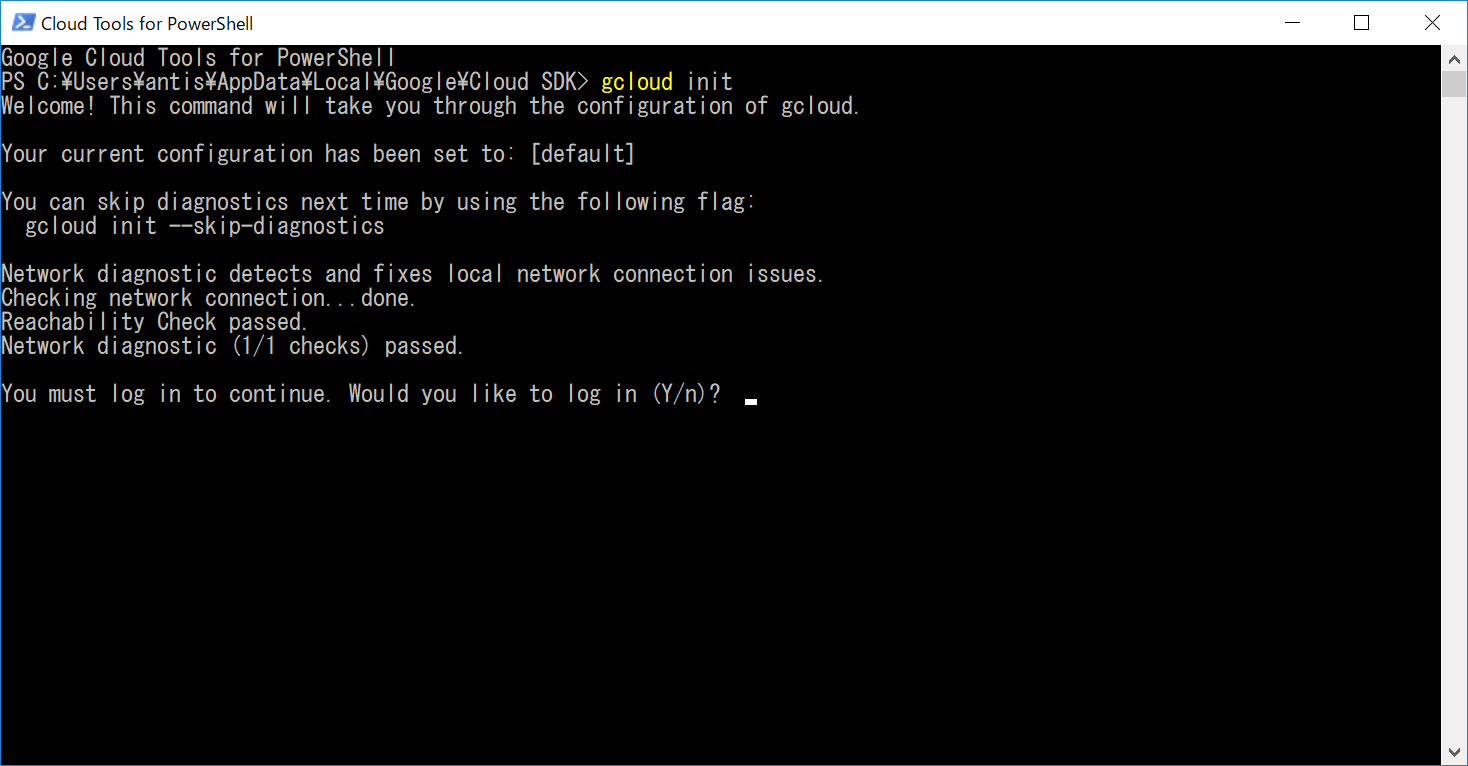
$ gcloud init
You must log in to continue. Would you like to log in (Y/n)?
といったように聞かれるので、Yを入力します。
ブラウザでページが開かれ、SDKでのログイン用のアカウント選択画面が表示されます。
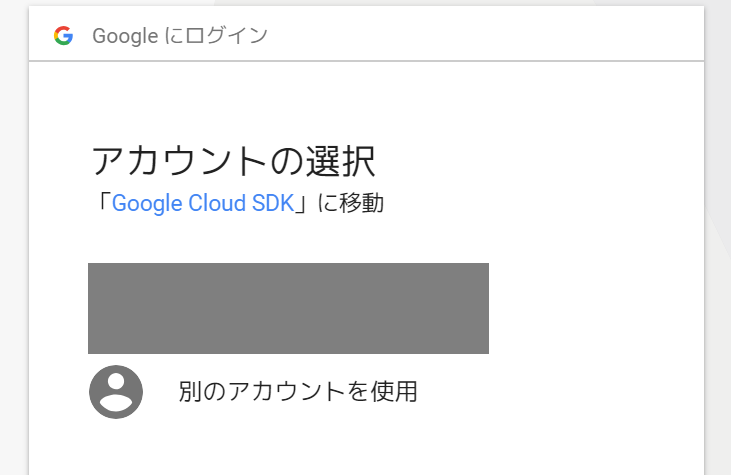
SDKを使う上での権限の確認が出てきますので許可します。
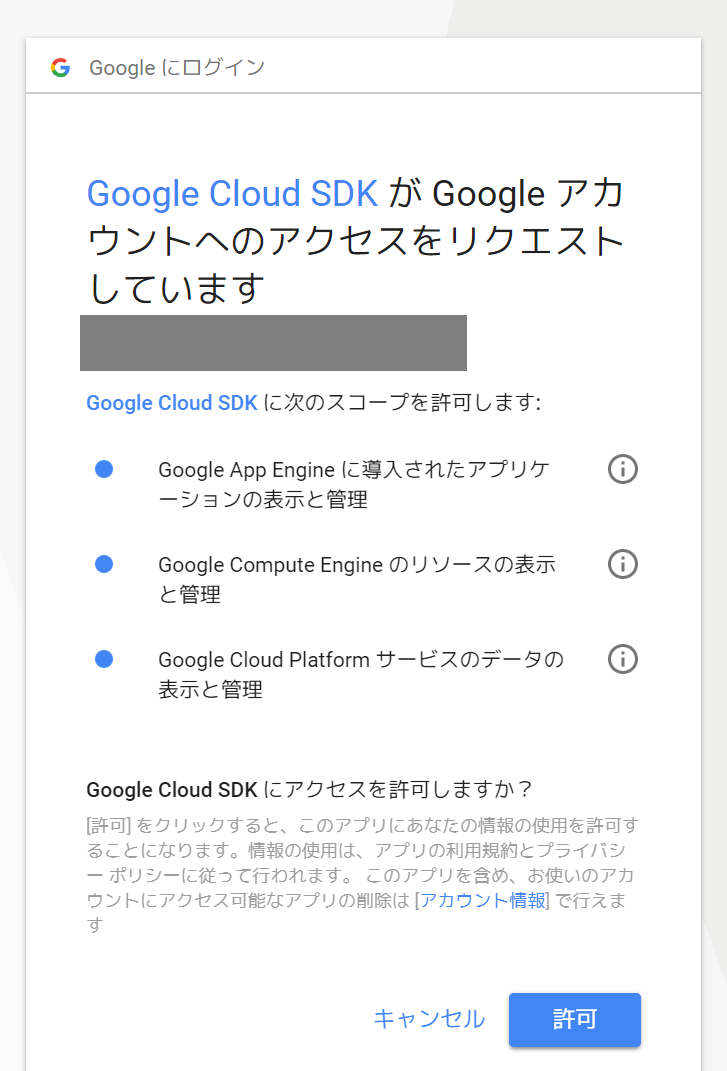
認証され、SDKが使えるようになります。
認証後PowerShellに戻ると、以下のようなプロジェクトを選択してください、というメッセージが表示されます。

番号もしくはプロジェクト名を指定していきます。番号がシンプルなので、今回は上記のスクショのとおり3を入力します。(人によって、ほかのプロジェクトの有無によって番号は異なります)
また、web上で指定したプロジェクト名と比較すると、番号が付与されていたりしますが、他の人との重複を避けるためのものなので気にせず進めます。
場合によってはデフォルトリージョンの選択が求められる?かもしれません。その場合日本に近いリージョンを選択するなどの対応をしてください。(Compute Engine APIを有効化していると出る模様?)
