はじめに
2020年も,機械学習コミュニティでは多くの新しい成果が見られました.2019年に引き続き,1年を振り返ってもっとも面白かった論文を10本紹介したいと思います.
* 本記事は,私のブログにて英語で書いた記事を翻訳し,適宜加筆修正したものです.
** 記事中の画像は,ことわりのない限り対象論文からの引用です.
論文10選(公開順)
普段から,読んだ論文を簡単にまとめてツイートしているので,それを使って公開日順に振り返っていきます.対象はおおまかに「2020年に公開された論文」と「2020年に学会・雑誌で発表されたもの」とします.全くの主観で選んでいるので,私の興味範囲である深層学習および応用研究に偏っている点はご容赦ください.
紹介するのはこちらの10本です!
- Rigging the Lottery: Making All Tickets Winners
- PIFuHD: Multi-Level Pixel-Aligned Implicit Function for High-Resolution 3D Human Digitization
- Jukebox: A Generative Model for Music
- Language Models are Few-Shot Learners
- Bootstrap Your Own Latent: A New Approach to Self-Supervised Learning
- Implicit Neural Representations with Periodic Activation Functions
- Graph Structure of Neural Networks
- Towards Faster and Stabilized GAN Training for High-fidelity Few-shot Image Synthesis
- An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
- Pre-training without Natural Images
Rigging the Lottery: Making All Tickets Winners
- 著者: Utku Evci, Trevor Gale, Jacob Menick, Pablo Samuel Castro, Erich Elsen
- URL: https://arxiv.org/abs/1911.11134
- 公開: November 2019
- 採録: ICML 2020
Rigging The Lottery [Evci+, 2020, ICML]
— Shion Honda (@shion_honda) December 26, 2020
パラメータ数を変えず、接続をつなぎ替えることで疎なNNを訓練する方法を提案した。刈り込みよりも良い解を見つけることができ、一定の計算コスト下で最高精度を達成できる。ResNet-50やMobileNetで有効性を確認。https://t.co/t7pBrX9GhI#NowReading pic.twitter.com/10CkMOXvcj
宝くじ仮説 (lottery ticket hypothesis)[1,2]は,ニューラルネットワークの訓練は宝くじのようなものだと主張しています.この仮説は[1]で
ランダムに初期化された密なフィードフォワードネットワークは,分離して訓練すると同程度の学習ステップ数で元のネットワークに匹敵するテスト精度に達するサブネットワーク(「当たりくじ」)を含んでいる(拙訳)
と説明されており,そのためにネットワークの刈り込み (pruning)が可能だとされています.では,学習は当たりくじを引くために常に大規模なネットワークから始め,当選発表(訓練と検証)後にハズレくじ(不必要なサブネットワーク)を刈り込むべきなのでしょうか?本論文は,その必要はないと答えています.著者らは,訓練中はモデルサイズを固定した状態で,接続(重み)の削除・生成を反復的に行うことで,スパースなニューラルネットワークを訓練する方法を紹介しています.提案された訓練方法は,「宝くじで不正をする (rig the lottery)」ことから,RigLと名付けられています.RigLのアルゴリズムは以下の図にまとめられています.
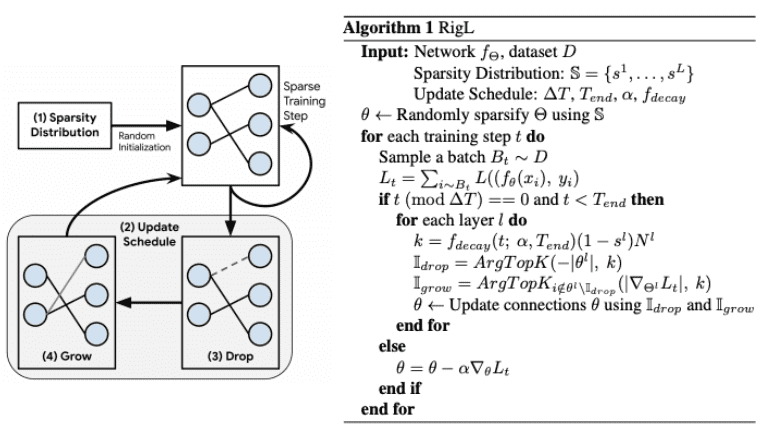
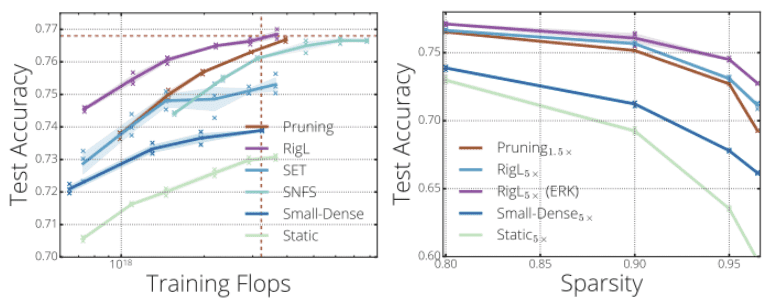
RigLは,様々なネットワークやデータセット(ImageNetにおけるResNet-50/MobileNet,WikiText-103におけるGRUなど)において,刈り込みよりも少ないFLOPとパラメータ数で,より高い精度を達成します.
