はじめに
前から機械学習がやってみたかったのだけど、それを会社で言っていたら、3ヶ月前から仕事中にやることを許されたのでまじめに勉強することにした。
とりあえず、画像の識別ができるようになるまで色々な苦労があったわけだけど、それっぽいことができるようになったので、上げてみる。
なるべく、毎行説明をいれ、つまずいたこともなるべく書くようにしたため、同じ初学者の助けになればと思う。
また、詳しい方いたら、良いところ悪いところ、こうした方がよい等コメントくれると嬉しいです。
初期スペック
- 大学は金属系、仕事は機械系
- Pythonによる機械学習入門(株式会社システム計画研究所)を読んだことがある。
- ニューラルネットワーク自作入門(マイナビ出版)を読んだことがある。
- プログラミング経験はプロゲートのpython講座をやったことがあるくらい。
ここ3ヶ月でやったこと
- python、機械学習の勉強会に参加した。
- courseraの機械学習コースを勉強中(6週目)。
- raspberry PiでLチカしたりした。
画像識別器について
2種類の画像を用意して、一方を正解、もう一方を不正解として、新たに画像を見せたときに、正解か不正解かを決める分類器を作った。
用意したもの
- anaconda(python,tensorflow,keras,etc)
- jupyter notebook(anaconda)
- PC(そんないいやつじゃない)
作成したコード
早速作成した、画像識別器のコードを以下に示します。
ここでは、女性の顔と、寺の画像を分けていますが、パスだけ変えてもらえれば他のでもできます。
ただ、識別能力は高くないので、似たような画像だとあんまりうまくいかないかも。
(写真は著作権の関係もあり表示を控えました。)
# 使用するモジュールの一部をimport
import os #パス(ディレクトリの場所)やファイルの操作等のモジュール
import glob #正規表現等のモジュール
import numpy as np #行列等を扱うモジュール
import cv2 #画像の入出力、変形等のモジュール
# X(女性の顔)についての設定
files = glob.glob('/Users/aaa/Desktop/AI/face_train/*.jpg')
# フォルダ内のそれぞれにファイルのパスを記録し、filesにリスト化
# X(女性の顔)の画像のファイル名をリスト化
files_mis = glob.glob('/Users/aaa/Desktop/AI/unknown/*')
# X(風景(寺))の画像のファイル名をリスト化
files_all = files + files_mis
# 画像ファイル名(パスつき)のリストを足し合わせる
files_count = len(files_all)
# files_allの写真の枚数を変数に入力
height = 100
width = 100
size = (height,width)
# 画像サイズの変更用変数(100*100の画像に圧縮)
count=0 #for文のカウント用
img_complete = np.empty((files_count*3,height*width))
# 指定の大きさの行列を適当な数値で作る。ここでは、後に画像を三倍に水増しするため、
# 写真の枚数の三倍の行とした。
for file in files_all: #学習用データのインプットと学習用にデータを変換
img = cv2.imread(file, cv2.IMREAD_GRAYSCALE)
#grayscaleで画像を読み込み
img_resize = cv2.resize(img,(height,width))
#画像サイズをheight*width(100*100)に変換
img_reshape = img_resize.reshape(height*width)
#画像を100*100から1*10000に変形
img_complete[count,:] = img_reshape
#画像枚数×10000の行列に変更
count = count+1
#カウントアップ
for i in (0,1): #90度と180度傾けたものを作成
img_flip = cv2.flip(img_resize,i)
#100*100にリサイズしたものを傾ける
img_reshape = img_flip.reshape(height*width)
#傾けたものを1*10000に変形
img_complete[count,:] = img_reshape
#学習用の行列につっこむ
count = count+1
#カウントアップ
print(count) #確認用
X = img_complete/255.
