この記事は Retty Advent Calendar 2017 24日目です.
昨日は@udoooom さんの 「カワイイはつくれる」 でした.
Rettyのサーバサイドエンジニア兼魚料理担当のnakagawa(@shinyorke)ともうします.
好きな魚料理は「青魚の南蛮漬け」1,趣味は野球のデータ分析です.2
気がつけばRetty Advent Calendar 2017三回目の登場です,今日もPythonのハナシで吟じます,よろしくお願いします![]()
テーマ「Pythonでのバックエンド開発」
一言で言うと, Pythonでバックエンド(バッチ処理)をオールインワンで作った時のノウハウとなります.
- 他社様のサービスとデータ連携する基盤をPython + Docker + AWS ECSで作った&運用している(今年から)
- Pythonライブラリ(Jupyter notebook, requests, pandas)を駆使してプロトタイピング
- バックエンドのタスク管理(Pipeline)をLuigiで作成
- 大きめ(数GB)のファイル(csv)をpandasで処理
- API呼び出しはScrapy
OSSライブラリ・フレームワークの組み合わせの一例として参考になれば幸いです.
あらすじ〜Rettyにおける予約導線について
RettyのWebサイトやアプリのお店詳細画面・まとめページには,提携させて頂いている他社サービスの情報を元に,
- 予約ボタン
- クーポン
- 予約に関する情報(コースや空席など)
を表示しています.
これらの予約に関する導線(予約導線)はユーザーさんにとって素敵な食の体験ができるよう,いち早く新しい情報を届ける(かつ,予約出来ない・行きたいお店が満席だった等の「負」を無くす)役割を果たしています.
これらの情報は提携サービスからの配信情報があるので,
- 提携しているサービスの情報を取得
- 更新した情報をRettyのレストラン情報などとマッピング
といったオペレーションを1日複数回行うためのバックエンドを作ろう!という企画が上がり,今シーズン中に構築・運用をはじめようという事になりました.
開発は10月スタートで,年内(2017)稼働が目標でした.
最初にやったこと「プロトタイピングと開発スコープの明確化」
提携先サービスを使った予約導線構築・改善プロジェクトが始動してからやったのは,
- プロトタイピング
- 開発スコープの明確化
でした.
Jupyter + requests + pandasでプロトタイピング
プロトタイピングは,
- Jupyter notebookでお試しコード記述&動作確認
- requestsでREST APIを呼び出し,挙動やデータ型の確認
- Retty本体とのマージを想定したデータセット(おためし版)をpandasで作る
といった手法を取りました.
具体的なノウハウ・例は以下のエントリーにまとめているのでご興味ある方はぜひご覧ください.
Webなエンジニアのための「Pythonデータラングリング」入門
※Retty Advent Calendar 20174日目のネタです
開発スコープの明確化は「Design Doc」
プランナーや他のエンジニアと,都度確認するようなこと(仕様調整やスケジュール管理)はSlackやGithub ISSUEで行いましたが,これらの「フロー型情報」では,
- なぜこのプロジェクトをやるのか
- 全体的な目標やKGI/KPI
- インフラや使用するアーキテクチャのコア情報
といった,流れちゃいけない&コロコロ変わっては困るような「ストック型情報」が残らない・流れるといった不幸が起きてしまうので,Design DocをQiita Teamに記述&共有,こちらをベースに合意形成をとりました.
特にインフラやアーキテクチャは作り始めてからちゃぶ台が返ると悲惨なことになるので,絵図(と言ってもホワイトボードの写真ですが)を交えてしっかり作って合意をいただきました.
また,バックエンド開発が私一人で,進捗がブラックボックスになる懸念もあったので,
- 朝会で具体的なTask・ゴールを宣言
- 動いているモノを見せる.具体的にはLuigiの画面スクショ(Pipelineの進行状況がわかるエビデンス)をSlackで共有したり,処理状況をSlack botで流したりetc...
他チーム連携および,「ちゃんと進んでるね」「もうすぐできそう」的な安心感(&ヤバイ時のアラートを即上げる)を担保するよう,心がけたつもりです.
全体像
作ったものの全体像です.
インフラとPipelineをベースに解説します.
インフラ(含む提携サービス)
複数の提携サービスに対して,一つのバッチアプリケーション(Docker上で運用,ECSを利用)で捌く構成にしました.