正常に使えるか、試しに情報表示用のコマンドを実行してみましょう。
$ gcloud info
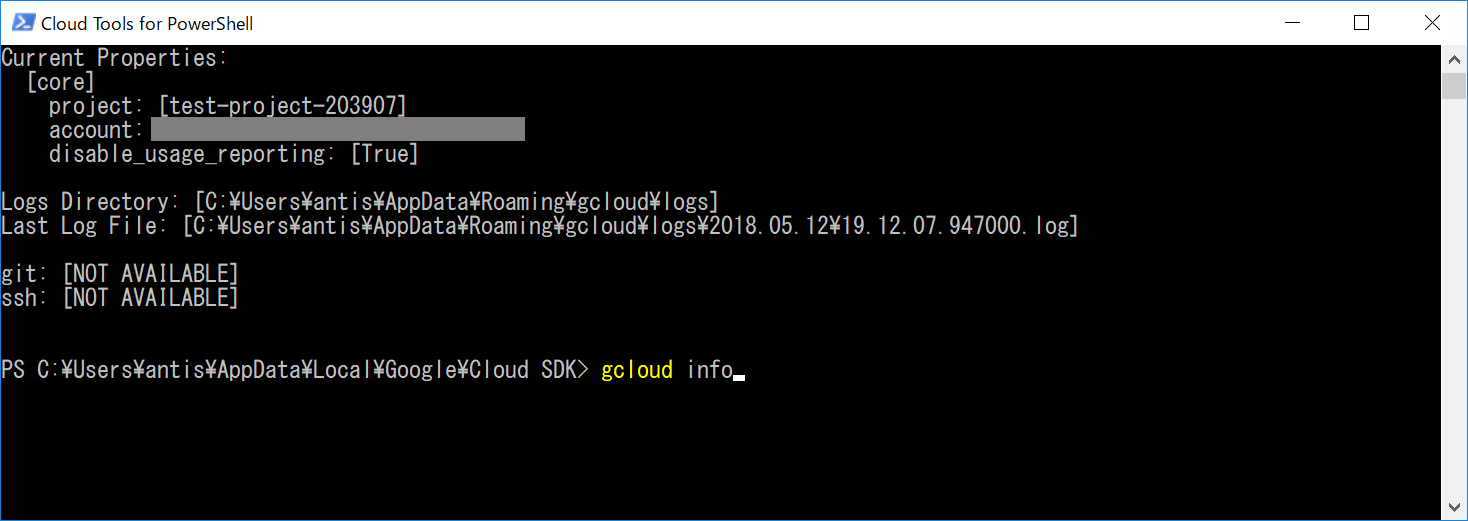
選択しているプロジェクト情報などが表示されます。(選択した、テスト用に作成したプロジェクトが表示されていることを確認してください。)
これで、SDKを使う準備が整いました。
PowerShell上で、bqコマンドでBigQueryに対してクエリを実行することができます。
以下のように書きます。
$ bq query "クエリ内容"
シンプルなSELECT文を試してみましょう。
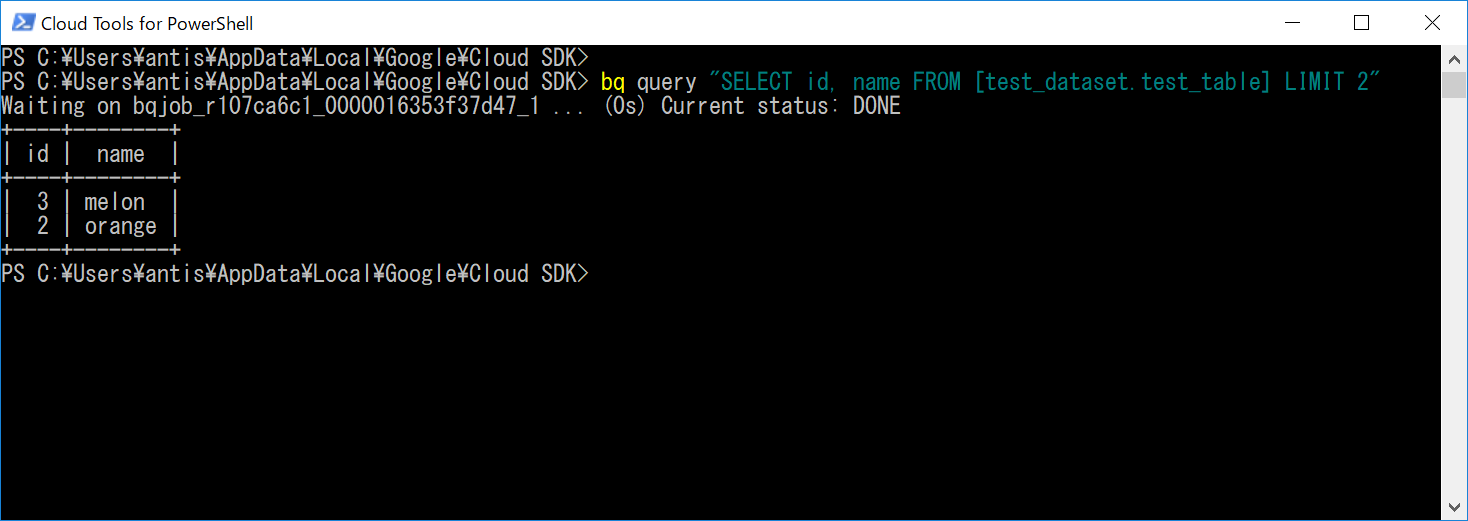
$ bq query "SELECT id, name FROM [test_dataset.test_table] LIMIT 2"
クエリ結果が表示されます。
本題の、dry_runオプションを使います。使い方は簡単で、コマンドにdry_runオプションを追加するだけです。
$ bq query --dry_run "SELECT id, name FROM [test_dataset.test_table] LIMIT 2"
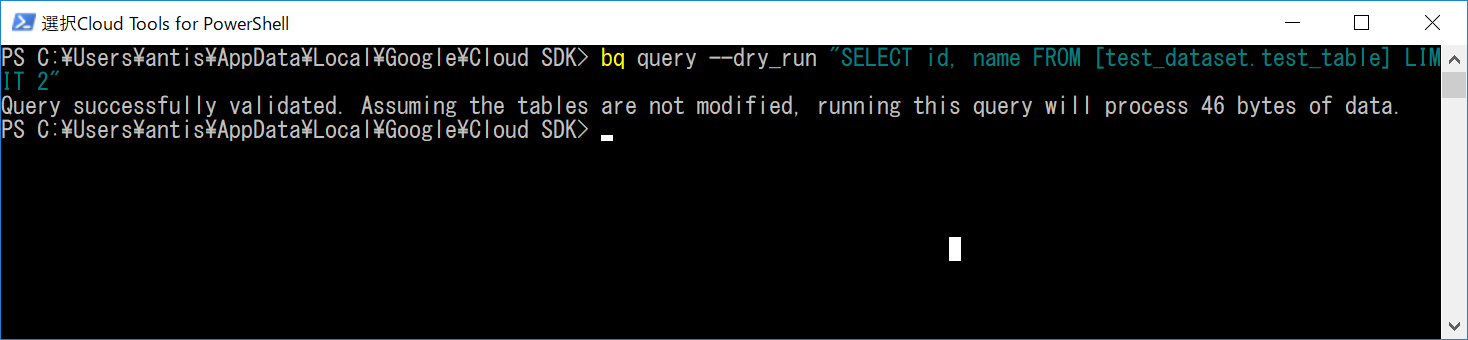
先ほどのように各行が表示されるのではなく、「クエリにエラーは無いですよ」「必要なサイズは〇〇バイトですよ」といったメッセージを表示してくれました。このコマンドは、通常のクエリとは異なりコストはかかりません。
Query successfully validated. Assuming the tables are not modified, running this query will process 46 bytes of data.
これで、SDK上からコマンドでもクエリが通るかどうか、必要なサイズがどのくらいか確認できるようになりました。webの時と同様、実行前になるべく実行したり、日々のクエリの事前の自動チェックなどで使えると思います。
APIでのdry_runオプションの使い方(Python)
次に、APIを利用して、Pythonからdry_runオプションを含めて実行する方法を見ていきます。
なお、残念ながらpandasではこのオプションは現時点だと使えない?ようなので、Python用のライブラリで扱っていきます。(Anaconda環境を前提に話を進めます)
APIの使用には証明書が必要になってきます。三つほど種類があるようで、以下のようになっています。
- API キー -> BigQueryは扱えないのでこの記事では触れません。
- OAuth クライアント ID -> だれが使っているかなどを正確に追うような、ユーザーが何人もいるようなアプリなどでの使用に向いているそうです。使ったことはないので詳細は割愛。
- サービス アカウント キー -> 対象のプロジェクトでアクセスが許可されているGCPのサービスにアクセスすることができます。分析基盤からスクリプトなどによるアクセス等はこちらになると思います。
サービス アカウント キーを発行していきます。
GCPのコンソールの左のメニューから、APIとサービス → 認証情報 をクリックします。

認証ボタンを作成 ボタンを押します。

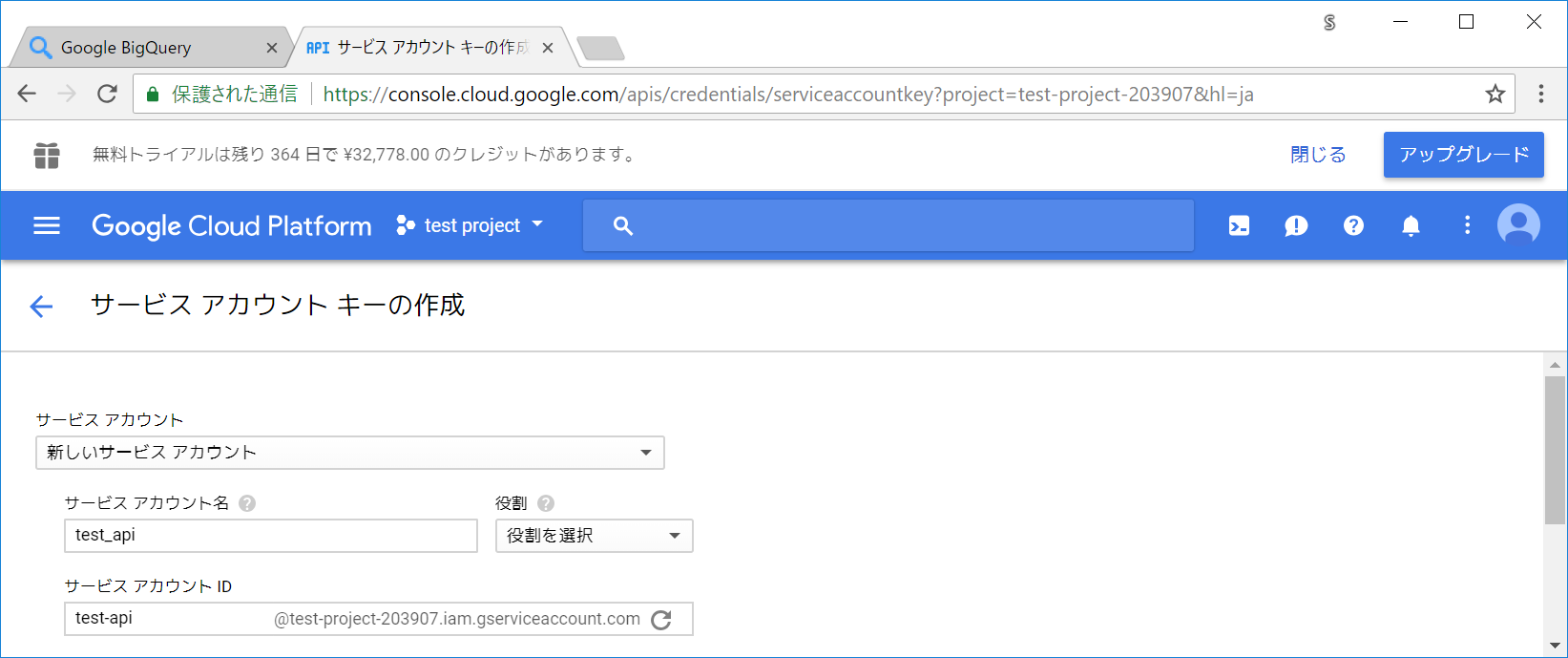
サービス アカウント キー を選択します。

サービス アカウント に 新しいサービス アカウント を選択し、サービス アカウント名 は今回は test_api としました。
役割(ロール)ですが、BigQueryが必要になるのですが、BigQueryの中でも結構色々種類があります。
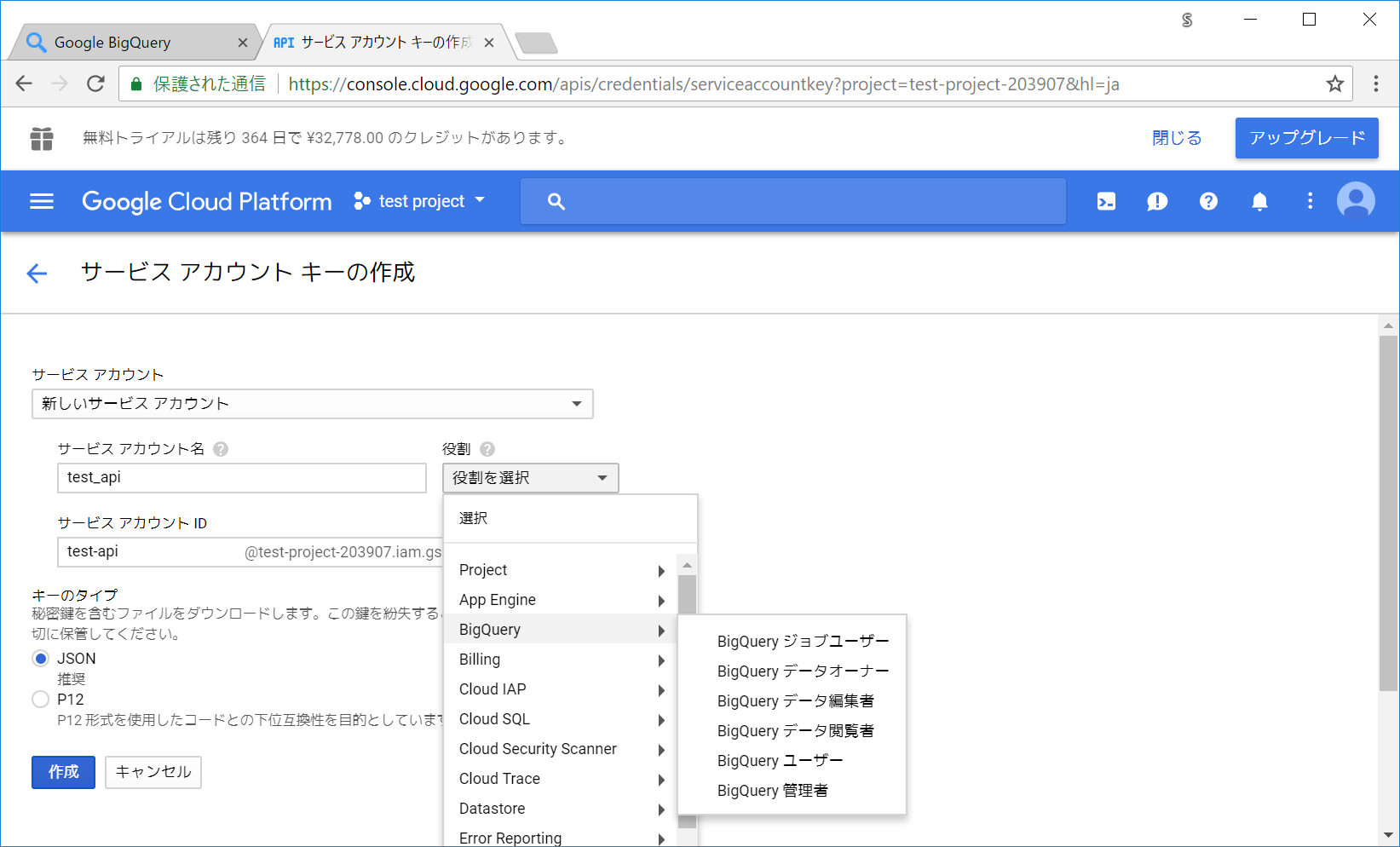
詳細は公式資料のアクセス制御ページなどに、権限の表が載っています。
ただ、表を見ながら設定していましたが、「あれ、これだとこのクエリできないの?表と違くない?」という状況に何度か遭遇したので、この辺りは別途調査が必要そうな印象です・・(この記事の本題から外れるので、調査する機会があれば別の記事で書きます)
なお、複数の役割を設定して、その分権限を広げることも可能だそうです。
