はじめに
CouseraのMachine Learning → Python 機械学習プログラミング → ゼロから作るDeepLearning と歩んできて、次は応用編やりたいなと思っていたところに自動運転関連のニュース。それで選んだ選んだこのテーマ。単純です。
自身の理解を整理するためのまとめですので、素人の意訳的な表現が随所にあります。そして、数学には全く精通していませんので、数式での解説はしません。(出来ません。)
内容の重複、誤り等々あると思いますので、コメントにてご指摘頂けるとありがたいです。
Mask R-CNN 概要
Mask R-CNN とは ICCV 2017 Best Paper に選出された手法で、物体検出やセグメンテーションを実現するための手法です。
ICCV とは International Conference on Computer Vision の略で、コンピュータービジョンの世界では最高峰のカンファレンスであり、最先端の研究内容が一堂に会する場であるようです。おそらく。
Mask R-CNNが有する機能と実現方法
ざっくりとまとめてみます。
物体検出とクラス識別
- 画像中の物体らしき領域とその領域が表すクラスを検出することを指します。
- 物体らしき領域は、画像を特定の領域に区切り、それらをしらみつぶしに評価することで得られます。
物体らしき領域は大量に検出されることになりますが、その中から「物体らしさ」が閾値以上の領域のみ、また、領域同士の重なりが閾値以上の領域群から「それらしさ」が最も高い領域のみ、といった条件で絞り込むことで、精度の高い結果が得られます。 - クラスは(当然ではありますが)学習で利用したデータセットに含まれるクラスそれぞれについて、「物体らしさ」を指す確率で得られます。
この確率は上記の「物体らしき領域」毎に得られますが、その領域毎に最も確率が高いクラスのみを採用します。
-- 例えば、クラスが1〜3まであり、物体らしき領域Rが得られたとして、そのRに関連するクラス群の確率が [0.1, 0.9, 0.1] と得られたとすると、その領域が示すものはクラス2であると判断します。色々と前置きが無いですが、ご容赦を。 - 結果的に以下のように領域とクラスが検出されます。

引用元: Faster R-CNN
これは入力となる画像上に検出結果である領域とクラス名+確率を表示したもので、自動運転や監視映像解析関連のニュース映像等でよく見る絵かと思います。
セグメンテーション
- 画像中のピクセル毎にクラスを検出することを指します。
- 画像全体をセグメンテーションする場合、結果は以下のような感じで表現されます。

引用元: http://jamie.shotton.org/work/research.html - Mask R-CNNでは物体検出結果として得られた領域についてのみセグメンテーションします。
これは、全ピクセルについてクラス検出よりもだいぶ効率的のように思えます。 - しっかりと学習できたMask R-CNNのモデルであれば、以下のようなセグメントが得られます。(私の場合は学習不足でこんなに綺麗な出力は得られませんでしたが。。。)
 引用元: [Mask R-CNN]
引用元: [Mask R-CNN]
ポーズ推定(ボーン検出、キーポイント検出)
- 人物の関節等のキーポイントを検出することを指します。
- Mask R-CNNのモデルからは人物の関節と姿勢が得られます。
 引用元: [Mask R-CNN]
- Mask R-CNNの応用編的な技術であり、私が試せてないかつ分かっていないので、本記事では取り扱いません。