# 画像データは0~255の配列。これを255で割り、0~1の値になおす。
# yについての設定
y = np.ones((len(files)*3,1),dtype = 'int32')
y2 = np.zeros((len(files_mis)*3,1),dtype = 'int32')
Y = np.r_[y,y2]
# 正解データの設定、ここでは、女性の画像を1(正解)、寺の画像を0(不正解)とした。
# 3倍しているのは、90度と180度傾け、画像が3倍になっているため
from tensorflow.python.keras.models import Sequential
# kerasのSewuentialモデルをimport
from tensorflow.python.keras.layers import Dense
# lerasのレイヤーをインポート
model = Sequential()
# 入力層
model.add(Dense(units = height*width/10,input_shape = (height*width,),activation = 'relu'))
# 1層目の出力を入力の1/10とし、活性化関数をreLu関数とした(適当)。
model.output_shape #確認用
from tensorflow.python.keras.layers import Dropout
# Dropout層を入れることで過学習を減らせるとのことなので、いれてみた(適当)。
model.add(Dropout(0.1))
# 画像の枚数も多くないので、Dropoutの率を1割としてみた(適当)。
# 中間層1
model.add(Dense(units = height*width/100,activation = 'relu'))
# 2層目の出力を入力の1/100とし、活性化関数をreLu関数とした(適当)。
model.output_shape #確認用
model.add(Dropout(0.1))
# 画像の枚数も多くないので、Dropoutの率を1割としてみた(適当)。
# 中間層2
model.add(Dense(units = height*width/100,activation = 'relu'))
# 中間層が1層だとうまく学習せず、なんとなく増やしたら学習するようになった。
model.output_shape
# 出力層
model.add(Dense(units = 1,activation = 'sigmoid'))
# sigmoid関数での出力。softmaxだとunits数が2になるのかもしれない。
# その場合はYを1hot化するのか?
model.output_shape
# compile
model.compile(
optimizer = 'adam',
loss = 'binary_crossentropy',
metrics = ['accuracy']
)
# modelのコンパイル
# adamを使うと学習率を決めなくてよいらしい。
# 2値分類だとbinaryを使う。metricsはまだ良くわかってない。
from tensorflow.python.keras.callbacks import TensorBoard
# tensorboardの利用
tsb = TensorBoard(log_dir = '180706face_test001_advance')
# tensorbardを利用するためにlogを記録。決めた名前のディレクトリが作成される。
# modelfit
history_adam = model.fit(
X,
Y,
batch_size = 90,
epochs = 40,
validation_split = 0.2,
callbacks = [tsb]
)
# modelfitで学習を開始する。
# batch_size,epochsは違う画像で数種類ためして良さそうな数値とした。
# validation_splitは学習データとテストデータの比。一般的に0.2らしい。
# callbacksはテンソルボードに記録する。
以上を実行すると、下のような表示がされ、学習とテストが実行されるはず。
Train on 732 samples, validate on 183 samples
Epoch 1/40
732/732 [==============================] - 2s 3ms/step - loss: 2.4210 - acc: 0.5178 - val_loss: 2.6244 - val_acc: 0.0000e+00
Epoch 2/40
732/732 [==============================] - 2s 2ms/step - loss: 1.3193 - acc: 0.4959 - val_loss: 0.7171 - val_acc: 0.4973
:
:
Epoch 40/40
732/732 [==============================] - 2s 2ms/step - loss: 0.3454 - acc: 0.8320 - val_loss: 0.1584 - val_acc: 0.9399
学習過程の出力
teriminalから以下を実行し、tensorboardを起動すると、学習過程がみれます。
細かいところですがlogdirとディレクトリ名の間のイコールの前後にスペース入れたりすると出てきません。
(僕はこれで半日悩みました)
tensorboard --logdir=180706face_test001_advance
その場で表示させる下記のほうが使いやすいかもしれない。