今回は、権限が多く本来は好ましくないですが、一旦「BigQuery ジョブユーザー」 + 「BigQuery データオーナー」の役割を割り当てます。(それぞれ試しで個別で発行したところ、Python上でエラーになったため)
(この辺りは、海外のstackoverflowなどでも、「その役割だったらそのクエリは実行できるはずだけど、エラーになるのは奇妙だね」といったような書き込みがあったので、要検証な印象・・)
キーのタイプはJSONを選択します。UI上でも、書籍でもJSONが推奨されていたので、JSONで特に問題はないと思います。
作成ボタンを押します。
秘密鍵のJSONファイルがローカルに保存されます。

※このファイルは外部に公開しないように注意してください。公開してしまうと、第三者があなたのテーブルに対してクエリが実行できてしまい、データを削除したり、コストがかなりかかるクエリを投げられたりしてしまいます。
仮にテーブルが追加されていない状態でも、パブリックデータセットと呼ばれる、BigQueryのパフォーマンス検証などで使える膨大な件数のデータセットなどへアクセスすることができ、それらのSELECT文などで容易に大きなサイズのクエリが発行できてしまいます。
万一ファイルが漏れたと思われたら、すぐさまその証明書を無効化したりするなどの対応をしてください。
また、長期間使わなそうな状態になったのであれば、面倒くさがらずにその証明書は安全のため無効化しておきましょう。
秘密鍵の発行ができたので、Pythonのコードを書いていきます。
まずはBigQuery用のライブラリをインストールします。
$ pip install bigquery-python
Successfully installed bigquery-python-1.14.0 google-api-python-client-1.6.7 httplib2-0.11.3 oauth2client-4.1.2 rsa-3.4.2 uritemplate-3.0.0
pipだけだとエラーになるので、condaでのインストールも行います。(もしかしたらconda側だけでOKかもしれません)
$ conda install -y -c conda-forge google-cloud-bigquery
The following NEW packages will be INSTALLED:
cachetools: 2.0.1-py_0 conda-forge
certifi: 2018.4.16-py35_0 conda-forge
chardet: 3.0.4-py35_0 conda-forge
futures: 3.0.3-py35_0
google-api-core: 1.1.2-py_0 conda-forge
google-auth: 1.2.1-py_0 conda-forge
google-cloud-bigquery: 1.1.0-py_0 conda-forge
google-cloud-core: 0.28.1-py_0 conda-forge
google-resumable-media: 0.3.1-py_0 conda-forge
googleapis-common-protos: 1.5.3-py35_0 conda-forge
pyasn1-modules: 0.0.9-py35_0 conda-forge
pysocks: 1.6.8-py35_1 conda-forge
readline: 7.0-ha6073c6_4
rsa: 3.4.2-py35_0 conda-forge
urllib3: 1.22-py35_0 conda-forge
Pythonのコードを書いていきます。
from google.cloud import bigquery
# ダウンロードした秘密鍵のJSONを指定します。
bqclient = bigquery.Client.from_service_account_json('./*****.json')
# 現在設定されているプロジェクトを表示します。
print(bqclient.project)
test-project-203907
Pythonから、APIを使ってプロジェクト名が確認できました。
簡単なクエリをPythonから実行してみます。
