今回は、実例があまり出てこない食品画像を攻略してみたいと思います。(といっても、精度100%は出ていません(^^;)

(右端「Padim + YOLOv5」が提案手法)
食品画像の難しさ
食品画像の検査は、工業製品と違って難しいと言われています。個人的には
- 見た目に多様性がある
- 位置が決まっていない
が理由だと思っております。
見た目の多様性は、例えばミカンでいうと、色やサイズ、形が様々で、一つとして同じものはありません。つまり、正常品の範囲が広く、正常/異常の境界線があいまいになりがちです。一方、工業製品は多様性が少なく、正常品の範囲が狭いです。このため、正常/異常の境界線がはっきりしています。
二点目、「位置が決まっていない」は、食品という特性上、位置が多少ズレることがあります。さらに、2つの食品があったとして、2つの位置が入れ替わったとしても正常となることがあります。つまり、位置ベースの異常検知手法が使えなくなります(Padimとか)。
データセット
今回は新しいデータセットであるLOCOを使います。
LOCOの詳細はこちらの記事に書かれている通り、「構造的な異常」と「論
理的な異常」が含まれるデータセットです。そして、ターゲットとなるのは"breakfast_box"です。

ベースライン
本稿で使う異常検知手法は、特に明記がない限り全てマハラノビスAD法を使います。
まずは、マハラノビスAD法でポン!をしてみます。
実験条件と結果は以下。
| backbone | level | 解像度 | ROAUC↑ | 正常品誤判定率@recall1.0↓ | |
|---|---|---|---|---|---|
| baseline | tf_efficientnetv2_xl_in21k | 8 | 700x700 | 0.891 | 0.931 |
ROAUCは異常検知の論文で頻出するAUCです。このスコアが大きいほど強い手法といえます。
正常品誤判定率@recall1.0
一方、正常品誤判定率@recall1.0は製造業でよくあるケースを想定しています。日本の製造業では(多分、食品業界でも)、外観検査した後に異常品を含んでいることは許されず、閾値は厳しめに設定されています。このとき、正常品を誤判定(過検知)するわけですが、この誤判定率は低くなければ使い物になりません。
そして、この誤判定率こそ、正常品誤判定率@recall1.0であり、定義としては以下です。
「異常品を100%弾く(recall1.0)くらいの厳しい閾値にしたときの、正常品の誤判定率」
もちろん、このスコアは小さいほど良いものです。論文ではROAUCが重宝されますが、個人的に、日本の製造業では、正常品誤判定率@recall1.0が重要な数値と考えています。上記の表の誤判定率0.931という数値は、正常品が100個あったとしたら、93個が誤判定されるという意味です。
データをよく見る
ベースラインではディープでポン!を行ってみました。
ROAUCが0.95に到達していないので、あまり良い異常検知器とは言えません。
そこで、Kaggleで教わった流儀で、データをよく見てみます。
Kaggleに限らず、異常検知においてもデータをよく見るのは大事です。
正常品は以下。

正常品の特徴として
- それぞれの食品の外観が多様
- ミカンとスモモの位置が入れ替わることがある
が挙げられます。続いて、異常品。

異常品の特徴として
- 小さい異常(傷など)もあれば、大きい異常(シリアルが入っていないなど)もある
- シリアルの量が多すぎるなど、量的な異常がある
があります。一点目(異常の大小)について、一般論では、大きい異常は全体画像で検査すれば容易に検出できますが、小さい異常は全体画像だけでは検出できず、拡大する必要があります。そこで、各食品を切り出して、画像を拡大する方法があります。これにより、小さい異常も必然的に大きくなり、目立つようになります。
二点目(量的な異常)は全体画像の検査(ディープでポン!)でも検出できそうです。ただ、ここでも各食品を拡大することにより、量が敏感に分かるような画像となるため、前述した各食品の画像拡大が有効そうです。
解法
本稿の解法は以下です。

