はじめに
前回、始めて3ヶ月の画像識別器と題して、作成した簡単な画像識別器についての記事を書いた。
前回の識別器ではドロップアウト層を除いて、入力層、中間層1、中間層2、出力層の4層のニューラルネットワークとした。その結果、手元の10問程度の問題で7~8割の正解率であった。
画像処理の世界では、CNN(Convolutional Neural Network)というやつが、優れた処理方法として知られているらしい。
そういうわけで、前回の識別器にCNNを実装してみた。
画像識別器について
前回同様、2種類の画像を用意して、一方を正解、もう一方を不正解として、新たに画像を見せたときに、正解か不正解かを決める分類器を作った。
用意したもの
- anaconda(python,tensorflow,keras,etc)
- jupyter notebook(anaconda)
- PC(そんないいやつじゃない)
作成したコード
前回同様、早速作成した、画像識別器のコードを以下に示します。
ここでは、女性の顔と、寺の画像を分けていますが、パスだけ変えてもらえれば他のでもできます。
ただ、識別能力は高くないので、似たような画像だとあんまりうまくいかないかも。
なるべく、前回と同じところは#が一つ、変えたところは##でコメントをつけたけど、あまりわかりやすくならなかった。
(写真は著作権の関係もあり表示を控えました。)
# 使用するモジュールの一部をimport
import os #パス(ディレクトリの場所)やファイルの操作等のモジュール
import glob #正規表現等のモジュール
import numpy as np #行列等を扱うモジュール
import cv2 #画像の入出力、変形等のモジュール
# X(女性の顔)についての設定
files = glob.glob('/Users/aaa/Desktop/AI/face_train/*.jpg')
# フォルダ内のそれぞれにファイルのパスを記録し、filesにリスト化
# X(女性の顔)の画像のファイル名をリスト化
files_mis = glob.glob('/Users/aaa/Desktop/AI/unknown/*')
# X(風景(寺))の画像のファイル名をリスト化
files_all = files + files_mis
# 画像ファイル名(パスつき)のリストを足し合わせる
files_count = len(files_all)
# files_allの写真の枚数を変数に入力
height = 32
width = 32
size = (height,width)
# 画像サイズの変更用変数(32*32の画像に圧縮)
### 前回は100*100であったが、CNNでは計算量が多くPCがフリーズしたため、32*32まで下げた。
count=0 #for文のカウント用
img_complete = np.empty((files_count*3,height,width))
# 指定の大きさの行列を適当な数値で作る。ここでは、後に画像を三倍に水増しするため、
# 写真の枚数の三倍の行とした。
## CNNでは、画像の行列をベクトルに直さない。
## 前回:[count,height*width],今回:[count,height,width]
for file in files_all: #学習用データのインプットと学習用にデータを変換
img = cv2.imread(file, cv2.IMREAD_GRAYSCALE)
#grayscaleで画像を読み込み
img_resize = cv2.resize(img,(height,width))
##画像サイズをheight*width(32*32)に変換
img_complete[count,:,:] = img_resize
##画像枚数*32*32の行列に変更
count = count+1
#カウントアップ
for i in (0,1): #90度と180度傾けたものを作成
img_flip = cv2.flip(img_resize,i)
##32*32にリサイズしたものを傾ける
##img_reshape = img_flip.reshape(height*width)
##傾けたものを1*10000に変形しない
img_complete[count,:,:] = img_resize
#学習用の行列につっこむ
count = count+1
#カウントアップ
print(count) #確認用
img_complete = img_complete/255.