クエリ結果は、BigQueryのライブラリ側でto_dataframe関数が用意されており、さくっとデータフレームに変換することができます。(dry_runを使わず、pandasで直接扱うのであれば、pandas側にもread_gbq関数が用意されています)
import pandas as pd
# legacy SQLの書き方だと、設定などしないとエラーになるようなので、
# シンプルにここでは標準SQLに合わせた FROM 部分の書き方をしています。
query = "SELECT id, name FROM `test_dataset.test_table` LIMIT 2"
query_job = bqclient.query(query=query)
row_iterator = query_job.result()
df = pd.DataFrame(data=row_iterator.to_dataframe())
print(df)
id name
0 3 melon
1 2 orange
PythonライブラリでBigQueryのSELECTができることが確認できました。
本題のdry_run設定を反映してみます。
QueryJobConfig というクラスで、いろいろクエリの設定ができるので、そちらに設定していきます。
query = "SELECT id, name FROM `test_dataset.test_table` LIMIT 2"
job_config = bigquery.QueryJobConfig()
job_config.dry_run = True
query_job = bqclient.query(query=query, job_config=job_config)
print(query_job.total_bytes_processed)
46
dry_runオプションの設定で、実行時に必要なバイト数が得られました。
なお、この状態ではもちろんクエリは実行されていない(コストがかかっていない)ので、データの変換などをしようとしてもエラーで弾かれます。
query_job.to_dataframe()
Not found: Job test-project-203907:******
これでAPI経由でもチェックができるようになりました。最初は大丈夫でも、日数が経ってログが増えた際に実はクエリの必要サイズがかなり多くなっていた・・ということを避けるように、簡単にバイト数のチェックができるので、可能ならば自動で毎日、各クエリで必要なサイズが異常に膨れていないかチェックするようになっていたら安心かな・・という印象です。
TIPS 6 : 日付単位でのパーティション機能を使う
前述の通り、BigQueryでは指定した対象のテーブルのカラム全体のサイズがコストに絡んできます。
それで、日別や月別のテーブルを分けるというのも一つの手です。
ただし、その場合テーブル数が膨大になってきます。
そこでBigQueryには、同じテーブルでありながら、内部的には日付別に分割されているものとして扱うための機能が用意されています。(パーティション)
便利ですが、以下のように制限や注意事項があります。(初見の時は少し分かりづらかった点も)
- SQLでのインサートなどができなさそうな印象がある(軽く調べた限り)。
- SDKなどでのloadコマンドだったりが必要になってきます。
- SELECT以外は制限が絡んできそうな印象があります。
- 日付ごとのパーティションに対してのみ、現在は機能が用意されている。(月単位だったり、時間単位だったりは現在指定できない)
- 2500パーティションまでしか1つのテーブルに持つことができない。
- 実質2500日。7年弱程度は大丈夫なので、新規案件などであればそれまでにGoogle側で制限が緩和されそうな印象があるものの、旧来からあるプロジェクトで10年分のログをBigQueryなどに引っ越す際などにはテーブルを(例えば5年単位などで)分ける必要がある。
- 2000パーティションまでしか、1日に更新することはできない。(データの引っ越しなどで、1日に一気に流す場合などに注意が必要)
- 50パーティションまでしか、10秒ごとに更新することはできない。
- 既に保存されている時系列データなどのテーブルにパーティションを反映していくのは、少し手間かもしれない。
- できれば最初からパーティション前提で組んであると良さそうです。
