iOS 11 で追加された Core ML と、iOS 10 の頃からある Metal Performance Shaders の CNN、Accelerate の BNNS について、2017年7月に勉強会で話した際のスライドです。

発表の概要
iOS 11で追加されたCore MLが非常に注目を集めていますが、「既存の機械学習ツールを使って学習させたモデル(のパラメータ)をiOS側に持ってきて推論を実行する」ということ自体はiOS 10からありました。
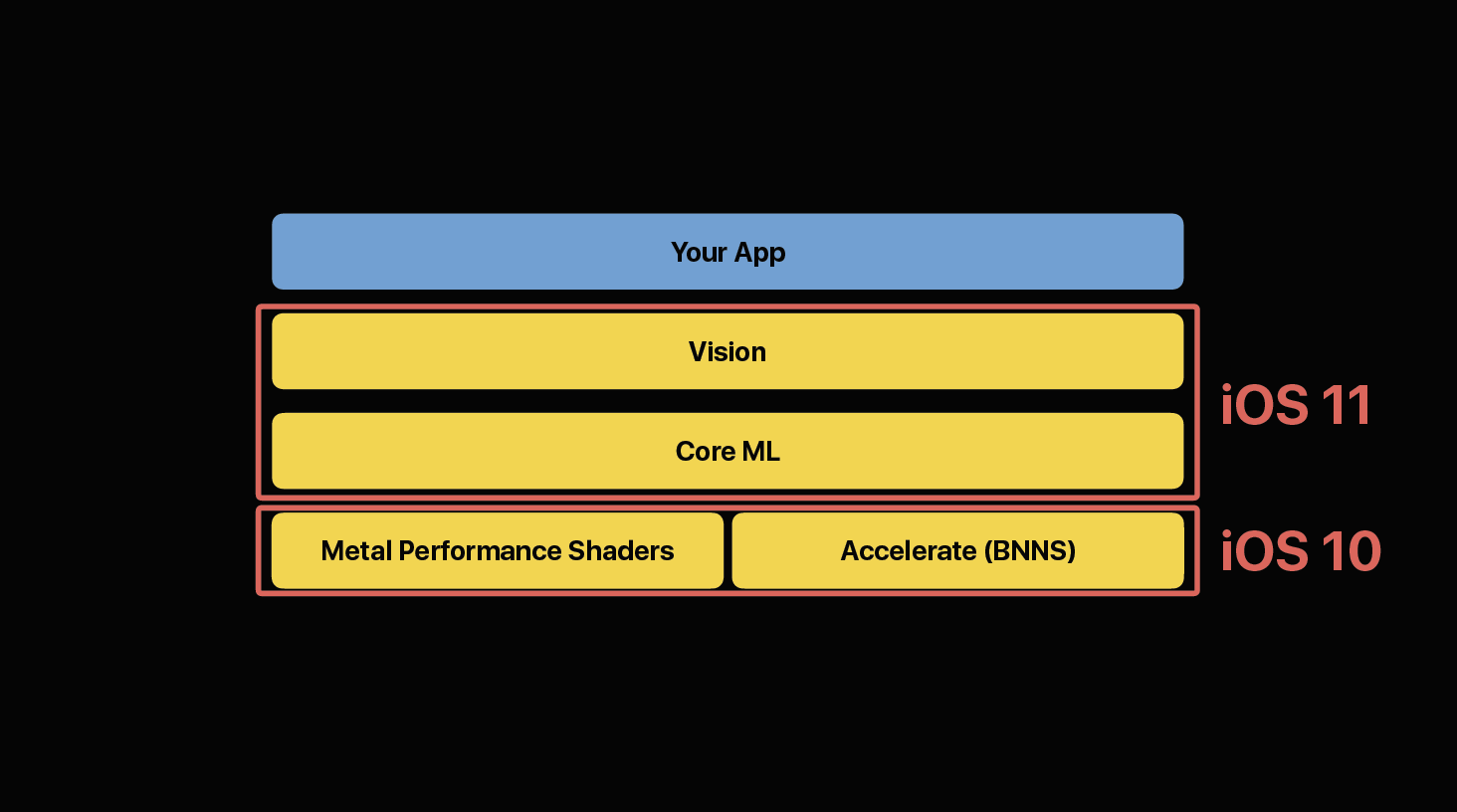
