はじめに
この記事では pythonのライブラリの gensimの中のLDAのモデルを使ってフォローされたQiitaタグの関係からユーザーの嗜好を考えてみようということをやってみます。
トピックモデルやgensimを実際にデータと共に使ってみることでどんなものか見てみることを目的とします。これを入り口にしてトピックモデルを実際に使ってみたり、詳しく勉強をはじめるきっかけとなれば幸いです。
LDAのモデルの内部がどのように実装しているかにはあまりふれません。「どういうことが出来るのか」にフォーカスします。また、データの取得(スクレイピング他)も触れます。
- データ取得(スクレイピング、API)
- データの成形
- モデルへの適用
詳しく説明している記事もありましたのでこの記事を読まれた後に物足りなさを感じた方は読んで見るとよいかと思います。
-
数式をなるべく使わずにトピックモデルの解説にチャレンジ
- 図を使って説明してあるので分かりやすいです。
-
トピックモデルの話
- Slide shareです。これのLDAの項目に数式で書いてあります。量は多くないですがすっきりまとめてある印象です。
また、トピックモデルに関する書籍で実際に紹介されたものでかつ調べてみてもよく紹介されている2冊をここで紹介します。
なお、私自身も執筆時点で勉強中ですので間違っている点やその他アドバイス等ありましたら、コメントにてご教示頂けますと幸いです。
トピックモデルとは
簡単にいうと、文章を内容からトピック(カテゴリ)を推定して分類するモデルです。
トピックモデルは文章中の単語が出現する確率を推定することで文章を分類することが出来ます。似たような単語が出てくるなら同じトピックと考える仕組みです。
どういったことが出来るのかに説明すると、例えば複数の文章があってそれを任意の個数のカテゴリに分類してくれます。
例えばニュース記事を500記事用意しましょう。そしてそれをこのモデルに 「10個のカテゴリに分けて」とお願いすると、500記事を文章の単語から判断して関係のあるまとまり10カテゴリに分けてくれます。
ここで注意が必要なのはそのまとまりそれぞれが「スポーツ」カテゴリとか「芸能」カテゴリとか必ずしも名前を付けられるかまでは分からないということです。「スポーツ」カテゴリではなくて、「野球」カテゴリと「サッカー」カテゴリかもしれません。あくまで教師なし学習なので特定のラベルがつくわけではありません。
その分面白いのは今まで思っていなかったような分け方をモデルが判定してくれるということです。トピックごとに重みの強い単語群を眺めてみると何か新しい示唆を与えてくれるかもしれません。
また、分けるカテゴリの個数を変えてみると単語群が変わって面白いです。
トピックモデルはどうやるのか
さて、これまでの例で出てきた内容の手順をまとめると、以下のような手順で文章のトピック分類が出来そうです。
- 文章を用意する
- 文章を単語に分ける (形態素解析)
- 単語を調整 (stop wordの除去、ステミング)
- ベクトル化 (bag of words)
- 必要な形式に変換してLDAのモデルに投入
これと同じようなことをやっている下記記事が参考になります。
トピックモデルを利用したアプリケーションの作成
また、以下の記事も似たようなことをやっているのですが、最後はLDAではなくランダムフォレストで教師あり学習をしています。比較しながら違いを見ると面白いと思います。
scikit-learnとgensimでニュース記事を分類する
今回やること
さて、LDAはいろいろなことに適用出来るようです(そういうふうにききました)。というわけでちょっと違ったことをやってみたいと思います。
ここから、やっとタイトルに出した「Qiitaのタグからユーザーの嗜好を考える」というのをやっていきます。
これまでの例だと、文章中の単語から文章をカテゴリ分けしました。
それを
- 文章 -> ユーザー
- 単語 -> フォローしているタグ
- 文章のカテゴリ分け -> ユーザーの属性分け
のように見立ててLDAをやってみたいと思います。
実装
手順
- データの取得
- ユーザーデータ
- ユーザーデータに紐づくフォロータグデータ
- データの成形
- モデルへの適用
データの取得
まずはユーザーのデータを取得します。今回は Contribution数上位1000人をまず持ってきます。
Qiita User Ranking のデータを利用させて頂きました。QiitaのユーザーがContribution順に並んでいるのでそれをそのまま取得します。
1ページ20ユーザーなので50ページクローリングします。
import requests
from bs4 import BeautifulSoup
import csv
import time
base_url = 'https://qiita-user-ranking.herokuapp.com/'
max_page = 50 # 1ページあたりユーザー20
qiita_users = []
for i in range(max_page):
target_url = base_url + "?page=" + str(i + 1)
target_html = requests.get(target_url).text
soup = BeautifulSoup(target_html, 'html.parser')
users = soup.select('main > p > a') # ユーザー名の位置
for k, user in enumerate(users):
qiita_users.append([(i*20 + k + 1), user.get_text()]) # ユーザーid(順位)とユーザー名
time.sleep(1) # サーバーに負荷をかけ過ぎないように1秒ずつ間隔を空ける
