この記事は リクルートライフスタイル Advent Calendar 2017 4日目の記事です。

はじめに
こんにちは!データエンジニアリンググループでエンジニアをやっている @shotat です。
最近は CETというプロジェクトでDataflowを書いたりGoを書いたり無限にSQLを書いたりしています。
先月サンフランシスコで行われた QCon2017 に参加してきました。
QConではArchitecture, DevOps, Microservices, AI, CS, Culture, Web…と幅広いトラックがあり、全体としてサービス・組織をどのようにスケーリングさせていくか?という点に関心が集まっていたように感じました。
トラックの一つとしてChaos Engineeringがあり、中でもChaos Architecture のセッションはカンファレンスで一番Attendeeの数が多く、Chaosに対する熱量の高さを感じました。自分もChaosの名に惹かれ参加してきました。
カンファレンス最終日の懇親会ではChaos Engineeringのオライリー書籍が配布され、著者兼Speakerのサインも無事に貰ってきました。なお、書籍の内容は Chaos Engineering - O'Reilly Media と同一なので、free ebook として読むことができます。
本記事では前半でChaos Engineeringの概要を軽くまとめ、後半ではChaos MonkeyのようにDockerコンテナを破壊するChaos Toolsである Pumba を触ってみます。
Chaos Engineering
Chaos Engineeringの定義
Chaos Engineeringの定義について Principles of Chaos Engineering から引用します。
Chaos Engineering is the discipline of experimenting on a distributed system in order to build confidence in the system’s capability to withstand turbulent conditions in production.
意訳すると、カオスエンジニアリングとは「分散システムが本番環境の過酷な状況に耐えうる能力に確信を得るための実験の規律」のような感じです。ちょっと分かりづらいですね。
Chaos Engineeringの概要
分散システムは多くの独立したサービス/コンポーネントから成り立っており、それらは相互に呼び出しを行っています。「分散システム」というとやや抽象的なので「マイクロサービス」だと捉えるとイメージしやすいですが、マイクロサービスでなくても分散システムであれば何でも当てはまります。
分散システムではコンポーネントが多い分、全体として個々のネットワーク障害やディスクの故障と言った現象が起こる頻度が高まります。分散システムで複数サービスが相互に呼び出し、あるいは協調する中、一つのコンポーネントがクラッシュしただけでシステム全体がクラッシュするようなことがあっては大変です。
そのため、マイクロサービスを設計する際にはサービス間で適切にCircuit breakerやAPIのrate limitを設定する必要があります(このあたりのポリシーの設定はIstioを使うと良いようです。QConではIstioのセッションもあり、そこで紹介されていました)。
しかし、大規模な分散システムは複雑系であり、fallbackやtimeoutの設定によっては予期しない振る舞いが発生する場合があります。予期しない振る舞いの具体例としては、「あるサービス間でCircuit breakerが発動することでシステム全体の負荷が下がり、連鎖的にシステム全体に負の縮退ループが走り続けて最終的にシステムダウンする」というような状況です。これはいわゆるブルウィップ効果と呼ばれるもので、小さな個の影響が増大して全体に駆け巡る可能性を示唆しています。
つまり、個別では正しいように見えるfallbackやtimeoutの設定が、システム全体として悪影響を及ぼすケースがあり、そしてそれを予測するのは非常に困難だと言われています。
こういった分散システムの複雑性に対処する方法論がChaos Engineeringです。
システムに対して様々な実験を行って弱点を発見し、回復力(resilience)を強化したり、経験的にシステムの振る舞いに対しての知見を深めていく行いをChaos Engineeringと呼びます。
いわゆるテスト(Testing)ではなく**実験(Experimentation)**である点が重要です。テストが単なるAssertionであるのに対し、Chaos Engineeringにおける実験は「システムに対する新たな知見を引き出す」という点が根本的に異なります。
Chaos Engineering実践のメリットとして、可用性や耐障害性を保証するだけでなく「機能開発のベロシティの向上」にも繋がる点が挙げられます。つまり、全貌の掴み難い大規模な分散システム/マイクロサービスにおいて確信をもってサービスをデプロイできるようになるのです。
Chaos とは?