# 画像データは0~255の配列。これを255で割り、0~1の値になおす。
X = img_complete.reshape(count,height,width,1)
## 後のConv2D層にいれる型に変形する。最後の数字が白黒だと1、RGBだと3。
print(X.shape) #確認用
(915, 32, 32, 1)
# yについての設定
y = np.ones((len(files)*3,1),dtype = 'int32')
y2 = np.zeros((len(files_mis)*3,1),dtype = 'int32')
Y = np.r_[y,y2]
# 正解データの設定、ここでは、女性の画像を1(正解)、寺の画像を0(不正解)とした。
# 3倍しているのは、90度と180度傾け、画像が3倍になっているため
from tensorflow.python.keras.models import Sequential
# kerasのSewuentialモデルをimport
from tensorflow.python.keras.layers import Dense
# lerasのレイヤーをimport
model = Sequential()
# 入力層
from tensorflow.python.keras.layers import Conv2D
## kerasのConv2D層(畳み込み層)をimport
model.add(
Conv2D(
filters=32,#出力チャンネルの数()
input_shape=(height,width,1),##input(ここではX)の形、RGBだと最後が3)
kernel_size=(3,3),#畳み込みのカーネルの大きさ
strides=(1,1),#畳み込みの際、何個ずつづらすか。
padding='same',#畳み込みによる画像の縮小を回避。'Valid'だと画像が少し小さくなる。
activation='relu'#活性化関数をレール関数とした。
)
)
## 上と同じ、入力層は書かなくて良い。
## 手元の本で、畳み込み層を2枚重ねていたので、それに習った。
model.add(
Conv2D(
filters=32,
kernel_size=(3,3),
strides=(1,1),
padding='same',
activation='relu'
)
)
from tensorflow.python.keras.layers import MaxPooling2D
## プーリング層のimport
model.add(MaxPooling2D(pool_size=(2,2)))
## プーリング層の追加。pool_sizeは画像サイズが大きいともっと大きな値とするとよいのかもしれない。
from tensorflow.python.keras.layers import Flatten
# Flatten層のimport
model.add(Flatten())
## 以下のDense層では、2次元テンソルしか投入できないため、ここで、Flatten層で行列を展開
# 入力層
model.add(Dense(units = height*width/8,input_shape = (height*width,),activation = 'relu'))
## 1層目の出力を入力の1/8とし、活性化関数をreLu関数とした(適当)。
## 前回は1/10としたが、units数は整数でないといけないため、割り切れる数とした。
model.output_shape #確認用
(None, 128)
from tensorflow.python.keras.layers import Dropout
# Dropout層を入れることで過学習を減らせるとのことなので、いれてみた(適当)。
model.add(Dropout(0.1))
# 画像の枚数も多くないので、Dropoutの率を1割としてみた(適当)。
# 中間層1
model.add(Dense(units = height*width/8,activation = 'relu'))
## 出力を入力と揃え、活性化関数をreLu関数とした(適当)。
## 入出力のunit数は同じにするのが基本らしい。
model.output_shape #確認用
model.add(Dropout(0.1))
# 画像の枚数も多くないので、Dropoutの率を1割としてみた(適当)。
# 中間層2
model.add(Dense(units = height*width/8,activation = 'relu'))
## 出力を入力と揃え、活性化関数をreLu関数とした(適当)。
## 入出力のunit数は同じにするのが基本らしい。
model.output_shape
# 出力層
model.add(Dense(units = 1,activation = 'sigmoid'))