- 3*3 512dの畳み込み層×8→逆畳み込み→bilenearアップサンプリング×2 で56*56の出力を得る。損失は交差エントロピー誤差で評価。のようですが、試していないので詳細不明です。。。
引用元: [Mask R-CNN]
- Mask R-CNNの応用編的な技術であり、私が試せてないかつ分かっていないので、本記事では取り扱いません。
- 3*3 512dの畳み込み層×8→逆畳み込み→bilenearアップサンプリング×2 で56*56の出力を得る。損失は交差エントロピー誤差で評価。のようですが、試していないので詳細不明です。。。
ネットワーク構造
Mask R-CNNは、その前身となる Faster R-CNN という手法をベースにしています。
Faster R-CNNは、物体検出とセグメンテーションの機能を有していて、Mask R−CNNはそれにセグメンテーションの機能を付加する形で進化した手法といえます。
それぞれのネットワーク構造は以下の通りです。
赤枠で囲んだ「mask branch」が追加部分です。
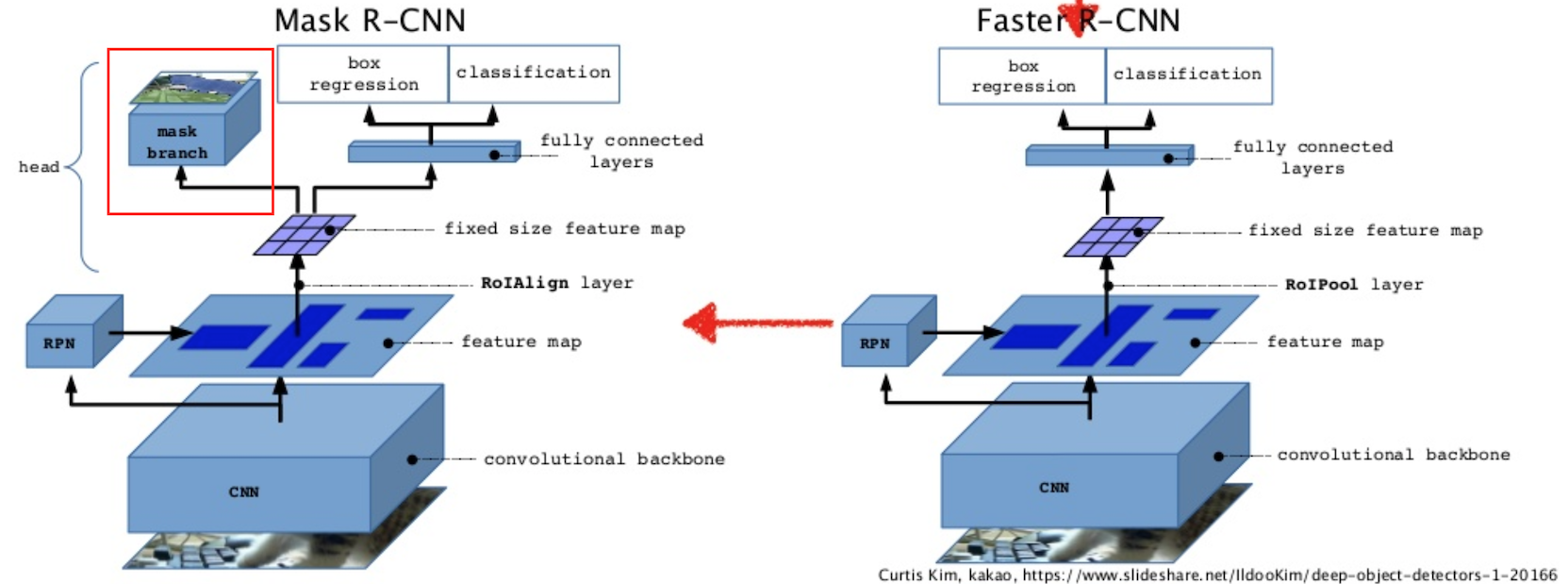
引用元: https://www.slideshare.net/windmdk/mask-rcnn
セグメンテーション以外の点でも進化(改善が加えられている)のですが、それについては後述する詳細に記載します。
以降では、まずはベースとなるFaster R-CNNについて記載し、その後にMask R-CNNでの改良点を記載する形でまとめます。
Faster R-CNN について
Faster R-CNNは大きく「Backbone」「RPN」「HEAD」の3つの層に分けられます。
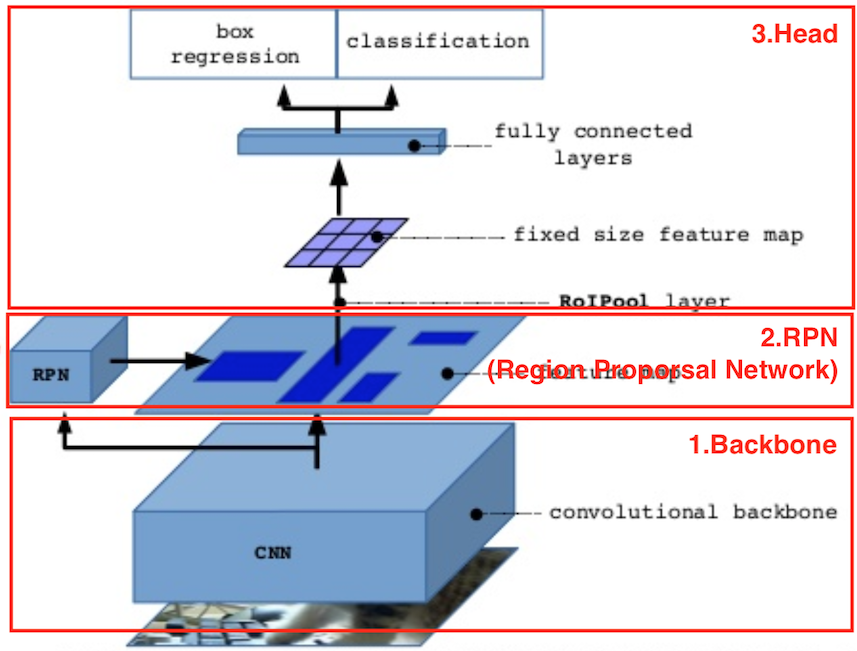
引用元: https://www.slideshare.net/windmdk/mask-rcnn
1. Backboneネットワーク
正に「Backbone」になるネットワークであり、入力画像の特徴を抽出する役割を担います。
複数の畳み込み層から構成されるネットワークを利用しますが、Mask/Faster R−CNN専用のネットワークというわけではなく、既存の優秀なネットワークアーキテクチャを ほぼそのまま 利用します。
これは、Mask/Faster R-CNNに限らずで、車輪の再発明は行わず優秀なありモノを活用しましょうというスタンスのようです。
既存のネットワークとして、論文中では「VGG」と「ResNet」を採用していて、「ResNet」の方が精度が良いようです。
幾つかのネットワークアーキテクチャの紹介と比較はこちら。
参考: CNNモデル比較論文 "An Analysis of Deep Neural Network Models for Practical Applications"を読んだ - 人間だったら考えて
ちなみに、ネットワークから得られる画像の「特徴」は、線/角/点といった低レベルな情報から、表面形状や部分といった高レベルな情報まで、ネットワークの構成により変わります。
一般的に、ネットワークの浅い層では、線/角/点といった低レベルな情報(単純な形状)が抽出され、層が深くなるに伝わりより具体的な情報(複雑な形状)が抽出されるようです。
と、言葉では全くうまく説明できませんので、こちらをどうぞ。
ネットワークの各層の出力が可視化されたものです。

引用:http://vision03.csail.mit.edu/cnn_art/index.html
