はじめに
2019年,2020年に引き続き,1年を振り返って最もおもしろかった深層学習の論文を選んで紹介したいと思います.最近,目を通す論文の数が減ってしまったので,今回は取り上げるのを8本とし,別記事として「応用事例編」を書くことにします.
* 本記事は,私のブログにて英語で書いた記事を翻訳し,適宜加筆修正したものです.元記事の方も拡散いただけると励みになります.
** 記事中の画像は,ことわりのない限り対象論文からの引用です.
論文8選(公開順)
普段から,読んだ論文を簡単にまとめてツイートしているので,それを使って公開日順に振り返っていきます.対象はおおまかに「2021年に公開された論文」と「2021年に学会・雑誌で発表されたもの」とします.他におもしろい論文があれば,コメントで教えていただけると嬉しいです1.
紹介するのはこちらの8本です!
- Exploring Simple Siamese Representation Learning
- Extracting Training Data from Large Language Models
- E(n) Equivariant Graph Neural Networks
- Learning Transferable Visual Models From Natural Language Supervision
- Unsupervised Speech Recognition
- Alias-Free Generative Adversarial Networks
- Deep Reinforcement Learning at the Edge of the Statistical Precipice
- Fake It Till You Make It: Face analysis in the wild using synthetic data alone
Exploring Simple Siamese Representation Learning
- 著者: Xinlei Chen, Kaiming He
- URL: https://arxiv.org/abs/2011.10566
- 公開: 2020年11月
- 採録: CVPR 2021
Simple Siamese Representation Learning [Chen+, 2021, CVPR]
— Shion Honda (@shion_honda) December 30, 2021
シャムネットワークによる表現学習において不可欠なのは勾配停止と予測器であることを経験的に示した.負例や大きなバッチサイズは不要.本結果についてEMアルゴリズムとの接続に関する仮説も提示.https://t.co/nseZTH80Rv#NowReading pic.twitter.com/EpmI7mTxza
ここ数年,画像の自己教師(教師なし)表現学習に関する論文が非常に増えています.SimCLR [1],BYOL(2020年の好きな論文の一つ)[2],SwAV [3]など,例を挙げればきりがありません.これらの手法は異なるアプローチをとっていますが,下流タスクでの性能は同程度です.では,自己教師表現学習を成功させるための重要な要素とは何なのでしょうか?
本論文では,単純なシャムネットワーク(SimSiam; simple Siamese network)を用いて実験することでこの問いに答えます.このネットワークは,2つの画像を入力とし,それらの類似度を出力します.2つの枝は,一方には予測モジュールがあり,もう一方には勾配停止演算があることを除いては重み共有されています.SimSiamは,「負例ペアのないSimCLR」,「モメンタムエンコーダーのないBYOL」,そして「オンラインクラスタリングのないSwAV」と解釈することができます.この比較は,下図を見るとよくわかります.
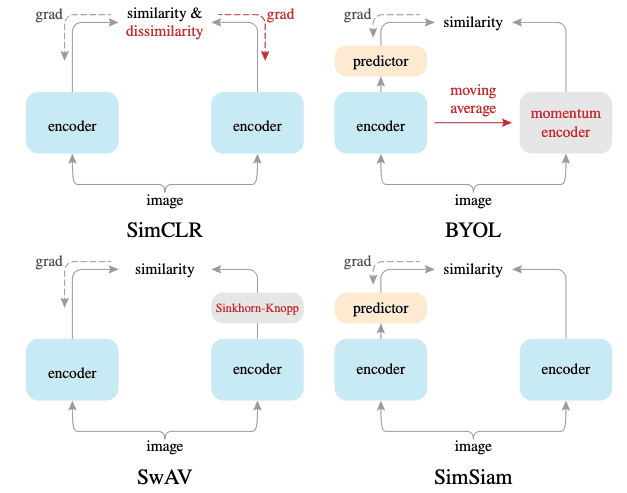
下流タスク(linear evaluation2)において,SimSiamは他の手法と同程度の性能を示しました.

この結果が示唆するのは,自己教師表現学習の重要な要素は,大きなバッチサイズ,負例ペア,モメンタムエンコーダのいずれでもなく,勾配停止と予測モジュールだということです.
また,本論文の著者は,SimSiamはEMアルゴリズムの実装として解釈できると主張しています.より詳細な議論については元論文をご覧ください.