実際にパーティションテーブルを作って、クエリを投げたりしてみましょう。
この記事ではテーブルの作成自体は、webのコンソールから進めます。(SDKでも対応できますが、若干手順が多くなります)
test_partition_table という名前でテーブルを作っていきます。
データは以下のようなCSVを使います。(データを入れる際のパーティション指定の都合、日付でそれぞれ別のファイルに分けています。)
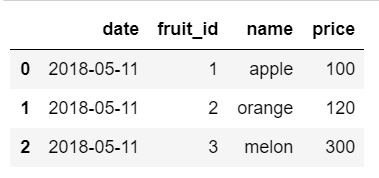
[fruit_data_partition_20180511.csv]
date,fruit_id,name,price
2018-05-11,1,apple,100
2018-05-11,2,orange,120
2018-05-11,3,melon,300
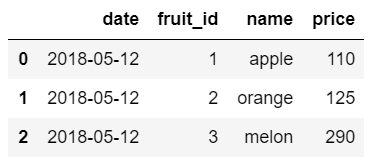
[fruit_data_partition_20180512.csv]
date,fruit_id,name,price
2018-05-12,1,apple,110
2018-05-12,2,orange,125
2018-05-12,3,melon,290
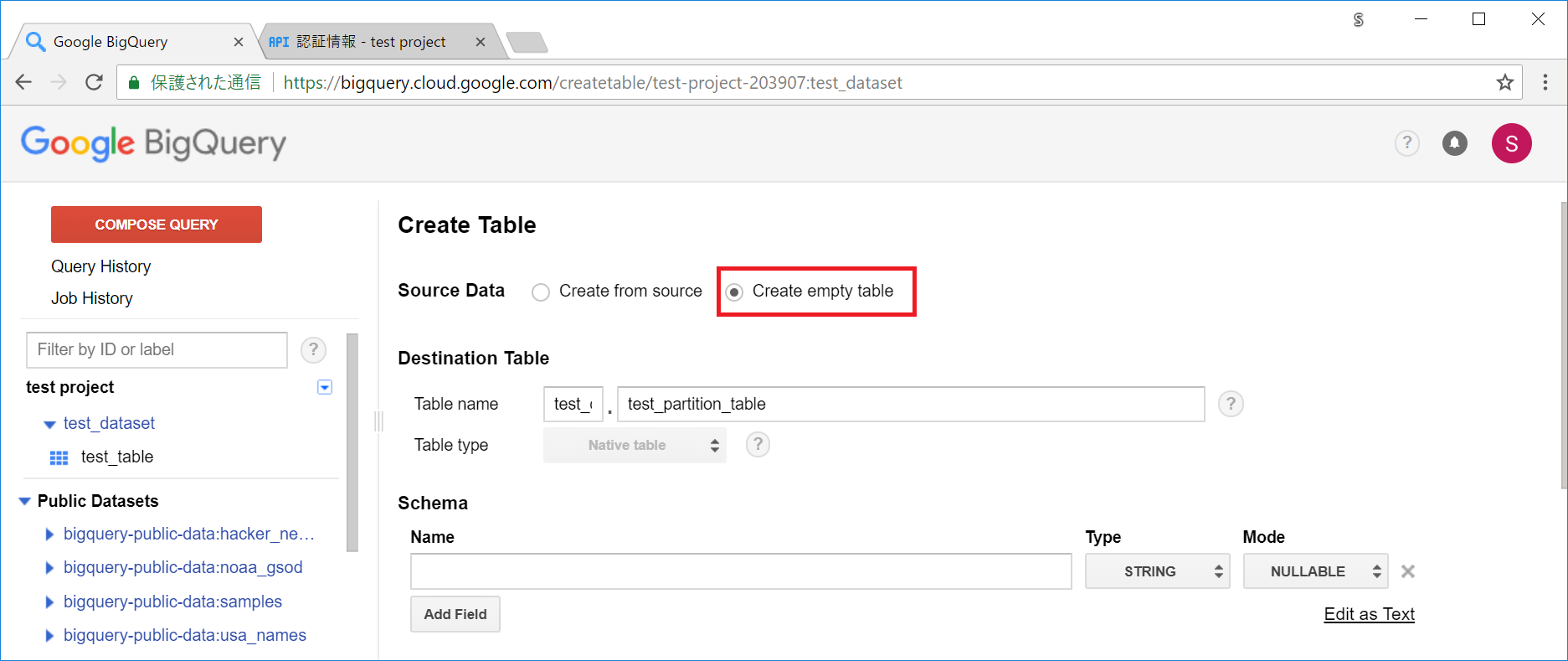
まずは対象のデータセットの右の ▼ アイコンから、 Create New Tableを選択します。

Source Data には、今度は Create Empty Tableを選択し、スキーマを一つ一つ手で指定して、データを入れていきます。
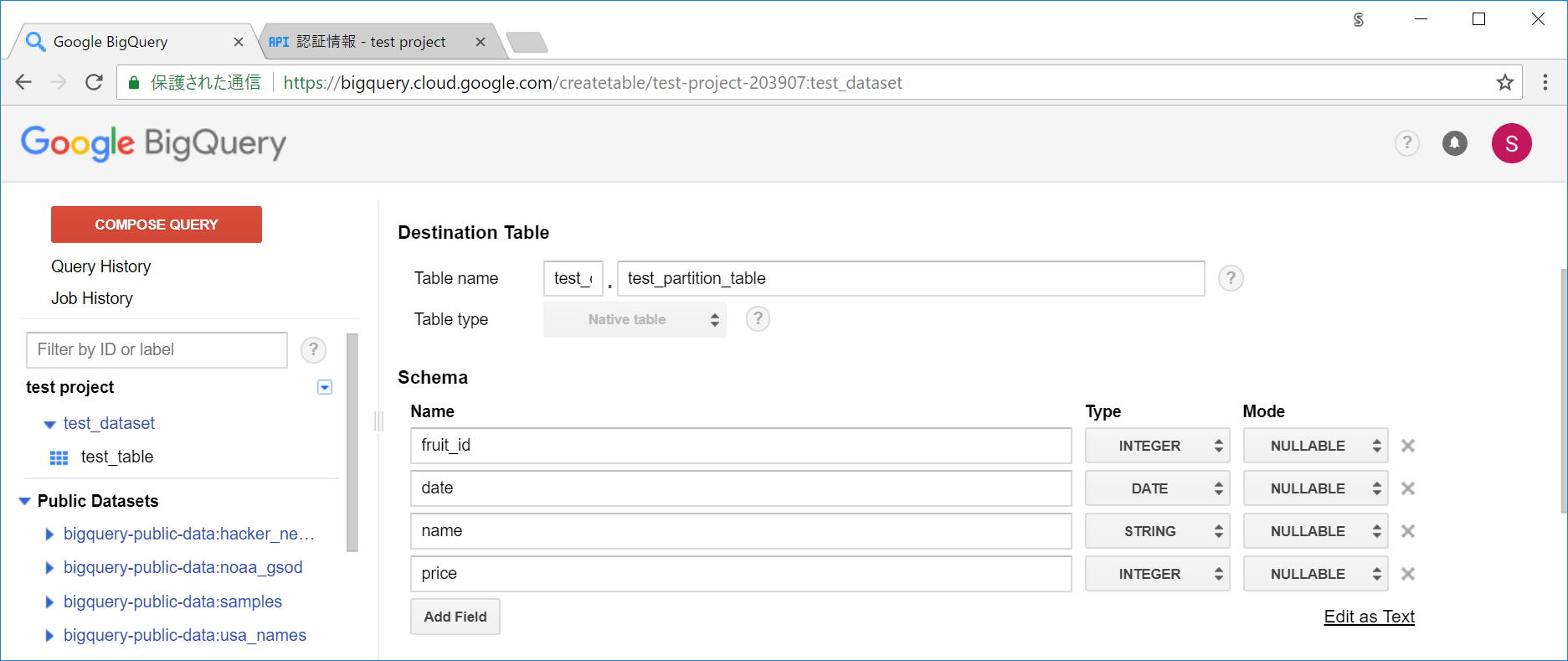
スキーマは以下のスクショのように設定しました。
パーティションの設定として、 Partition Type にDayを選択しました。これで日付単位でパーティション分割がされます。

Partition Field には _PARTITIONTIMEを選択しています。(この値は、データを読み込む際のコマンドなどで指定します)
(普通に日付のフィールド選択すれば、そのフィールドの値に応じて自動でパーティションを設定してくれるんじゃ?と思いましたが、試したところそんなことはなかったので、無難に_PARTITIONTIMEを選択しました。)
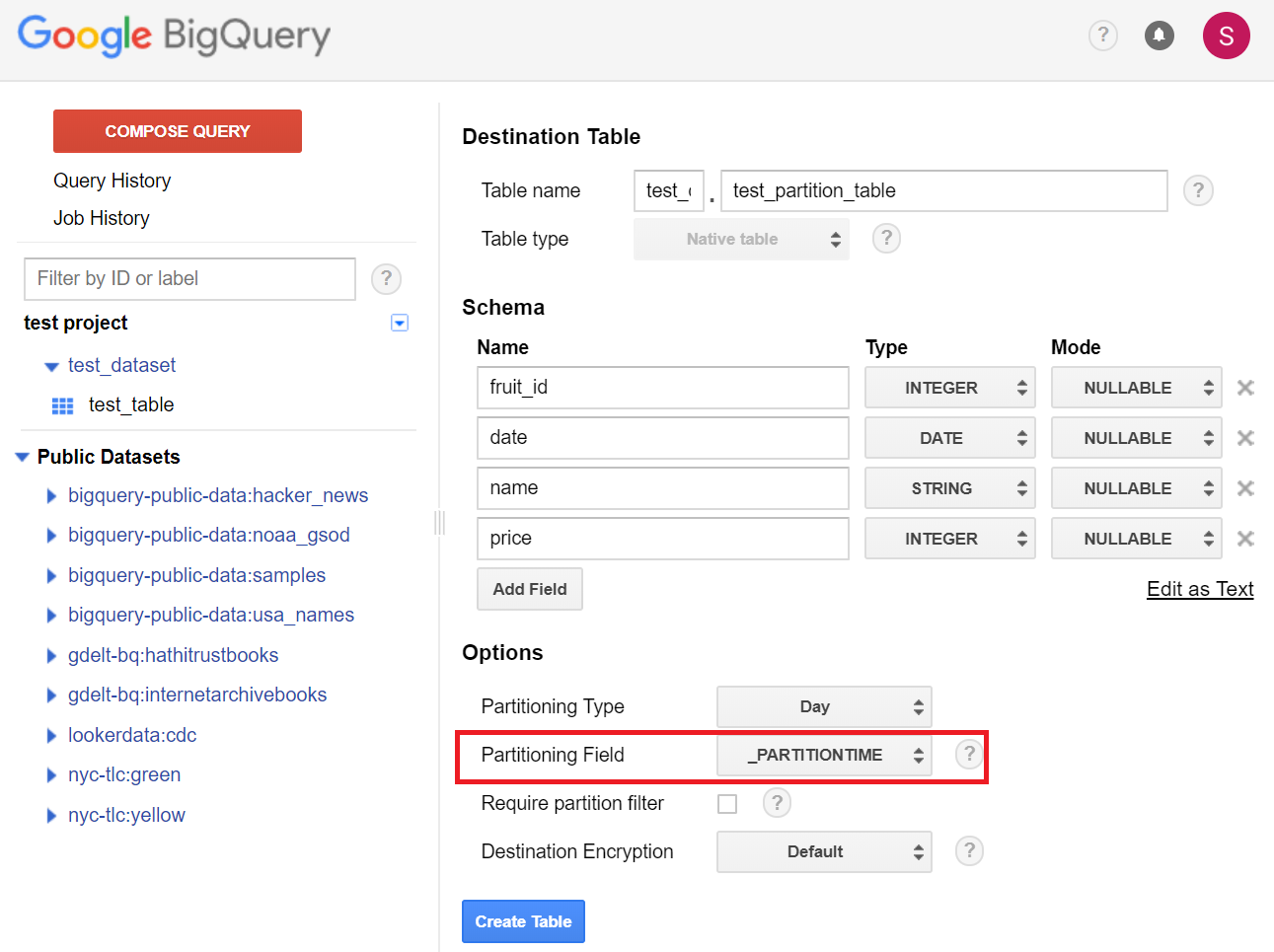
Create Table ボタンを押してテーブルを作成します。
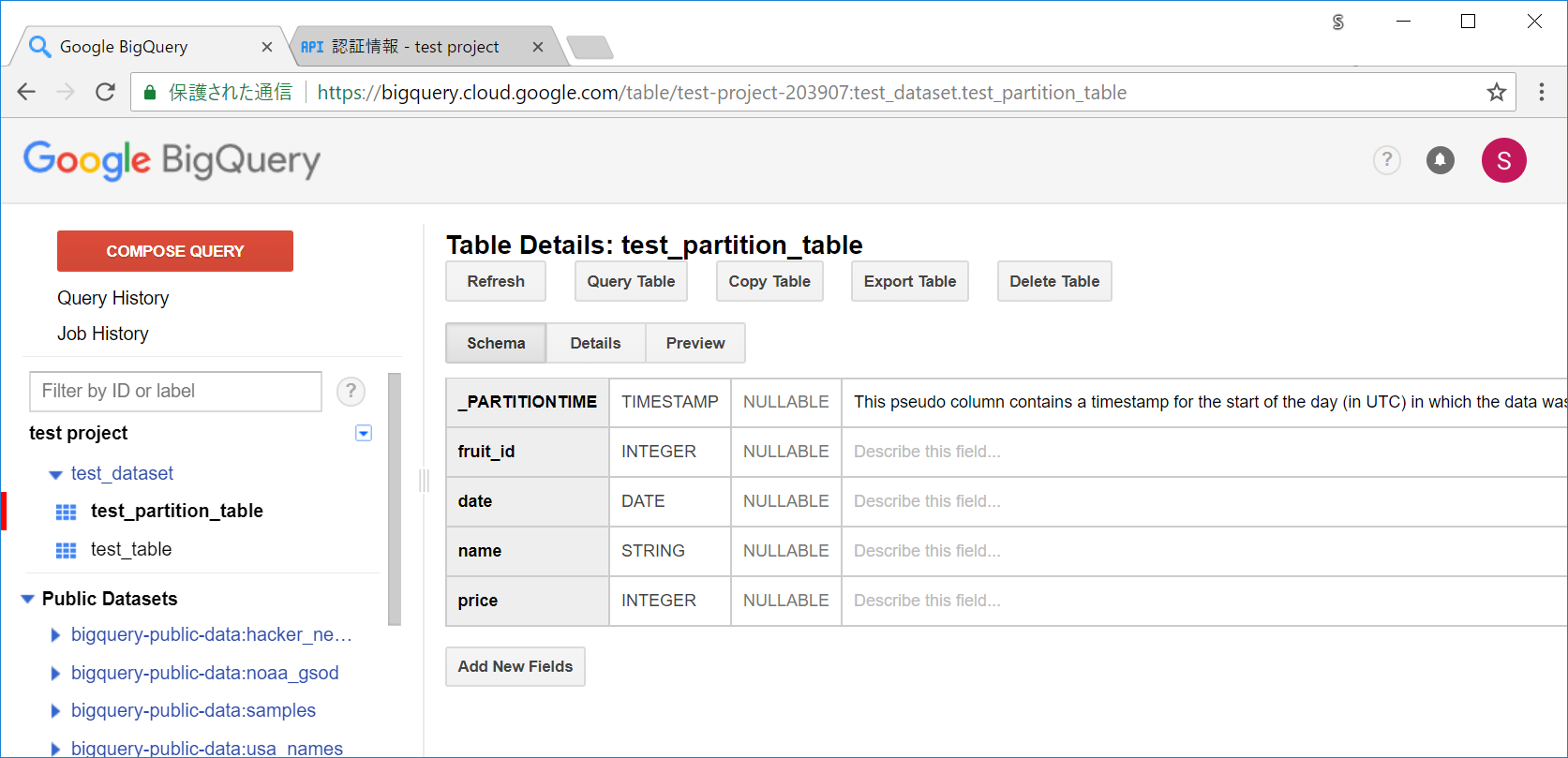
上記のようなスキーマのテーブルが追加されます。_PARTITIONTIMEという、パーティション用のカラムが追加になっています。
SDKを使ってデータを入れます。
bq load コマンドを使いますが、通常時と異なりパーティション用の指定として、テーブルの後に$日付という形式で指定する必要があります。指定しないと当日の日付が参照されたりするため、指定し忘れたりすると予期せぬパーティションにデータが格納される可能性があります。(dateフィールドとパーティションの日付が異なるといった状態になります)
以下のような記述になります。
$ bq load --skip_leading_rows=1 bq load --skip_leading_rows=1 --autodetect 'test_dataset.test_partition_table$20180511' fruit_data_20180511.csv '<テーブルの指定>$<パーティションの日付>' <CSVのパス>
※CSVにヘッダーがある場合、--skip_leading_rows=1 といった値を指定します。
※CSVカラムの順番がBigQuery側のスキーマの順番と異なる場合のために、--autodetectを指定しています。
PowerShellで入れたいデータのCSVがあるフォルダに移動して、実際にデータを入れてみましょう。
$ bq load --skip_leading_rows=1 --autodetect 'test_dataset.test_partition_table$20180511' fruit_data_20180511.csv
Upload complete.