1層目(Conv1)では線/角/点といった情報が抽出されている(といった情報に反応するフィルタ)ですが、3層、5層と層が深まるに連れて、より具体的な抽出結果が得られています。
8層目である出力層では、各クラスに対応する出力がそれっぽい絵になっていますね。
深い層ほど高度な情報が得られる、言い換えると深い層ほど入力画像の意味を理解している、ということになると思います。
話が逸れました。既存アーキテクチャの流用の話に戻ります。
Mask/Faster R-CNNでは、流用するネットワークのHeadに当たる層を除いた層のみを利用します。
上の図であれば、後半の [ 4096 → 4096 → 100 ] の層を除きます。
これは、Mask/Faster R-CNNでは、入力画像の特徴が欲しいのであって、後半の [ 4096 → 4096 → 100 ] で得られるクラス識別の情報は不要であるためです。
Mask/Faster R-CNNでは、新たなHeadを設け、入力画像の特徴を元にクラス識別に加えて物体領域の検出+セグメンテーションを行います。
また、私の実装では、ネットワークアーキテクチャだけでなく、学習結果(重み)も流用しています。
(Kerasが提供するVGG16の重みを利用しました。)
このように、既存のネットワークアーキテクチャ+重みを流用し、Headだけを差し替える手法は転移学習やファインチューニングと呼ばれます。
転移学習は流用部分の重みを変更しない、ファインチューニングは重みを変更する、という点で異なる手法とされています。
参考: Keras / Tensorflowで転移学習を行う - Qiita
Kerasであれば以下のようなコードでHead(top)部無しの学習済みのモデルが得られます。
model = VGG16(weights='imagenet', include_top=False)
2. RPN(Region Proporsal Network)
冒頭の概要に書いた「物体らしき領域」の候補となる領域を選定する役割を担います。
わざわざ『「物体らしき領域」の候補』を探すという回りくどい手順を踏む理由は以下2点。
- Backboneの出力に対して、しらみつぶしにHead部処理(「物体らしき領域」と「クラス識別」)を行うのは非常に非効率。
- 従来の手法でも候補選定しているが、その手法は学習しない手法であり外れ率が高い。結果的に、大量の候補に対してHead部の処理を行う必要ありで非効率。
従来の手法とは、Faster R-CNNの更に前身の手法である「R-CNN」、「Fast R-CNN」のことです。
前身に次ぐ前身で分かりづらいですが、R-CNN系の歴史はこちらにまとまっています!
参考: 物体検出についての歴史まとめ - Qiita
従来の手法では1点目の課題に対応するため、「Selective Search」という手法が用いられていますが、2点目の課題に加えて遅いという問題がありました。
参考: R-CNNとしてSelective search を使ってみた - Qiita
というわけで、Faster R-CNNではこの点も学習可能にする(更にBackboneの出力をHeadと共有する)ことで効率化&精度向上しようという目論見でRPNが導入されました。
このRPNがFaster R-CNNの革新的な点です。
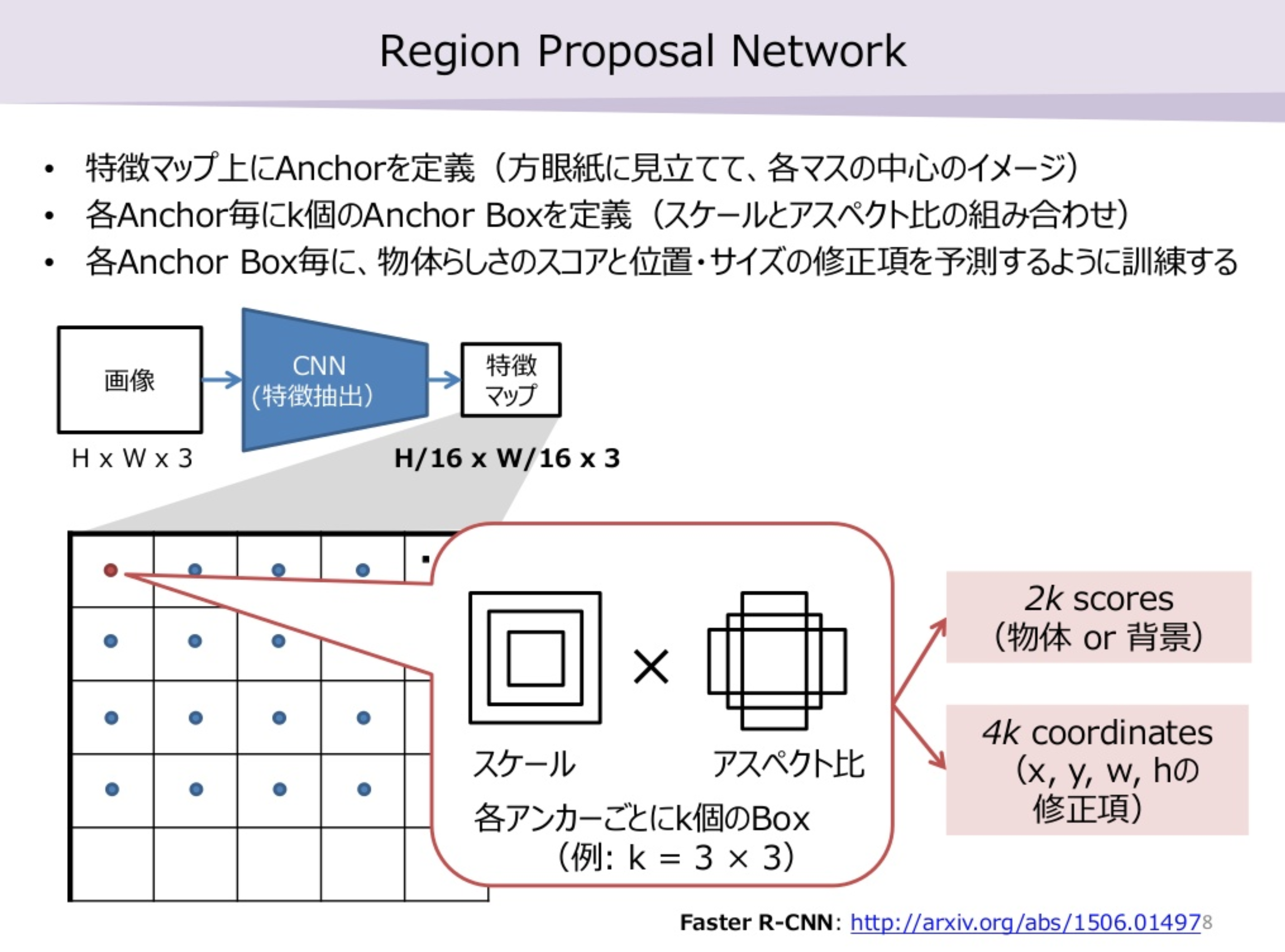
2.1. RPNのネットワークの構造
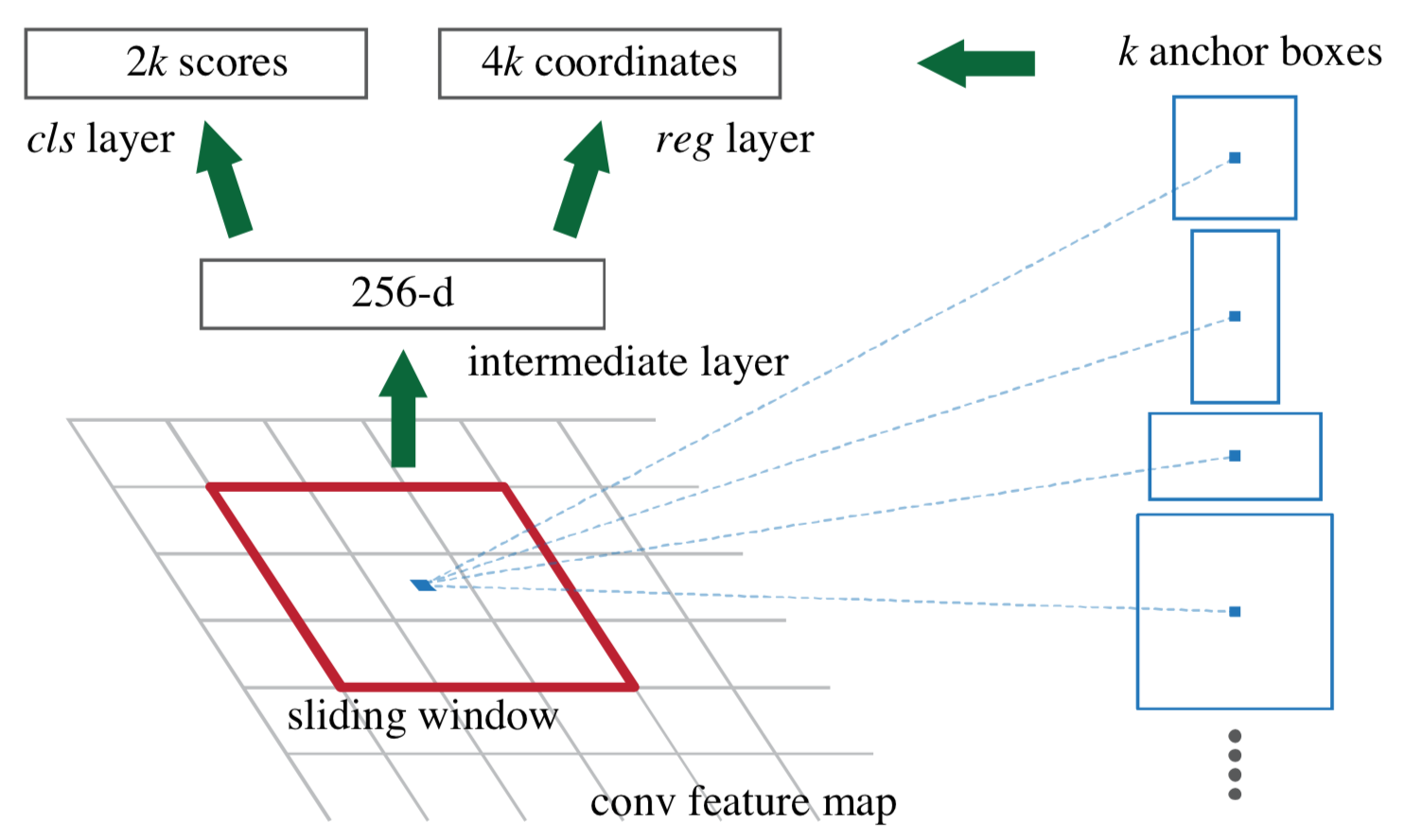