図
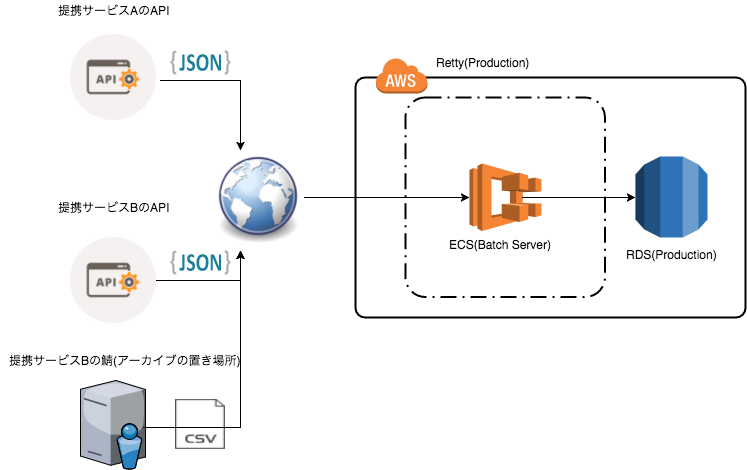
構成と提携サービスの情報(ざっくり)
構成はざっくりこんな感じです
- インフラはAWS ECS
- Dockerでアプリケーションを構築,ベースのイメージはPython 3.6の公式イメージ
- ライブラリ管理はpip, pip-toolsでベースのライブラリとバージョン管理3
- バッチアプリからDB(RDS)を操作する際は,SQLAlchemy(SQL操作ライブラリ)4, pymysql(MySQLコネクタ)を活用5
- バッチはLuigi, API呼び出しはScrapy, データの処理でpandas(後述)
なお,提携サービスは
- APIはすべてREST,戻り値はJSON
- 一部データがアーカイブ(zip)で配布, 2つの大きいcsvファイル(数GB)で構成
このcsvファイルが結構強敵でした.
Pipeline
いきなりLuigiの話をする前に,実際出来上がったモノのPipelineを見てもらったほう早いかも,ということで披露します.
このエントリーでのPipelineは,
- データ取得→前処理・加工→保存→後処理
- それぞれのTaskをパイプで繋ぐもの
ぐらいで見てもらえると見やすいかもです.
なお,サービス名ややってることが見えそうな所はモザイクにしてます![]()
全体
最大で8つのworkerが同時に起動して並列処理をしています.
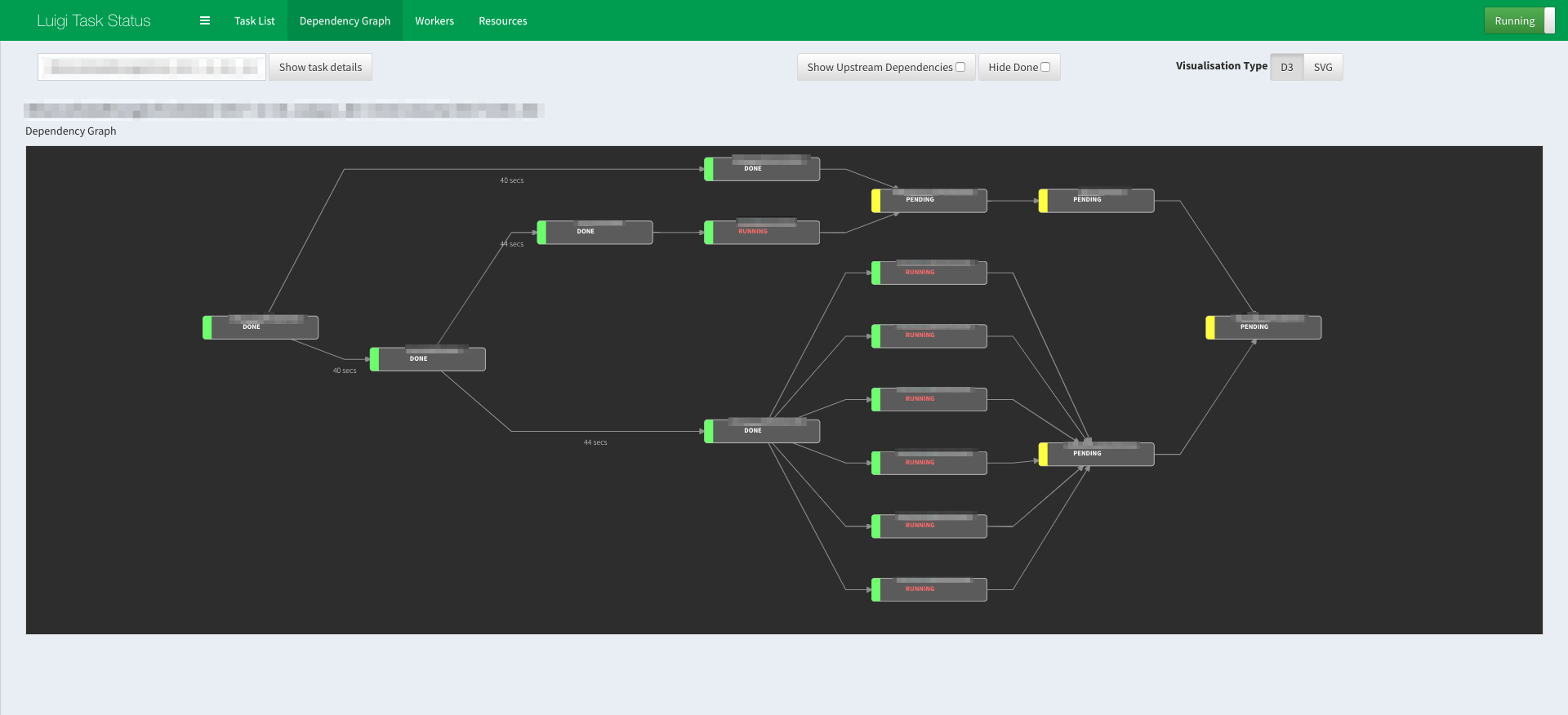
役割分担
複数の提携サービスのAPI・データを同時に処理した後,最後にMapping(後処理)を実施して終わらせています.
Python製バックエンドの勘どころ
お待たせしました,ここでようやっとPythonの登場です
Luigiによるバッチ構築
Luigi #とは
Luigiはひと言で言うと,
データフローを制御するためのFramework
で,Spotifyが開発, OSS化しています.
ちなみに名前の由来は,世界一有名な赤帽子の配管工さん...の双子の弟と,PyPIのドキュメントにもそっと記述されています.6
