はじめに
自然言語処理全くワカラン人でもBERTが使えるようになるためのノートブックです。
対象とする人
- とにかくBERTを触ってみたい
- 環境構築が苦手
やること
- GoogleColabでBERTを使うための爆速チュートリアル
- JPOPの歌詞を可視化してみるデモ
BERTの簡単な説明
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
We introduce a new language representation model called BERT, which stands for Bidirectional Encoder Representations from Transformers. Unlike recent language representation models, BERT is designed to pre-train deep bidirectional representations from unlabeled text by jointly conditioning on both left and right context in all layers. As a result, the pre-trained BERT model can be fine-tuned with just one additional output layer to create state-of-the-art models for a wide range of tasks, such as question answering and language inference, without substantial task-specific architecture modifications.
この名の通り双方向のTransformerを用いた汎用的な言語モデルである。
ざっくり言うとWord2Vecのように可変長の文字列を固定長の数値ベクトルで表現することができる。
BERTの学習は2ステージに分けられる。
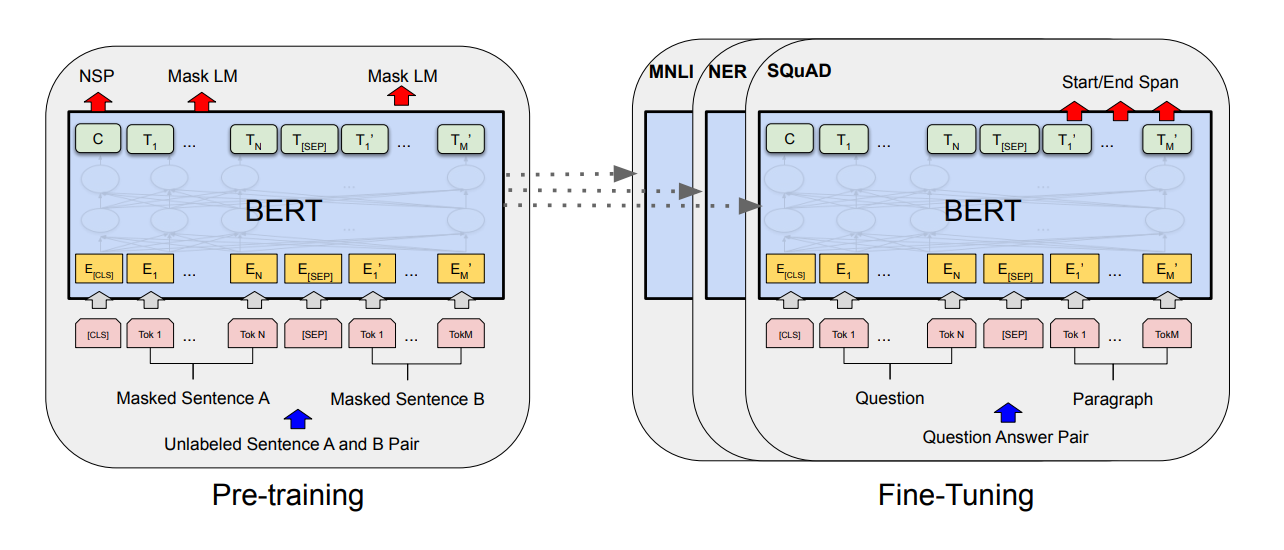
実践的な説明からすると図左側のPre-Trainingの部分はGoogleや偉大なる研究室、個人などから学習済みのモデルが提供されている。
- BERT日本語Pretrainedモデル - KUROHASHI-KAWAHARA LAB
- BERT with SentencePiece を日本語 Wikipedia で学習してモデルを公開しました – 原理的には可能 – データ分析界隈の人のブログ、もとい雑記帳
- BERT-Base, Multilingual Cased (New, recommended)
※ここを自前でやろうとすると膨大な時間とGPU/TPUが必要になる。
右側のFine-Tuningは自分で実装する部分である。Pre-Trainingで取得できたベクトルを利用して、取り組んでいるタスク(「スパム検知」や「記事の要約」など)に応じた実装をする。
事前学習(Pre-Training)
Task#1: Masked LM (MLM) 穴埋め問題
Input: the man went to the [MASK1] . he bought a [MASK2] of milk.
Labels: [MASK1] = store; [MASK2] = gallon
- ランダムに一定数の単語をマスキング
- マスクした単語を予測するように学習
従来は文脈を考慮せずにtarget wordを予測していたため、プログラミング言語の"Python💻"とニシキヘビの"Python🐍"を同じものとみなしてしまう。
BERTでは穴埋め問題(Cloze test)のように前後の文脈から単語を予測させている。これによって
- DeepLearningとかクラウドが同じ文に含まれるぞ → プログラミング言語Python
- ジャングルとかコブラが同じ文に含まれるぞ → ニシキヘビPython
というように使い分けができるようになる。
Task#2: Next Sentence Prediction (NSP) 次文予測
Sentence A: the man went to the store .