- 全体画像で異常スコアAを出す
- 各食品をYOLOv5で切り出し、各食品の異常スコアBを出す
- 異常スコアAとBをマージ(加算)し、総合スコアを出す
異常スコアのマージ方法
この解法はシンプルですが、異常スコアのマージ(加算)方法が結構やっかいです。ここで、計算例を書いてみます。例えば、正常品が「ミカン2個の画像」と定義します。そして、正常品の異常スコアAとBが共に1だったとして、普通に足すと
- 正常品(ミカン2個 )の総合スコア
= 異常スコアA+異常スコアB1+異常スコアB2
= 1+1+1 = 3 - 異常品(ミカン1個 )の総合スコア
= 異常スコアA+異常スコアB1
= 2+1 = 3
で、総合スコアが同じになってしまいました。このからくりは、異常品において、本来加算するはずだったミカンの異常スコアB2(=1)がないことです。結果的に、異常品では、ミカンが欠落しているため、全体画像のスコア(異常スコアA)が2と大きくなっています(good!)が、ミカンの個数が少ないため、総合スコアが同じになってしまったパターンです。このように、異常スコアを普通に加算すると、欠品している画像の総合スコアが低くなりがちになります。
そこで、本稿では、マージ方法で良く使われる標準化を使います。標準化は、平均値で引いて標準偏差で割る((score - average) / std)操作です。上記の例で、単純化のために異常スコアAとBの平均値が1、標準偏差が1だったとして、各スコアを標準化し加算します。
- 正常品(ミカン2個 )の総合スコア
= 異常スコアA+異常スコアB1+異常スコアB2
= (1-1)/1+(1-1)/1+(1-1)/1 = 0 - 異常品(ミカン1個 )の総合スコア
= 異常スコアA+異常スコアB1
= (2-1)/1+(1-1)/1 = 1
計算式がやや煩雑ですが、結果的に異常品の総合スコアが大きくなりました(good!)。この操作は、雑な言い方をすると「正常品の異常スコアをいくら足しても総合的には0になり、異常品の異常スコアは顕著に大きな数値となる」です。
先にネタバレですが、"breakfast box"で異常スコアを単純に加算すると、ディープでポン!よりもスコアが悪化します。一方、この標準化を使うことで、ディープでポン!よりもスコアが改善します。
可視化
可視化の説明は分かりにくいです。そのため、読み飛ばしていただいた結構です。
異常部分の可視化には、Padimを使用しました。PadimはマハラノビスAD法とほぼ同じ手法ですが、空間情報を残しているため、ピクセル単位の異常検知が可能となります。直感的な説明は以下のとおりです。
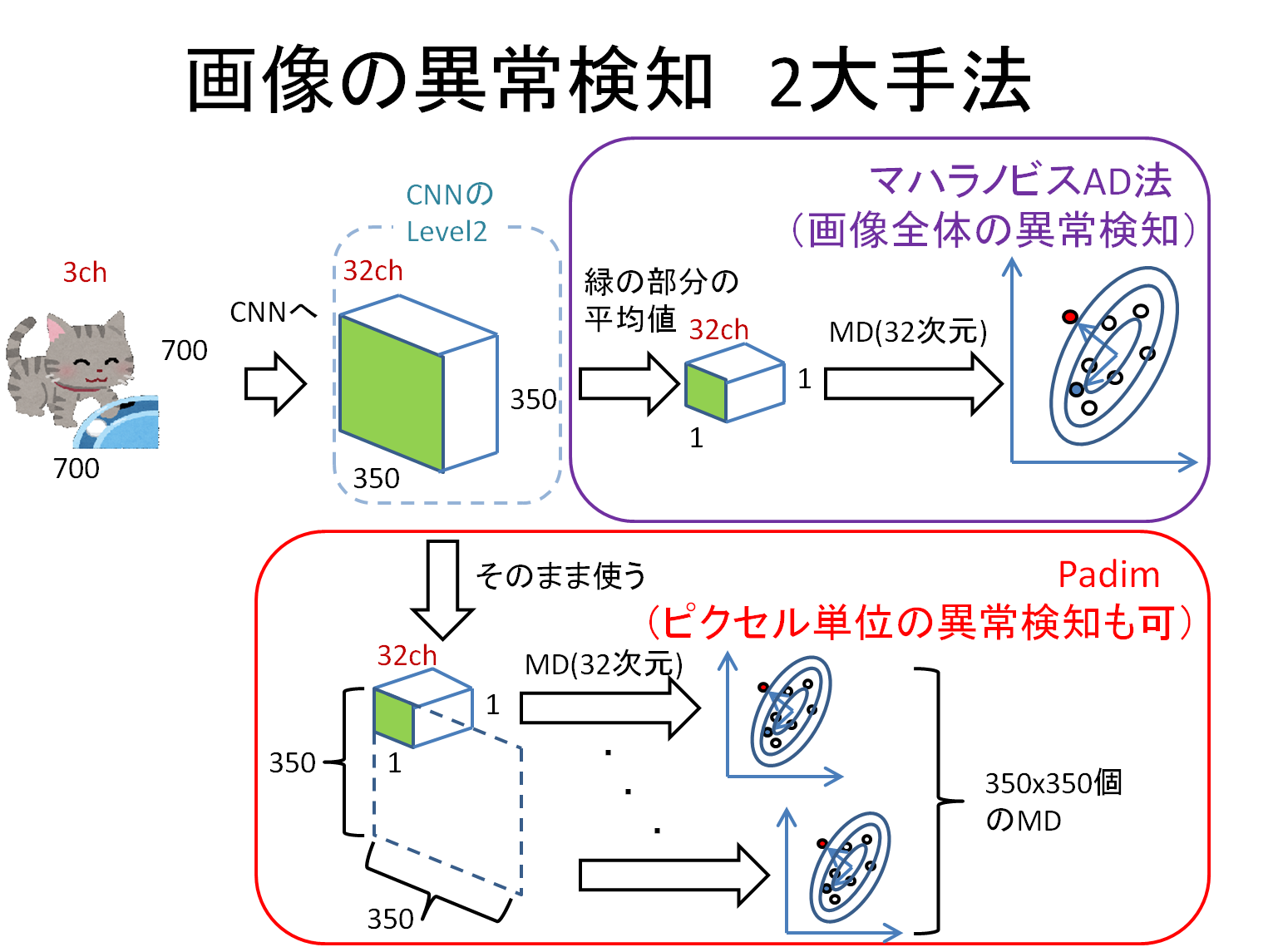
冒頭で述べた通り、Padimは位置ベースの異常検知手法です。そのため、ミカンとスモモが入れ替わる"breakfast_box"は大の苦手です。そこで、ここでも、異常マップをマージして改善を図ります。比較対象(ベースライン)として、全体画像に適用したPadimを後ほど掲載します。
異常マップのマージ方法は、以下のとおりです。
- 全体画像にPadimを適用し、異常マップ$M$(ベースラインと等しい)を取得します。
- YOLOv5で各物体を切り出し、切り出した画像にもPadimを適用して異常マップ$m$を取得します。
- ただし、切り出す座標$p_{left},p_{right},p_{top},p_{bottom} $を取得しておきます。
- さらに、切り出した画像にマハラノビスAD法を適用し、前述した標準化を適用した異常スコアB($s_b$)を取得しておきます。
- 最後に、$M$の$p_{left},p_{right},p_{top},p_{bottom} $に$m$と$s_b$を加算します。
疑似コードで書くと、こんな感じ。
# M :画像全体の異常マップ(ベースラインに等しい),shape(700,700)
# m :切り出した画像の異常マップ,例えば shape(100,50)
# p_left, p_right, p_top, p_bottom, s_bはスカラー
M[p_top:p_bottom, p_left:p_right] = M[p_top:p_bottom, p_left:p_right] + m + s_b
最後に異常スコアB($s_b$)を足すのが重要なところで、これが無いとあまり改善しません。この意図は、たとえ異常部位を的確に抽出できなくても、異常部位を含んでいる物体(bounding box)の異常度が高くなり、視認性が改善されるところにあります。前述した通り、$s_b$は正常品では、ほとんど0に張り付いています。ところが、異常品の$s_b$は顕著に大きな値なので、異常部位を含むbounding boxの異常度が高くなる仕組みです。
結果
YOLOv5
物体検出はYOLOv5を使いました。train_dataでアノテーションを行い、テストデータに適用したところ、recallは100%近い印象です。以下の画像はテストデータの画像です。