Waiting on bqjob_r5abd13c5_0000016358be7ae4_1 ... (0s) Current status: DONE
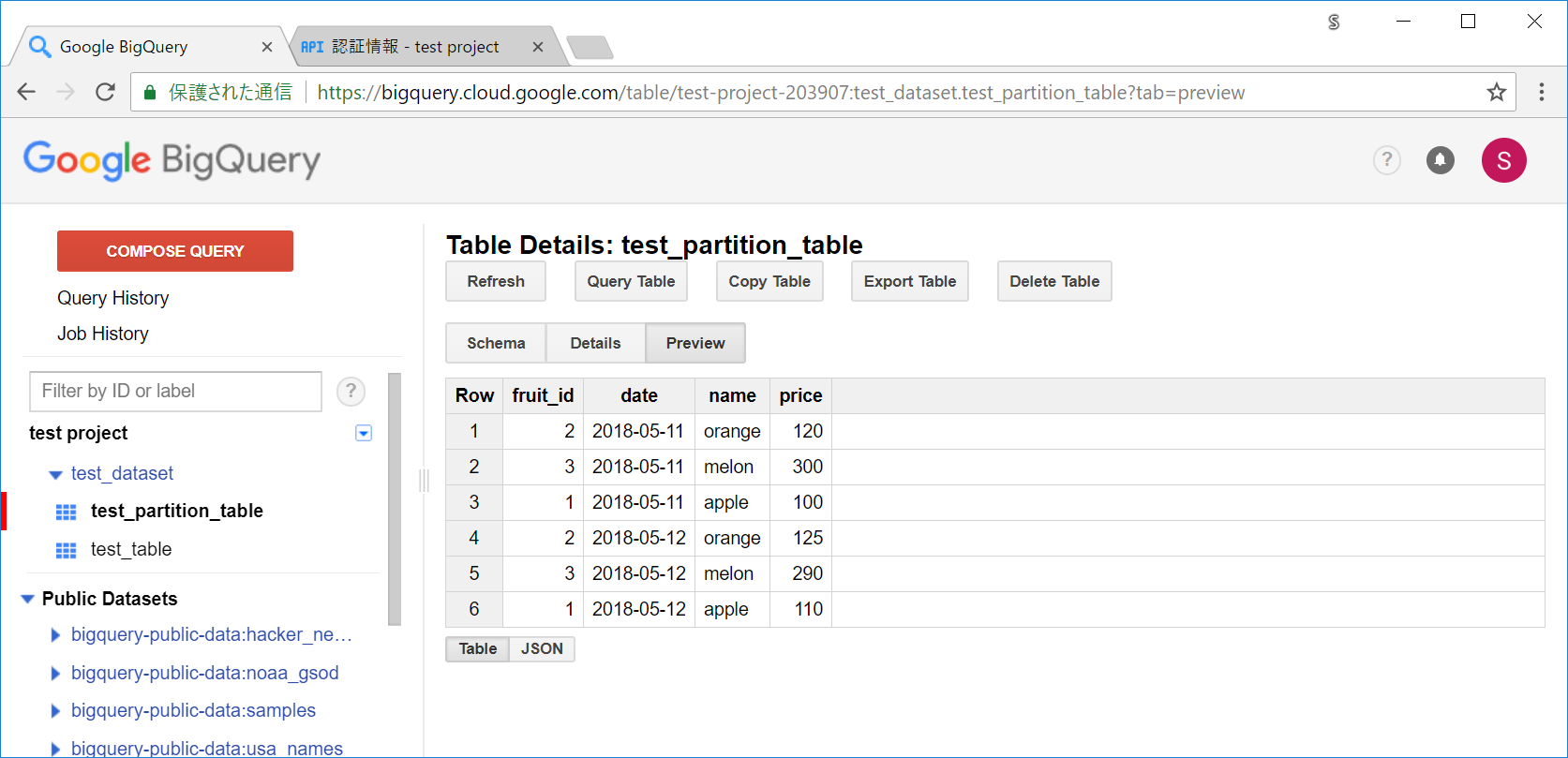
webのコンソールを一度F5してみて、Previewボタンを押してみると、確かにデータが入っています。

別の日付のパーティションにも、データを入れていきます。テーブルの後の日付と、ファイルパスの個所を変えてあります。
$ bq load --skip_leading_rows=1 --autodetect 'test_dataset.test_partition_table$20180512' fruit_data_20180512.csv
これで、20180511と20180512のパーティションそれぞれにデータが入りました。
あとは、SELECTを実行する際に、パーティションを指定すればOKとなります。
注意 : dateフィールドではなく、_PARTITIONTIMEのフィールドをWHEREなどで指定しないと、サイズが減ってくれません。
まずは、パーティションを参照しない場合のサイズを確認しておきましょう。
SELECT fruit_id, name FROM [test_dataset.test_partition_table]
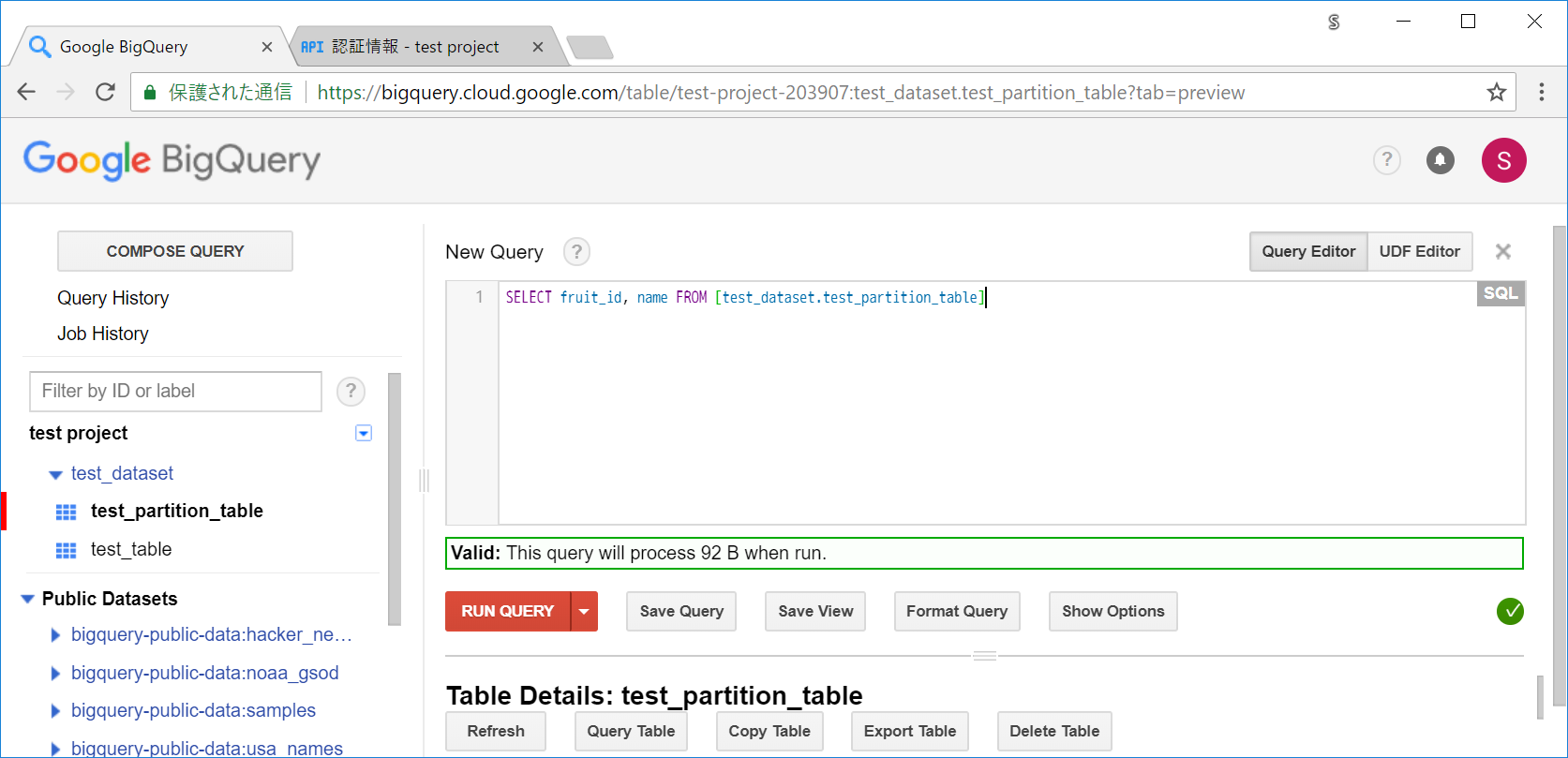
Valid: This query will process 92 B when run.