print('scraping page: ' + str(i + 1))
# CSVにデータを吐き出す
f = open('qiita_users.csv', 'w')
writer = csv.writer(f, lineterminator='\n')
writer.writerow(['user_id', 'name'])
for user in qiita_users:
print(user)
writer.writerow(user)
f.close()
以下のようなCSVが得られます。
user_id,name
1,hirokidaichi
2,jnchito
3,suin
4,icoxfog417
5,shu223
...
次に、 タグデータを取得します。Qiitaの提供するAPIを使って各ユーザーがフォローするタグデータを取得します。 https://qiita.com/api/v1/users/(user_name)/following_tags のような形でタグデータを取得出来ます。ただし、QiitaのAPIは1時間に150リクエストしか受け入れていないので1,000人のタグのデータを一気に取得することは出来ませんでした。今回は1時間たった後にもう一回実行するとCSVを更新してくれるようにしました(7回やると1,000人分に到達)。データは150人分とりあえず取得でもこの後問題なく進めます。(そもそも1,000という数字は適当です。変えてみると面白い結果が得られるかもしれません。欲をいうとAPI経由ではなくQiitaのデータを直接SQLで取りたい。。)
import csv, requests, os.path, time
# 先程のユーザーデータを使います。
f = open('qiita_users.csv', 'r')
reader = csv.reader(f)
next(reader)
qiita_tags = []
qiita_user_tags = []
# CSVのユーザーデータの個数を取得します。(1回目は関係なし)
if os.path.isfile('qiita_user_tags.csv'):
user_tag_num = sum(1 for line in open('qiita_user_tags.csv'))
else:
user_tag_num = 0
# CSVのタグデータが既にあればそのタグデータを取得(1回目は関係なし)
if os.path.isfile('qiita_tags.csv'):
f_tag = open('qiita_tags.csv', 'r')
reader_tag = csv.reader(f_tag)
qiita_tags = [tag[0] for tag in reader_tag]
# CSVファイルをオープン
f_tag = open('qiita_tags.csv', 'w')
writer_tag = csv.writer(f_tag, lineterminator='\n')
f_user_tag = open('qiita_user_tags.csv', 'a')
writer_user_tag = csv.writer(f_user_tag, lineterminator='\n')
# ユーザーごとにAPIを叩く
for user in reader:
if user_tag_num < int(user[0]):
target_url = 'https://qiita.com/api/v1/users/' + user[1] + '/following_tags'
print('scraping: ' + user[0])
# エラーチェック (リクエスト数のオーバー、ユーザーが存在しないの2点が出る)
try:
result = requests.get(target_url)
except requests.exceptions.HTTPError as e:
print(e)
break
target = result.json()
# リクエスト数オーバーのときは諦める
if 'error' in target:
print(target['error'])
if target['error'] == 'Rate limit exceeded.':
break
continue
# user_id, tag_1, tag_2, ... のようにデータを入れる
qiita_user_tag = [int(user[0])]
for tag in target:
if tag['name'] in qiita_tags:
qiita_user_tag.append(qiita_tags.index(tag['name']) + 1)
else:
qiita_tags.append(tag['name'])
tag_num = len(qiita_tags)
qiita_user_tag.append(tag_num)
qiita_user_tags.append(qiita_user_tag)
time.sleep(1) # サーバーに負荷をかけ過ぎないように1秒間隔を空ける
# データをCSVに吐き出す
for tag in qiita_tags:
writer_tag.writerow([tag])
writer_user_tag.writerows(qiita_user_tags)
f_tag.close()
f_user_tag.close()
f.close()
以下、出力例。CSVファイルがタグのファイルとユーザーとタグの関係のデータのファイルの2つが出来ます。タグの行番号がタグのidになるようにしています。
GoogleAppsScript
ActionScript
JavaScript
CSS
docker
...