引用元: Faster R-CNN
Backboneの出力をRPNの入力として、cls layerから「物体と見なすか否か」を、reg layerから「オフセット」を得る、という構造です。
図中の k はBackboneの出力におけるピクセルごとのアンカー数です。
唐突に「オフセット」「アンカー」といった単語が出てしまいましたが、2.2.にて説明しますので、今は
何かしら基準となる「アンカー」というものがあり、出力としては「物体と見なすか否か」と「オフセット」が得られる。
とだけ理解しておいてください。
各レイヤの構造
これはメモ程度に。
- intermediate layer:
ストライド幅3、256 dの畳み込み。 - cls layer:
ストライド幅1、2k dの畳み込み。
活性化関数にSoftmaxを用いてアンカー毎に物体/非物体を指す確率に変換。 - reg layer:
ストライド幅1、4k dの畳み込み。
活性化関数は無し(線形回帰)。
2.2. RPNの学習のステップ
RPNの学習は大まかに以下のステップで進められます。
- Backboneの出力がRPNに対して、「アンカー」と呼ばれる『「物体らしき領域」の候補』を選定するための基となる領域を定義。
- 1.のアンカーそれぞれに対して、正解とするデータを定義。
- 1.のアンカーそれぞれに対して「物体と見なすか否か」と「オフセット(正解とする領域からどれだけズレているか)」を得る。
- 2.で得られた情報と正解とするデータを基に損失を得る。
各ステップの概要は以下の通りです。
1. アンカーの定義
Backboneの出力の1ピクセル毎に9つのアンカーを定義します。
9つ=3種類のスケール×3種類のアスペクト比 のことで、論文では以下の組合せを用いています。
スケール:128ピクセル, 256ピクセル, 512ピクセル
アスペクト比:1:2, 1:1, 2:1
ここで注意点が2つあります。
- 1点目
上記スケールは入力画像に対してのピクセル数です。
なので、Backboneの出力に対して適用する場合は、1/16します。
なぜ、1/16なのかと言うと、Backboneでストライド幅2のPoolingを4回行っており、Backboneの出力1ピクセルが入力画像16ピクセル分に相当するためです。(2^4=16)
ちなみに、Poolingとは特徴を残しつつ縮小する手法で、ストライド幅2だと以下のように縦横1/2になります。

- 2点目
アンカーは各スケールで面積が同じであるべきです。
私は以下のように実装しました。参考まで。
anchor_box_aspect_ratios = [
(1. / math.sqrt(2), 2. / math.sqrt(2)), # 1:2
(1., 1.), # 1:1
(2. / math.sqrt(2), 1. / math.sqrt(2)) # 2:1
]
2.正解とするデータの定義
各アンカーと訓練データの領域から、各アンカー毎に「物体と見なすか否かのフラグ」と「オフセット(基となる領域からどれだけズレているか)」を求めます。
アンカーと訓練データの領域との重なり具合を基に、物体/非物体/評価対象外の何れかに分類し、「物体」に分類したアンカーについては、対応するアンカーからのオフセットを求めます。
重なり具合について「IoU(Intersection Over Union)」(重複する面積の割合)で評価し、IoUが閾値A以上であれば物体、IoUが閾値B以下であれば非物体、それ以外のアンカーは評価対象外とします。