上記のクエリでは、92B必要になるようです。
日付単体であれば、テーブルの後に $日付 とクエリに書くことで、パーティションを参照したクエリを書くことができます。
SELECT fruit_id, name FROM [test_dataset.test_partition_table$20180511]
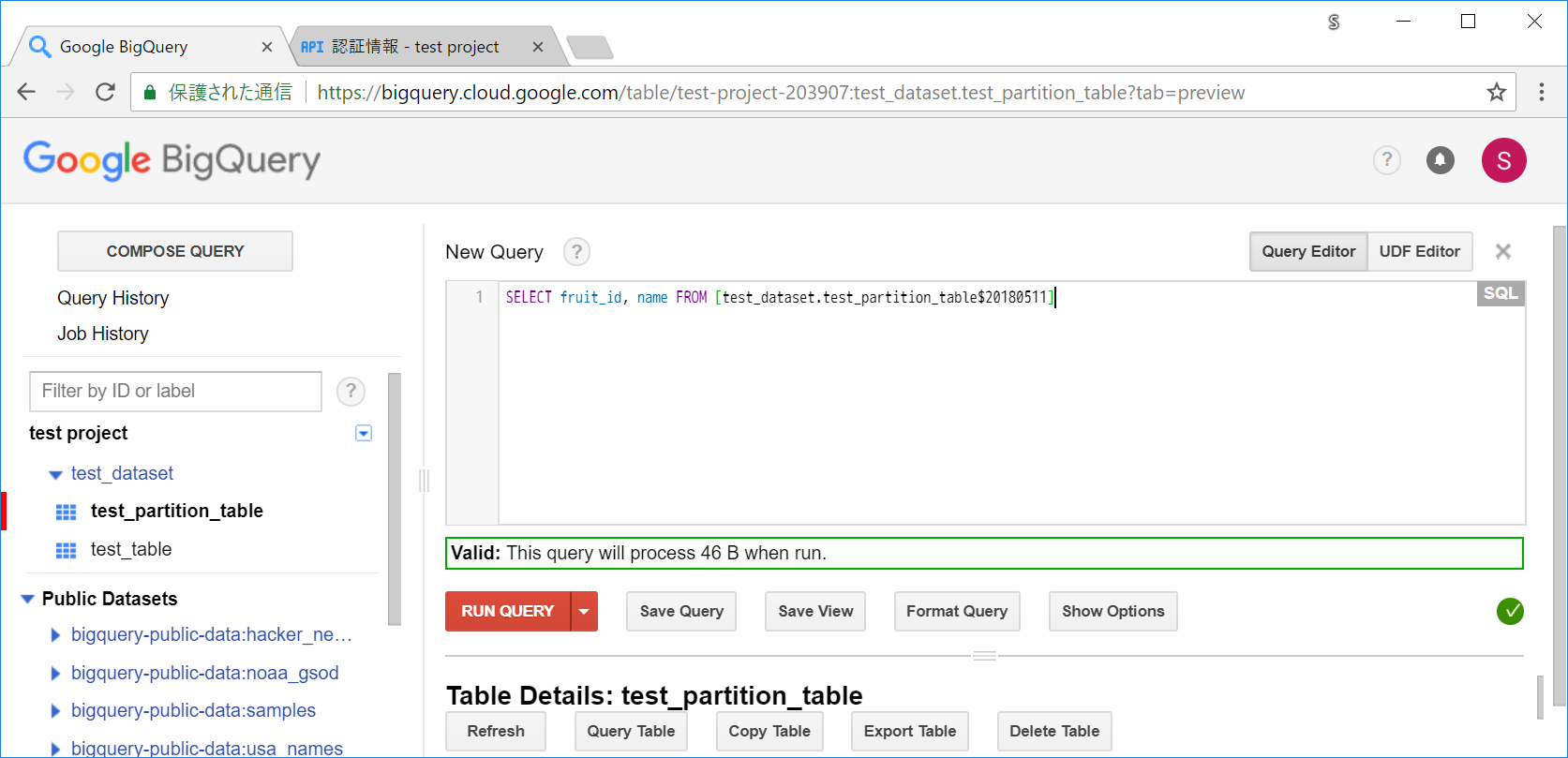
Valid: This query will process 46 B when run.
パーティションを参照することで、92Bから46Bにサイズを減らすことができました。
複数の日付範囲を指定したい場合には、以下のようにWHEREの個所に書いていきます。今回は20180511のみの日付範囲で指定しているので、日付単体のときとサイズは一緒ですが、サイズは減っています。
SELECT
fruit_id, name
FROM
[test_dataset.test_partition_table]
WHERE
_PARTITIONTIME >= "2018-05-11 00:00:00" AND _PARTITIONTIME < "2018-05-12 00:00:00"
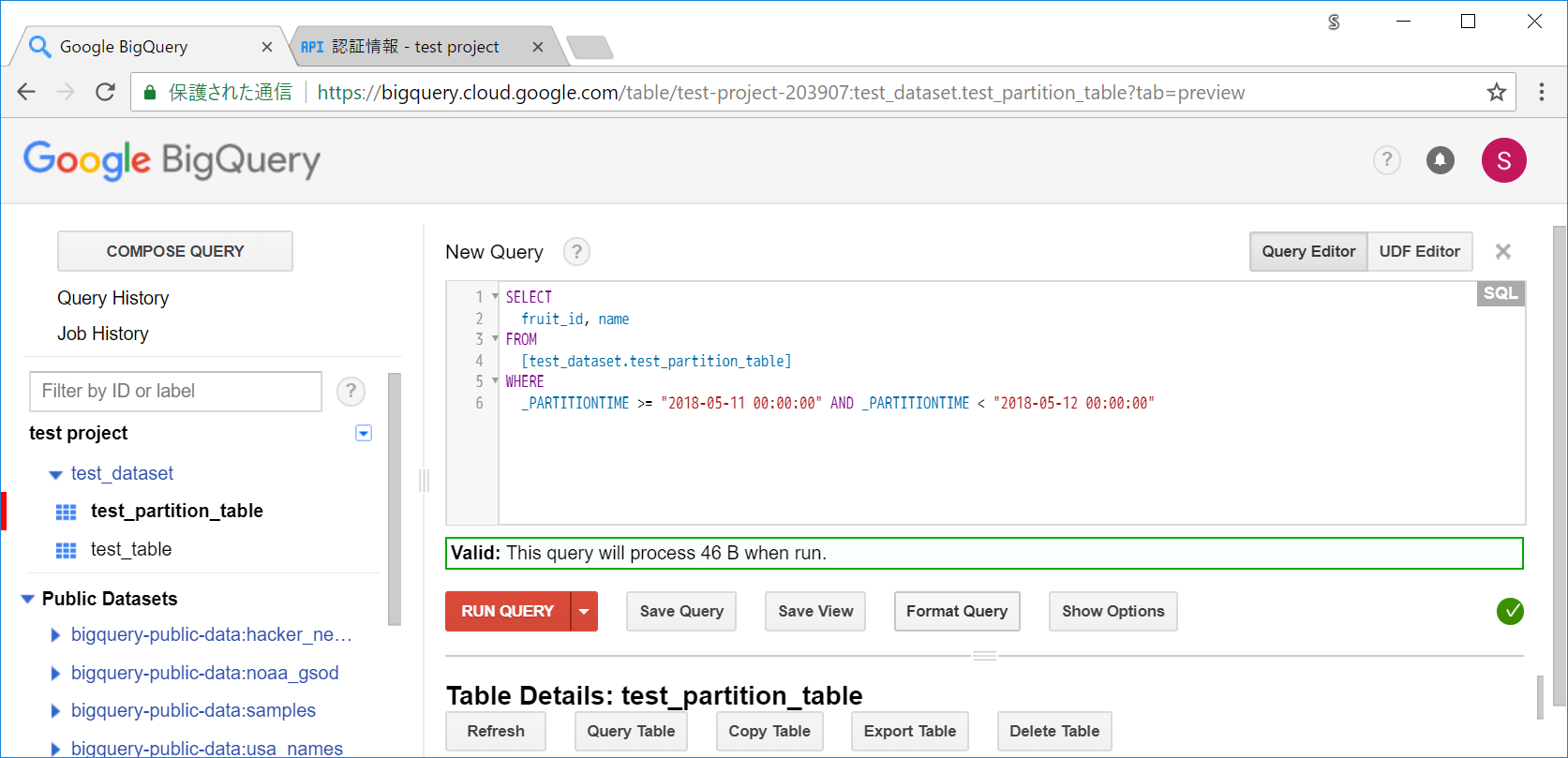
Valid: This query will process 46 B when run.