Extracting Training Data from Large Language Models
- 著者: Nicholas Carlini, Florian Tramer, Eric Wallace, Matthew Jagielski, Ariel Herbert-Voss, Katherine Lee, Adam Roberts, Tom Brown, Dawn Song, Ulfar Erlingsson, Alina Oprea, Colin Raffel
- URL: https://arxiv.org/abs/2012.07805
- 公開: 2020年12月
- 採録: USENIX Security Symposium 2021
Extracting Training Data from Large LMs [Carlini+, 2020]
— Shion Honda (@shion_honda) February 11, 2021
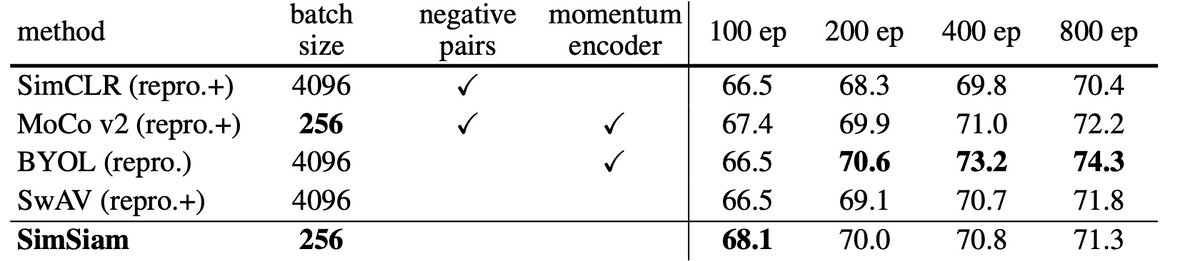
GPT-2から訓練データの一部を取得する攻撃の研究.適当な入力から多数の文章を生成し,他のLMとperplexityを比較するなどの方法で結果を絞り込む.人名やソースコード,チャット記録などが確認された.https://t.co/J0sJL1wDAG#NowReading pic.twitter.com/5bmUyF8JmP
この論文では,大規模言語モデルのある脆弱性を指摘しています.それは,学習データの抽出が可能であるということです.GPT-2(インターネットから収集したデータセットで学習させた,公開されている大規模言語モデル) [4]に繰り返しクエリ文を入力し,生成されたテキストをあるアルゴリズムでフィルタリングすると,名前,電話番号,メールアドレス,128ビットのUUID,オンラインチャットの会話記録などの機密データを抽出することができました.復元されたものの中には,Donald Trump氏のツイートまでありました😱
大きなモデルはより多くの情報を記憶します.実際,著者らのブログ記事によると,GPT-3 [5]は『ハリー・ポッターと賢者の石』の約1ページを正しく再現したそうです.
このプライバシーと著作権の問題は,言語モデルがますます大きくなっている現在の傾向を考慮すると,一層深刻です.この問題を軽減するために,著者らは差分プライバシーを使用したり,学習データを慎重にサニタイズしたりといった対策をいくつか提案していますが,より具体的な解決策が求められています.
E(n) Equivariant Graph Neural Networks
- 著者: Victor Garcia Satorras, Emiel Hoogeboom, Max Welling
- URL: https://arxiv.org/abs/2102.09844
- 公開: 2021年2月
- 採録: ICML 2021
E(n) Equivariant Graph Neural Networks [Satorras+, 2021, ICML]
— Shion Honda (@shion_honda) December 26, 2021
ノードの座標を入力にとりE(n)変換に同変なEGNNを提案.対称性を考慮できるためサンプル効率が良く過学習しづらい.N体粒子の力学系モデリング,GAEの再構成誤差,分子の性質予測(QM9)でSOTA.https://t.co/S0pD3atwhZ#NowReading pic.twitter.com/pVDpSUIsab
「同変性」は,聞き慣れない言葉かもしれませんが,今日の機械学習の主要なトピックの一つです.関数$\phi: X \rightarrow Y$,変換$T_g: X \rightarrow X$,それと対応する変換$S_g: Y \rightarrow Y$が与えられたとき,次の式が成り立つならば$\phi$は抽象的な変換$g$について同変であると呼びます:
$$
\phi(T_g(x)) = S_g(\phi(x)) .
$$
具体例を挙げると,バウンディングボックスを検出するモデルで,入力する画像が横にずれたら,ボックスも同じように移動してほしいというような性質です.関連する概念として,次の式で表される不変性があります:
$$
\phi(T_g(x)) = \phi(x) .
$$
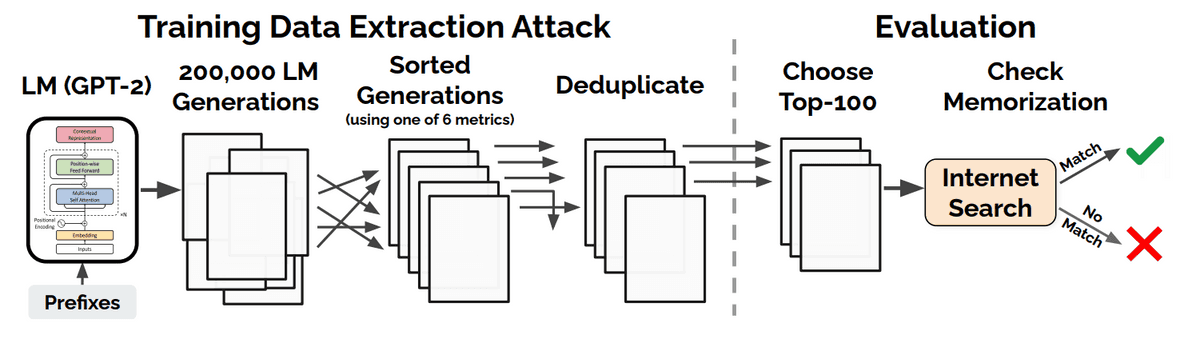
本論文では,$g$としてE(n)変換を考えます.E(n)変換とは,n次元ユークリッド空間における並進,回転,反射,並べ替えのことです.グラフニューラルネットワーク (GNN)は設計上,並べ替えに対しては同変ですが,他の変換に対しては同変ではありません.同変性と不変性の概念は,2次元データよりも自由度の大きい3次元データにおいて,より重要です.
