はじめに
前回に引き続き、推薦システムの領域をデータの観点から分類して各領域の特性や適用できる手法について紹介していきます。
前回記事をまだご覧になっていない方は、ぜひそちらから見ていただけると今回記事もスムーズに読めるかと思います。
今回の対象
今回は、「シーケンス情報あり・属性情報なし」、「シーケンス情報あり・属性情報あり」、「セッション情報あり」の3つの領域を見ていきます。
シーケンス情報あり・属性情報なし
入力データ
インタラクションが発生した時間の情報が付与され、時間軸でソートされたデータを用います。
時間情報はそれ自体を特徴量として使う場合もあれば、インタラクションのソートのためだけに用いられる場合もあります。
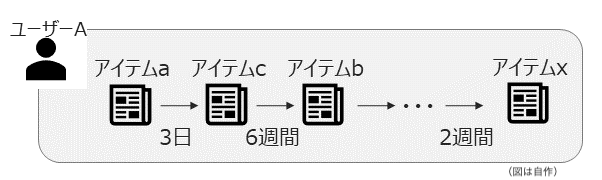
本領域の特徴
- ユーザーの好みが時間とともに変化することを仮定しています
- シーケンス長(ユーザー毎のインタラクション数)は十〜数百程度を想定する場合が多いです
アプローチ
この領域では、アテンション機構をベースにしたモデルとマルコフ性に基づいた手法が多かったので、それらについて紹介します。
アテンションベース
-
自然言語処理領域で用いられるBERTモデルのアーキテクチャを推薦システムに導入した研究(BERT4Rec[1])をはじめとし、セルフアテンション機構やTransformerモデルを活用する試みが多くなされています
-
BERT4Recでは、left-to-rightとright-to-leftの双方向のシーケンス情報を用い、穴埋め形式の問題(前後のインタラクション履歴から穴埋めされたアイテムを予測する問題)を学習します
-
予測時は、right-to-leftの情報は使えないため、left-to-rightのみで最新アイテムを予測する形をとっています
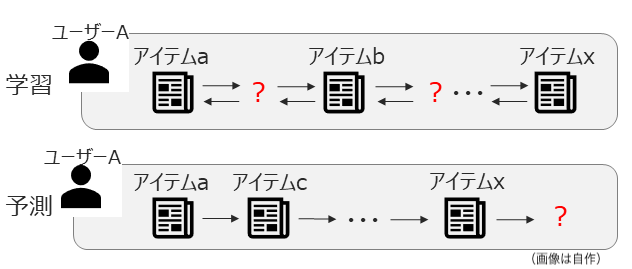
-
2022年のRecSys(推薦システム関連のトップカンファレンス)においても、Transformerベースのモデルに対するノイズへの頑健性を高める研究[2]がベストペーパーに選ばれており、依然として注目度の高い技術・領域となっています
マルコフ性に基づく手法
-
マルコフ性に基づく、すなわち直近$T$個のインタラクションのみが次の推薦に影響を与えると仮定したモデルも研究が進められており、CNNの枠組みで学習するモデル(Caser[3]など)が提案されています
-
Caserは、複数のフィルタを用いることで様々な観点のアイテム間の関係性をモデリングすることが可能となっています
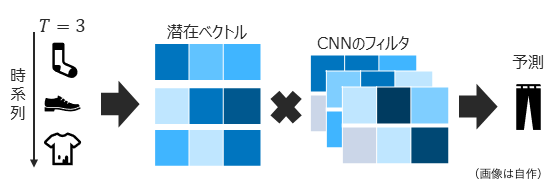
-
ユーザーの好みが非常に激しく変化することが想定されるサービスであれば、直近のデータのみを用いる上記のような手法が有力になると考えられます(古いデータはノイズになってしまうため)
-
ただし、一般的には一貫した嗜好のもとで部分的に好みが変化(飽きなどの影響)する場合が多いと考えられ、研究事例・性能の両面でアテンションベースの手法にやや押されている印象です
アプローチ間の比較
一般的に、下記表のようにデータ量によって得意とする範囲が異なると言われています。
| データ量 | |||
| 少 | 中 | 多 | |
| アテンションベース | × | ○ | ◎ |
| マルコフ性に基づく手法 | ○ | △ | △ |
所感
- 音楽・動画配信サービスなど、ユーザーの嗜好が動的なサービスは多いと考えられ、今後より一層需要が高まると考えられます
- ユーザー数が少ないサービスでは、学習データがスパースになってしまい性能面の課題が残るため、スパース性に関する研究が今後重要になるのではないかと思いました
シーケンス情報あり・属性情報あり
入力データ
シーケンス情報に加えて、ユーザー・アイテム等の属性情報が付与されたデータを用います。
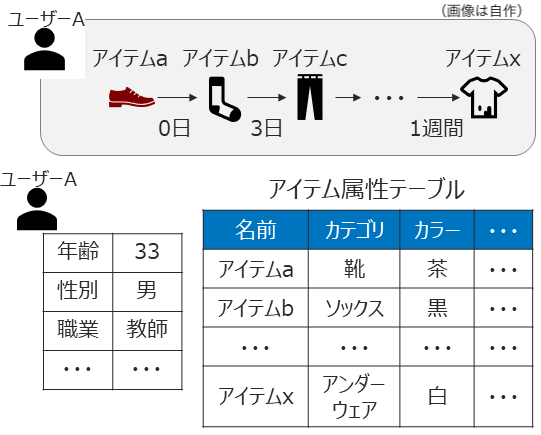
本領域の特徴
- ユーザーの好みが時間とともに変化することを仮定しています