PIFuHD: Multi-Level Pixel-Aligned Implicit Function for High-Resolution 3D Human Digitization
- 著者: Shunsuke Saito, Tomas Simon, Jason Saragih, Hanbyul Joo
- URL: https://arxiv.org/abs/2004.00452
- 公開: April 2020
- 採録: CVPR 2020
PIFuHD [Saito+, 2020, CVPR]
— Shion Honda (@shion_honda) August 25, 2020
人の全身画像から陰関数表現で3次元復元を行うPIFuを、HD画像でより高精度な推定ができるように改良した。入力には推定した正面と背後の法線マップを追加し、メモリ効率改善のためネットワークは2種類の解像度を扱う階層構造をとる。https://t.co/1ZpQDewR7r#NowReading pic.twitter.com/qdwDVtdv8y
PIFuHDは,1枚の画像から人体の3次元形状を復元するディープラーニング手法であるPIFu (Pixel-aligned Implicit Function) [4]のアップデート版です.この論文を選んだのは,純粋に楽しいからです.驚くべき結果が得られるだけでなく(下の画像を参照),著者がColabのデモを提供しているため,自分の画像ですぐに試すことができます.

多くの人がこのデモを試し,その結果を#pifuhdにアップロードしています.私のお気に入りは,サカナクションの曲に合わせてG7のリーダーたちが踊っている動画です.
もしG7の方々に 新宝島 を踊らせたら #サカナクション #新宝島 #pifuhd pic.twitter.com/TTn75rwlqw
— もうせ (@motulo) June 30, 2020
技術的な詳細については,著者によるプレゼンテーション動画がおすすめです.
Jukebox: A Generative Model for Music
- 著者: Prafulla Dhariwal, Heewoo Jun, Christine Payne, Jong Wook Kim, Alec Radford, Ilya Sutskever
- URL: https://arxiv.org/abs/2005.00341
- 公開: May 2020
Jukebox [Dhariwal+, 2020]
— Shion Honda (@shion_honda) May 1, 2020
DilatedConvの階層VQ-VAEとSparse Transformerの事前分布により、多様なジャンルの音楽の数分間に渡る波形を直接生成することに成功した。歌手や歌詞で条件付けることもでき、自然に発声される。数十億パラメータの複数のモデルを120万曲で訓練。https://t.co/eTeCg2bOnv pic.twitter.com/uGKxIpBWJd
リアルな画像を生成することはもはや驚くべきことではありませんが,リアルな音楽を生成することは,その非常に長い依存関係のために依然として難しい課題です.具体的には,CD品質(44kHz)の4分間の曲には,高度に抽象的な情報(c.f.,イントロ,Aメロ,サビ)を持つ1000万個以上のタイムスタンプが含まれています.OpenAIは勇敢にも,生の音声波形を様々なジャンルで生成することに取り組み,本論文で提案されているJukeboxは,実際に印象的な音楽を生み出すことに成功しました.
こちらに,チェリーピックされていない7,131個のサンプルがあります.これらは特定のジャンルやアーティストで条件付けられており,中には歌詞でも条件付けられているものがあります.例えば,このサンプルはStevie Wonderの「I Just Call To Say I Love You」の続きです.10秒後からは新しい曲のように聞こえますが,歌い手と曲のスタイルを維持できています.
この魔法の裏側には何があるのでしょうか?VQ-VAE-2 [5]に触発されて,著者らは階層的なVQ-VAEを使って長距離の依存関係を処理しています.事前分布(生成器)については,64×64サイズの画像と生の音声波形の生成に成功した効率的なTransformerであるSparse Transformer [6]を使用しています.
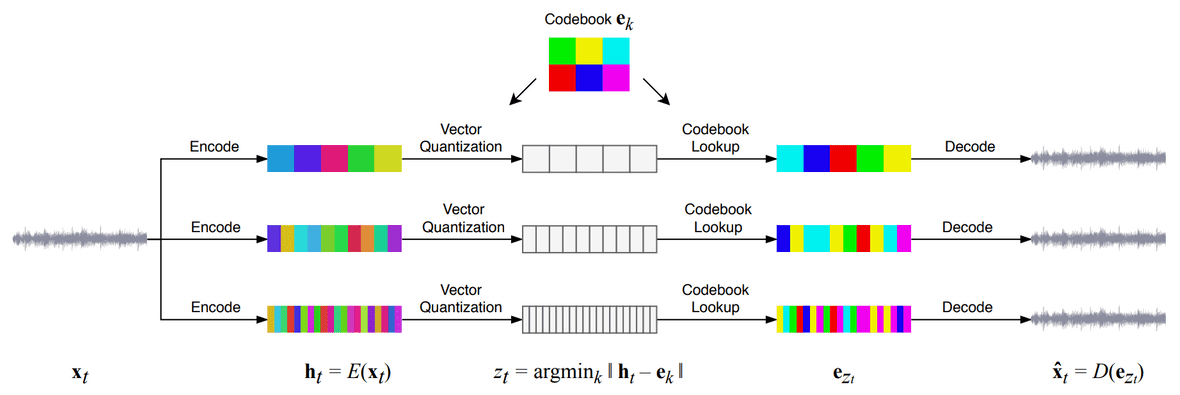
オフィシャルブログより引用.