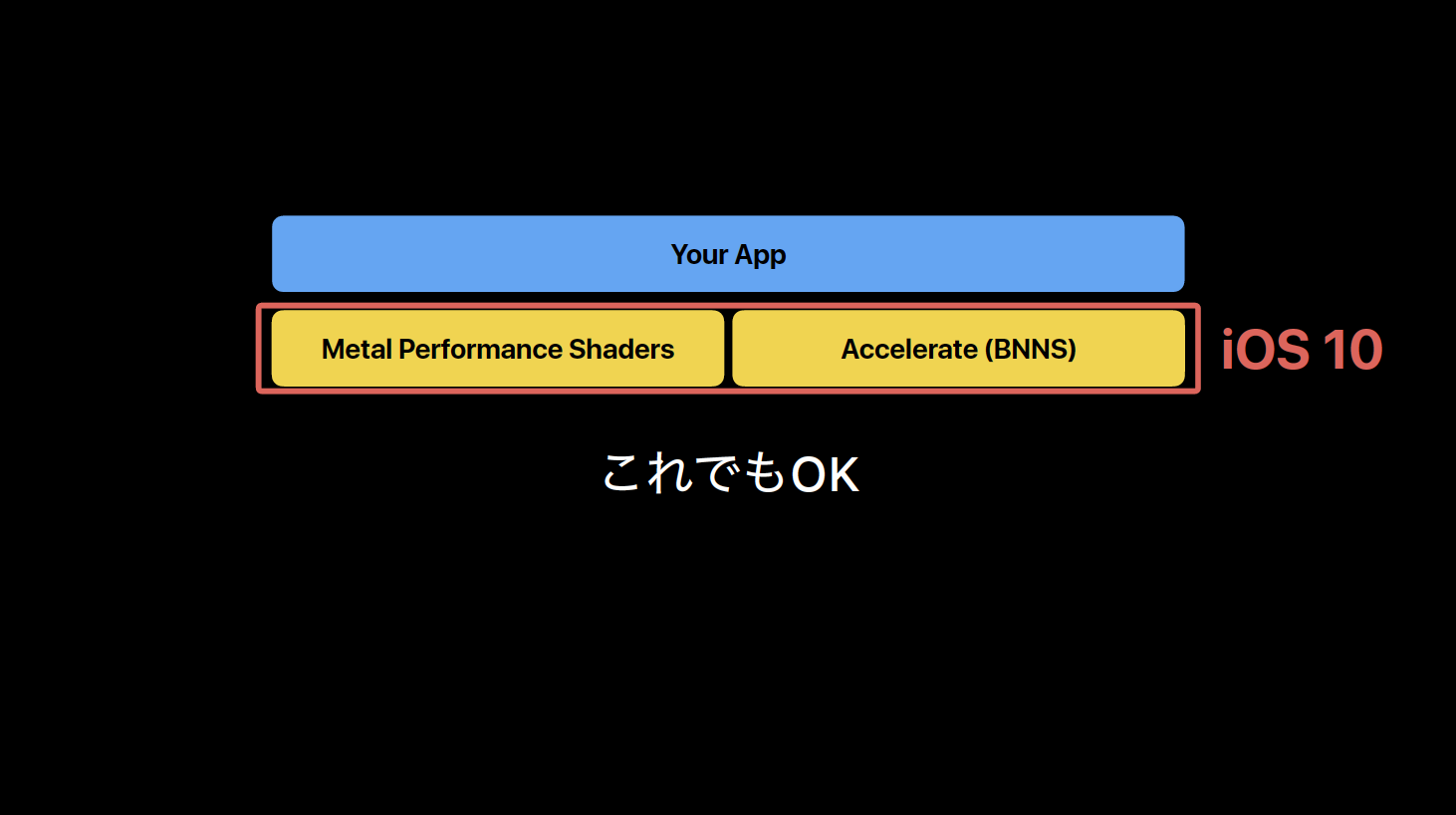
そして、そこに不便さがあったので広まらず、Core MLで改善されたことにより使われるようになった、という側面はもちろんありつつも、いややはりそれでも単にそういうことがiOS 10できるようになったということ自体が知られていなかっただけなのでは、と Core ML と Metal Performance Shaders の注目度のあまりの違いから考えていました。
それにしてもCoreMLはこんなに話題になるのに、なぜMPSCNNはあんまり盛り上がらなかったのか。「iOS側でのネットワーク実装とかモデル持ってくるのとか色々面倒」というCoreMLで改善された部分がネックになる以前に、そもそも