1,1,2,3,4
2,5,6,7,3,8,9,10,11,12,13,14,15,16,17
3,18,19,20,21,22,23,24,25,26,27,28,29,30,31,32,33,34,35,36,37
4,38,39,40,41,42,43,44,45,46,47,48,3,49
5,50,51,52,53,54,55,56,57,58,59,60,41,61,62,63,64,65,66,67,68
...
データの成形とモデルへの適用
データの成形とモデルの成形を行います。
以下の1ファイルで実行可能ですが、実際には iPython notebookで作業は行っています。
またクラスにしてもっと使いやすく出来そうですが、作成した流れが分かれば十分なので作業の流れそのままです。
import csv
import gensim
from pandas import DataFrame
# タグのid(key)とname(value)を結びつける辞書の作成
tag_name_dict = {}
with open('qiita_tags.csv', 'r') as f_tags:
tag_reader = csv.reader(f_tags)
for i, row in enumerate(tag_reader):
tag_name_dict[(i+1)] = row[0]
# あるユーザー(key)がどのタグをフォローしているか
user_tags_dict = {}
with open('qiita_user_tags.csv', 'r') as f_user_tags:
user_tags_reader = csv.reader(f_user_tags)
for i, row in enumerate(user_tags_reader):
user_tags_dict[int(row[0])] = row[1:-1]
# tags_list フォローされているタグのリスト (複数人にフォローされていればダブリあり)
tags_list = []
for k, v in user_tags_dict.items():
tags_list.extend(v)
# 1人にしかフォローされていないタグ
once_tags = [tag for tag in tags_list if tags_list.count(tag) == 1]
# 1人しかフォローされていないタグをuser_tagsのタグからも削除
user_tags_dict_multi = { k: [tag for tag in user_tags if not tag in once_tags] for k, user_tags in user_tags_dict.items()}
# タグをフォローしていないユーザーを省く (1人しかフォローしていないタグは削除していることに注意)
user_tags_dict_multi = {k: v for k, v in user_tags_dict_multi.items() if not len(v) == 0}