さらに、訓練データのある1領域に対して複数の重複するアンカーがある場合は、「NMS(Non Maximum Suppression)」という手法でいづれか1つに絞り込みます。
NMSは、
対象とする1領域に対して複数の重複する領域候補がある場合、IoUが閾値C以上の候補からIoUが最大となる候補だけ残しその他は除外する
という手法です。
IoU、NMSについては以下を参考にしてください。
参考: 物体検出におけるNon-Maximum Suppressionのアルゴリズム | meideru blog
さらに、上記だけでは訓練データにより、物体/非物体と見なす領域が膨大になる、また、非物体の割合が多くなる可能性があることから、正解とするデータの上限をDと定め、物体:非物体の割合をE:Fとしています。
不要そうな情報をバサッと切り捨てることで精度を保ちつつ速度を上げるということですね。このような、情報の選別、パラメータ選定など、数学的背景と経験を持ち合わせていないと難しい領域なんだろうなと感じました。。
上記でA〜Fで示したパラメータは論文中では以下になっています。
A:0.7
B:0.3
C:0.3
D:64
E:1
F:3
※D,E,Fについては論文中に記載が無いが、精度、学習速度の安定性の面から必要と思われる。参考とした実装からそのように理解した。
オフセットについては、正解とする領域からの差異そのままではなく、以下のように正規化した形にします。
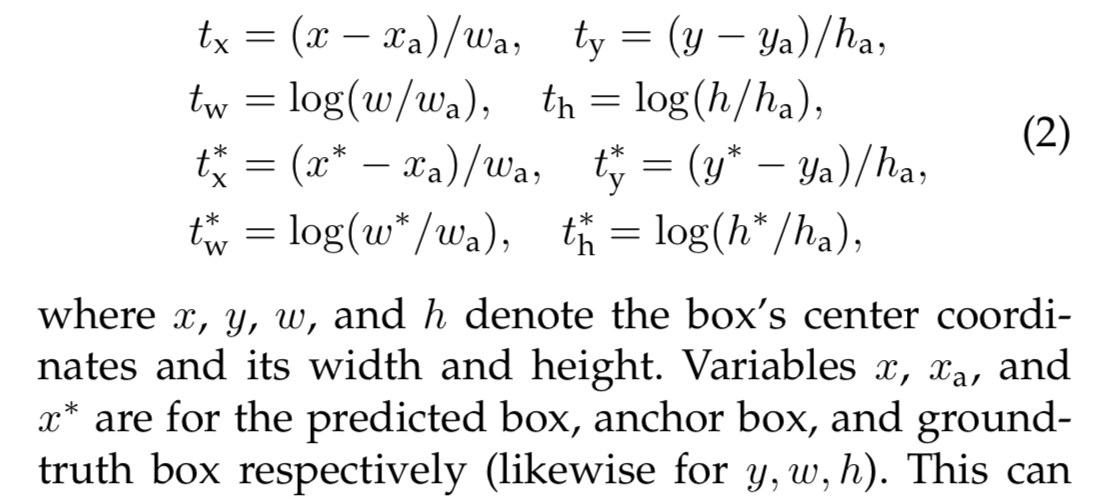
引用元: Faster R-CNN
入力データの正規化(スケールを揃える)の効果は以下の通りで、機械学習全般で重要な要素です。
θ同士の範囲に差があると、目的関数J(θ)が非対称的な形になり、最急降下法で最小値にたどり着くまでに時間がかかります。スケーリングによって、目的関数J(θ)が対称的な形となり、最急降下法で最小値までたどり着く時間が短くなります。
引用元: スケーリング (feature scaling) - Coursera Machine Learning (2): 重回帰分析、スケーリング、正規方程式 - Qiita
3.アンカー毎の予測結果
「2.1. RPNのネットワークの構造」の図に示すcls layerから「物体と見なすか否か」が、reg layerから「オフセット」が得られます。
アンカーに対してオフセットを適用することで、領域の候補が得られますが、その候補群はそれぞれ重複している可能性があります。
ですので、「2.正解とするデータの定義」で行った手法と同様に、IoUを用いて重複度を判定し、候補を絞り込みます。
具体的な処理は以下の通りです。
- まず、cls layerから得られる「物体と見なすか否か」を示す値(物体である確率)が高い領域上位A件を残します。
- 次に、残った領域から重複を排除するため、NMSによりIoUがB以上の領域を重複として除外し、最終的にC件以下にします。
上記でA〜Fで示したパラメータは論文中では以下になっています。
A: 12000
B: 0.7
C: 2000
4.損失を得る(学習する)
上記の2.、3.で得られたデータから損失を求めます。
cls layer、reg layerそれぞれの損失を求め、それらを合算した損失をRPNの損失とします
なお、損失は3.で「物体である」とみなされた領域についてのみ求めます。
損失関数は以下のとおりです。
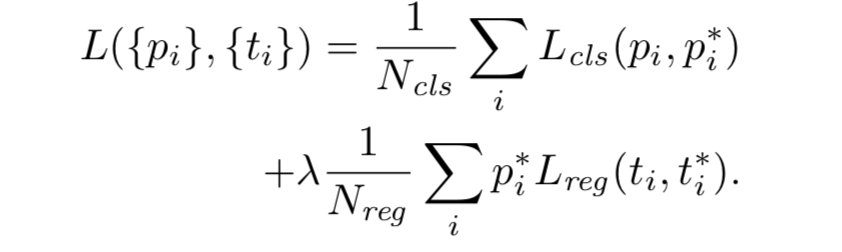
Lcls:cls layerの損失関数