— Shuichi Tsutsumi (@shu223) 2017年7月16日
(つづき)そもそも「他ツールで学習させたモデルを利用してiOS側で推論を実行できるようになったよ」っていうこと自体もあまり知られてなかった気がする。(そしてCore MLでそれができるようになった!って言ってる記事も見かける。。) https://t.co/SA23gU4WII
— Shuichi Tsutsumi (@shu223) 2017年7月16日
確かに自分も Metal Performance Shaders のCNN APIを用いた機能を実装しようとしたときに、情報があまりに少なく、何ができて何ができないのか、どうやるのかがよくわからなかった、ということがありました。
で、そのへんをシンプルに説明したら、もっと興味をもつ人も出てくるんじゃないかなと思い、実装手順を3ステップで解説してみました。
MPSCNNを用いた機械学習機能の実装手順3ステップ
Step 1: モデルをつくる
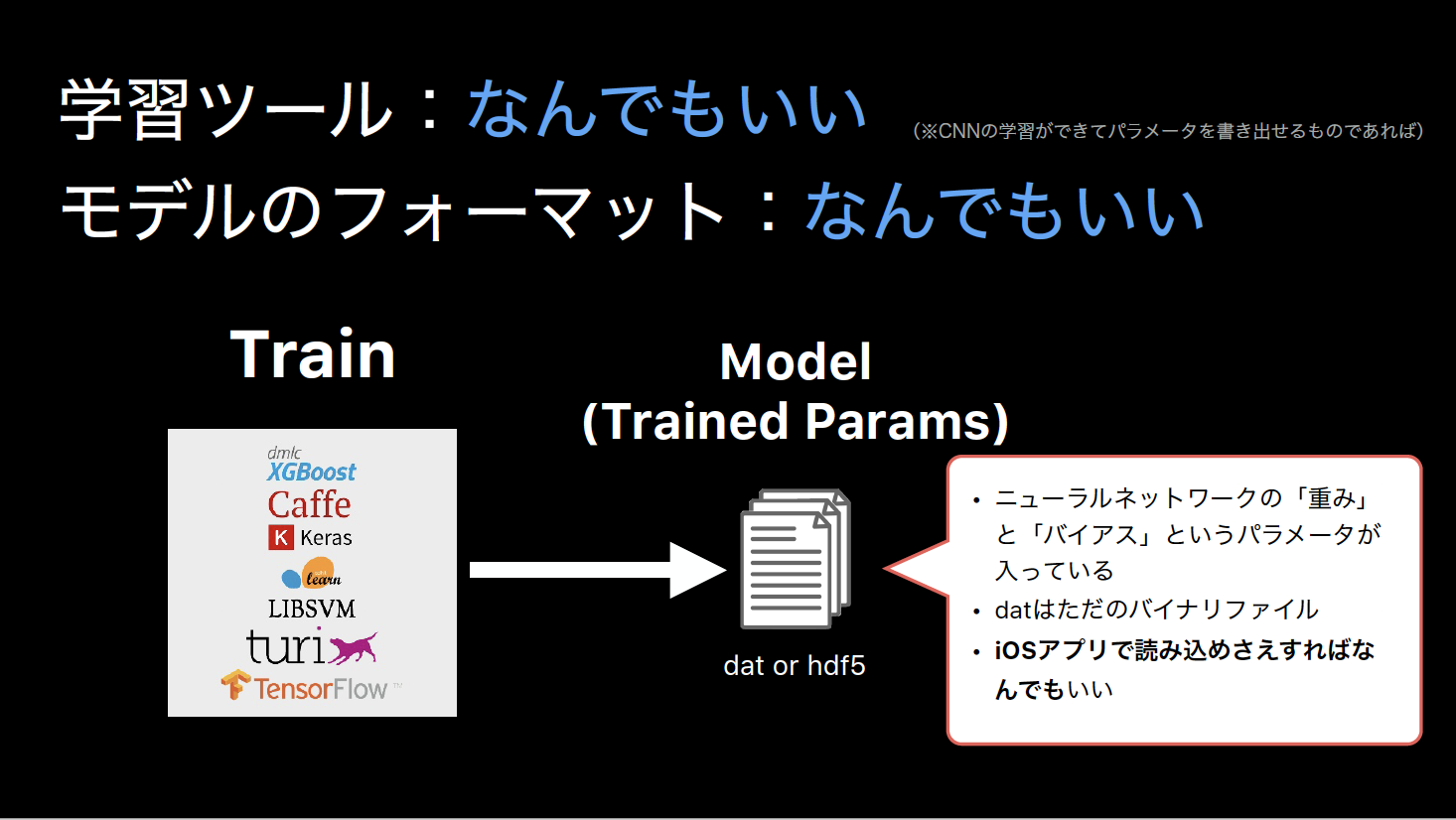
Core ML は