本論文で提案されたEGNN(E(n)-equivariant GNN)は,E(n)変換に対して同変なGNNです.元祖GNNとは異なり,EGNNの各層はノード埋め込み,座標埋め込み,エッジ情報のセットを入力として受け取り,2種類の埋め込みを更新します.
EGNNはその強い帰納的バイアスのおかげで,力学系のモデリングとQM9データセット(原子の3次元座標を含む)の分子活性予測において,特にデータセットが小さい場合に,元祖GNNを上回る性能を発揮しました.EGNNはその後,分子の正規化フローに拡張されました [6].
日本語の解説記事ではこちらが詳しいです.
Learning Transferable Visual Models From Natural Language Supervision
- 著者: Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, Ilya Sutskever
- URL: https://arxiv.org/abs/2103.00020
- 公開: 2021年3月
Learning Transferable Visual Models From Natural Language Supervision [Radford+, 2021]
— Shion Honda (@shion_honda) January 4, 2022
画像とテキストのエンコーダを4億の画像・説明文ペアで対照学習させたCLIPは,ゼロショットで多様な画像分類を高精度に解ける.画像の事前学習パラダイムを変える結果.https://t.co/bS6iMnsUzL#NowReading pic.twitter.com/r8DONjX8DM
個人的には,2021年に発表された論文の中で最もインパクトのある論文だと思います.この論文では,自然言語を教師として視覚的な概念を学習するCLIP(contrastive language-image pre-training)を提案しています.ネットワークはテキストエンコーダと画像エンコーダからなります.2つのエンコーダは,意味的に類似したペアは近く,類似しないペアは遠くなるような空間にテキストおよび画像をエンコードするように同時に学習されます.そしてこれは,インターネットから収集した4億組の画像とテキストを用いた対照学習により実現されています.
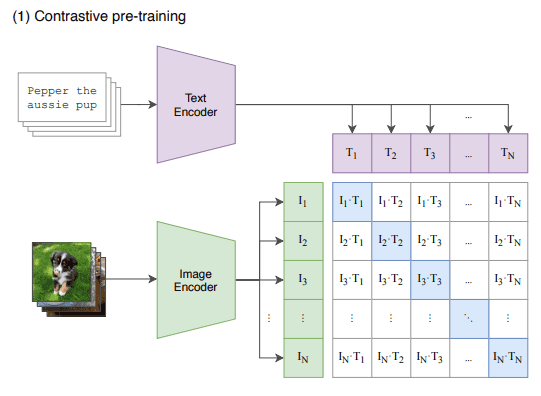
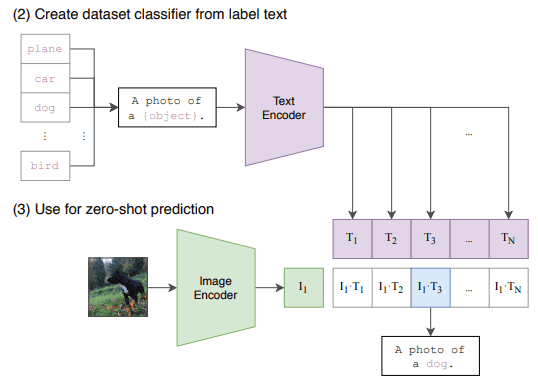
対照事前学習が済むと,CLIPはゼロショットでの画像分類に使用できます.ゼロショット分類の手順は以下の通りです.
