はじめに
この記事は前回の研究論文編の続編です.今回は,2021年のおもしろかった深層学習応用事例を紹介します.
* 本記事は,私のブログにて英語で書いた記事を翻訳し,適宜加筆修正したものです.元記事の方も拡散いただけると励みになります.
事例4選
紹介するのはこちらの4事例です!
AlphaFold2
タンパク質の機能はその構造に依存するため,タンパク質の構造は生物の内部で何が起きているのかを理解するための鍵の一つです.しかし,タンパク質の構造を実験によって解析するには膨大な時間と費用がかかります.また,アミノ酸配列から構造を正確に予測することは不可能でした(タンパク質の折りたたみ問題)——AlphaFold(2)[1]が登場するまでは.
私は構造生物学に詳しくないので,AlphaFold2の詳細についてはここでは触れませんが,DeepMindの公式ブログ「AlphaFold: a solution to a 50-year-old grand challenge in biology」にある次の図を見ると,これが本当のブレイクスルーなのだと納得できます.
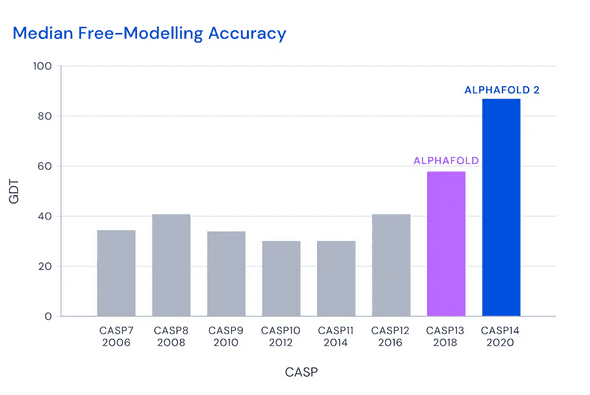
AlphaFold2の完全版は,3TBのディスクとGPUを含む巨大な計算資源を必要とします(詳細はこちら).しかし,幸いなことに簡易版ならGoogle Colabで試すことができます.
「予測」されたタンパク質構造のデータベースもすでに公開されています.AlphaFoldがライフサイエンスや創薬をどのように加速していくのか,楽しみですね.
ちなみに,AlphaFold2に関しては,AlphaFold2解体新書を始めとして日本語の情報が充実しているようです.
GitHub Copilot
GitHub Copilot は,極めて賢いコードのオートコンプリート機能です.Copilotはコードコメントを含む文脈に基づき,現在のコードを完成させるために最適なコードスニペットを提案します.Copilotのコアとなる機械学習モデルは,GitHubで公開されているソースコードで学習した大規模な言語モデル,OpenAI Codexです[2].
以下のビデオにある通り,関数を書きたいときは,適切なコメントを書いてタブキーを押すだけで済みます.Copilotがあなたに代わって関数を完成させてくれるのです.
Copilotは(まだ)完璧なプログラマではないので,オートコンプリートされたコードが正しいかどうかを確認するために常にテストコードを書かなければなりません(Copilotはその作業も支援します!).いずれにせよ,特にその言語やフレームワークに精通していない場合は,ほぼ確実にコーディングの総時間を短縮できるでしょう.
Copilotが巻き起こしている論争についても触れておくべきでしょう.研究論文編で紹介した論文「Extracting Training Data from Large Language Models」が指摘するように,Codexは学習データを記憶している可能性が高いです.そのため,個人情報(誤ってアップロードしたAPIキーなど)を抜き出したり,ライセンスで保護されているリポジトリからコードを盗用したりする可能性があります.また,公開リポジトリに存在する間違ったコード,悪意のあるコード,非効率なコードが拡散するのを助長する可能性もあります.
エアフレンド
エアフレンド は,自分好みに育てることができるチャットボットです.会話をしながら自分の理想とする反応をチャットボットに細かく設定することができます.また,チャットボットを(物理的な)友人と共有することもできます.
現在,エアフレンドは日本語にしか対応していませんが,その自然な会話とカスタマイズ性が評価され,すでに65万人のユーザーを獲得しています.
