本記事は、原著者の許可を得て以下のリンクを翻訳したものです。翻訳内容に誤りがある場合、その責任は翻訳者にあります。また記事によっては、訳語を適宜Qiitaで読みやすいように段落分け、カテゴライズ分けをして記述しているものもありますのでご了承ください。
https://fullvalence.com/2026/01/13/from-vmware-to-ibm-cloud-vpc-vsi-part-7-automation/
このシリーズの全てのブログ記事はこちらです:
- VMwareからIBM Cloud VPC VSIへ(パート1):導入
- VMwareからIBM Cloud VPC VSIへ(パート2):VPCネットワーク設計
- VMwareからIBM Cloud VPC VSIへ(パート3):仮想マシンの移行
- VMwareからIBM Cloud VPC VSIへ(パート4):バックアップとリストア
- VMwareからIBM Cloud VPC VSIへ(パート5):VPCオブジェクトモデル
- VMwareからIBM Cloud VPC VSIへ(パート6):ディザスターリカバリー
- VMwareからIBM Cloud VPC VSIへ(パート7):自動化
- VMwareからIBM Cloud VPC VSIへ(パート8):Veeam Backup and Replication
VPCのオブジェクトモデルを考えると、大規模な環境をデプロイおよび管理するには自動化の活用を検討する必要があることは明らかです。さらに、災害対策(ディザスタリカバリー)を想定し、あるリージョンから別のリージョンへVPC環境を複製または再作成する計画がある場合、運用上の課題は一層増大します。
そこで私は、以下をどのように実現するかを示すことを目的に、比較的シンプルなTerraformモジュールのセットを作成しました。
- IBM Cloudの1つのリージョンに、シンプルな2層のオートスケーリングアプリケーションをデプロイする
- 災害対策に備えて、2つ目のIBM Cloudリージョンにこのアプリケーション用のVPCネットワークトポロジーの雛形を作成する
- 最初のリージョンから2つ目のリージョンへアプリケーションデータをレプリケーションする
- 災害発生時にアプリケーションを2つ目のリージョンへフェイルオーバーする
アプリケーション設計
この2層アプリケーションは簡易的な(試験用の)ものです。構成は以下の通りです:
- IBM Cloudのリージョナル・アプリケーション・ロードバランサー
- その背後に、リージョン内の3つのゾーンに分散された3台以上のオートスケーリング対応アプリケーションVSIを配置
- さらにその先に、リージョンの最初の2ゾーンに分散されたプライマリ-スタンバイ構成のデータベースVSIペアを配置
第1層で動作する「アプリケーション」は単にSSHです。これらのVSIは共通のSSHホストキーを共有しており、これはWebアプリケーションで証明書を共有するのと似た考え方です。
データベースは、ストリーミングレプリケーションモードで構成されたPostgreSQLです。アプリケーションからデータベースへの接続は、単にpsqlコマンドを使用します。また、アプリケーションVSIからはパスワードなしで直接接続できるように設定されています。
Apply complete! Resources: 76 added, 0 changed, 0 destroyed.
Outputs:
region1_lb_hostname = "2e3d3210-us-east.lb.appdomain.cloud"
region2_lb_hostname = "5532cedf-ca-tor.lb.appdomain.cloud"
smoonen@laptop ibmcloud-vpc-automation % ssh root@2e3d3210-us-east.lb.appdomain.cloud
Welcome to Ubuntu 24.04.3 LTS (GNU/Linux 6.8.0-1041-ibm x86_64)
. . .