- 下流タスクのクラスラベルを文章に変換する
- 与えられた画像をエンコードする
- 文ラベルの候補をエンコードする
- 画像埋め込みと各文埋め込みの内積を計算する
- 最も高い内積を持つクラスを選択する
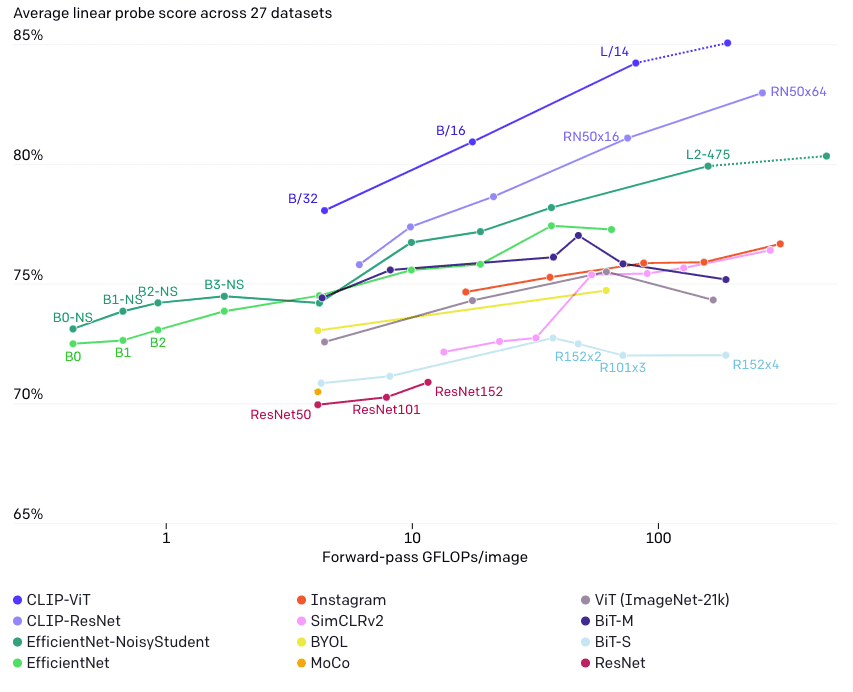
事前学習済みCLIPの性能は抜群です.CLIPのゼロショット分類の精度は,様々なデータセットにおいて,事前学習済みResNet-50の教師あり線形プローブと遜色ありませんでした.また,CLIPの線形プローブは,ImageNetで事前学習された強力なベースラインを凌駕しています.
画像は"CLIP: Connecting Text and Images"より.
さらに,下図で比較したように,ゼロショットCLIPはImageNet事前学習済みモデルよりも分布シフトに対して非常に頑健であることがわかります.これは,ベースラインが見かけの相関(spurious correlations)に騙されてしまうのに対し,ゼロショットCLIPは騙されにくいことが一因と考えられます.

これらの結果は,CLIPが自然言語の教師から広範囲の視覚的概念を学習したことで,その画像埋め込みが柔軟かつ汎用的,さらに頑健になっていることを示唆しています.CLIPは,画像に対する事前学習のパラダイムをImageNetの固定ラベル分類からWebスケールの画像・テキスト対照学習へと変えつつあります.
CLIPはすでに,テキストから画像への合成(DALL-E [7]とVQGAN+CLIPは大いに話題になりました!)や視覚に基づく質問応答 [8] といった興味深いアプリケーションで使用されています.ちなみに,DALL-EはCLIPと同時にOpenAIから公開されました.
最後に,本論文は48ページと圧倒されるほど長いのですが,洞察に満ちた分析が多く含まれており,間違いなく読むに値するものでした.その多くは公式ブログの記事でも省略されているので,ここでは重要なポイントを列挙したいと思います.
- CLIPの目的関数はゼロショット画像分類の精度という点で,Transformerによる言語モデリングやbag-of-wordsの訓練よりもはるかに効率的である.Webスケールでの学習において,効率は非常に重要.
- 訓練時のバッチサイズは32,768.メモリ使用量を節約するために様々なテクニックを使った.
- プロンプトエンジニアリングはパフォーマンスを向上させる.例えば,クラスラベル「ボクサー」(アスリートのボクサーと紛らわしい)をそのまま使うよりも,より説明的な「ペットの一種であるボクサーの写真」の方が良い.
- CLIPは,細かい分類やシステマチックなタスクでは性能が低い.例を挙げるなら,前者は車の種類の分類,後者は物体の数え上げである.
- CLIPの表現はデジタルなテキストには有用だが,手書きのテキストにはそうでない.MNISTでは,ゼロショットCLIPは輝度値に対するロジスティック回帰に負ける.
Unsupervised Speech Recognition
- 著者: Alexei Baevski, Wei-Ning Hsu, Alexis Conneau, Michael Auli
- URL: https://arxiv.org/abs/2105.11084
- 公開: 2021年5月
- 採録: NeurIPS 2021
Unsupervised Speech Recognition [Baevski+, 2021, NeurIPS]
— Shion Honda (@shion_honda) January 3, 2022
wav2vec 2.0で抽出した音声表現から生成した音素とテキストから得られた音素とで敵対的学習を行うことで,教師なしの音声認識を実現した.性能が教師ありに並ぶこともある.低リソース言語でも有効.https://t.co/rgYEkEGz9R#NowReading pic.twitter.com/onPC6hgE91
近年,音声認識の精度が大きく向上し,多くのアプリケーションで活用され始めています.しかし,ほとんどの手法は,書き起こした音声を学習データとして必要とするため,世界で話されている7,000言語のうちごく一部でしか利用できないのが現状です.
そこで著者らは,音声認識をよりインクルーシブにするために,教師を全く必要としないwav2vec-U(wev2vec Unsupervised)を開発しました.Wav2vec-Uは,wav2vec 2.0や音素変換モデルなどの既存のツールを利用して,敵対的な方法で音素系列生成器を学習させます.