AIで架空の友達を育てて共有したり,みんなが育てたAIと話せる無料アプリ「エアフレンド」を個人開発しました.推しが言いそうなセリフをAIに教えると,推しの人格を学習したAIと会話できます
— Ryobot (エアフレンド開発者) (@_Ryobot) September 14, 2021
エアフレンド→ https://t.co/NhvnUd7CAo pic.twitter.com/wcK6BzgbcN
エアフレンドのもう一つの素晴らしいところは,個人(@_Ryobot)が開発していることです.チャットボットのモデルは10億個のパラメータを持つTransformerなので,数千ものユーザーに対してサービスを提供し続けるのは大変なことだと想像されます.他の言語は「近いうちに」対応されるそうです.
Google Meetの背景効果
Google Meet の背景効果は,ウェブブラウザ上での機械学習(WebML)の最も身近な例と言えるでしょう.ご存知のように,Google Meetは背景をぼかしたり,置き換えたりすることができます.ZoomやMicrosoft Teamsなど他のオンライン会議アプリもこの機能をサポートしていますが,1つだけ違うことがあります.Google Meetはブラウザ上で動作するのです.
この背景の効果は,深層学習ベースのセグメンテーションが必要で,素朴に実装するとリアルタイム処理には重すぎます.Google Meetに込められた魔法は,Google AIのブログで明らかにされています.簡単に説明すると,セグメンテーションからレンダリングまでのパイプライン全体を,ストリーミングデータに最適化された機械学習フレームワークである**MediaPipe**で定義し,WebAssembly(Wasm)に変換しています.実行時には,ブラウザがWasmのコードをネイティブのマシンコードに変換するため,JavaScriptのコードよりも高速に実行されます.

図は"Google AI Blog: Background Features in Google Meet, Powered by Web ML"より.
セグメンテーションモデルには,TFLite にエクスポートし,XNNPACKで加速したMobileNetV3-small [3]を採用しています.MobileNetは低解像度のセグメンテーションマスクを出力し,このマスクは後続のモジュールで改良されます.
本機能については,日本語でも詳しい解説記事が出ています.
おわりに
最後までお読みいただきありがとうございました.毎年恒例のこの記事がお役に立てれば幸いです.2022年が素晴らしい一年になりますように.
参考文献
[1] John Jumper, Richard Evans, Alexander Pritzel, Tim Green, Michael Figurnov, Olaf Ronneberger, Kathryn Tunyasuvunakool, Russ Bates, Augustin Žídek, Anna Potapenko, Alex Bridgland, Clemens Meyer, Simon A. A. Kohl, Andrew J. Ballard, Andrew Cowie, Bernardino Romera-Paredes, Stanislav Nikolov, Rishub Jain, Jonas Adler, Trevor Back, Stig Petersen, David Reiman, Ellen Clancy, Michal Zielinski, Martin Steinegger, Michalina Pacholska, Tamas Berghammer, Sebastian Bodenstein, David Silver, Oriol Vinyals, Andrew W. Senior, Koray Kavukcuoglu, Pushmeet Kohli, Demis Hassabis. "Highly accurate protein structure prediction with AlphaFold". Nature. 2021.
[2] Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde de Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, Alex Ray, Raul Puri, Gretchen Krueger, Michael Petrov, Heidy Khlaaf, Girish Sastry, Pamela Mishkin, Brooke Chan, Scott Gray, Nick Ryder, Mikhail Pavlov, Alethea Power, Lukasz Kaiser, Mohammad Bavarian, Clemens Winter, Philippe Tillet, Felipe Petroski Such, Dave Cummings, Matthias Plappert, Fotios Chantzis, Elizabeth Barnes, Ariel Herbert-Voss, William Hebgen Guss, Alex Nichol, Alex Paino, Nikolas Tezak, Jie Tang, Igor Babuschkin, Suchir Balaji, Shantanu Jain, William Saunders, Christopher Hesse, Andrew N. Carr, Jan Leike, Josh Achiam, Vedant Misra, Evan Morikawa, Alec Radford, Matthew Knight, Miles Brundage, Mira Murati, Katie Mayer, Peter Welinder, Bob McGrew, Dario Amodei, Sam McCandlish, Ilya Sutskever, Wojciech Zaremba. "Evaluating Large Language Models Trained on Code". 2021.
[3] Andrew Howard, Mark Sandler, Grace Chu, Liang-Chieh Chen, Bo Chen, Mingxing Tan, Weijun Wang, Yukun Zhu, Ruoming Pang, Vijay Vasudevan, Quoc V. Le, Hartwig Adam. "Searching for MobileNetV3". ICCV. 2019.