スコア
マージで使う平均値と標準偏差は、validationデータを用いて算出しました。validationデータは、正常品であるものの、学習データとして使っていないデータを指します(LOCOでは、validationデータが別に用意されています)。実験条件と結果は以下。
| Backbone | Level | 解像度 | ROAUC↑ | 正常品誤判定率@recall1.0↓ | |
|---|---|---|---|---|---|
| ミカン | tf_efficientnet_b5 | 6 | 400x400 | ||
| スモモ | 〃 | 7 | 500x500 | ||
| シリアル | 〃 | 5 | 300x300 | ||
| バナナチップ | 〃 | 6 | 600x600 | ||
| Baseline | tf_efficientnetv2_xl_in21k | 8 | 700x700 | 0.891 | 0.931 |
| Score merge | 0.924 | 0.833 |
異常スコアB(ミカン、スモモ・・・)は各Backboneによって出しました。また、異常スコアAはBaselineの異常スコアを使用しました。
結果的に、score mergeによって、ベースラインの誤判定率を10%改善しました。各食品をYOLOで切り出し、異常部位を拡大する狙いは成功したようです。最終的な誤判定率が0.833なので、正常品の10個に8個は誤判定されます。しかし、2/10個は正確な判定ができるすので、工場の状況によっては、これを導入するところもあるのではないでしょうか。
可視化
以下は、全て異常品の可視化結果です。












災い転じて・・・
ここまで見てきて、「YOLOv5」や「可視化」の結果に疑問を持った方がいるかもしれません。なぜなら、以下の可視化は矛盾があるからです。
これらの画像はYOLOv5を使うことで、視認性が改善されています。つまり、YOLOv5で異物を物体(ミカン、スモモ、シリアル、バナナチップ)として誤検出してことを示しています。そして、YOLOv5の検出は以下。

確かに、ピンポン玉とミカンの皮はミカンとして、鍵はバナナチップとして検出されています。これにより、この画像は、ロジック的に画像単位の異常度も上がりますし、異常マップにおける異常部位の異常度も上がり、精度が改善されます。普段は嬉しくない、YOLOv5の誤検出ですが、今回は「災い転じて福となす」の効果があったようです。
まとめ
今回は、実例があまり出てこない食品画像で異常検知を行ってみました。
分かったことは以下です。
- 食品画像はやっぱり難しい
- 特に、多様性を吸収するのが難しい
- ただ、工夫すれば精度を改善でき、実用に耐えうる精度を出せる気がする
- 本稿で使った技術は食品だけではなく、工業製品でも精度改善に寄与できる
- 今回はマハラノビスAD法を使ったが、PatchCoreやfastflowに変えることでスコア改善が期待できる
実は、まだまだ改善のアイデアがありますが、冗長になるので、ここまでとさせていただきます。