はじめに
(株)日立製作所 OSSソリューションセンタの伊藤雅博です。この投稿では、Apache Sparkのデータ処理の流れを簡単に説明します。
Apache Sparkとは
Sparkはインメモリで処理を行う並列分散処理フレームワークであり、Hadoop(YARN)やMesos、Kubernetesなどのクラスタ上で動作します。Sparkでは処理内容をScala、Java、PythonまたはSQLで記述し、これをSparkアプリケーションとしてクラスタ上で実行します。
この投稿では、YARNクラスタ上で動作するSparkアプリケーションを例として、その処理の流れを簡単に説明します。
Sparkアプリケーションの例
今回の説明で使用するSparkアプリケーションでは、単語が改行区切りで記載された以下のようなテキストファイルから、各単語の出現回数を集計します。
Apple
Orange
Banana
Apple
Unknown
Orange
...
Pythonで記述したSparkアプリケーションを以下に示します。Sparkアプリケーションで使用するAPIには、基本的な操作を行うRDD APIと、より抽象的で高度な最適化が行われるDataFrame/DataSet APIがありますが、今回は処理内容を追いやすいRDDベースのアプリケーションを例に説明します。
from pyspark import SparkContext, SparkConf
from operator import add
if __name__ == "__main__":
conf = SparkConf().setAppName("Fruits count App")
sc = SparkContext(conf=conf)
sc.textFile("/data/fruits.txt")\
.filter(lambda x : x != "Unknown")\
.map(lambda x : (x, 1))\
.reduceByKey(add)\
.saveAsTextFile("/data/fruits_count")
sc.stop()
このSparkアプリケーションでは、HDFS上のテキストファイル/data/fruits.txtを読み出し、Unknownという単語を除外して各単語の出現回数を集計し、その結果をHDFSの/data/fruits_countディレクトリに以下のようなファイル群として書き出します。
(u'Orange', 186287)
(u'Apple', 126847)
(u'Banana', 94280)
...
Sparkアプリケーション実行時のリソース割当
SparkアプリケーションをYARNクラスタ上で実行する流れを以下の図に示します。このYARNクラスタは1台のマスタノードと、2台のワーカノードで構成されています。

まず、マスタノードのYRAN ResourceManagerに対して、spark-submitコマンドでSparkアプリケーションを投入します。この投入時に、Sparkアプリケーションに割り当てるリソース量を指定します。Sparkアプリケーションは以下に示す2種類のコンテナをYARNクラスタ上で実行するため、それぞれに対して割り当てるCPUコア数とメモリ容量を指定します。
- 1個のDriverコンテナ
- Sparkアプリケーション全体の実行を監督する
- SparkのAPIを使用していない(分散処理しない)部分のコードを実行する
- 1個以上のExecutorコンテナ
- SparkのAPIを使用して分散処理する部分のコードを実行する
以下のspark-submitコマンドは、Driverに1CPUコアと4GBメモリ、Executorは3個で各2CPUコアと32GBメモリを指定して、Pythonで記述したSparkアプリケーション(spark_app.py)を投入する例です。
spark-submit \
--master yarn \
--deploy-mode cluster \
--driver-cores 1 \
--driver-memory 4G \
--num-executors 3 \
--executor-cores 2 \
--executor-memory 32G \
spark_app.py
Sparkアプリケーションを投入されたYARN ResourceManagerは、各ワーカノードのYARN NodeManager上で指定されたリソースを持つコンテナ群を立ち上げます。
Sparkの処理(ジョブ、ステージ、タスク)とデータ(RDD、パーティション)
Sparkアプリケーションの処理を時系列に見ていきます。Sparkアプリケーションの処理は、ジョブ、ステージ、タスクという階層構造になっています。Sparkアプリケーションは1つ以上のジョブで構成され、各ジョブは1つ以上のステージで構成され、各ステージの処理は1つ以上のタスクで並列に分散処理されます。