# sigmoid関数での出力。softmaxだとunits数が2になるのかもしれない。
# その場合はYを1hot化するのか?
model.output_shape
# compile
model.compile(
optimizer = 'adam',
loss = 'binary_crossentropy',
metrics = ['accuracy']
)
# modelのコンパイル
# adamを使うと学習率を決めなくてよいらしい。
# 2値分類だとbinaryを使う。metricsはまだ良くわかってない。
from tensorflow.python.keras.callbacks import TensorBoard
# tensorboardの利用
tsb = TensorBoard(log_dir = '180718face_CNN')
# tensorbardを利用するためにlogを記録。決めた名前のディレクトリが作成される。
# modelfit
history_adam = model.fit(
X,
Y,
batch_size = 90,
epochs = 15,
validation_split = 0.2,
callbacks = [tsb]
)
# modelfitで学習を開始する。
# batch_size,epochsは違う画像で数種類ためして良さそうな数値とした。
# validation_splitは学習データとテストデータの比。一般的に0.2らしい。
# callbacksはテンソルボードに記録する。
結果、以下のようなものが表示されるはず。
Train on 732 samples, validate on 183 samples
Epoch 1/15
732/732 [==============================] - 2s 3ms/step - loss: 0.6532 - acc: 0.6175 - val_loss: 0.2498 - val_acc: 1.0000
Epoch 2/15
732/732 [==============================] - 2s 2ms/step - loss: 0.4412 - acc: 0.8087 - val_loss: 1.1566 - val_acc: 0.4426
:
:
Epoch 15/15
732/732 [==============================] - 2s 2ms/step - loss: 4.5094e-04 - acc: 1.0000 - val_loss: 0.0672 - val_acc: 0.9836
層の構成
作成した層は以下のコードで確認できる。
model.summary()
# modelがどのような層構造をしているかの確認

学習過程の出力
出力方法は前回と一緒なので割愛。
出力結果は以下。val_lossが増えているような気もするので、少し過学習をしているのかもしれない。それもあって、epoch数を少し減らしている(前回は40)。
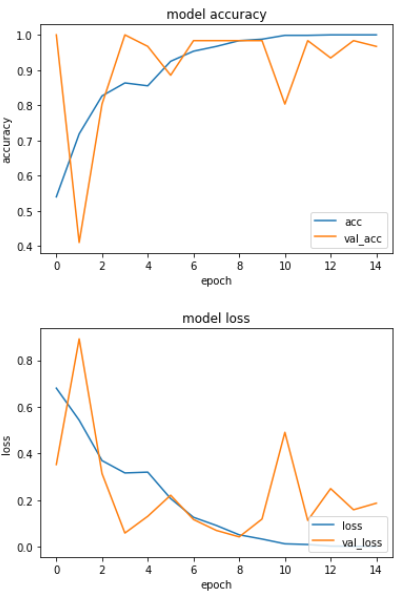
学習モデルの利用
作った層に投入できる形に合わせるので、前回と少し違うけど基本一緒なのでコードは割愛。
10問程度だけど、与えた問題に対しては全問正解した。
# テスト用データについての設定(やっていることは上とおなじ)
# 学習用データをニューラルネットワークに突っ込む前と同じ形にする。
files_test = glob.glob('/Users/CRT401/Desktop/AI/test/*')
count_test=0
height = 32
width = 32
size = (height,width)
img_test = np.empty((len(files_test),height,width,1))
for file in files_test:
img3 = cv2.imread(file, cv2.IMREAD_GRAYSCALE)
img_resize3 = cv2.resize(img3,size)
img_reshape3 = img_resize3.reshape(height,width,1)
img_test[count_test,:,:] = img_reshape3
count_test = count_test+1
img_test_255 = img_test/255.
print(img_test_255.shape)
TEST = model.predict(img_test_255)
# test用データを学習済みのモデルに突っ込む
# たぶんテストデータが1枚だとうまくいかない
Len = TEST.shape
test_t = np.zeros(Len)
count = 0
for t in TEST:#学習済みの0.5より小さければ1(正解)、それ以外なら0を出力
if t > 0.5:
test_t[count] = 1
else:
test_t[count] = 0
count = count + 1
print(test_t)
[[0.]
[1.]
:
[0.]]
感想
苦労した点
- 相変わらずなれていないので時間はかかる。
- 層に投入する形が前回と違ったので、前処理を変更しなければいけなかった。
- 画像サイズが大きいとPCがフリーズしてしまうため、相当小さくしなければいけなかった。
面白かった点
- CNNっていうのがよくわかっていなくても、モデルは作れる。
- kerasでやると、CNNにしたからといって特別な苦労はなかった。
- CNN使うと、正解率がすごい。
今後の予定と抱負
- ラズパイとの組み合わせ
- optimizerとかactivationとかの関数のブラッシュアップ
- kaggleっていうやつをやってみたい。(今は、titanicをこねくり回している)
おわりに
CNNというのを導入してみた。仕組みをよく理解しているわけではないけど、ちゃんと機能しているらしい。
勉強するほど、勉強しなきゃいけないことが増えるけど、プログラミングはすぐに試せて、結果がでるので楽しい。
今、kaggleのtitanicで遊んでいるので、今度はそれについて書きたい。
ここまで、読んでいただきありがとうございました。