# gemsimへのインプットのために変換
corpus = [[(int(tag), 1) for tag in user_tags]for k, user_tags in user_tags_dict_multi.items()]
# LDAのモデルの呼出と学習 ここでtopicの数(ユーザー層の数)を設定出来る
lda = gensim.models.ldamodel.LdaModel(corpus=corpus, num_topics=15)
# 各トピックの出現頻度上位10位を取得
topic_top10_tags = []
for topic in lda.show_topics(-1, formatted=False):
topic_top10_tags.append([tag_name_dict[int(tag[0])] for tag in topic[1]])
# 各トピックの出現頻度上位10位を表示
topic_data = DataFrame(topic_top10_tags)
print(topic_data)
print("------------------")
# ユーザーの嗜好の表示
c = [(1, 1), (2, 1)] # タグ1とタグ2をフォローしているユーザー
for (tpc, prob) in lda.get_document_topics(c):
print(str(tpc) + ': '+str(prob))
結果
以下各トピックごとの単語群です。(iPython notebookの表示を使いました)
各行が各トピックを表します。行0のユーザー層、行1のユーザー層、...といった感じで15個のユーザー層にわかれました。
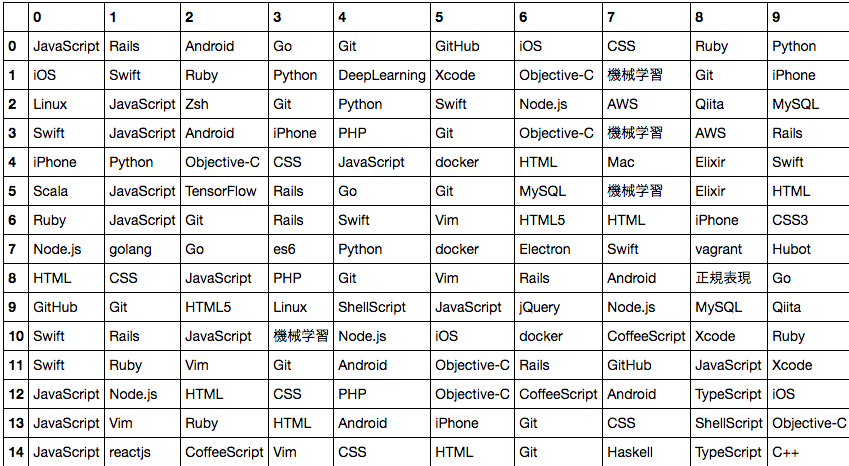
タグ1とタグ2をフォローしているユーザーがどのトピックに属しているか。「7」っぽいようです。今回は適当にinputしましたが、自分のフォローしているタグをinputデータにすれば自分がどんなユーザー層か見えるかもしれません。
また、これを利用すればタグのレコメンド的なことも出来そうです。
0: 0.0222222589596
1: 0.0222222222222
2: 0.0222222417019
3: 0.0222222755597
4: 0.022222240412
5: 0.0222222222222
6: 0.0222222374859
7: 0.688888678865
8: 0.02222225339
9: 0.0222222557189
10: 0.0222222222222
11: 0.0222222222222
12: 0.0222222222222
13: 0.0222222245736
14: 0.0222222222222
おまけ: 以下はトピック数20個バージョンです。なんとなく20個のほうが傾向見えるような気がします。
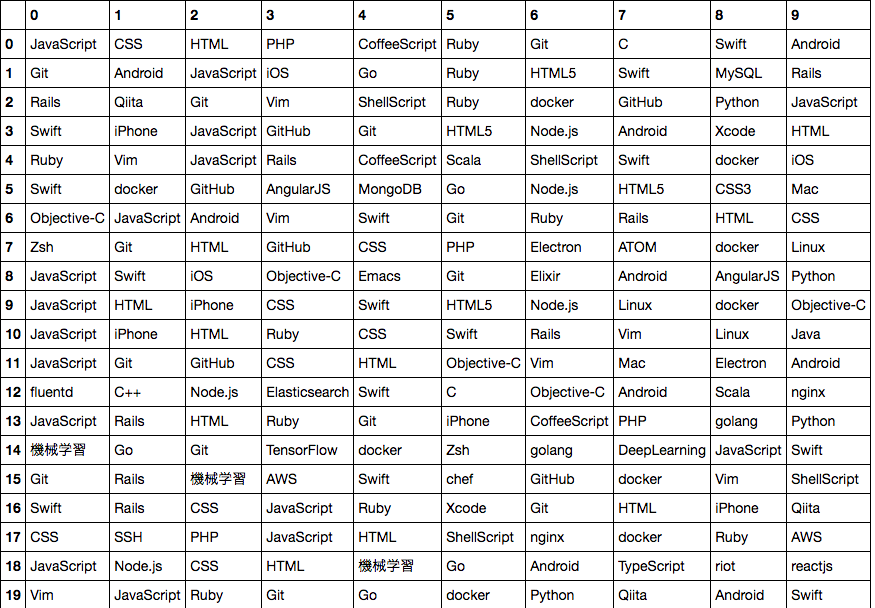
データ数を増やしたり、トピック数を変えることで色々なことが見えてきそうです。
終わりに
これをきっかけにトピックモデルに興味を持たれた方がいれば幸いです。
自分でももっと勉強しようと思います。