Lcls = p* × log(p)
p*:「物体と見なすか否か」の正解
p:「物体と見なすか否か」の予測値
Lreg:reg layerの損失関数
論文中では Lreg = SmoothL1 と記載されている。
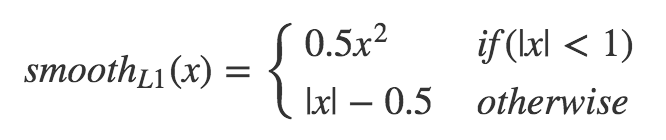
t*:「オフセット」の正解
t:「オフセット」の予測値
引用元:学習方法 - Deepに理解する深層学習による物体検出 by Keras - Qiita
RPNについての補足
ここまでの説明の大半がざっくりと1枚にまとまっている素晴らしい資料がありました。
素晴らしすぎて涙が出ます。
引用元: Object Detection & Instance Segmentationの論文紹介 | OHS勉強会#3 - SlideShare
RPNについての説明動画もありました。
やはり、動きがあると分かりやすい。
3. How RPN (Region Proposal Networks) Works - YouTube
3. Headネットワーク(出力層)
Backboneの出力からRPNで得られた領域候補を切り出し、それぞれについてクラス識別と領域抽出(物体検出)を行う役目を担います。
構造や損失関数は、前身となるFast R-CNNと同じです。
3.1. Headのネットワークの構造
- RoI Pooling layer:
RPNで得られた領域候補毎に7*7でPoolingする。
異なるサイズの領域候補を固定サイズにすることが目的。
参考: 最新の物体検出手法Mask R-CNNのRoI AlignとFast(er) R-CNNのRoI Poolingの違いを正しく理解する - Qiita - 中間層:
RoI Pooling layerで得られた結果をユニット数1024で全結合。これを2層。 - クラス識別層:
ユニット数=クラス数で全結合。
活性化関数にSoftmaxを用いてRPNの領域候補毎×クラス毎の確率を得る。 - 領域抽出層:
ユニット数=クラス数×4で全結合。
RPNの領域候補に対するオフセットを得る。
3.2.Headの学習について
損失関数はRPNと同じ。
クラス識別はlog loss。
領域抽出はSmoothL1。
補足
Faster R-CNNのように1つネットワークから複数の出力を得る学習方法をマルチタスク学習と呼びます。
また、複数の出力の損失を合算するなりして統合した損失をマルチタスク損失と呼びます。
MaskRCNN
ようやく本題のMaskRCNN。。。
Faster R-CNNとの差異のみまとめます。
1. Backbone
論文ではResNet、ResNet-FPNを用いる構成になっています。
が、私の実装ではVGGのまま。
2. RPN
Faster R-CNNと同じ。
3. Headネットワーク(出力層)
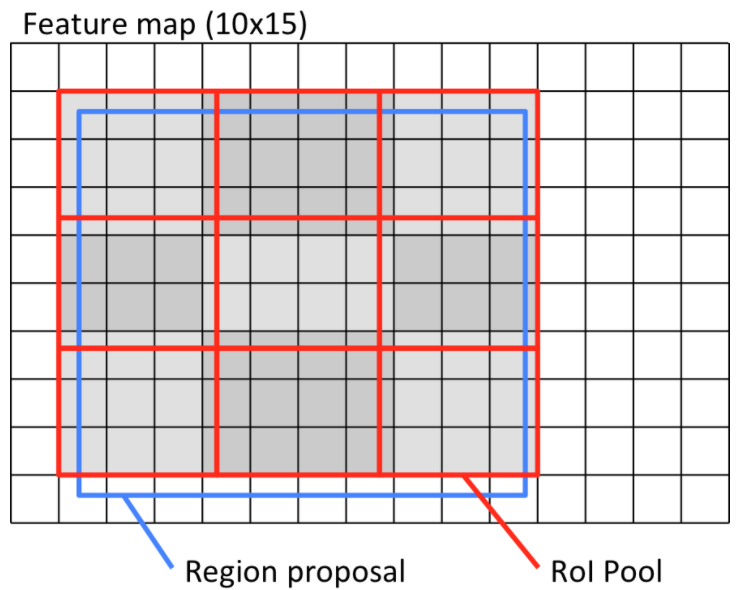
RoIAlign layer:
RoIPoolingに変わるレイヤであり、RoIPoolingで問題だったサブピクセルレベルのズレを解消する手法です。
以下はRoIPooingです。
赤いPoIPoolの領域を決定した時点で領域提案より0.5ピクセルズレます。
入力画像のスケールに戻すと0.5*16=8ピクセルのズレとなり、セグメンテーションにおいては結構なズレ。
以下はRoIAlignです。
領域提案をそのまま利用し、各セル内の4点の近傍4ピクセルから双線形補間(bilinear interpolation)を用いて各点の値を算し、それら4点をプーリングで縮約します。