そもそもChaosとは何でしょうか?カオスは日本語では「混乱・混沌」のように訳されますが、Chaos Engineeringのニュアンス的には「複雑系・カオス理論・カオス力学」分野で意味されるカオスの方が正しいです。
つまり、一定の入力に対してカオスな振る舞いをする分散システムを取り扱う理論です。
**「カオス的挙動を持つ複雑な分散システムに対し、コントロールされた外乱を引き起こす」という意味であり、「カオスな外乱をシステムに加える」**という意味ではないことに注意して下さい。
「カオスを注入する」という表現も見かけますが、あくまで注入する事象自体はコントロールされています。
Antifragile/Robust/Resilient
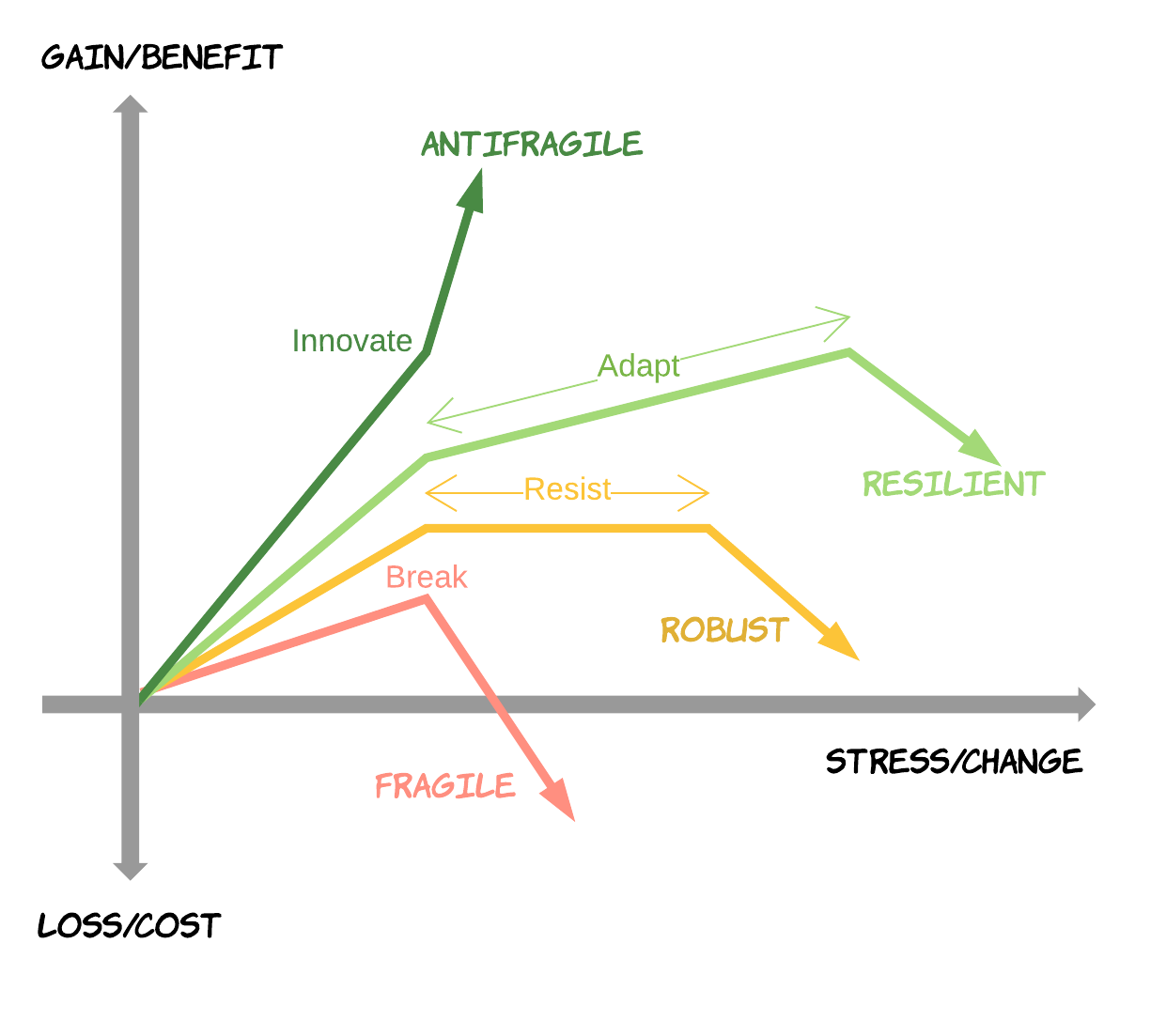
図: From Fragile to Antifragile Software - RHD Blog より
Chaos EngineeringではAntifragile(反脆い)という概念が理解の助けとなります。
Antifragileというのは「系にストレスが加わった際に、それを糧にしてより強くなる」性質です。ドラゴンボールで例えるとサイヤ人です。衝撃や不確実性に耐えるだけでなく、それらを味方につけるという点がRobust(頑健)やResilient(復元力のある)とは異なります。
Chaos Engineeringはシステムにストレスを加え続けることでシステム自体を成長させるという点でAntifragileな営みと言えます。
Fragile/Robust/Resilient/Antifragileについては以下の記事に詳しく書いてあるので説明はそちらに譲ります。
なお、Antifragileの書籍は今年邦訳本が出ました。分割2巻でやや長いですが非常に面白いのでオススメです。
Chaos Engineeringの原則
分散システムの振る舞いは複雑系のため、単純な予測モデルを使った予測を行うことができません。
そのため、Chaos Engineeringでは予測モデルを構築するのではなく「実験的・経験的」アプローチを利用して、システムの振る舞いを理解することが原則です。
システムに注入した外乱に対してシステムがどのように反応して振る舞うのかを観察し、システムへの理解を深めていきます。外乱はランダムではなく体系的に与え、システムの振る舞い知見を最大限引き出せるような実験を行います。
また、以下のような発展的な原則が5つあります。
上の4つについては以下のページに記述があるので説明を割愛します。
NetflixのChaos Engineeringの原則
- Hypothesize about steady state: 定常状態の振る舞いについて仮説を立てる
- Vary real-world events: 実世界の事象に変化をつける
- Run experiments in production: プロダクション環境で実験を実行する
- Automate experiments to run continuously: 実験を自動化して継続的に実行する
- Minimize blast radius: 爆発半径を最小化する
- 本番環境でChaos実験を行うと想定外にユーザに悪影響を及ぼす可能性があるため、緊急停止の仕組みを作り影響範囲を最小化するようにする。また、実験は深夜に行うのではなく、すぐに対応できるようにオフィスに人がいる日中に行うようにする。

以上がChaos Engineeringについての概要で、続けてPumbaについて紹介します。
Pumba
Chaos Engineeringの本でも紹介されている Pumba を使ってみます。
Pumbaは Chaos Monkey のような挙動をDockerのコンテナレベルで行うツールです。
Chaos MonkeyがAWSのインスタンスをランダムに停止するのに対し、PumbaはDockerのコンテナをランダムにkillすることができます。他にもネットワークのエミュレート機能があり、NW遅延やパケロスを引き起こすこともできます。
PumbaをKubernetes(k8s)上で実験してみます。今回は簡単のため複数サービスではなく単一のサービスのみ扱います。