- 以下の3つの情報を効率的に活用することが必要になります
- ユーザーの普遍的選好 → ユーザー単位での大局的な選好の学習
- ユーザーの直近の行動履歴を反映した短期的な興味・関心 → ユーザー単位の短期的な選好の学習
- ユーザー・アイテムの属性情報に基づく傾向 → サービス利用者全体での大局的な傾向の学習
アプローチ
一般に「シーケンス情報あり・属性情報なし」領域の手法を拡張したものが主流となっている印象です。
ここ2〜3年で研究が本格化してきている領域というイメージで、研究事例はまだ少なかったです。
ここでは、属性情報をうまく使って「シーケンス情報あり・属性情報なし」の手法を拡張している研究を2つ紹介します。
S3-Rec (2020)[4]
- 上記で紹介したBERT4Recなど、Transformerを使ったモデルはあくまで周囲のアイテムとの共起の情報のみから潜在ベクトルを学習していました
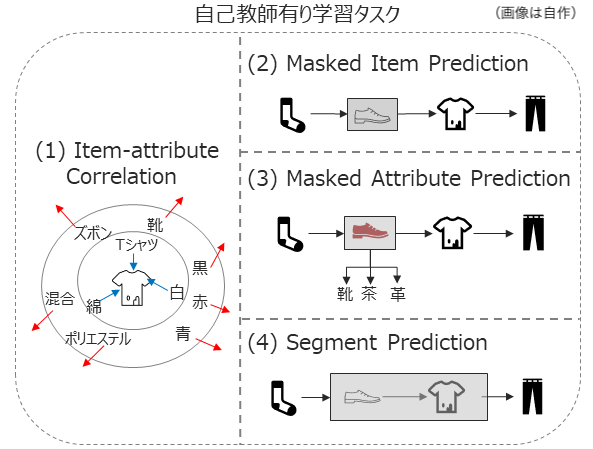
- S3-Recでは、より効果的な潜在ベクトルの学習になるよう、自己教師あり学習を用いてアイテム属性情報を潜在ベクトルに埋め込みます。
- 具体的には、下記図に示すような4つの自己教師ありタスクを設定し、事前学習として学習します
- アイテムを入力すると、該当のアイテムに対応する情報(Tシャツや綿など)とアイテムの潜在ベクトルが近づくように、それ以外の情報は遠ざかるように学習するタスク
- マスクされたアイテムをleft-to-rightで予測するタスク(一般的な「シーケンス情報あり・属性情報なし」の学習方法とほぼ同じ)
- マスクされたアイテムの「属性情報」を当てるタスク
- 複数の連続するアイテムをマスクし、アイテムの流れを学習するタスク
- fine-tuningでは、「シーケンス情報あり・属性情報なし」のアテンションベースモデルと同様に穴埋め形式の学習をleft-to-rightで行います(アイテムの潜在ベクトルは事前学習で得られたものを初期値として設定)
TARN (2022)[5]
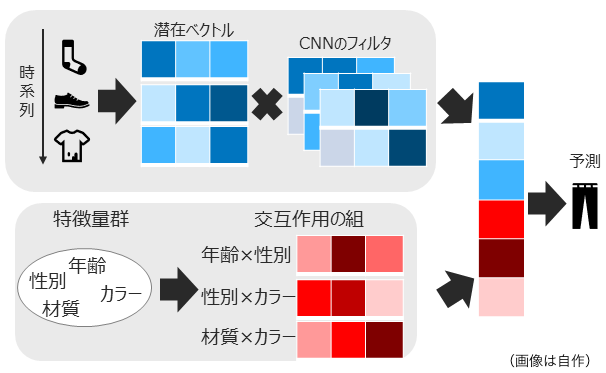
- 好みの動的変化に関する学習機構と属性情報によるモデリングを別々のモデルで学習し、最後に統合して予測を行うモデルです
- 好みの動的変化に関する部分はCNNを採用しており、上記で紹介したCaserに非常に類似しています
- 属性情報のモデリングは内積を用いた属性情報間の2次の交互作用を学習するモデルを提案しており、前回の記事で紹介したFactorization Machinesと非常に類似しています
- これら2つのモデルから得られたベクトルを最後に結合し、次に推薦すべきアイテムを予測するタスクを解いています
所感
- 論文を読んだ感じでは、基本的に拡張前の手法より10%前後性能が改善しているものが多く、今後研究が活発になりそうな領域です
- 性能向上と引き換えにモデルが複雑になり計算資源や実行時間の観点で使いづらくなることも多そうなので、そのあたりに関する研究が今後出てくることを期待したいです
セッション情報あり
入力データ
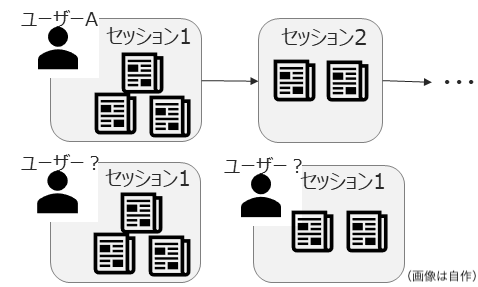
シーケンス情報に一定の区切りがあるようなデータ構造を用います
- 例:ログイン〜ログアウトまでを1つのセッションとする、など
本領域の特徴
- 短期的な行動のみに基づく推薦が求められます(一つあたりのセッション長は短い場合が多いため)
- シーケンス情報よりも対象とするシーケンス長が短く、だいたい3〜数十程度の長さを対象としたデータセットが多いです
- GDPR・個人情報保護などを背景にユーザーは匿名を仮定する場合が多く,ユーザーの属性情報は扱わない問題設定として議論されることが多いです(そのため、この記事でもセッション情報だけは属性情報あり/なしで分けずに紹介しています)
アプローチ
セッション情報に対するアプローチとしては、時系列モデルやそれを更に拡張してGNNによるエンべディングを挟むような手法が近年の主流となっています
時系列モデル