最近は機械学習プロジェクトにおけるデータパイプライン(前処理→学習→モデル作成→デプロイ,的な)で使われる機会が多いですが,Airflow7やRundeck同様,サービスのバックエンドとしても有効です.
特徴
- Pipelineの構築・保守はすべてPythonのコードで行う
- 処理単位(Task)はPythonで記述
- かなり軽量で,覚えたら気楽にサクッと作れる
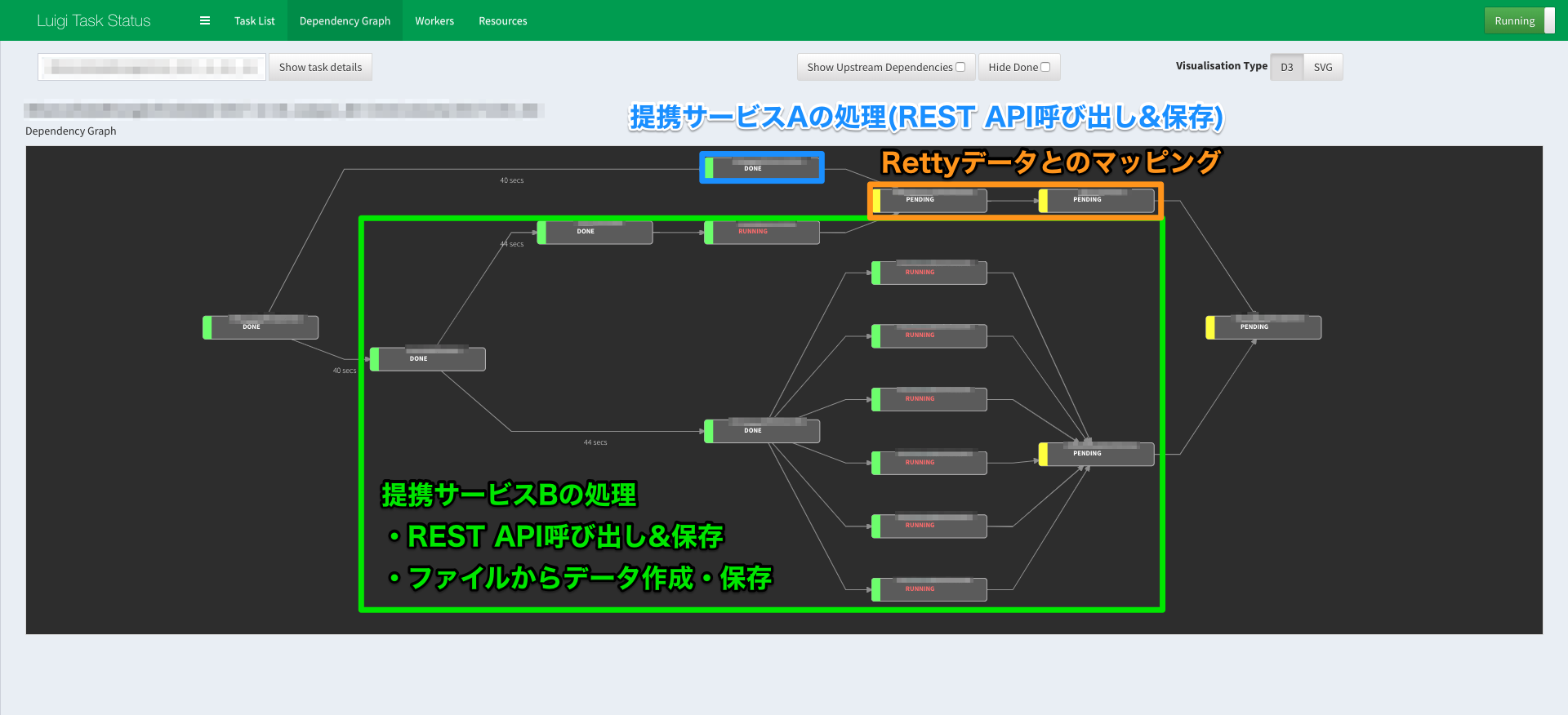
- 処理状況を監視するUI(割とかっこいい)が最初から用意されている ※Pipelineのスクショがそれ
実際の運用は
- supervisordでluigi daemonを立ち上げて運用
- 決まった時間にluigiコマンドでPipeline処理実行,なお処理のトリガーはcrontab8
- 各処理をTaskからkickする仕様にしている,Scrapyもデータ処理も
なお,Rettyではデータ集計の基盤などで以前からLuigiが使われており,他のメンバーに引き継いだりContributeを促す際もやりやすい,という利点もありました.9
使い方(雰囲気サンプル)
公式サイトに,SpotifyのTopアーティストをとるサンプルなどもありますが,めっちゃ単純なサンプルだとこんな感じです.
個人的には,ベースとなる処理を書いて継承した方が楽だったのでそんな書き方してます.
import os
import logging
from datetime import datetime as dt
import luigi
from luigi import Task
class LuigiSampleBaseTask(Task):
"""
親クラス(あってもなくてもいい)
"""
# 共通して使うパラメータを指定(今回は日付と出力先)
date = luigi.DateParameter()
output_dir = luigi.Parameter()
# 中で使うformat
OUTPUT_PATH_FROMAT = '{dir}/{filename}.txt'
TIMESTAMP_FORMAT = '%Y/%m/%d %H:%M:%S'
def process_start(self):