k8sのクラスタは今回 minikube を使ってローカルに立てます。kubectl, minikube周りの環境構築については以下を参照して下さい。
- https://kubernetes.io/docs/tasks/tools/install-kubectl/
- https://kubernetes.io/docs/tasks/tools/install-minikube/
minikube + Pumbaで適当に試してみます。
minikubeで適当なpodを起動するのは以下のコピペです。
https://kubernetes.io/docs/getting-started-guides/minikube/
$ minikube start
$ kubectl run hello-minikube --image=gcr.io/google_containers/echoserver:1.4 --port=8080
$ kubectl expose deployment hello-minikube --type=NodePort
$ curl $(minikube service hello-minikube --url)
それっぽいレスポンスが来ればOKです。
続いてPumbaのDaemonSetを作ります。ここでは各Nodeで1つずつPumbaを飼うためにDaemonSetを利用していますが、minikubeだとあまり関係ありません。
以下のYAMLを作成し、pumba_kube.yml とします。
apiVersion: extensions/v1beta1
kind: DaemonSet
metadata:
name: pumba
spec:
template:
metadata:
labels:
app: pumba
name: pumba
spec:
containers:
- image: gaiaadm/pumba:master
imagePullPolicy: Always
name: pumba
args:
- pumba
- --random
- --interval
- "30s"
- kill
- --signal
- "SIGKILL"
- "re2:hello-minikube"
volumeMounts:
- name: dockersocket
mountPath: /var/run/docker.sock
volumes:
- hostPath:
path: /var/run/docker.sock
name: dockersocket
--interval 30s で30秒置きにランダムにk8s内のコンテナを壊すことになります。Podではなくコンテナレベルです。
また、今回は "re2:hello-minikube" の指定をすることで正規表現でhello-minikubeにマッチするコンテナだけを選択的に破壊します。何も指定しないと kube-system 系のコンテナまで破壊されてしまい、k8sの挙動が追いづらくなるためそれを防いでいます。が、kube-system系のコンテナが破壊されてもk8s側で自動で復旧してくれるので実際はそのまま動き続けます。
以下のコマンドを実行すると、DaemonSetを作成できます。
$ kubectl create -f pumba_kube.yml
podの生成完了を待ちつつ、以下のコマンドでk8s内のリソースを確認します。
$ kubectl get all
NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE
deploy/hello-minikube 1 1 1 0 4m
NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE
ds/pumba 1 1 1 1 1 <none> 1m
NAME DESIRED CURRENT READY AGE
rs/hello-minikube-57889c865c 1 1 0 4m
NAME READY STATUS RESTARTS AGE
po/hello-minikube-57889c865c-cq6jq 0/1 Error 2 4m
po/pumba-8bjxx 1/1 Running 0 1m