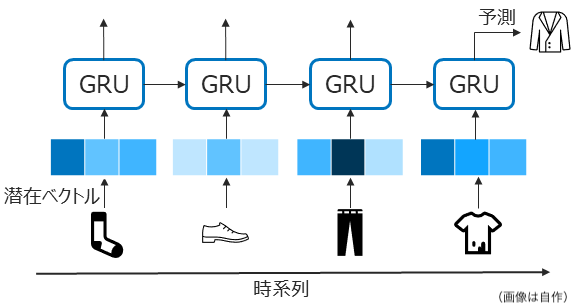
代表的手法のGRU4Rec (2016)[6]について紹介します。
GRU4RecはTransformer登場以前に自然言語処理界隈でよく用いられていたRNNのアーキテクチャの一つであるGRUを用い、シーケンス情報を時系列的に考慮するモデルです。
GRU構造で順番にエンコードすることで、アイテム間の類似性や相補性を学習できると言われています。
GNN + 時系列モデル
セッション情報はシーケンス長が短いということもあり、時系列モデルのみで類似性などを考慮して推薦精度を高めるのは限界が見えつつありました。
そこで現れたのが、グラフニューラルネットワーク(GNN)を用いてユーザー・アイテム間の関係性を表現し、より洗練されたユーザー・アイテム潜在表現を獲得してから時系列モデルでそれらを処理する手法です。
GC-SAN (2019)[7]はその代表的手法の一つであり、セッション履歴を1つの有向グラフで表現し、得られた有向グラフをGNNに入力してアイテムの潜在表現を学習しながら、アテンション機構によってアイテム間の関係性も学習します。
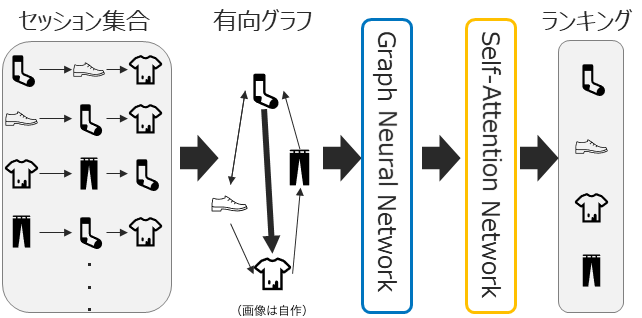
その他
上で紹介した手法は、すべて1つのセッション内の情報だけで学習するモデルでした。
Cross-sessions Encode/Concat/Auto (2022)[8]は、GRU4Recを拡張して複数のセッションをまたいで情報を処理するアーキテクチャを提案しています。
この論文の主題はアーキテクチャではない(と思っている)のですが、一つのセッションにとどまらない形での学習方法・モデルとして紹介しました。
所感
- セッション情報はシーケンス情報と同一視される場合が多く、セッション情報特有の課題に対する研究はまだまだ未発達であるという印象です(論文の比較手法でもシーケンス情報を対象とした手法と比較していることも多いです)
- アイテムの属性情報を活用するような研究は今回見つけられなかったですが、今後発展するかもしれません
簡易検証
最後に、今回紹介した手法の性能を簡易的に確認したいと思います。
データセット
- Movielens-100k:視聴した映画に対して5段階で評価したデータセット
| データセット | ドメイン | ユーザー数 | アイテム数 | データ数 | sparsity[%] |
|---|---|---|---|---|---|
| Movielens-100k | 映画 | 1,000 | 1,700 | 100,000 | 94.1 |
※sparsity = (1 - データ数 / (ユーザー数 × アイテム数)) × 100。値が大きいほどデータセットのスパース性が高くユーザーの好みが推定しづらい。
※本来は前回記事とデータセットを揃えたかったのですが、モデルが大規模過ぎて学習が終わらないので、データセットの規模が小さいMovielens-100kを今回は採用しました。
モデル
- NeuMF (ベースライン)
- BERT4Rec
- GRU4Rec
- Caser
- GC-SAN
- S3-Rec
実装はRecBoleというライブラリを利用します。
結果・考察
| モデル | パラメータ数 | MRR@10 | nDCG@10 | 実行時間[s] |
|---|---|---|---|---|
| NeuMF | 361,153 | 0.70 | 0.60 | 120 |
| BERT4Rec | 220,736 | 0.69 | 0.59 | 3556 |
| GRU4Rec | 158,952 | 0.80 | 0.68 | 861 |
| Caser | - | - | - | - |
| GC-SAN | 253,248 | 0.80 | 0.67 | 14265 |
| S3-Rec | - | - | - | - |
※Caserは使用しているPyTorchとの相性が悪いのかエラーが出たため結果なし、S3-Recについては1日経っても学習が終わらなかったので今回は結果なしとしています。