双線型補完については以下を参考にしてください。
参考: https://algorithm.joho.info/image-processing/bi-linear-interpolation/
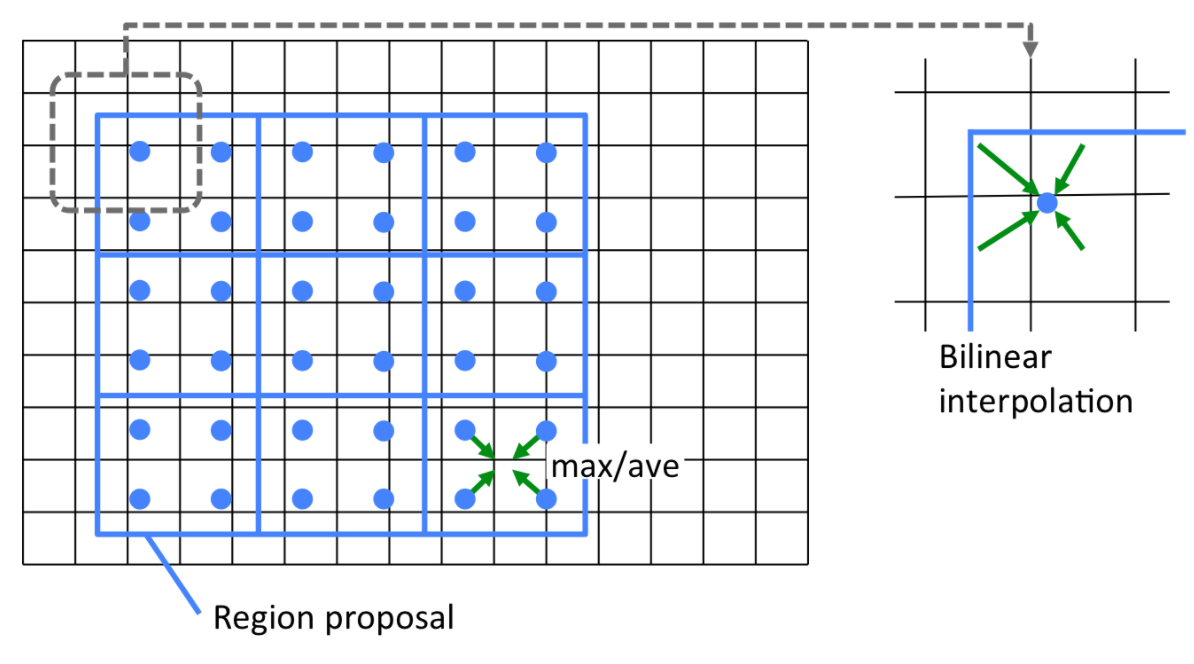
なお、私の実装では tf.image.crop_and_resize で代用してしまったので、bilinear interpolationのアルゴリズムなど詳細は理解していません。。。
引用元: 最新の物体検出手法Mask R-CNNのRoI AlignとFast(er) R-CNNのRoI Poolingの違いを正しく理解する - Qiita
セグメンテーション(マスク) layer:
領域提案中の物体であるピクセルを得るための層です。
構造は以下の通りです。
- 畳み込み層×3:
フィルタ数:256
ストライド幅:3
入力と出力のサイズが同じになるようpaddingを調整。 - 逆畳込み層×1:
フィルタ数:256
ストライド幅:2
ここで出力サイズを2倍に拡張する。 - 活性化:
sigmoidで0〜1に変換。
出力値はビットマスクとして扱います。
値が0.5以上のピクセルを物体とみなします。
補足
クラス識別、領域抽出のレイヤについてはFaster R-CNNと同じ構造。
ネットワーク構造全体像
Mask R-CNNのネットワーク構造です。
といっても、私の実装を Kerasの keras.utils.plot_model で出力したもので、reshape等々細かい処理(KerasのLayer)が全部出力されています。目が痛い。
参考まで。
学習方法
論文では3つの学習方法が記載されており、4stageに分けて学習する方法が最も推奨されるようです。
以下にその学習方法をまとめます。
- stage1
BackboneとRPNの学習を行う。 - stage2
BackboneとHeadの学習を行う。
RPNの重みは固定する。 - stage3
RPNのみ学習を行う。
Backboneの重みは固定する。 - stage4
RPN、Headの学習を行う。
Backboneの重みは固定する。
論文にはstage4では無視できる程度の改善しか得られたなかったと記載あり。
なお、私の実装では上記とも異なる2ステージの学習しか行っていません。
stage1: RPN学習、Backbone固定。
stage2: Head学習、RPN+Backbone固定。
理由は、クラウド利用コスト高。。
学習データ
COCO Dataset を利用しました。
http://cocodataset.org/#home
データ増強(Data Augumentation)は、画像の左右反転をランダムに行うのみとしました。
が、訓練データ画像を一巡する毎に反転有無を切り替える形にしたほうが良かったかもしれません。
ランダムだと毎回反転/非反転になり得る画像もありそうですし。
実装と結果
こちらにまとめています。
https://github.com/shtamura/maskrcnn
まあ、結果は芳しくありません。
学習方法、Backboneネットワーク等、論文との差異は多々ありますが、一番の差異は学習に掛けられる時間、予算がしょぼいことかと思います。。
それでも、物体検出は見落としはあるものの割と正確ですし、セグメンテーションも外れてはいないというレベルで実現出来ていると思います。
以下、出力結果の一例(マシな方)です。


不明点