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
svc/hello-minikube NodePort 10.98.30.208 <none> 8080:32090/TCP 3m
svc/kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 7m
hello-minikube のpodがクラッシュしています。Pumbaに定期的にkillされ続けてるのでpodが全く立ち上がらない状況です。この状態で curl $(minikube service hello-minikube --url) を実行しても接続できません。Podに冗長性がないのが問題なので、いくつかのPodがPumbaにkillされてもService全体が落ちないように hello-minikube をスケールアウトしみます。
$ kubectl scale --replicas=5 deployment/hello-minikube
適当なタイミングで再びリソースの状況を確認してみます。Pumbaによってpodが何回かRESTARTしていたり、落ちているPodがあることが分かりますが、サービス全体としては問題なく生きています。
curl $(minikube service hello-minikube --url) でも問題なく接続できることが分かります。
$ kubectl get all
NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE
deploy/hello-minikube 5 5 5 4 8m
NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE
ds/pumba 1 1 1 1 1 <none> 2m
NAME DESIRED CURRENT READY AGE
rs/hello-minikube-57889c865c 5 5 4 8m
NAME READY STATUS RESTARTS AGE
po/hello-minikube-57889c865c-6rmcw 1/1 Running 1 4m
po/hello-minikube-57889c865c-cq6jq 1/1 Running 3 8m
po/hello-minikube-57889c865c-cwdm8 1/1 Running 0 4m
po/hello-minikube-57889c865c-dbspp 1/1 Running 2 4m
po/hello-minikube-57889c865c-lfvx9 0/1 Error 1 4m
po/pumba-w5xg9 1/1 Running 0 47s
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
svc/hello-minikube NodePort 10.98.30.208 <none> 8080:32090/TCP 8m
svc/kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 12m
後始末としてminikubeのクラスタを消します。
$ minikube delete
今回は非常に簡単な例でしたが、もう少し複雑なサービス間連携があるシステムで試してみると面白いと思います。PumbaはDaemonSetとして既存のk8sクラスタに簡単にデプロイできる点がお手軽だと感じました。ネットワークのシミュレート機能も今度触ってみたいと思います。
まとめ

本記事ではChaos EngineeringとPumbaを簡単に紹介してみました。Chaos Engineeringに興味を持たれた方はオライリー本か NetflixのTechBlog を読むと面白いと思います。
オライリー本の巻末にはPumba以外にもいくつかツールが紹介されているので何か試したい方は参照してみて下さい。
なお、本記事の挿絵は全ていらすとやで [クトゥルフと検索] (http://www.irasutoya.com/search?q=%E3%82%AF%E3%83%88%E3%82%A5%E3%83%AB%E3%83%95) して探してきました。