Sentence B: he bought a gallon of milk .
Label: IsNextSentence
Sentence A: the man went to the store .
Sentence B: penguins are flightless .
Label: NotNextSentence
このように文Aと文Bが連続しているかどうかを予測させる。
これによって文と文の関係性や論理構造を学習できる=文脈を読み解くことができると言われているが…
このあたりは議論が多くなされているところで、実はよくわかっていない。
BERT以降様々な改良モデル1では**NSPの効果はそれほどないのでは?**という説も出てきている。
転移学習(Fine-Tuning)
Pre-Trainingモデルを利用して文や単語をベクトルとして表現できれば、あとはクラスタリングやクラス分類など好きなように応用することができる。
これがBERTがここまで注目されている最大の理由だ。
ここはデモを見てもらうのが早いのでサクサク次へ行こう。
環境構築
今回はGoogleColaboratory上で日本語BERTの環境構築を行う。
- BERT日本語Pretrainedモデル - KUROHASHI-KAWAHARA LABを利用
- 単語分割ではNagisaを利用
実際のモノを見た方が早い。
nagisa_bert/nagisa_bert.ipynb
中央のOpen in ColabというボタンをクリックするとGoogleColabで直接実行できるようになる。初心者でもセルを実行していけば何となく雰囲気は理解できるのでは?
なんでnagisaなの?
今回扱うPre-TrainedモデルはJUMAN++という単語分割ツールを用いているので、本来ならそちらに合わせるべきだ。
だが、しかし、but…下記の理由でnagisaを使うことにする。
-
pip install nagisaで導入できるのでGoogleColabで使いやすい- GoogleColabでJUMAN++を使うのはなかなかしんどいハズ
- single_word_listで柔軟に分割に対応できる
- SentencePieceやJUMAN++では分割の粒度が細かすぎる
- 特にナウい文章を分析するときは「タピオカミルクティー」とか「馬
と鹿」などを分割させたくない
- nagisa使ってみたい
確かにJuman++を使った方がvacabの語彙と近いというのはゴモットモだ。
だが、こちらをご覧いただきたい。
from pyknp import Juman
jumanpp = Juman()
result = jumanpp.analysis("「馬と鹿」は日本の男性ミュージシャン米津玄師の楽曲だ")
for mrph in result.mrph_list(): # 各形態素にアクセス
print(mrph.midasi)
['「', '馬', 'と', '鹿', '」', 'は', '日本', 'の', '男性', 'ミュージシャン', '米津', '玄師', 'の', '楽曲', 'だ']
え…「馬🐴」と「鹿🦌」?
「馬と鹿」がきちんとに分割されたところで、そんな単語ベクトルに誰が興味を持つんだ。だったら未知語[UNK]扱いでもいいから、「馬と鹿」という単語でしっかりベクトル化して欲しい。
米津玄師もそう。おそらくどちらも未知語扱いされそうなんだから「米津」「玄師」ではなくて「米津玄師」でしっかり一単語として処理して欲しい。
nagisaのsingle_word_listという機能を使えばこれがうまいこと柔軟に制御できるのだ。
import nagisa
text = "「馬と鹿」は日本の男性ミュージシャン米津玄師の楽曲だ"
words = nagisa.Tagger(single_word_list=['馬と鹿', '米津玄師']).tagging(text)
words.words
['「', '馬と鹿', '」', 'は', '日本', 'の', '男性', 'ミュージシャン', '米津玄師', 'の', '楽曲', 'だ']
大量のデータを扱うときは処理性能で優れているJUMAN++の方がいいかもしれない。
デモ
今年流行ったあの曲を可視化してみる
それでは聞いてください。
君とジョブの終わり 将来の夢
大きなサイズ忘れない
1年後の8月14日午前7時00分(実際の日時)
また出会えるのを信じて
最高の思い出を
出会いはふっとした瞬間
帰り道の交差点でひらめいてくれたね
「シェルで書いてcronで処理すれば当日コマンド打たなくてよくね?」
僕は照れくさそうに
crontab -e を打ちながら
本当はとてもとても
手抜きをしてた
あぁvimでシェルを綺麗に書いて
ちょっとドヤ顔
あぁログが時間とともに流れる
嬉しくって楽しくって
冒険もいろいろしたよね
二人の秘密のリポジトリ
君とジョブの終わり 将来の夢
日付でファイル作成し
1日後の朝7時
また出会えるのを信じて
痛恨の権限エラー
<中略>
君が最後まで
心から「消すの忘れないで」
叫んでたこと知ってたよ
涙を堪えて笑顔でrm -f
せつないよね
でかすぎるそのサイズ
突然の実行でどうしようもなく
始末書書くよログも残すよ
忘れないでね crontab -r
いつまでも

なんか見てると切なくなってくる…😥
おわりに
実際に動かしてみたい方はこちらからどうぞ
参考
-
RoBERTaやALBERTなど ↩