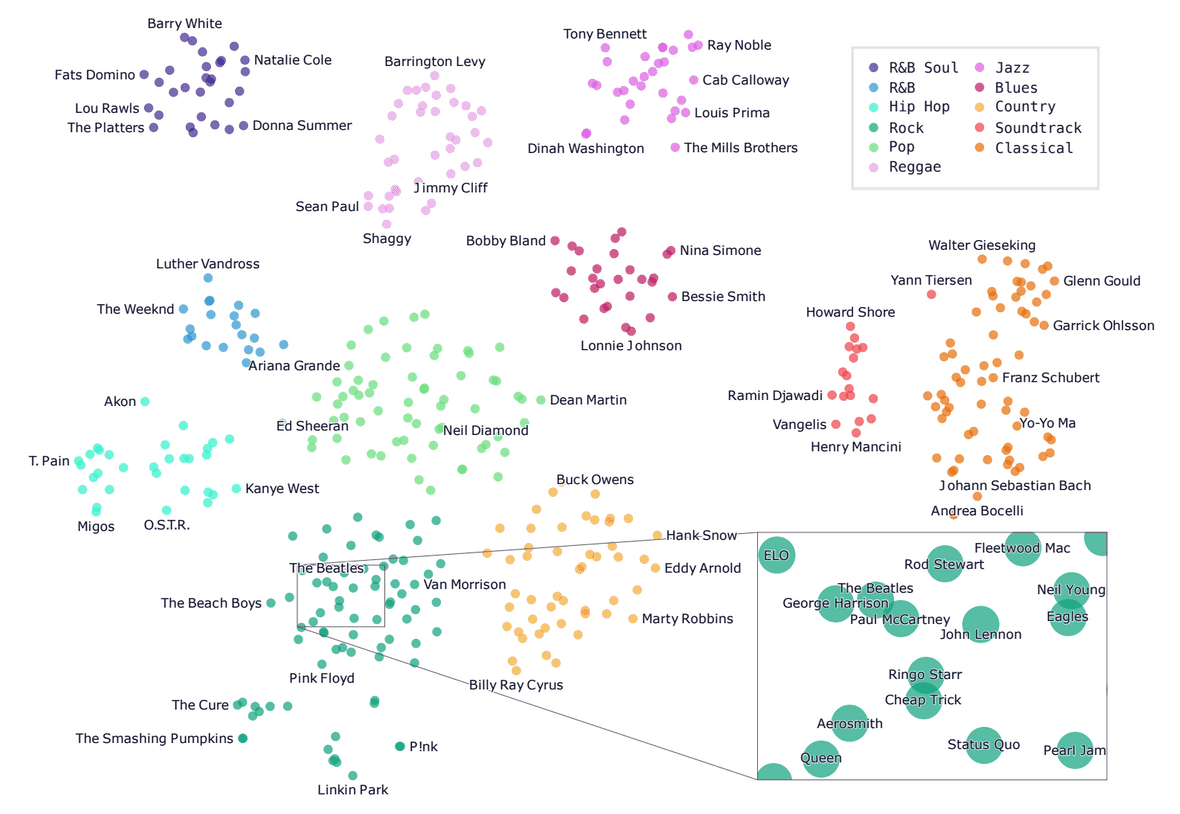
論文の付録も読み応えがあります.下の図は,Jukeboxで学習した(アーティスト,ジャンル)の埋め込みのt-SNEプロットです.ELOがThe Beatlesに似ているというのは納得できます😉.
Language Models are Few-Shot Learners
- 著者: Tom B. Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel Herbert-Voss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, Daniel M. Ziegler, Jeffrey Wu, Clemens Winter, Christopher Hesse, Mark Chen, Eric Sigler, Mateusz Litwin, Scott Gray, Benjamin Chess, Jack Clark, Christopher Berner, Sam McCandlish, Alec Radford, Ilya Sutskever, Dario Amodei
- URL: https://arxiv.org/abs/2005.14165
- 公開: May 2020
- 採録: NeurIPS 2020 (Best Paper)
LMs are Few-Shot Learners [Brown+, 2020]
— Shion Honda (@shion_honda) August 4, 2020
GPT-2を1750億パラメータに拡張したGPT-3を3000億トークンで事前学習させた。fine-tuningをせずに入力文にタスクの説明や具体例を入れるin-context学習という方法で、翻訳から四則演算まで様々なタスクに汎化できる。https://t.co/Qriqd9Thiq#NowReading pic.twitter.com/eRnlQbq5UT
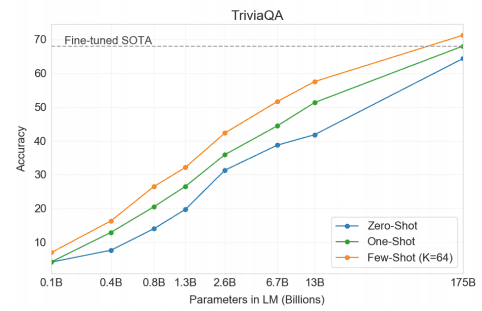
GPT[6,7]の最新バージョンであるGPT-3は,1750億ものパラメータ(Turing-NLGの10倍!)を持ち,3000億トークンからなるデータで訓練される事前学習済み言語モデルです.著者らは,GPTをスケールアップすることで,fine-tuningなしのfew-shot learningの性能が大幅に向上することを発見し,これをin-context learningと呼んでいます.次の図は,in-context learningと従来のfine-tuningを比較したものです.