timestamp = dt.now().strftime(self.TIMESTAMP_FORMAT)
logging.info('Process Start:{}'.format(timestamp))
def process_done(self):
timestamp = dt.now().strftime(self.TIMESTAMP_FORMAT)
if not os.path.exists(self.output_dir):
os.makedirs(self.output_dir)
with open(self.OUTPUT_PATH_FROMAT.format(dir=self.output_dir, filename=self.__class__.__name__), 'w') as f:
f.write(timestamp)
def output(self):
# 処理が終わったらクラス名を使ってファイルを作る(ファイルの有無でタスク実行判断)
return luigi.LocalTarget(
self.OUTPUT_PATH_FROMAT.format(dir=self.output_dir, filename=self.__class__.__name__)
)
class Sample1stTask(LuigiSampleBaseTask):
"""
最初のTask
"""
def requires(self):
# 依存関係を書く,スタートなのでナシ
return None
def run(self):
self.process_start()
# TODO 一番目の処理
self.process_done()
class Sample2ndTask(LuigiSampleBaseTask):
"""
2番目のTask
"""
def requires(self):
# 依存関係を書く,1stが終わったら処理(以下同じ
return Sample1stTask(
date=self.date,
output_dir=self.output_dir,
)
def run(self):
self.process_start()
# TODO 二番目の処理
self.process_done()