Keral, Caffe, scikit-learn, etc. といったメジャーな機械学習ツールで学習させたモデルからのコンバートをサポートしていることが大きなポイントですが、それらの学習結果を「使える」という点ではMPSCNNも同様です。
Step 2: ネットワークを実装する
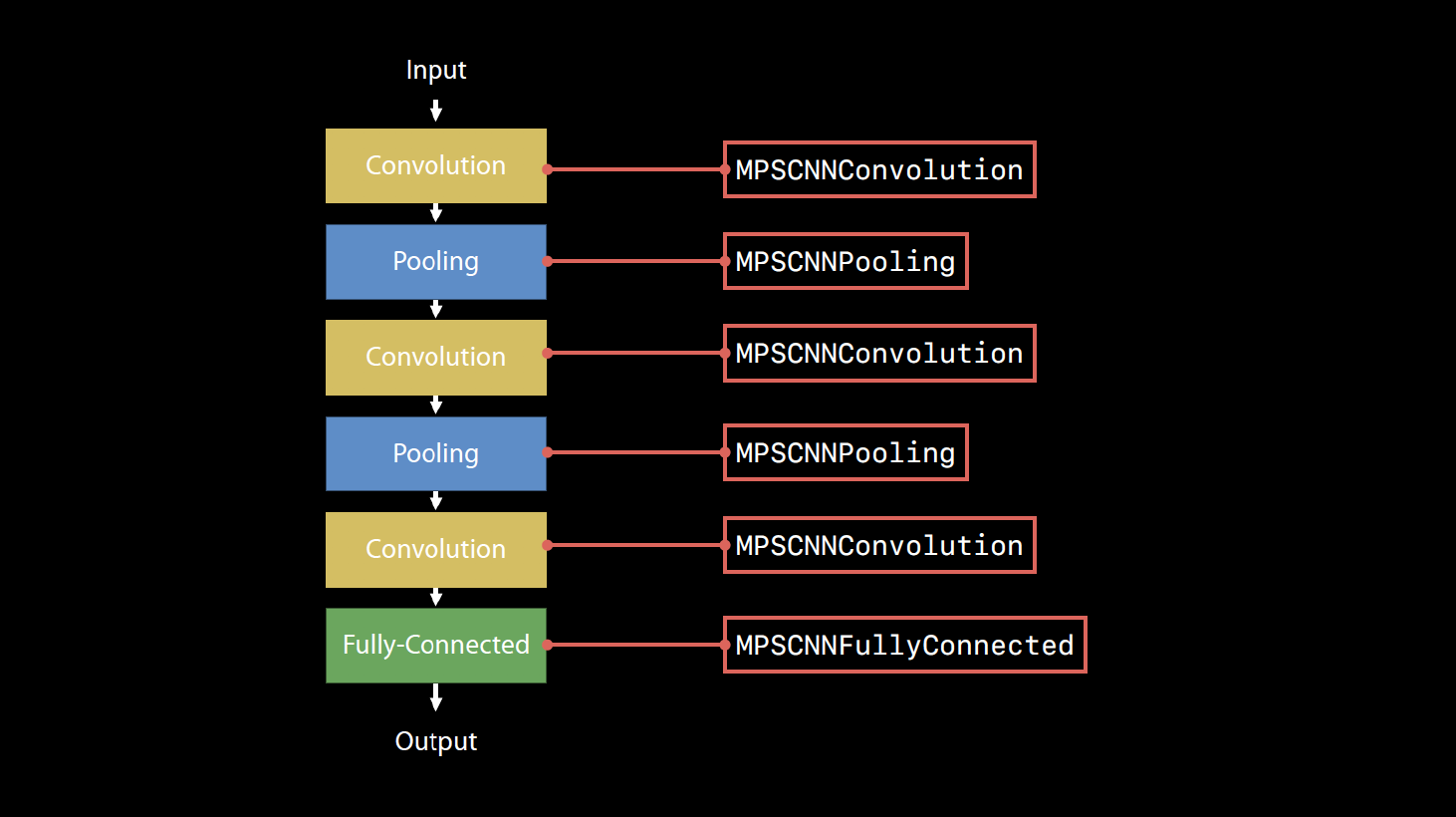

Step 3: 推論の実行処理を書く
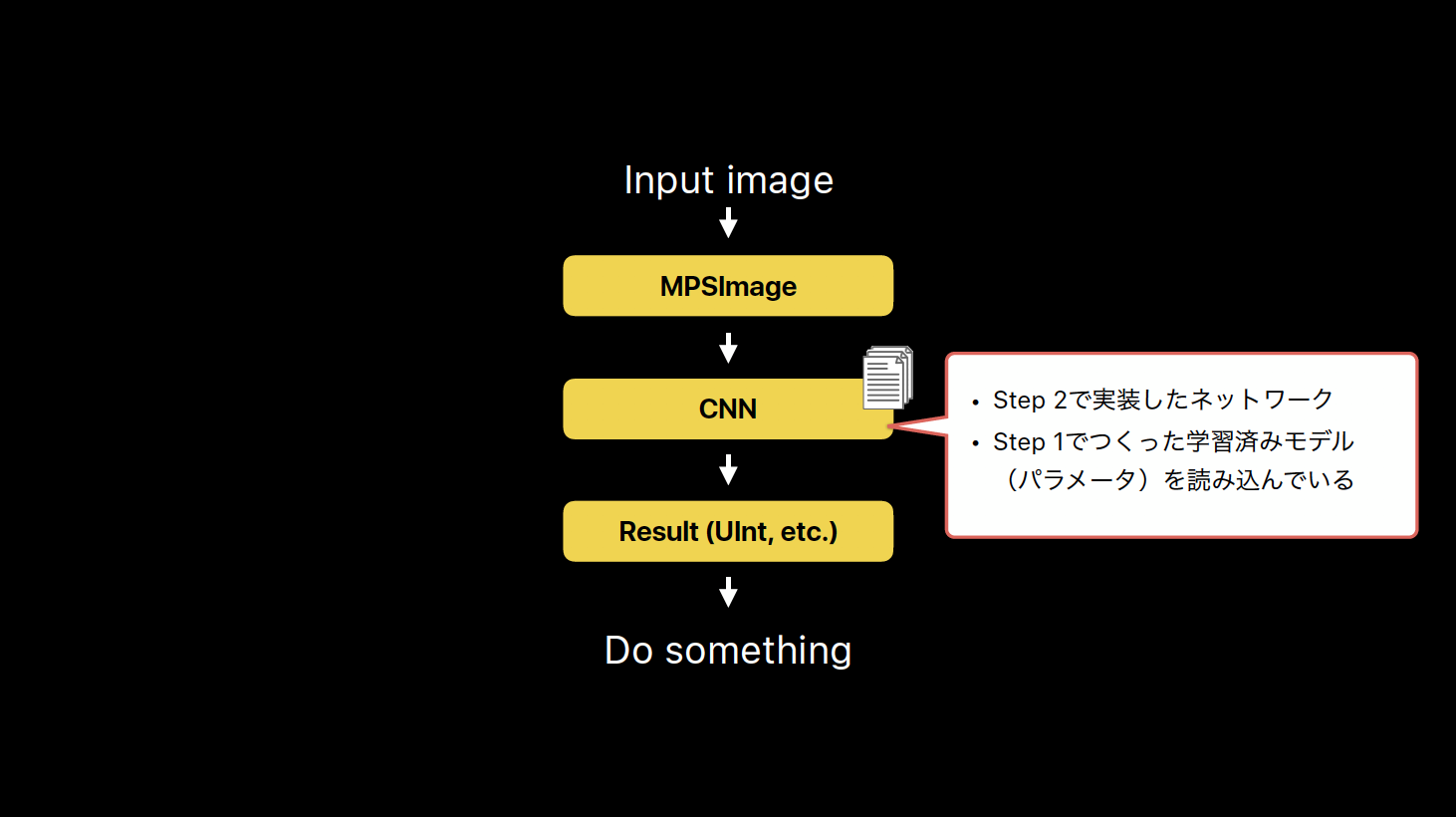
MPSCNN のつらみと Core ML & Vision
上記のMPSCNNを用いた実装手順、意外と簡単そう/使えそう と思っていただけたのではないでしょうか?