root@smoonen-tier1-tlha2hqzy6-lrioe:~# psql -h db-primary.example.com testdb appuser
psql (16.11 (Ubuntu 16.11-0ubuntu0.24.04.1))
testdb=> \dt
List of relations
Schema | Name | Type | Owner
--------+------------------+-------+----------
public | test_replication | table | postgres
(1 row)
プライマリリージョン内でのデータベースサーバーのフェイルオーバーは、この検証の範囲外です。PostgreSQLのフェイルオーバーやDNSの再割り当てを管理するには、独自の自動化や運用プロセスを構築する必要があります。
以下の図は、アプリケーションのトポロジーと、セカンダリリージョンへのストレージレプリケーションの様子を示しています。
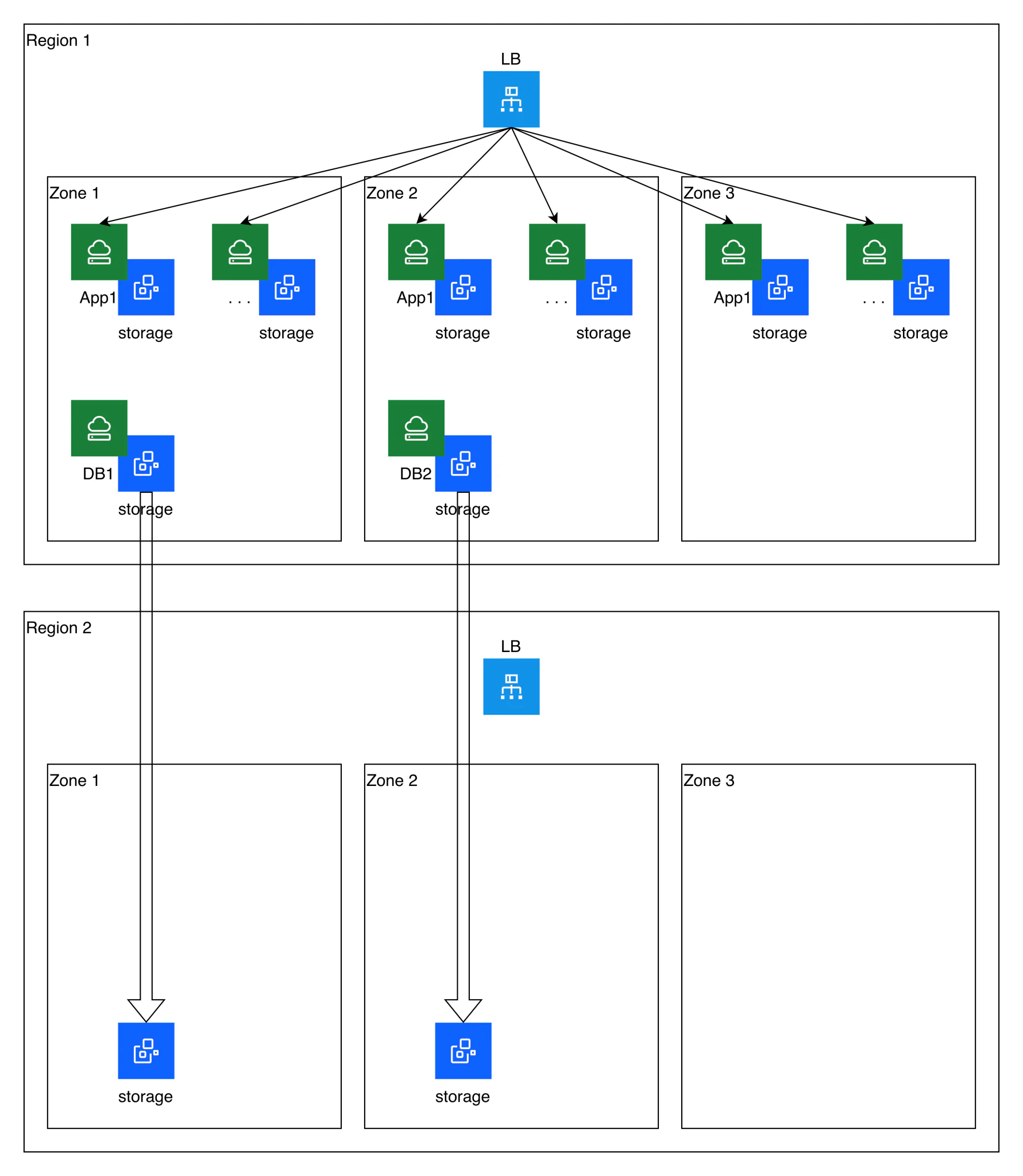
レプリケーション
以前に記載した通り、この自動化では、シンプルなレプリケーション手法としてブロックストレージのスナップショットとクロスリージョンコピーを利用しています。ただし、この方法には "ボリューム間の書き込み順序の整合性(write-order consistency)が保証されない""RPO(目標復旧時間)上の制限"といった制約があります。この例ではボリュームは1時間間隔でコピーされますが、実際の環境ではRPOはさらに長くなる可能性があります。
書き込み順序の整合性がないため、このモデルではどちらのデータベースが「最新」か(どちらをプライマリとして復元すべきか)を判断する必要があります。
また、アプリケーションデータ(例えばIBM Cloud VPCのファイルストレージに保存され、セカンダリリージョンにもレプリケートされているトランザクションログなど)を扱う場合も、復旧処理を完了する前に同様の整合性確認が必要です。
この例では、アプリケーションサーバーはステートレスであるため、そのストレージはセカンダリリージョンにはレプリケートされません。定義情報から再作成することが可能です。
フェイルオーバー
上記の図から分かるように、通常のレプリケーション稼働時には、セカンダリリージョンにはロードバランサー以外の稼働中インフラは存在しません。
フェイルオーバー時には、追加のTerraformモジュールを使用して、最新のコピー済みストレージスナップショットを特定し、それを基にアプリケーションサーバーおよびデータベースサーバーのインスタンスやインスタンスグループを再構築します。
詳細
追加の手順および考慮事項については、GitHubリポジトリのドキュメントを参照してください。