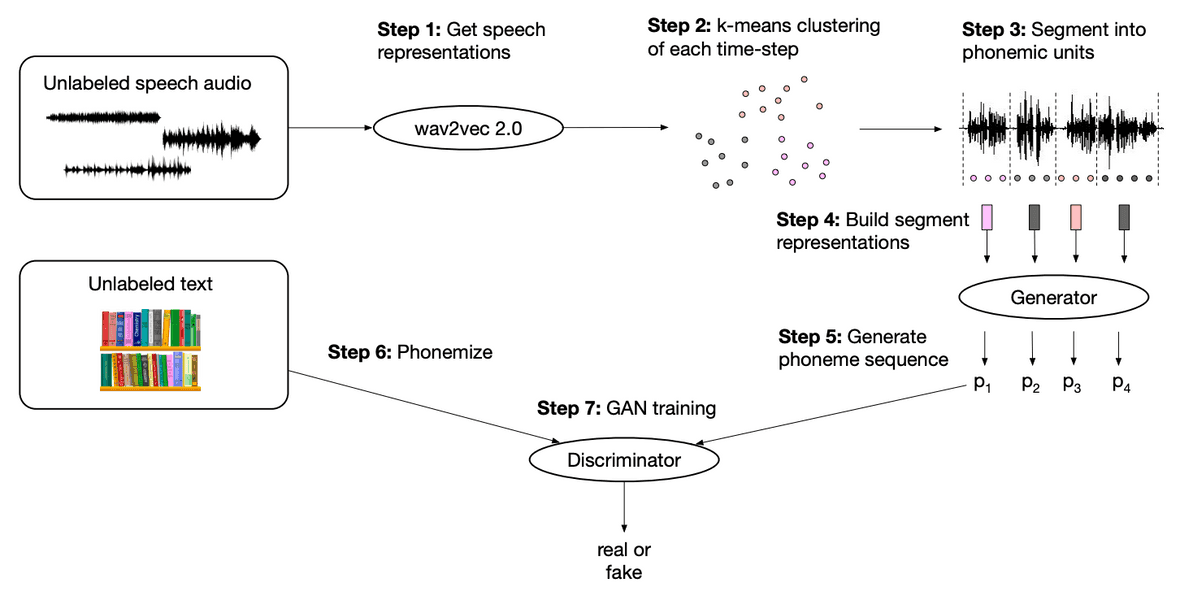
その仕組みは以下の通りです.
- wav2vec 2.0を使って音声表現を得る
- k平均法で表現内のクラスタ(音素単位)を特定する
- 音声データを音素単位に分割する
- wav2vec 2.0の表現を平均値プーリングしてセグメントごとの表現を構築する
- セグメントごとの表現を生成器に送り込み,音素系列を生成する
- ラベルなしテキストを音素に変換する(これが本物の音素系列)
- 生成された音素系列と本物の音素系列を識別器に入力する
その結果,wav2vec-Uは数千時間のデータで教師あり学習した従来のSOTA手法に近い音素誤り率(PER; phoneme error rate)を達成しました.また,キルギス語,スワヒリ語,タタール語などの低リソース言語に対する実験でも,その有効性が確認されました.
Alias-Free Generative Adversarial Networks
- 著者: Tero Karras, Miika Aittala, Samuli Laine, Erik Härkönen, Janne Hellsten, Jaakko Lehtinen, Timo Aila
- URL: https://arxiv.org/abs/2106.12423
- 公開: 2021年6月
- 採録: NeurIPS 2021
Alias-Free GAN [Karras+, 2021]
— Shion Honda (@shion_honda) September 20, 2021
従来のStyleGANは髪などのテクスチャが画像の座標に依存するが,その原因は生成過程でのエイリアシングだった.生成器を流れる値を連続信号として扱い,LPFを再現する構造を導入することで並進・回転に同変なGANを実現した.https://t.co/hOZ6lyQT0f#NowReading pic.twitter.com/TozuP2wNUr
StyleGANs [9,10] の進化はまだ終わっていません.Tero KarrasのチームはStyleGAN3を発表し,画像の絶対座標にいくつかの細部の特徴が貼り付いてしまう現象を引き起こす,望ましくないエイリアシング効果を解決しました.この公式ビデオを見てください.StyleGAN2 のパネルでは,頭を動かしても,髪の毛とひげが画面に貼り付いています.
この問題を検証した結果,根本的な原因は生成器がテクスチャを生成する際に,位置情報(エイリアシングによるアーチファクトから推測される)を濫用していることだと判明しました.エイリアシングを防ぐために,著者らはすべての信号を連続信号として扱い,生成器全体をサブピクセルレベルで並進同変にするために,アーキテクチャにいくつかの変更を加えました.