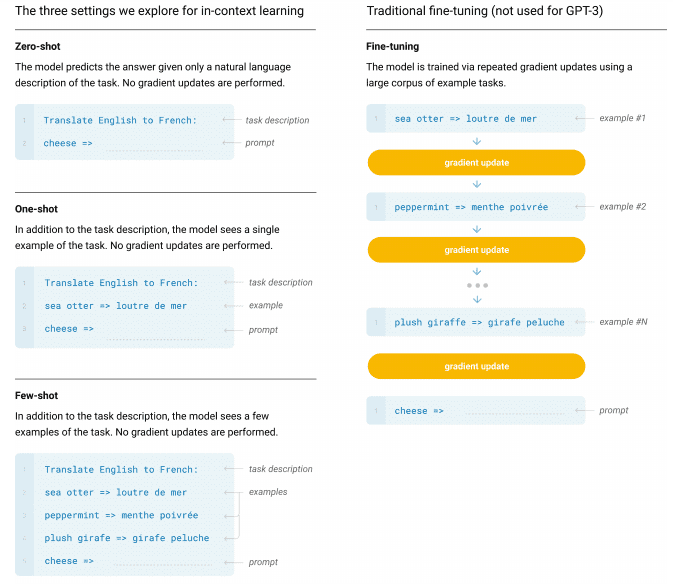
一言でいうと,彼らのin-contextなfew-shot learningでは,モデルはタスクの説明文といくつかの具体例およびプロンプトを含む入力を推論時に初めて見て,その場で答えを予測します.追加の訓練やfine-tuningはありません.GPT-3は,翻訳,テキスト生成,要約,質問応答,さらには算術など,さまざまなタスクに対応することができます.場合によっては,fine-tuningされた従来モデルを上回ることもあります.
さらに驚くべきことに,GPT-3は英語をJSXコードに翻訳することができると報告されています.量的変化が質的変化に転移する,とはこのことですね.
This is mind blowing.
— Sharif Shameem (@sharifshameem) July 13, 2020
With GPT-3, I built a layout generator where you just describe any layout you want, and it generates the JSX code for you.
W H A T pic.twitter.com/w8JkrZO4lk
OpenAIでは,学習済み重みの代わりにGPT-3モデルをAPIとして公開しています.利用したい方は,ベータ版のwaitlistに参加してください.
Bootstrap Your Own Latent: A New Approach to Self-Supervised Learning
- 著者: Jean-Bastien Grill, Florian Strub, Florent Altché, Corentin Tallec, Pierre H. Richemond, Elena Buchatskaya, Carl Doersch, Bernardo Avila Pires, Zhaohan Daniel Guo, Mohammad Gheshlaghi Azar, Bilal Piot, Koray Kavukcuoglu, Rémi Munos, Michal Valko
- URL: https://arxiv.org/abs/2006.07733
- 公開: June 2020
- 採録: NeurIPS 2020
Bootstrap Your Own Latent [Grill+, 2020]
— Shion Honda (@shion_honda) June 24, 2020
onlineとその重みのEMAをとったtargetの2つのネットワークを用意。異なる拡張を施した画像をそれぞれに入力し、targetの出力をonlineに予測させるという自己教師学習BYOLを提案。負例を使わず様々なタスクでSOTA。https://t.co/oYduYPifKw#NowReading pic.twitter.com/StHxVCo97f
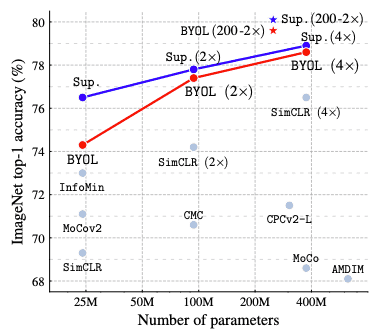
負例からの情報を活用する自己教師学習アルゴリズムの一種である対照学習は,2020年で最もホットな研究トピックの1つでした.MoCo,SimCLR,InfoMinなど多くの手法がImageNetの精度を競いました[8-10].これらの手法は,同じ画像の異なるデータ拡張結果の表現間の距離が小さく,異なる画像間の距離が大きくなるべきだという前提に基づいています.
