
今年の言語処理学会(NLP2018)では、形態素解析に関するワークショップ(形態素解析の今とこれから)が開催されました。そこで 「RNNを用いた日本語単語分割/品詞タグ付けツールの紹介」 というタイトルで LT を行いましたので、そのツールについて Qiita でもご紹介したいと思います。
発表したツールは nagisa という名前で Github に公開されており、これから NLP を始めようと考えている Python ユーザーの方にも使いやすいツールを目指し開発しています。
また PyCon JP 2019 では 「Python による日本語自然言語処理 〜系列ラベリングによる実世界テキスト分析〜」 というタイトルで発表しました。
発表スライド:https://speakerdeck.com/taishii/pycon-jp-2019
他の形態素解析器との違い
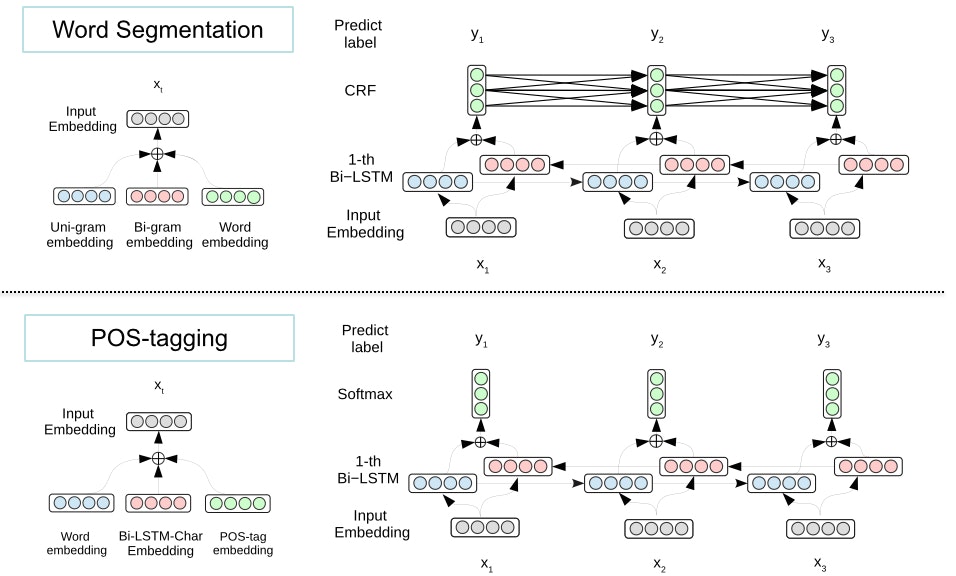
日本語の形態素解析器は、MeCab、 JUMAN++、 KyTea、 Sudachi などのソフトウェアが存在しますが、nagisa には以下の特徴があります。
-
pip install nagisaでインストール可能- パッケージにモデルファイルが含まれているので、辞書のインストールが不要です。
- Bidirectional-LSTM を用いた日本語単語分割と品詞推定
- Bi-LSTM を用いた文字単位の系列ラベリングによる解析を行うので、顔文字やURLに対して頑健な解析が可能です。
- 複数の後処理機能を備える
- ユーザーによる出力単語の微調整や品詞による出力単語のフィルタリングが可能です。
インストール方法
pip で簡単にインストールできます。
Linux、Windows、macOS をサポートしています。
pip install nagisa
基本的な使い方
import nagisa でインポートし、nagisa.tagging(text) で単語分割と品詞タグ付けを行います。
import nagisa
text = 'Pythonで簡単に使えるツールです'
words = nagisa.tagging(text)
print(words)
#=> Python/名詞 で/助詞 簡単/形状詞 に/助動詞 使える/動詞 ツール/名詞 です/助動詞
words.words で出力単語列のリストを得ることができ、words.postags では出力単語列に対応する品詞のリストを得ることができます。
print(words.words)
#=> ['Python', 'で', '簡単', 'に', '使える', 'ツール', 'です']
print(words.postags)
#=> ['名詞', '助詞', '形状詞', '助動詞', '動詞', '名詞', '助動詞']
品詞による出力単語のフィルタリング
引数に品詞を指定することで、出力単語をフィルタリングすることも可能です。
nagisa.extract は、必要な品詞の単語だけを抽出する関数です。
words = nagisa.extract(text, extract_postags=['名詞'])
print(words)
#=> Python/名詞 ツール/名詞
nagisa.filter は、不要な品詞の単語を取り除く関数です。
words = nagisa.filter(text, filter_postags=['助詞', '助動詞'])
print(words)
#=> Python/名詞 簡単/形状詞 使える/動詞 ツール/名詞
nagisa.tagger.postags には、利用可能な品詞の一覧が含まれていますので、品詞を確認しつつ、フィルタリングする品詞を選択することが可能です。
print(nagisa.tagger.postags)
#=> ['oov', '感動詞', '補助記号', 'web誤脱', '接尾辞', '動詞', '接頭辞', '言いよどみ', '形状詞', '形容詞', '空白', '助動詞', '英単語', '漢文', '未知語', '記号', '代名詞', '連体詞', 'URL', 'ローマ字文', '接続詞', '副詞', '名詞', '助詞']
出力単語を微調整する方法
入力として、「ニューラルネットワークを使ってます。」という文を nagisa に与えた場合、デフォルトの設定では「ニューラル/名詞」と「ネットワーク/名詞」の2つの単語として分割されてしまいます。