class Sample3rdTaskA(LuigiSampleBaseTask):
"""
3番目のTask(その1)
"""
def requires(self):
return Sample2ndTask(
date=self.date,
output_dir=self.output_dir,
)
def run(self):
self.process_start()
# TODO 三番目の処理 ※Sample3rdTaskBと同時並行
self.process_done()
class Sample3rdTaskB(LuigiSampleBaseTask):
"""
3番目のTask(その2)
"""
def requires(self):
return Sample2ndTask(
date=self.date,
output_dir=self.output_dir,
)
def run(self):
self.process_start()
# TODO 三番目の処理 ※Sample3rdTaskAと同時並行
self.process_done()
class SampleLastTask(LuigiSampleBaseTask):
"""
4番目のTask(終了処理)
"""
def requires(self):
# 3番目のTask2つ(A, B)が終わったらやる(listで指定)
return [
Sample3rdTaskA(
date=self.date,
output_dir=self.output_dir,
),
Sample3rdTaskB(
date=self.date,
output_dir=self.output_dir,
),
]
def run(self):
self.process_start()
# TODO 三番目の処理 ※Sample3rdTaskAと同時並行
self.process_done()
if __name__ == '__main__':
luigi.run()
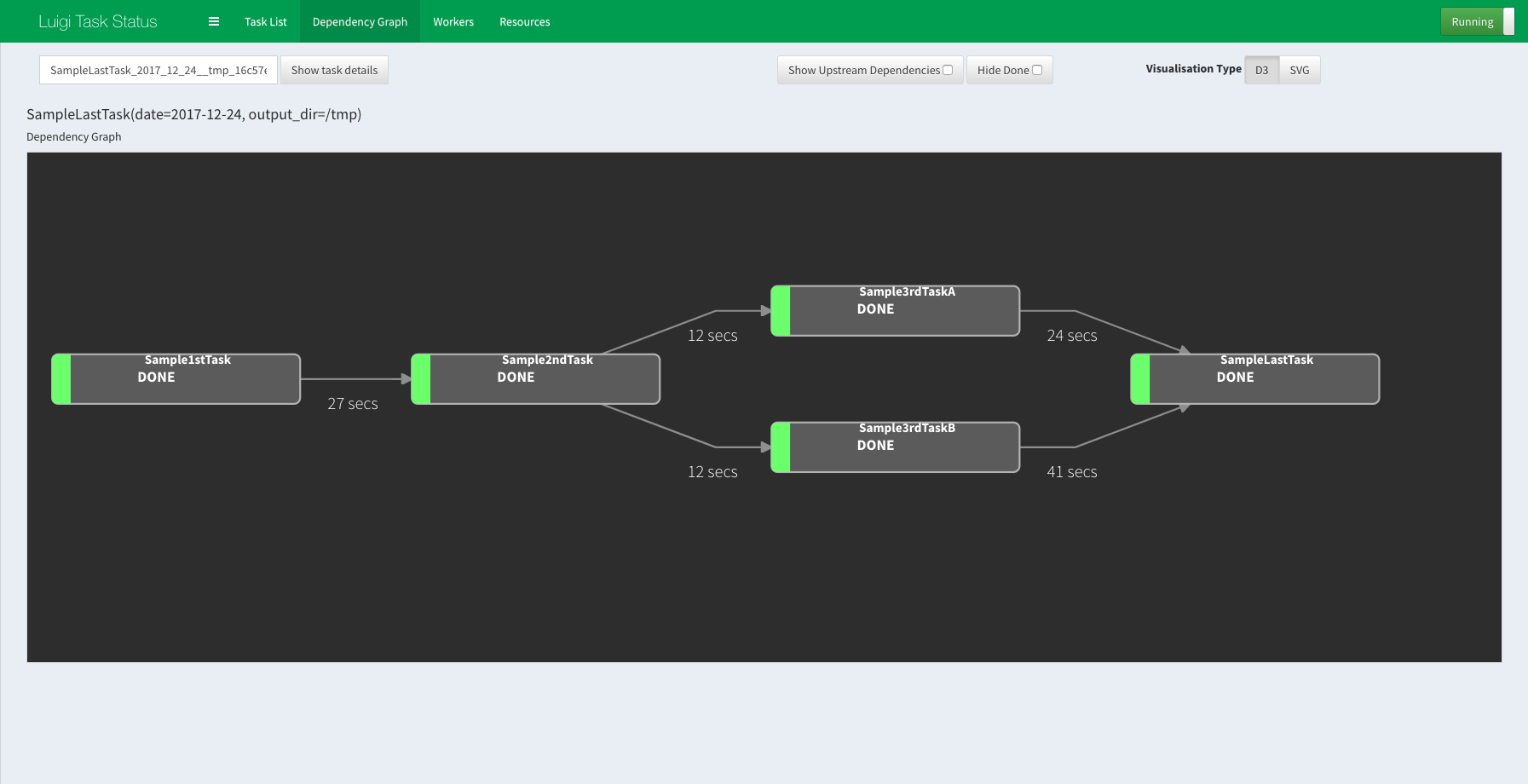
コマンドを叩いて実行すると,こんなワークフローになります,シンプルですね.