import matplotlib.pyplot as plt
def plot_history(history_adam):
# print(history.history.keys())
# 精度の履歴をプロット
plt.plot(history_adam.history['acc'])
plt.plot(history_adam.history['val_acc'])
plt.title('model accuracy')
plt.xlabel('epoch')
plt.ylabel('accuracy')
plt.legend(['acc', 'val_acc'], loc='lower right')
plt.show()
# 損失の履歴をプロット
plt.plot(history_adam.history['loss'])
plt.plot(history_adam.history['val_loss'])
plt.title('model loss')
plt.xlabel('epoch')
plt.ylabel('loss')
plt.legend(['loss', 'val_loss'], loc='lower right')
plt.show()
# 学習履歴をプロット
plot_history(history_adam)
# 参考、引用:http://aidiary.hatenablog.com/entry/20161109/1478696865
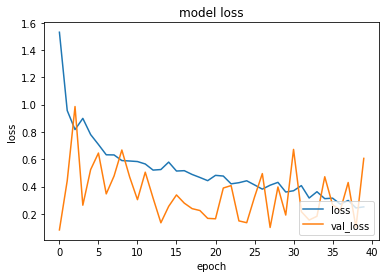
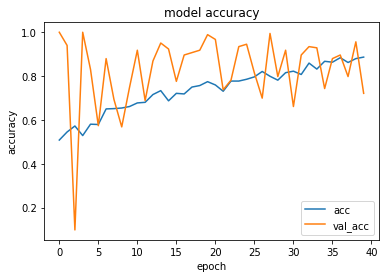
以下のようなものが表示される。
val_accやval_lossを見ると、なんとなく学習しているような気はするけど、性能はよくなさそう。
CNNとか使えばよくなるのかもしれない。(後日、試したところだいぶよくなった)
学習モデルの利用
ここでは、学習させたモデルを利用して、新たなテストデータに対して画像識別をさせてみた。
# テスト用データについての設定(やっていることは上とおなじ)
# 学習用データをニューラルネットワークに突っ込む前と同じ形にする。
files_test = glob.glob('/Users/aaa/Desktop/AI/test/*')
count_test=0
height = 100
width = 100
size = (height,width)
img_test = np.empty((len(files_test),height*width))
for file in files_test:
img3 = cv2.imread(file, cv2.IMREAD_GRAYSCALE)
img_resize3 = cv2.resize(img3,size)#100*100に変更
img_reshape3 = img_resize3.reshape(height*width)
img_test[count_test,:] = img_reshape3
count_test = count_test+1
img_test_255 = img_test/255.
TEST = model.predict(img_test_255)
# test用データを学習済みのモデルに突っ込む
# なぜかテストデータが1枚だとうまくいかない
Len = TEST.shape #テストに使う枚数
test_t = np.zeros(Len) #テストに使う枚数の行列を作成
count = 0
for t in TEST:#学習済みの0.5より小さければ1(正解)、それ以外なら0を出力
if t > 0.5:
test_t[count] = 1
else:
test_t[count] = 0
count = count + 1
print(test_t)
以下のようなものが表示される。枚数が少なかったので、自分で見比べて、7~8割くらいの正解率だった。val_accを見てもそのくらい。
[[0.]
[1.]
:
[0.]]
感想
苦労した点
- 今回は自信もないので書いていないけど、とにかく環境構築が一番苦労した。パスって何?仮想環境って何?ってところから始めているので、そこが一番難しかった。PCを何度も動かなくしている。
- プログラムをあまり書かない人間からすると、当然だけど一文字違うだけで動かないので、誤字によって動かないのか、書き方がおかしいのかとか、何が原因かわからずはじめのうちはエラーメッセージもまともに読めないので苦労した。
- 層の数とかで何故か動かなかったりとか、原因がわからないままのトラブルが多い。
面白かった点
- 機械学習は、パラメータ少しいじったくらいでは、あんまり変化がないのが意外だった。
- 画像を変えるだけで、プログラムを変えなくても学習してくれるのが意外だったし、色々できて面白い。
- よくわかっていなくても、意外に動く。
今後の予定と抱負
- ラズパイとの組み合わせ
- CNNの導入(すでにやってみたけど、だいぶ学習率がよくなった。今度書こうと思う)
- optimizerとかactivationとかの関数とか適当なところをもう少し勉強していじってみたい。
おわりに
機械系とか材料系とかその他諸々、勉強したけど、システム系ほど色々情報が世に出ていて、個人レベルで積極的にアウトプットされている業界はないと思う。
今回もQiitaや色々な個人サイトを参考にさせていただきました。なんとか、それっぽいことがここまでできたのも、こういったサイトや個人のおかげだとおもってます。ありがとうございました。
ちなみに、本では「現場で使えるTensorflow開発入門」がとても役立ちました。
ここまで読んでくれてありがとうございます。