これに対して,提案されているBootstrap Your Own Latent (BYOL)は,負のペアを全く使用せずにすべての対照学習手法の性能を上回り,自己教師学習と教師あり学習のギャップを埋めました.
下の図に示すように,BYOLは,オンラインネットワーク($\theta$)とターゲットネットワーク($\xi$)の2つのネットワークを使用しており,ターゲットネットワークは,単にオンラインネットワークの指数移動平均です.
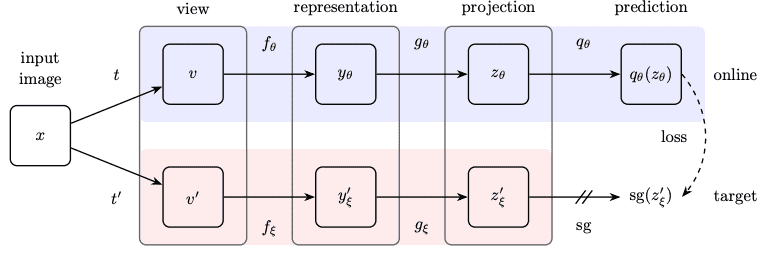
入力画像$x$は,2つの異なるデータ拡張 ($t$と$t'$)によって$v$と$v'$に変換され,オンラインネットワークとターゲットネットワークにそれぞれ供給される.BYOLは,オンラインネットワークによる予測($q_{\theta}(z_{\theta})$) とターゲットネットワークによる出力($\mathrm{sg}(z'_{\xi})$)の間のL2距離を最小化するように訓練されます(ここで,$\mathrm{sg}$ は勾配の停止を意味します).これが,BYOLが潜在変数のブートストラップを行う方法です.
BYOLのもう一つの利点は,対照学習のベースラインと比較して,バッチサイズの選択やデータ拡張の選び方に対して頑健なことです.また,論文の中では,学習テクニックについての議論もあります.興味のある方は,ぜひチェックしてみてください.
Implicit Neural Representations with Periodic Activation Functions
- 著者: Vincent Sitzmann, Julien N. P. Martel, Alexander W. Bergman, David B. Lindell, Gordon Wetzstein
- URL: https://arxiv.org/abs/2006.09661
- 公開: June 2020
- 採録: NeurIPS 2020
Sinusoidal Representation Networks [Sitzmann+, 2020]
— Shion Honda (@shion_honda) September 22, 2020
陰的表現の獲得に向けて活性化関数に正弦関数を用いたSIRENを提案。高次の微分情報を失わないため、ReLUなどの従来手法よりも画像や音声などの自然信号を学習するのに適していることを実験的に確認した。https://t.co/dggPCbvHlH#NowReading pic.twitter.com/YPJUm2wFwP
科学における様々な問題は,implicit neural representations (INR)に帰着します.例えば,INRは,画像,音声信号,3次元形状をモデル化することができ,また境界値問題を解くことができます.しかし,一般的なReLU-MLPネットワークは,ReLUの2階微分がいたるところゼロであることから,信号やその微分の細かい部分をうまく表現することができません.tanhやsoftplusのような他の活性化関数は高階微分を表現することができますが,それらもまた,細かい部分を表現することができません.
そこで著者らは,周期的で$n$回微分可能な活性化関数としてsinを利用したニューラルネットワークを提案しました(sinusoidal representation networksの頭文字をとってSIREN).sin関数の利点は,下図によく現れています.これは目的の画像にフィットさせたINRを比較したもので,他の活性化とは異なり,SIRENはでGaussianとLaplacianも含めて学習できていることがわかります.

SIRENのこの特性は,3D形状をモデリングする際に特に有効なようです.

このような一見単純な解決策がこれまでに登場しなかったのはなぜなのか,疑問に思う方もいるかも知れません.周期的な活性化関数は10年以上前から研究されていたそうですが,本論文が2020年においても新しいものであることには2つの要因があると思います.第一に,INRに周期的な活性化関数を適用する方法はあまり研究されていなかったことです.第二に,SIRENは初期化にちょっとしたテクニックをを必要とすることです.ネットワークを通して活性値の分布を維持するために,SIRENの初期の重みは慎重に設計された一様分布からサンプルしなければなりません.
プロジェクトページに音声,微分方程式,プレゼンテーションビデオなどのサンプルがあります.
Graph Structure of Neural Networks
- 著者: Jiaxuan You, Jure Leskovec, Kaiming He, Saining Xie
- URL: https://arxiv.org/abs/2007.06559
- 公開: July 2020
- 採録: ICML 2020
Graph Structure of NNs [You+, 2020, ICML]
— Shion Honda (@shion_honda) August 10, 2020
MLPやCNNを「関係グラフ」で表現すると、その性能はグラフのクラスタ係数と平均経路長で特徴づけることができ、複数タスクに共通して性能が高いNN構造を与える領域を発見した。その構造はマカクの神経回路に類似する。https://t.co/2tAzwdeGTK#NowReading pic.twitter.com/4mvkifJe52
この刺激的な研究は,グラフMLの研究者とコンピュータビジョンの研究者の共同研究によって行われました.