今回紹介した手法はNeuMF(時系列を考慮しないモデル)と比べると同等以上の性能を示すことが確認できました。
このことから、ユーザーの短期的な選好の変化を学習することが重要であるのだろうと考えられます。
時系列情報を考慮するモデルの間で比較すると、BERT4Recは他2つの手法(GRU4RecとGC-SAN)に大きく劣る結果となりました。
理由としては、今回のデータセットのユーザーあたりのセッション長が短めだったことが挙げられると思います。
GRU4Recはもともとセッション情報向け手法でセッション長が短いことが前提ですし、GC-SANは時系列モデルの前段にGNNが挟まってより洗練されたエンべディングで学習できたことで差が生まれたのではないかと考えられます。
GC-SANは高い性能を示しましたが、GNN部分と時系列モデル部分の2つを学習しなければならない分、パラメータ数と実行時間が大きくなりがちで、実利用には使いづらそうに感じました。
全体を通して、時系列情報を使わないモデルと比べてモデルの規模・実行時間が大きくなりがちで大規模データセットには適用が難しそうだったので、精度を落とさずに軽量化した手法も今後調べてみようと思います。
まとめ
今回は、「シーケンス情報あり・属性情報なし」、「シーケンス情報あり・属性情報あり」、「セッション情報あり」の3つの領域について紹介しました。
シーケンス情報を扱うための手法としてTransformerやGNNを活用する手法が今後の主流となりそうです。
また、「シーケンス情報あり・属性情報あり」の領域についてはこれから研究が盛り上がる領域だと感じましたので、今後注視していきたいと思います。
簡易的な検証では、前回紹介した時系列情報を考慮しない領域と比べると得られる情報が増えて性能は上がる傾向にありましたが、実行時間などの観点ではまだまだ改善の余地があるという結果になりました。
参考
- Zhu et. al., "BERT4Rec: Sequential Recommendation with Bidirectional Encoder Representations from Transformer", CIKM (2019)
- Chen et. al., "Denoising Self-Attentive Sequential Recommendation", RecSys (2022)
- Tang et. al., "Personalized Top-N Sequential Recommendation via Convolutional Sequence Embedding", WSDM (2018)
- Zhou et. al., "S^3-Rec: Self-Supervised Learning for Sequential Recommendation with Mutual Information Maximization", CIKM (2020)
- Zhang et. al., "Neural Time-Aware Sequential Recommendation by Jointly Modeling Preference Dynamics and Explicit Feature Couplings", IEEE Trans Neural Netw Learn Syst (2022)
- Hidasi et. al., "Session-based Recommendations with Recurrent Neural Networks", ICLR (2016)
- Xu et. al., "Graph Contextualized Self-Attention Network for Session-based Recommendation", IJCAI (2019)
- Bruun et. al., "Learning Recommendations from User Actions in the Item-poor Insurance Domain", RecSys (2022)