text = 'ニューラルネットワークを使ってます。'
print(nagisa.tagging(text))
#=> ニューラル/名詞 ネットワーク/名詞 を/助詞 使っ/動詞 て/助動詞 ます/助動詞 。/補助記号
例えば、「ニューラルネットワーク」は1つの単語として、出力して欲しいと思った場合、 nagisa.Tagger の引数に single_word_list=["ニューラルネットワーク"] と指定することで single_word_list に含まれる単語は強制的に1つの単語として出力することが可能です。
tagger_nn = nagisa.Tagger(single_word_list=['ニューラルネットワーク'])
print(tagger_nn.tagging(text))
#=> ニューラルネットワーク/名詞 を/助詞 使っ/動詞 て/助動詞 ます/助動詞 。/補助記号
すぐに利用できる日本語ストップワードを搭載
nagisaには日本語のストップワードリストが組み込まれているため、「の」「を」「に」などの不要な語を簡単に除去できます。
import nagisa
text = "日本語のストップワードを簡単に利用できます。"
tokens = nagisa.tagging(text)
print(tokens.words)
#=> ['日本', '語', 'の', 'ストップ', 'ワード', 'を', '簡単', 'に', '利用', 'でき', 'ます', '。']
# ストップワードを除外する
words = [word for word in tokens.words if word not in nagisa.stopwords]
print(words)
#=> ['日本', '語', 'ストップ', 'ワード', '簡単', '利用', '。']
顔文字やURLに対して頑健な解析
単語分割モデルでは、文字単位の Bidirectional-LSTM を用いて入力文の単語境界を求めるので、顔文字や URL を1つの単語として出力してくれます。
text = '(人•ᴗ•♡)こんばんは♪'
words = nagisa.tagging(text)
print(words)
#=> (人•ᴗ•♡)/補助記号 こんばんは/感動詞 ♪/補助記号
url = 'https://github.com/taishi-i/nagisaでコードを公開中(๑¯ω¯๑)'
words = nagisa.tagging(url)
print(words)
#=> https://github.com/taishi-i/nagisa/URL で/助詞 コード/名詞 を/助詞 公開/名詞 中/接尾辞 (๑ ̄ω ̄๑)/補助記号
おわりに
良い点はたくさん述べたものの、 MeCab と比較すると解析速度は非常に遅いなど、改善すべき点はまだまだ存在します。
ですが、もしプログラムを書いている途中に 「必要があるたびに名詞のみを抽出するプログラムを書いている」、「ユーザー辞書を準備するほどでもないけど、この単語の出力はこうなっていて欲しい」、「日本語ストップワードを利用したい」 などと思ったことがあるのであれば、一度 nagisa を試してみるのはいかがでしょうか?
ちょっとした手間を省けるような使いやすいツールを目指し nagisa の開発を続けたいと思います!
nagisa: https://github.com/taishi-i/nagisa
nagisa に関する記事
- Pythonで動く形態素解析ツール「nagisa」を使ってみた
- 形態素解析ツールのnagisa(なぎさ)を知っていますか?
- Japanese Text Segmentation and Analysis with Web ChaMame
- 「進撃の巨人」に一番似てる文章は?〜word2vec入門〜
- 日本語形態素解析エンジンnagisaは古典中国語(漢文)を学習できるのか
- Deep Manzai Part 2 〜 前半戦 〜
- Pythonで自分のどんなツイートが「いいね」されやすいかを分析してみた
- [PyCon2019] レポート Python による日本語自然言語処理 〜系列ラベリングによる実世界テキスト分析〜
- nagisaで自然言語処理を試してみる
- 日语分词器的介绍与比较
- Text Summarization of Japanese Articles using python and NLP
- An Overview of Japanese NLP Libraries