予測性能の高いニューラルネットワークには何か共通点があるのでしょうか?この疑問に答えるために,本論文ではグラフ理論の観点からニューラルネットワークを分析します.まず,著者らは,関係グラフ (relational graph) (a,b)と呼ばれるニューラルネットワークの新しい表現方法を定義します.次に,関係グラフの空間を体系的に探索するためのグラフ生成器を設計します.この関係グラフにより,ニューラルネットワークは平均経路長とクラスタ係数という2つのグラフ統計量で特徴づけられるようになります(c).最後に,生成されたニューラルネットワークの予測性能と,対応する関係グラフのグラフ統計量との関係についての分析を行います(d).
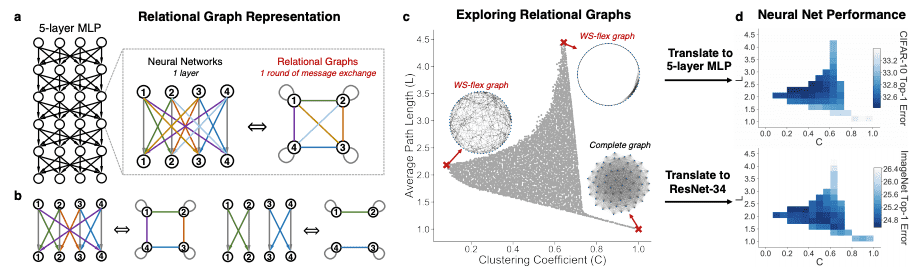
主な発見には次のようなものがあります.
- 関係グラフの空間には,予測性能を有意に向上させるスイートスポットが存在する.
- ニューラルネットワークの予測性能は,その関係グラフのクラスタリング係数と平均パス長のなめらかな関数で近似できる.
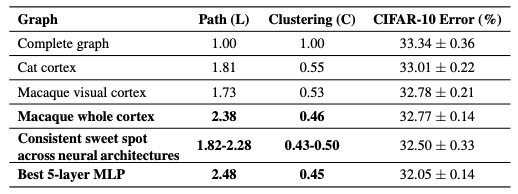
- 最も性能がよいニューラルネットワークのグラフ統計量はマカクザルと類似している.
Towards Faster and Stabilized GAN Training for High-fidelity Few-shot Image Synthesis
- 著者: Bingchen Liu, Yizhe Zhu, Kunpeng Song, Ahmed Elgammal
- URL: https://arxiv.org/abs/2101.04775
- 公開: September 2020
- 採録: ICLR 2021
Faster GAN Training for Few-shot Image Synthesis [Anonymous, 2020]
— Shion Honda (@shion_honda) November 26, 2020
skip-layer excitationとautoencoder型の識別器を採用することで、100枚程度のデータ・GPU1枚・数時間の訓練で高解像度の画像生成に成功した。StyleGANのような特徴のdisentangleも可能。https://t.co/nFxOtFq9bU#NowReading pic.twitter.com/KupguLBgku
StyleGAN2は素晴らしい研究成果ですが,一方で膨大なデータと計算量を必要とするという問題があります[11].実際,FFHQの1024×1024サイズの顔画像を生成するための学習に,StyleGAN2は8台のTesla V100 GPUと7万枚の画像を使用し,全学習に9日間を要しました.これは,研究を再現したい小規模な研究室や企業にとってはほとんど実現不可能なことです.また,この制約はGANの実応用の可能性を狭めています.
この限界は明らかであり,StyleGAN2の発表から6ヶ月後に,同じ著者らはStyleGAN2-ADA(StyleGAN2 with adaptive discriminator augmentation)[12]を発表しました.これにより,StyleGAN2は数千枚の訓練画像で元と同等の品質の画像を生成できるようになりました.
本論文の著者らは,さらに先を行きました.この論文では,skip-layer excitationモジュールとオートエンコーダー型の識別器を採用し,1台のRTX-2080 GPUと数百枚の画像で数時間訓練するだけでFFHQの画像を生成する方法(通称Lightweight GAN)を提案しています.

そして幸いなことに,Phil Wang氏がGitHubでLightweight GANの美しく使いやすい実装を公開しました.そのおかげで,Colaboratoryや任意のGPUを使って好きな画像を生成できるようになりました.「GANの民主化」ですね!
私も実際に,200枚の寿司の画像を使ってLightweight GANを訓練してみました.訓練後は,以下のようにかなりリアルな寿司画像が生成されました.生成された画像は「This Sushi Does Not Exist」でも見ることができます.あなたはどんなGANを作りたいですか?

詳しくは,元論文や前回の記事を参照してください.