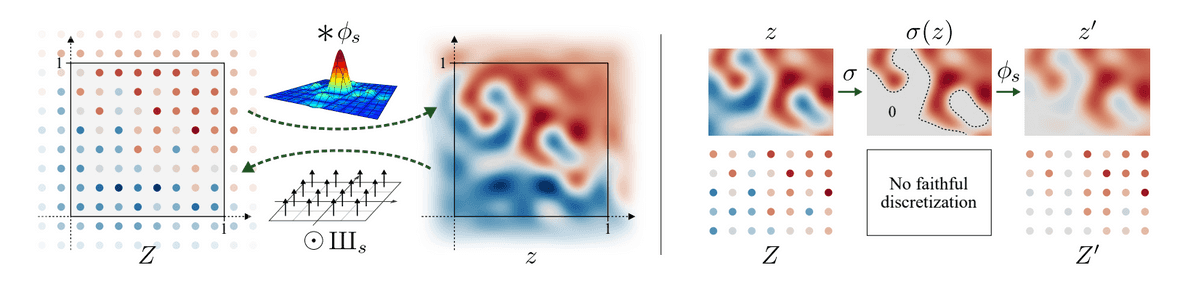
これにより,StyleGAN3はFFHQ-Uのような整列されていない画像データセットで学習できるようになりました.また,この生成器は表面のテクスチャを合成するために特徴マップの中に独自の座標系を作り出すということも発見されています.

プロジェクトページには他にも動画があります.
Deep Reinforcement Learning at the Edge of the Statistical Precipice
- Rishabh Agarwal, Max Schwarzer, Pablo Samuel Castro, Aaron Courville, Marc G. Bellemare
- URL: https://arxiv.org/abs/2108.13264
- 公開: 2021年8月
- 採録: NeurIPS 2021
Deep RL at the Edge of Statistical Precipice [Agarwal+, 2021, NeurIPS]
— Shion Honda (@shion_honda) December 29, 2021
DRLの性能評価で習慣とされる数回の試行に基づく点推定は不確実性を無視している.3つの対策を提案:
- ブートストラップによる区間推定
- スコアの分布を示す
- 集約統計量にはIQMを使うhttps://t.co/NJZPmfGNOT#NowReading pic.twitter.com/3shOzNtesy
強化学習の分野では,一連のタスクをまたいだスコアの平均値や中央値などの要約統計量の点推定値によってアルゴリズムを評価します.しかし実際には,これは統計的な不確実性を無視しており,報告されたスコアは不当に「幸運な」ものであることが多いという問題がありました.
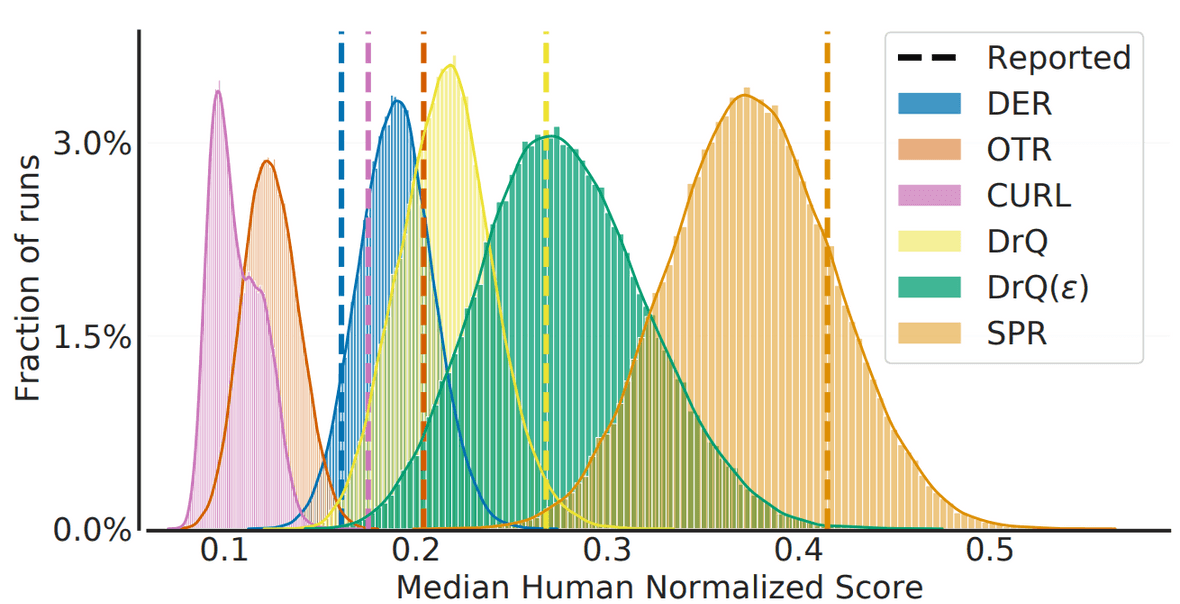
特に最近の強化学習タスクは計算量が多く(例:StarCraft [11]),何百回も繰り返すことができないため,この問題はより深刻になってきています.わずかな回数の実行で統計的不確実性に対処するために,著者らは信頼性の高い評価を実現するための3つの提言を行いました.