Sparkで処理するデータはRDD (Resilient Distributed Dataset) という概念で表現され、各RDDは1個以上のパーティションで構成されます。以下の図に処理(ジョブ、ステージ、タスク)とデータ(RDD、パーティション)の時系列の関係を示します。
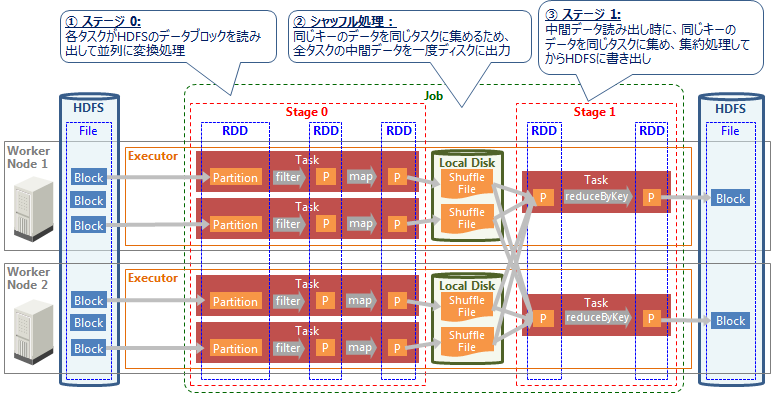
このSparkアプリケーションでは、HDFS上のファイルを読み出し、変換処理(filter、map)を行い、集約(reduceByKey)して、結果をファイルとしてHDFSに書き出します。このSparkアプリケーションの処理は1個のジョブ、2個のステージで構成されており、これを2個のExecutor(それぞれ2コアを割り当て)が処理します。
なお、**実際のSparkでは様々な最適化が行われるため、コード上の変換APIの呼び出しと、実際に行われる変換処理は必ずしも一致しません。**上記の変換処理(filter、map、reduceByKey)も、実際には別の変換処理に置き換えられたり、さらに細かい変換処理に分割されたりして実行されます。
今回はSparkのデータ処理の流れを理解するのが目的ですので、filter、map、reduceByKeyの順で処理が行われると仮定したうえで、その動作を時系列に説明していきます。
① ステージ0: HDFSからデータファイルを読み出して変換処理
このステージでは、HDFS上から1個のファイルを読み出して変換処理します。このファイルはHDFS上で6個のブロックに分割されて格納されており、1タスクが1ブロックを読み出して1パーティションとして扱い、クラスタ上で並列処理します。ここでは各タスクがHDFSのデータ読み出し、変換処理(filter、map)を行い、処理結果を一度中間ディスクに書き出します。
各タスクは、Executorのタスクスロット(≒CPUコア)に割り当てられて、並列に処理されます。今回は2個のExecutorがそれぞれ2コアを持つため、合計4個のタスクスロットで並列処理できます。
一方、入力ファイルは6個のブロック(=6パーティション)で構成されているため、このステージは6個のタスクで構成されますが、タスクスロット数は4個のため、実際に並列処理できるのは4タスクのみです。残りの2タスクは、前のタスクが終了してタスクスロットに空きが出てから実行されます。
② シャッフル
ステージ内の各タスクは独立に処理され、タスク間の依存関係やデータ交換はありません。しかし処理内容によっては、別々のタスクが持つデータが必要なこともあります。今回実行するreduceByKey処理ではキーごとにデータを集約するため、事前に同じキーのデータを同じタスクに集める必要があります。このように複数タスクのデータにまたがる処理を行う場合、シャッフル処理によってデータを再配置します。
シャッフル処理では、ステージの全タスクがデータを一度中間ディスク(デフォルト設定では各ワーカノードのローカルディスク)に出力します。全タスクが中間データを出力し終えたら、そのステージは終了します。そして次のステージの各タスクが中間データを読み出すことで、データを交換した状態で処理を再開します。
Sparkは基本的にインメモリで処理を行いますが、シャッフル時はディスクへの読み書きが発生することになります。ただし、ワーカノードのメモリに余裕があれば中間ファイルはページキャッシュ上に残り続けるため、ファイルの読み書きは実質的にインメモリでの処理となります。そのため、シャッフル処理を高速化したい場合は、Sparkが使用するメモリに加えてページキャッシュ用のメモリも考慮する必要があります。
③ ステージ1: データを変換処理してHDFSに書き込み
このステージは2個のタスクで構成されており、各タスクが中間ディスクからデータを読み出し、同じキーのデータを同じタスクに集めます。そして、キーごとにデータを集約するreduceByKey処理を行い、その結果をHDFSに書き戻します。
複雑なSparkアプリケーションの場合
上記の例では1個のファイルを処理しましたが、もし複数個のファイルを読み出して処理する場合は、ファイルの個数だけジョブが生成されることになります。また、複雑な処理になると1個のジョブが大量のステージで構成されたり、別々のジョブのステージが1個のステージに合流したりもします。例えば2個のファイルを読み出して結合する場合、2つのジョブが生成され、各ジョブの途中で1つのステージに合流します。
おわりに
この投稿では、簡単なSparkアプリケーションを例として処理の流れを説明しました。Sparkでは様々な最適化が行われるため、実際の処理はより複雑です。しかし動作の基本的な概念を理解しておくと、エラー発生時の原因究明やパフォーマンスチューニングに役立つかもしれません。