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
- 著者: Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, Neil Houlsby
- URL: https://arxiv.org/abs/2010.11929
- 公開: October 2020
- 採録: ICLR 2021
An Image is Worth 16x16 Words [Dosovitskiy+, 2020]
— Shion Honda (@shion_honda) January 2, 2021
パッチに分割した画像の埋め込みを入力に取るVision Transformer(632Mパラメータ)は、ImageNetより大きなJFT-300Mで事前学習させると汎化した。CNNベースのBiTよりも少ない訓練時間で画像分類のSOTA達成。https://t.co/5OpJf4z188#NowReading pic.twitter.com/e7QBEkPVLb
昨年は,Transformerを画像タスクに適用する試みが多く見られました.Cordonnierらは,self-attentionと畳み込み層の等価性について研究しました[13].Chenらは,GPTを用いて自己回帰的に画像を生成しました[14].Carionらは,Transformerを物体検出に応用しました[15].このような研究を踏まえると,Transformerベースの事前学習モデルで画像分類をすることは自然な流れと言えるでしょう.
上記のような研究に触発されて,Google ResearchのチームがVision Transformer (ViT)を訓練し,Big Transfer (BiT)やNoisy StudentなどのCNNのベースラインを超えて新記録を達成しました."A picture is worth a thousand words"(百聞は一見にしかず)ということで,下の図でViTの概要を見てみましょう.
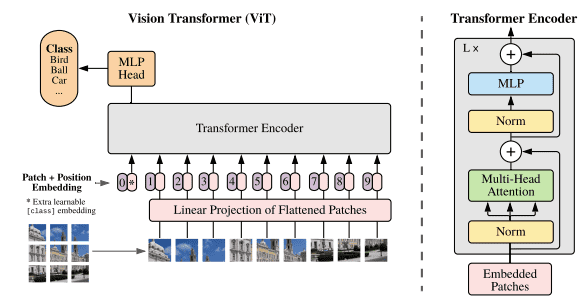
タイトルが暗示している通り,画像は16x16サイズの小さなパッチに分割され,通常のTransformerでトークンが埋め込まれてエンコーダーに渡されるのと同じように,位置エンコーディングとともにネットワークに入力されます.モデル全体は,分類の損失が最小になるように訓練されます(したがって,教師あり学習です).
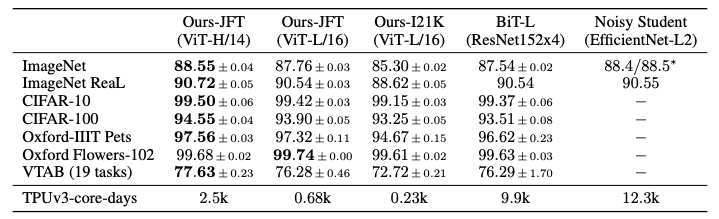
著者らの報告によると,ViTは帰納バイアスが小さいため,「中規模」のImageNetで学習した場合には汎化がうまくいきませんが,300倍大きいJFT-300Mというデータセットで学習した場合にはCNNのベースラインを性能で上回ります.それにもかかわらず,ViTはBiTやNoisy Studentよりも大幅に短い計算時間で訓練できます.
巨大なTransformerを用いた画像分類で教師あり事前学習が有効であることがわかったので,今年は半教師バージョンが登場するのではないでしょうか.
Pre-training without Natural Images
- 著者: Hirokatsu Kataoka, Kazushige Okayasu, Asato Matsumoto, Eisuke Yamagata, Ryosuke Yamada, Nakamasa Inoue, Akio Nakamura, Yutaka Satoh
- URL: https://openaccess.thecvf.com/content/ACCV2020/html/Kataoka_Pre-training_without_Natural_Images_ACCV_2020_paper.html
- 公開: November 2020
- 採録: ACCV 2020
Pre-training without Natural Images [Kataoka+, 2020, ACCV]
— Shion Honda (@shion_honda) December 30, 2020
アルゴリズムに従って自動生成できるフラクタル画像のデータセットであるFractalDB-1k/10kを作成し、ImageNetと同様の事前学習を行った。ダウンロード不要で倫理や権利関係の問題を回避できる。https://t.co/sxz9A0IozI#NowReading pic.twitter.com/m9HnFQ3n3W
これまでの研究で,大規模なデータセットを用いた事前学習が精度向上の鍵であることが明らかにされてきました.しかし,このようなデータセットでは,ラベルの間違い,著作権の侵害,プライバシーの侵害,非倫理的なバイアスなどの問題が発生することがしばしばあります.そこで,本論文では,人工画像を用いた事前学習が可能であることを示しました.
具体的には,著者らはあるアルゴリズムでFractal Database(FractalDB)を用意し,それを用いてResNet-50の事前学習を行いました.