ところが・・・


っていうつらさがあり、他にも色々と面倒な点があり、やっぱりCore ML & Visionのおかげで各段に便利になった、という話をスライドに書いています。
BNNS の使いどころ、MPSCNN との使い分け
最後にAccelerateフレームワークのBNNSの使いどころについてWWDC17のMetal Labで聞いた話が出てきます。

BNNSについていただいたコメント
この点について、スライドを読んだsonsonさんからFacebookでコメントいただきました。
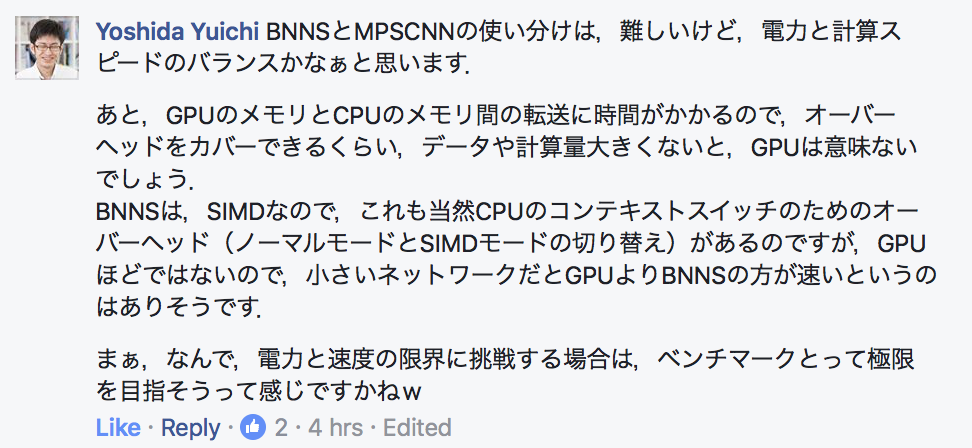
BNNSとMPSCNNの使い分けは,難しいけど,電力と計算スピードのバランスかなぁと思います.
あと,GPUのメモリとCPUのメモリ間の転送に時間がかかるので,オーバーヘッドをカバーできるくらい,データや計算量大きくないと,GPUは意味ないでしょう.
BNNSは,SIMDなので,これも当然CPUのコンテキストスイッチのためのオーバーヘッド(ノーマルモードとSIMDモードの切り替え)があるのですが,GPUほどではないので,小さいネットワークだとGPUよりBNNSの方が速いというのはありそうです.
まぁ,なんで,電力と速度の限界に挑戦する場合は,ベンチマークとって極限を目指そうって感じですかねw
なるほど、単に「CNNの計算はGPUが向いてるでしょ」とか「Appleの人も言ってた」とかってだけでBNNSのことは忘れようとか言ってちゃいけない、と反省しました。
確かに GPU <-> CPU間の転送速度のボトルネックとGPUによる高速化がどれぐらい見込まれるかのバランスによる というのは非常に納得です。また「SIMDモードへの切り替えのオーバーヘッド」(はあるがGPUとの転送ほどではない)というあたりもまったく考慮できてなかったところです。
CPU、GPUの負荷がそれぞれどれぐらいか、というのはXcodeで簡単に見れますが、GPU <-> CPU間の転送状況を見る方法もあるのでしょうか?GPUまわりの計測・デバッグ手法はもうちょっと勉強したいところです。