$ luigi --module tasks.luigi_sample SampleLastTask --workers 2 --date 2017-12-24 --output-dir /tmp
pandasで大きめのテキストファイルを処理する方法(サンプル)
一部データがアーカイブ(zip)で配布, 2つの大きいcsvファイル(数GB)で構成
これと戦う為,pandasを活用しました.
流石にGBを超えるとオンメモリで処理が辛いですし,一括処理するためだけにメモリのためにお高いEC2インスタンスは使いたくありません.10
pandasのコントリビューター, @sinhrksさんのブログ記事「pandas でメモリに乗らない 大容量ファイルを上手に扱う」を参考に,以下の対策でメモリに依存する処理を回避しました.
- read_csvする時に「chunksize」オプションを指定して, DataFrameを分割読み込み
- queryで絞って対象データが確定した時点で,DataFrameを複製せず,「inplace=True」オプションでDataFrameを直接書き込み
LuigiのTaskとして,
- 数GBのcsvファイルをchunksize指定でreas_csvして,分割した単位で別のcsvに保存(オンメモリで処理して差し支えない程度の小さいファイルに分割)
- 「1.」のタスク後,分割したcsvファイルを読み込んで処理するTaskを並列実行,処理時にqueryで絞ってinplaceでデータサイズを圧縮
この2つを数珠つなぎに実行するPiplineを作って処理をしました.
Jupyter notebookなどで普段使ってる時はオンメモリで良くても,実務仕様の時はオンメモリとストレージをバランス良く使いたいよね,ということで覚えたほうが良いtipsだと思いました.
使い方(雰囲気サンプル)
部分的なスニペットとなります,雰囲気が伝われば幸いです.
chunksizeで分割して保存
import pandas as pd
# 大きいファイルを10万行毎にDataFrame化してcsvとして保存
no = 0
for r in pd.read_csv('/tmp/hoge/big_stanton.csv', chunksize=100000):
# TODO 何かしらの前処理
filename = '{no}_mini_gordon.csv'.format(no=no)
r.to_csv(filename, index=False) # DataFrame.indexを引き継ぐ必要ない時は,indexを含めないほうがファイルサイズ的にもお得
no += 1
queryで絞った後,inplaceでダイエット
import pandas as pd
df = pd.read_csv('/tmp/hoge/big_stanton.csv')
# DataFrame内に日付があったと仮定して
expr = 'date >= {from_date} and date <= {to_date}'.format(from_date=20171224, to_date=20171225)
# query条件(expr)に合致したデータのみ残る,外れたデータは消える
df.query(expr, inplace=True)
Scrapyによる,データ取得(API呼び出し)と保存
提携サービス(今回は2つ)毎にScrapyアプリを構築し, API呼び出しとデータ保存を行いました.
Scrapyを使ったAPI呼び出しサンプルと背景については,これもRetty Advent Calendar 2017で紹介させていただいています(20日目)
REST API提供者と自分にやさしいAPIクライアントをPythonでいい感じに作る方法
今回はLuigiのTask(Pythonクラス)から呼び出す為,scrapyコマンド...ではなく,ScrapyのPythonコードI/F,具体的にはCrawlerProcessを使っています.11
サンプルコード
【Github】scrapy-connpass/blob/master/connpass/connpass/run.pyより.