- ブートストラップ法によるスコアの区間推定を行い,その信頼区間を報告せよ
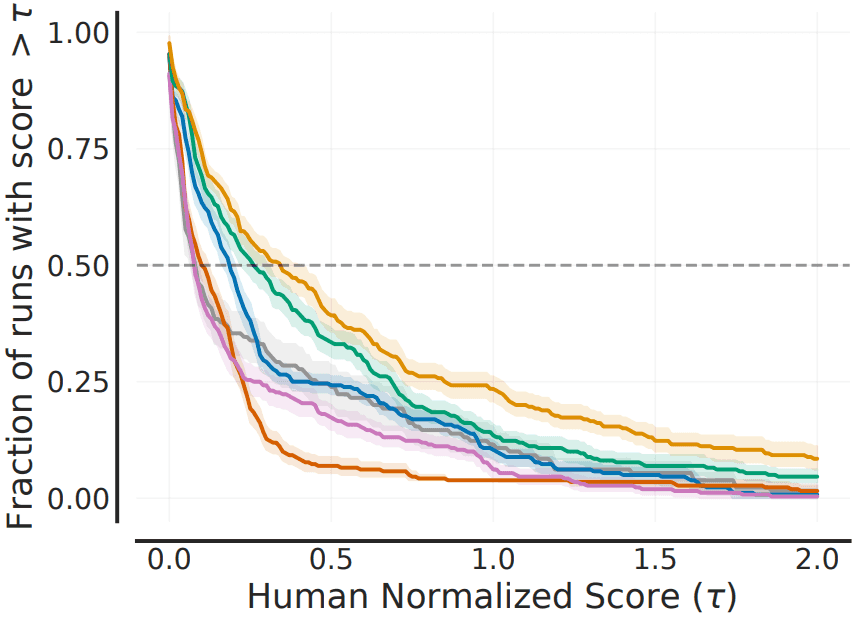
- 平均スコアの表ではなく,下図のような性能プロファイル(スコア分布)を提示せよ
- 要約スコアを出す際には四分位平均(IQM; interquartile mean)を使用せよ(IQMは外れ値に強く,中央値よりも信頼区間が小さい!)
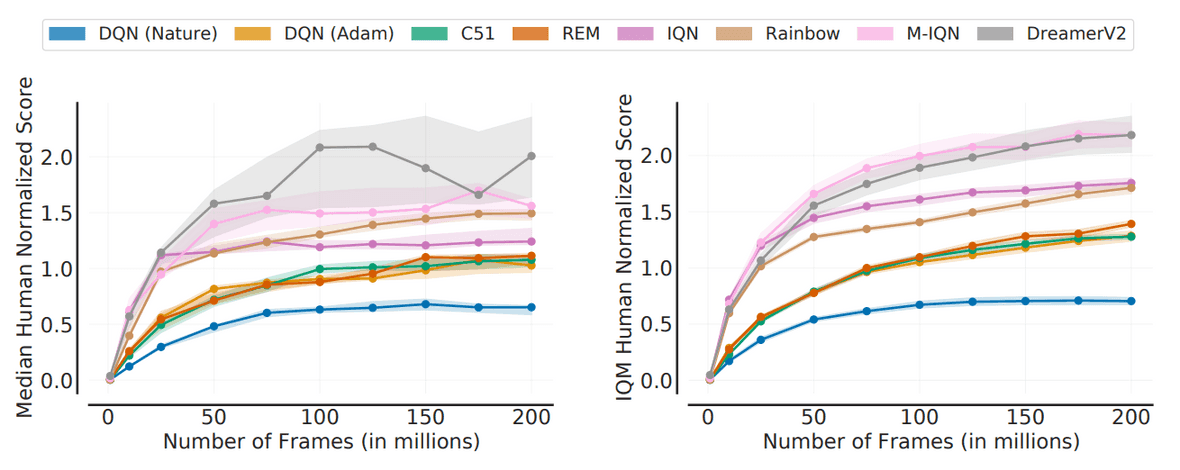
彼らの提言に従うと,どのアルゴリズムが優れているかがより明確にわかります.下図では,左のパネルが中央値,右のパネルがIQMで比較されています.IQMは,DreamerV2が必ずしもM-IQNより優れていないことを教えてくれます.
著者らはこの評価プロトコルをrliableというライブラリにまとめました.こちらからチェックしてみてください.
Fake It Till You Make It: Face analysis in the wild using synthetic data alone
- 著者: Erroll Wood, Tadas Baltrušaitis, Charlie Hewitt, Sebastian Dziadzio, Matthew Johnson, Virginia Estellers, Thomas J. Cashman, Jamie Shotton
- URL: https://arxiv.org/abs/2109.15102
- 公開: 2021年9月
- 採録: ICCV 2021
Fake It Till You Make It [Wood+, 2021, ICCV]
— Shion Honda (@shion_honda) October 19, 2021
顔のパーツ,肌,髪…と要素を組み合わせることで顔の写実的な3Dモデルを作成.合成されたラベル付き画像でResNetを学習した後,実データでラベル適応を行うことで,各種タスクでSOTAに匹敵する性能を達成した.https://t.co/7o95jYbFkj#NowReading pic.twitter.com/VPGWBW41CA
人間の顔を扱うコンピュータビジョンのタスクには人気があります.例えば,検出,個人の識別,3D再構成,画像生成,画像編集などのタスクがあります.しかし,実世界から高品質なデータを収集することにはさまざまな困難がつきまとうため,合成データを用いたアプローチに期待が寄せられています.合成データには,実データにはない3つの利点があります.