先人の知恵を頼りまくって実装、検証まで漕ぎ着ける事ができましたが、1点全く分からない点があります。
それは、RPN、Headから得られるオフセット値、また、学習データのそれを以下の値で割っている点です。
[0.1, 0.1, 0.2, 0.2]
実装上はこのあたりです。
https://github.com/shtamura/maskrcnn/blob/master/xrcnn/frcnn.py#L484
確かに、この値で割ることで学習結果が改善したのですが、改善した理由が分からず。
フィーチャースケーリングの一貫だとすると、何とスケールを合わせているのか。。。
お分かりの方がいましたら、教えて頂けると助かります。
他の物体検出手法
Faster/Mask R-CNNは、良い領域候補を予測することが鍵となる手法でしたが、それとは異なるアプローチを取る手法もあります。
YOLO、SSDといった手法です。入力画像を固定の領域に分割し直接領域を予測しようという、精度よりも速度優先のアプローチのようです。
YOLO (You only look once) - Deepに理解する深層学習による物体検出 by Keras - Qiita
最後に
だいぶ長くなってしまい、かつ、後半息切れ気味で駆け足になってしまいましたが、個人的に理解に時間がかかった点は書けたつもりです。
ここまで駄文にお付き合い頂けた方がいらっしゃいましたら大変ありがたいことです。
参考資料、引用元
書籍
- Python 機械学習プログラミング
- ゼロから作るDeep Learning
- MLP 画像認識
論文
論文以外
- Coursera - Machine Learning
http://coursera.org/learn/machine-learning/ - 各CNNのパフォーマンス比較
http://szdr.hatenablog.com/entry/2017/03/01/000614 - 隠れ層の出力可視化
http://vision03.csail.mit.edu/cnn_art/index.html - Pooling図解
https://pythonmachinelearning.pro/introduction-to-convolutional-neural-networks-for-vision-tasks/ - IoU、NMSについて
https://meideru.com/archives/3538 - フィーチャスケーリングについて
https://qiita.com/katsu1110/items/6a6d5c5a6b8af8fbf813#%E3%82%B9%E3%82%B1%E3%83%BC%E3%83%AA%E3%83%B3%E3%82%B0-feature-scaling - 損失関数について
https://qiita.com/GushiSnow/items/8c946208de0d6a4e31e7#%E5%AD%A6%E7%BF%92%E6%96%B9%E6%B3%95 - RPNについて
https://www.slideshare.net/ToshinoriHanya/ohs3 - RPN解説動画
https://www.youtube.com/watch?v=X3IlbjQs190 - RoIPoolingとRoIAlignの違い
https://qiita.com/yu4u/items/5cbe9db166a5d72f9eb8 - ファインチューニングと転移学習の違い
https://qiita.com/yampy/items/6f1f48fee16db7888f07