# 事実上,デバッグ用のツール
from scrapy.crawler import CrawlerProcess
from scrapy.utils.project import get_project_settings
from connpass.spiders.api import ApiSpider
def search_my_event(nickname='shinyorke', count=100):
settings = get_project_settings()
crawler = CrawlerProcess(settings)
crawler.crawl(ApiSpider, nickname=nickname, count=count)
crawler.start()
if __name__ == '__main__':
search_my_event()
Pythonのクラスから書けるということは,LuigiのTaskから呼び出すのも結構楽にできます(雰囲気コードです).
from luigi import Task
from scrapy.crawler import CrawlerProcess
from scrapy.utils.project import get_project_settings
from connpass.spiders.api import ApiSpider
class SampleScrapyTask(Task):
"""
Luigi TaskからScrapyを呼び出すサンプル
"""
def requires(self):
# 依存関係を書いてね(便宜上省略)
pass
def run(self):
settings = get_project_settings()
crawler = CrawlerProcess(settings)
crawler.crawl(ApiSpider, nickname='shinyorke', count=10)
crawler.start()
def output(self):
# ファイル等のアウトプットを実装する(Luigiのお作法)
pass
結び
結果的に,ほぼ納期通りにバッチは運用開始,要件も満たした上で日々ユーザーさんにとって良い食体験をするお手伝いを基盤レベルで出来始めたかな?と思っています.
運用当初は処理が終わりきらない・アラートが上がる...度にソルジャー的な処理をしてましたが,最近はSlack通知も落ち着き12,安定運用なフェーズに入りました,良かったよかった![]()
今後の展開・宿題としては,
- 現時点で構築・運用者が私一人なのでさっさと増やす・引き継ぐ(教育含めて)
- 連携サービスは今後も増えるので,スケールに備えた構成にしたい. LuigiアプリとScrapyアプリの間で機能レベルの依存はしていないが,結局呼び出したりしてる箇所での依存はあるので切り離していい感じにすることが必要13
- まあまあ大きいアプリになったので,コンテナ単位で分割を考える(つまりマイクロサービス化)
- 今回はScrapyおよびLuigiのJOB Queueや非同期処理に頼ったが,マイクロサービスにする時に備えてQueueとかの運用をいい感じにする(でないとマイクロサービスにはできない)
- 他の予約導線や他社連携バッチへの横展開(アーキテクトやノウハウ他)
私はPythonistaなのですべてPythonでやりきる回答を出しましたが,他にもイケてるアプローチなどあったら是非コメントとかいただけると幸いです.
今年のアドベントカレンダーも明日がラスト.
明日はRetty CTO @taru0216 さんがラストを締めくくります.
良いメリー・クリスマス・イヴを![]() 14
14
-
魚が美味しいお店は南蛮漬け(洋食系だとエスカベッシュ)が美味い,という揺るぎない持論とこだわりがあります← ↩
-
野球の人と呼ばれています #察し ↩
-
わかりにくい公式ドキュメント...をいい感じにしたモノタロウ増田さんのスライドがメチャクチャ参考になりました! ↩
-
PyMySQLはPythonのみでできているMySQLコネクタで...という解説は,別のエントリーで紹介させていただいています(手前味噌) ↩
-
「Also it should be mentioned that Luigi is named after the pipeline-running friend of Super Mario.」, PyPIより引用. ↩
-
Airflowを使うことも考えましたが,機能がリッチすぎるのと,保守できるメンバー育成に課題がありそうだったので断念しました.余談ですが,AirflowのDockerイメージを使って運用は個人的なプロダクトでやってます(こちらのエントリーを参照). ↩
-
Airflowだとcrontabに限らず独力で実行可能,ここぐらいかなイケてないのは ↩
-
というより,そんなメンバーの皆様からLuigiを教わりました ↩
-
TB超えのデータであれば,Spark等に逃して並列処理も検討してました...が,そこまでやるほどのサイズでもないのでpandasで頑張りました. ↩
-
コードのコメントにある通り,例えばPyCharmでデバッグする際のデバッグ用コードとしてもすごく便利です. ↩
-
文章の都合上,本文中では触れていませんがタスク単位でSlack通知,異常時は教えてくれる仕組みにしています. ↩
-
パッケージ構成は申し訳ないですが非公開で
 ↩
↩ -
このエントリーが出る頃,私は歩いて山手線を一周していることでしょう(そんなイベントに参加している予定)
 ↩
↩