- プライバシーの心配がない
- 完璧なラベルが自動的に得られる(実データでは入手不可能なものや非常に高価なものもある)
- 多様性を制御できる
合成データにはもちろん欠点もあります.ドメインギャップの問題です.本論文では,Face Syntheticsという非常に精巧な合成データを作成することでこの問題を解決しました.Face Syntheticsは,下図のような3次元の顔テンプレートに順次パーツを追加していくことで,リアリティと表現力を同時に実現しました.

Face Syntheticsは,ランドマーク検出や顔のセグメンテーションなど,顔に関連するタスクに対するニューラルネットワークの訓練に実際に役立っています.このデータセットで事前学習し,下流タスクでファインチューニングしたResNetは,実データで学習したSOTAモデルと同等の性能を発揮しました.
Face Syntheticsは,ランドマークとセマンティックセグメンテーションのラベルが付与された512x512の解像度の顔画像を10万人分集めたデータセットです.非商用の研究用途に限り,こちらで利用可能です.その他の可視化については,プロジェクトページをご覧ください.

おわりに
「応用事例編」もぜひご覧ください.
また,個人ブログの方では,英語ですが
などの記事をほそぼそと書いています.ご興味のある方は,ぜひこちらも覗いてみてください.
2021年のAIの研究動向に関心のある方にはステート・オブ・AIガイドの素晴らしい年間レビューもおすすめです.
参考文献
[1] Jonathan Frankle, Michael Carbin. "A Simple Framework for Contrastive Learning of Visual Representations". ICML. 2020.
[2] Jean-Bastien Grill, Florian Strub, Florent Altché, Corentin Tallec, Pierre H. Richemond, Elena Buchatskaya, Carl Doersch, Bernardo Avila Pires, Zhaohan Daniel Guo, Mohammad Gheshlaghi Azar, Bilal Piot, Koray Kavukcuoglu, Rémi Munos, Michal Valko. "Bootstrap your own latent: A new approach to self-supervised Learning". NeurIPS. 2020.
[3] Mathilde Caron, Ishan Misra, Julien Mairal, Priya Goyal, Piotr Bojanowski, Armand Joulin. "Unsupervised Learning of Visual Features by Contrasting Cluster Assignments". NeurIPS. 2020.
[4] Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, Ilya Sutskever. "Language Models are Unsupervised Multitask Learners". 2019.
[5] Tom B. Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel Herbert-Voss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, Daniel M. Ziegler, Jeffrey Wu, Clemens Winter, Christopher Hesse, Mark Chen, Eric Sigler, Mateusz Litwin, Scott Gray, Benjamin Chess, Jack Clark, Christopher Berner, Sam McCandlish, Alec Radford, Ilya Sutskever, Dario Amodei. "Language Models are Few-Shot Learners". NeurIPS. 2020.
[6] Victor Garcia Satorras, Emiel Hoogeboom, Fabian B. Fuchs, Ingmar Posner, Max Welling. "E(n) Equivariant Normalizing Flows". NeurIPS. 2021.
[7] Aditya Ramesh, Mikhail Pavlov, Gabriel Goh, Scott Gray, Chelsea Voss, Alec Radford, Mark Chen, Ilya Sutskever. "Zero-Shot Text-to-Image Generation". 2021.
[8] Sheng Shen, Liunian Harold Li, Hao Tan, Mohit Bansal, Anna Rohrbach, Kai-Wei Chang, Zhewei Yao, Kurt Keutzer. "How Much Can CLIP Benefit Vision-and-Language Tasks?". 2021.
[9] Tero Karras, Samuli Laine, Timo Aila. "A Style-Based Generator Architecture for Generative Adversarial Networks". CVPR. 2019.
[10] Tero Karras, Samuli Laine, Miika Aittala, Janne Hellsten, Jaakko Lehtinen, Timo Aila. "Analyzing and Improving the Image Quality of StyleGAN". CVPR. 2020.
[11] Oriol Vinyals, Igor Babuschkin, Wojciech M. Czarnecki, Michaël Mathieu, Andrew Dudzik, Junyoung Chung, David H. Choi, Richard Powell, Timo Ewalds, Petko Georgiev, Junhyuk Oh, Dan Horgan, Manuel Kroiss, Ivo Danihelka, Aja Huang, Laurent Sifre, Trevor Cai, John P. Agapiou, Max Jaderberg, Alexander S. Vezhnevets, Rémi Leblond, Tobias Pohlen, Valentin Dalibard, David Budden, Yury Sulsky, James Molloy, Tom L. Paine, Caglar Gulcehre, Ziyu Wang, Tobias Pfaff, Yuhuai Wu, Roman Ring, Dani Yogatama, Dario Wünsch, Katrina McKinney, Oliver Smith, Tom Schaul, Timothy Lillicrap, Koray Kavukcuoglu, Demis Hassabis, Chris Apps, David Silver. "Grandmaster level in starcraft ii using multi-agent reinforcement learning". Nature. 2019.