補足となりますが、前述のとおり、「2500パーティションまでしか1つのテーブルに持つことができない」という制限があるので、7年弱程度でテーブルを分けないといけません。
ただ、たとえば両方のテーブルをまたがってクエリをしたいケースも出てくると思います。
そういった場合は、例えばテーブル名を「test_table_2010_to_2014」「test_table_2015_to_2019」といったように、テーブル名の始まりを「test_table_」と統一しておくことで、SELECT文などでワイルドカード指定することで、test_table_で始まるテーブル全てを対象にする、といったことが可能です。
この機能を使うには、BigQueryで二つあるクエリのうち、標準SQLという方を使う必要があります。
Show Optionsボタンを押してオプションを表示し、Use Legacy SQLのチェックを外してください。


今まで作ったtest_から始まるテーブル全てをクエリ対象にする例 :
SELECT fruit_id, name FROM `test_dataset.test_*`
TIPS 7 : API経由などでデータを入れる場合には、有料のものと無料のものがある
BigQueryにデータを入れる場合には、日々の時系列データなどはAPIなどで自動化しつつの利用が多くなると思います。
その場合、無料のものと有料のもの(ストリーミングインサート)があるため、「今使っているライブラリのものはどちらなのか」という点を意識する必要があります。
- 無料の場合には、データを入れるBigQueryのジョブが開始されるまで少し待つ必要があります。
- すぐに終わるときもあれば、(仮にわずかなデータの読み込みであっても)何分も待ったりするケースがあったりと、結構ばらつきます。
- 有料の場合には、データを入れる処理がすぐに開始されます。
深夜のcronなどで、ちょっと待ったくらいなら誤差の範囲、といったケースであれば無料の方を利用しましょう。(データ量にもよりますが、長期的に見ると結構コストが多くなる可能性があります)
もしくは、「すぐにデータを入れて集計しないといけない!」といった、アドホックに行う分析などのケースでは、有料の方でも1回やるくらいなら大した金額にはならないので有料の方を使う、といった感じで問題ないと思います。
注意しないといけないのは、インサートなどは基本無料なので、その感覚でpandasなどで大規模データをBigQueryに入れようとすると、pandasのto_gbq関数などは有料の方のものを使っているため、コストがかかることに気づかないまま使ってしまう可能性がある、ということです。
この辺りは知っておけば問題はありません。cronなどで日々大量のデータを扱う場合には、pandasではなくPython側のライブラリなら、無料・有料のもの両方使えるので、そちらを使いましょう。
試しにPythonでの無料の方法でのデータを入れる対応を、終わるまでの時間を確認しつつ実行してみます。
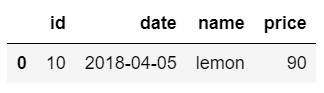
以下のようなシンプルなCSVを、test_tableに入れることを試してみます。
[fruit_data_lemon.csv]
id,date,name,price
10,2018-04-05,lemon,90
from datetime import datetime
from google.cloud import bigquery
# 秘密鍵のJSONを指定します。
bqclient = bigquery.Client.from_service_account_json('./***.json')
# 保存する対象のデータセットの参照を取得します。
dataset_ref = bqclient.dataset(dataset_id='test_dataset')
# 保存する対象のテーブルの参照を取得します。
table_ref = dataset_ref.table(table_id='test_table')
job_config = bigquery.LoadJobConfig()
# 読み込むデータのフォーマットを指定します。今回はCSVとなります。
job_config.source_format = 'CSV'
# 1行目にカラムの行を含んでいるCSVなので、1を指定します。
job_config.skip_leading_rows = 1
# カラムの順番などをうまいこと判定してくれるように、Trueを指定します。
job_config.autodetect = True
# rb(read bytes)ではなくr指定などだとエラーになるので注意してください。
with open('./fruit_data_lemon.csv', 'rb') as f:
print('処理開始 :', datetime.now())
load_job = bqclient.load_table_from_file(
file_obj=f, destination=table_ref, job_config=job_config)
# ジョブが開始して、処理が終了するまで待ちます。
load_job.result()
print('処理完了 :', datetime.now())
処理開始 : 2018-05-13 10:44:34.605185
処理完了 : 2018-05-13 10:44:39.377795
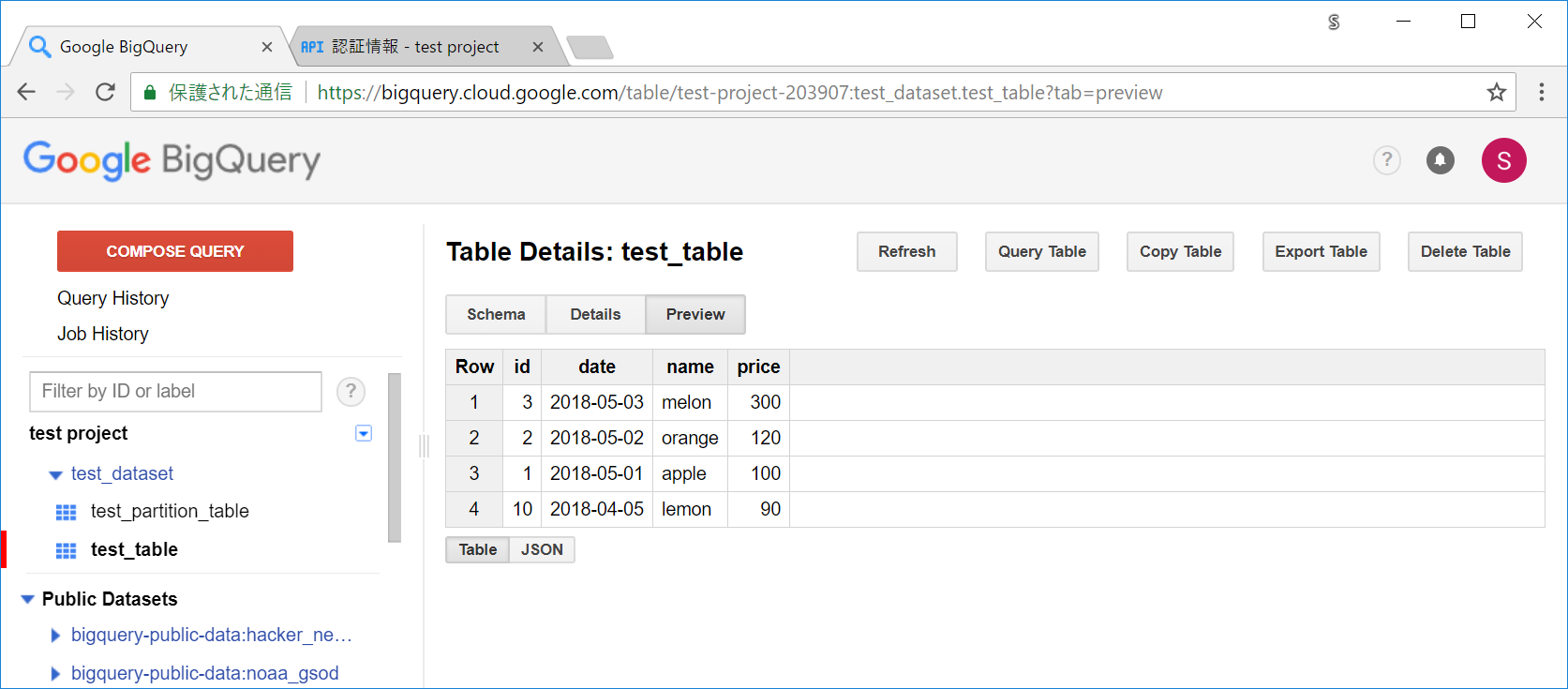
今回はさくっと終わり、5秒程度で終わったようです。
プレビュー画面でF5して確認してみても、確かに入っています。
まとめ
-
webコンソールでクエリを実行する際には、実行前に必要なサイズを確認する。
- 確認用のUIは常に表示しておくと好ましい。
- SELECT文は、必要最低限のカラムのみを指定する。
-
基本的に、WHEREやLIMITではサイズは減らない。
- WHEREで減らしたい場合はパーティションテーブルなどを検討する。
-
予算上限とアラートを設定する。
- プロジェクトごとと、会社全体の両方で設定するのが好ましい。
- なるべく早めに設定しておく。(できれば最初に)
-
SDKやAPIでも、必要サイズを事前にチェックする機能が設けられている。
- テーブルが肥大化して、気づかないうちにサイズが大きくなっていた・・ということを防ぐために、できればcronなどで実行しているクエリを毎日自動でチェックしてくれるようにしておくと安心。
- **日付単位でパーティションを分けてくれる機能がある。**コストがぐっと下がり、クエリのパフォーマンスもよくなるので、時系列のログなどでは極力使うようにする。
- **APIなどでのデータの読み込みは、無料のものと有料のものがある。**使うライブラリによって、有料のケースが発生するので留意する。
安全に使うための機能は色々と用意されており、しっかり知れば怖くないサービスです。圧倒的な速度とコスト削減が望めるケースもあると思いますので、今まで使ってこなかった方も、新規案件などでは積極的に検討してみてもいいかもしれません。![]()