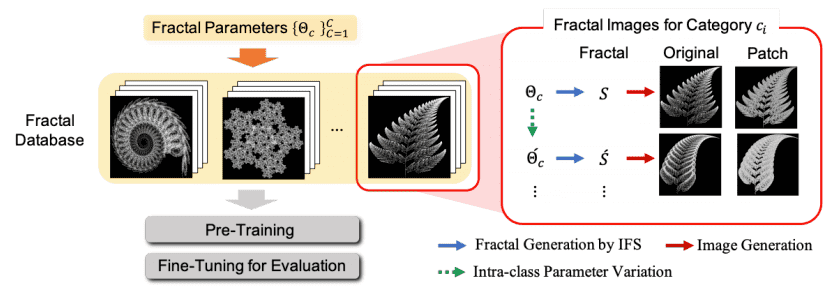
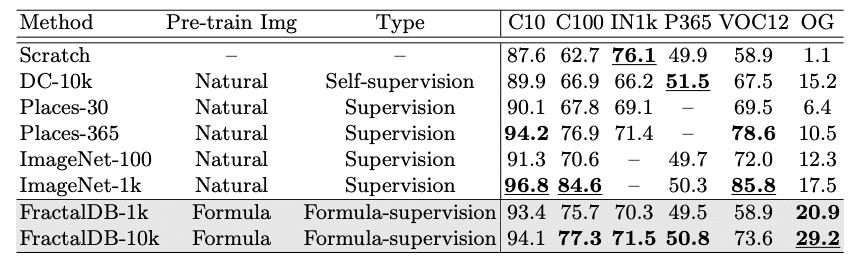
FractalDBを用いて事前学習したモデルは,ImageNet-1kを用いて事前学習したモデルを上回ることはできなかったものの,有望な結果が得られました.上に挙げたような問題点を考慮すると,FractalDBはこれからの事前学習におけるひとつの選択肢になるでしょう.
なお,本研究は,個人的にも関わりのある日本の有志研究グループであるcvpaper.challengeから生まれたものであり,所属組織に依らない新しい研究のあり方を提示している点も興味深いです.
おわりに
ここには載せきれませんでしたが,他にも面白い論文が多々ありました.おすすめの論文がありましたら,気軽にコメントをいただければ幸いです.
また,現行ブログの方では,英語ですが
などの記事をほそぼそと書いています.ご興味のある方は,ぜひこちらも覗いてみてください.
参考文献
[1] Jonathan Frankle, Michael Carbin. "The Lottery Ticket Hypothesis: Finding Sparse, Trainable Neural Networks". ICLR. 2019.
[2] Madison May. "Comparing Rewinding and Fine-tuning in Neural Network Pruning". ICLR. 2020.
[3] Shunsuke Saito, Zeng Huang, Ryota Natsume, Shigeo Morishima, Angjoo Kanazawa, Hao Li. "PIFu: Pixel-Aligned Implicit Function for High-Resolution Clothed Human Digitization". ICCV. 2019.
[4] Ali Razavi, Aaron van den Oord, Oriol Vinyals. "Generating Diverse High-Fidelity Images with VQ-VAE-2". NeurIPS. 2019.
[5] Rewon Child, Scott Gray, Alec Radford, Ilya Sutskever. "Generating Long Sequences with Sparse Transformers". 2019.
[6] Alec Radford, Karthik Narasimhan, Tim Salimans, Ilya Sutskever. "Improving Language Understanding by Generative Pre-Training". 2018.
[7] Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, Ilya Sutskever. "Language Models are Unsupervised Multitask Learners". 2019.
[8] Kaiming He, Haoqi Fan, Yuxin Wu, Saining Xie, Ross Girshick. "Momentum Contrast for Unsupervised Visual Representation Learning". CVPR. 2020.
[9] Ting Chen, Simon Kornblith, Mohammad Norouzi, Geoffrey Hinton. "A Simple Framework for Contrastive Learning of Visual Representations". ICML. 2020.
[10] Yonglong Tian, Chen Sun, Ben Poole, Dilip Krishnan, Cordelia Schmid, Phillip Isola. "What Makes for Good Views for Contrastive Learning?". NeurIPS. 2020.
[11] Tero Karras, Samuli Laine, Miika Aittala, Janne Hellsten, Jaakko Lehtinen, Timo Aila. "Analyzing and Improving the Image Quality of StyleGAN". CVPR. 2020.
[12] Tero Karras, Miika Aittala, Janne Hellsten, Samuli Laine, Jaakko Lehtinen, Timo Aila. "Training Generative Adversarial Networks with Limited Data". NeurIPS. 2020.
[13] Jean-Baptiste Cordonnier, Andreas Loukas, Martin Jaggi. "On the Relationship between Self-Attention and Convolutional Layers". ICLR. 2020.
[14] Mark Chen, Alec Radford, Rewon Child, Jeff Wu, Heewoo Jun, Prafulla Dhariwal, David Luan,
Ilya Sutskever. "Generative Pretraining from Pixels". ICML 2020.
[15] Alexander Kolesnikov, Lucas Beyer, Xiaohua Zhai, Joan Puigcerver, Jessica Yung, Sylvain Gelly, Neil Houlsby. "Big Transfer (BiT): General Visual Representation Learning". ECCV. 2020.
[16] Qizhe Xie, Minh-Thang Luong, Eduard Hovy, Quoc V. Le. "Self-training with Noisy Student improves ImageNet classification". CVPR. 2020.
[17] Nicolas Carion, Francisco Massa, Gabriel Synnaeve, Nicolas Usunier, Alexander Kirillov, Sergey Zagoruyko. "End-to-End Object Detection with Transformers".ECCV. 2020.