この記事は Retty Advent Calendar 2017 20日目です。
昨日は @resessh さんの 「Vue.jsをTypeScriptで書く環境を構築する (Sublime Text編)」 でした。
REST API提供者と自分にやさしいAPIクライアントをPythonでいい感じに作る方法
Rettyのサーバサイドエンジニアかつ,Python使いのnakagawa(@shinyorke)ともうします.1
データ分析をしたり,機械学習をしたりする上で,当然のことながらまとまったデータが必要ですと.
データを得る・活用する際は,
- 公開されているAPI(REST API)から取得する
- Webサイトをクロールして目的のページをスクレイピングする
- APIから取ったデータorスクレイピングしたデータをDBに保存する
といった苦行楽しい作業をするわけですが,その「楽しい作業」を,
- サイト事業者およびAPI提供者に迷惑をかけることなく「ひと(提供者,つまり他人)にやさしく」取得する
- なるべく開発しない,つまり「開発者(自分)にやさしく」サクッと作る
という視点でサクッと開発する方法を紹介します.
なお,このエントリーではWebサイトのクロール・スクレイピングには一切触れません,あくまでもAPI呼び出しの話ですあしからず!2
「REST API提供者と自分にやさしい」 #とは
API提供者に迷惑をかけないかつ,作る側も楽する事で「ひと(提供者と自分)にやさしく」できるのでは?
という意味です.
REST APIをCallしてデータを取得,分析およびサービス内で利用するのはよくある話ですが,
API提供者から見た場合
- 不意に突然やってくる大量リクエスト
- 上がるCPU利用率,遅れるレスポンス
- 【もしかして】攻撃されている???
開発者から見た場合
- 毎回APIを呼ぶ実装を書くのがダルい
- リクエストの並列化・間隔調整を書くのがめんどくさい
- 結果,雑なAPIクライアント作って大砲が無事完成→無差別大量リクエストが(ry
と,(知ってか知らずかは別として)お互い不幸になるようなトラップがいくつかあります.
両者から見たら悪夢でしかありません,悪気はないのに.3
開発者(自分)がちゃんと気を使って開発するのは当然のことですが,とはいえフルスクラッチで作るのもイケてないので,「既存のFW・ライブラリの組み合わせで両者にやさしい」APIクライアントを思いつきで作ってみました.
今回の主役はエンジニア界隈では「スクレイピングのフレームワーク」として最近知名度を上げてきている「Scrapy」です.
Scrapy #とは
Webサイトをスクレイピングしてデータを保存するまでの処理を一気通貫に書ける・動かせるPython製のフレームワークで,
- インストールが楽(pipで入れておしまい)
- アプリの雛形がコマンド一つでザクッと作れる(DjangoやRuby On Railsと同じ)
- 開発が楽. クロール・スクレイピング・データ保存の実装に集中できる
- robots.txtの把握やsitemap.xmlからの捜索,リクエスト数・間隔など, 「後から作ると辛い」部分が最初から揃っている
- クロール・スクレイピングとデータ保存が非同期で動く
といった特徴があります.
Scrapyの具体的な内容が気になる方は,公式のドキュメントを読んでいただくか,
この辺をチェックしていただくと,雰囲気や内容が伝わるかと思います(意訳・説明すると長くなるので端折ります).
なお,いずれのエントリー(および,Scrapyに関する書籍・記事)において,「Webスクレイピングの道具だよ」という紹介がされていますが,
戻り値がテキスト(JSON/XMLなど)である以上,REST APIでも十分実用可能です!
サンプル〜connpass APIから勉強会情報を検索してDBに保存
ScrapyとPythonの標準ライブラリ(json,sqlite3)を使って,
- connpassのAPIを検索して勉強会の一覧を取得
- 一覧の内容をDB(SQLite3)に保存
するサンプルを作りました.
このサンプルを元に,「API提供者と自分にやさしいAPIクライアント」の勘どころを紹介します.
「API提供者と自分にやさしいAPIクライアント」の勘どころ
「API提供者にやさしく」および,「自分にやさしい」ポイントの紹介です.
API提供者にやさしく〜「にんげんらしく」振る舞う
API・サイト提供者からみた迷惑のNo.1は間違いなく,
過度な回数のリクエスト
です.
具体的には,
- 必要もないのに並列実行している
- API・サイトの性能限界を超えるリクエスト間隔
- 一度読んだらもう呼ばなくてええやん?(キャッシュ取ろうよ)
が代表例かと思います.
APIとサイトの提供者は常に,
「(呼ぶならせめて)にんげんらしく振る舞ってくれよ」7
と思うはずです.
良識ある開発者はこれらを考慮して,
- 適切な場所でsleepを入れる(リクエスト間隔の調整)
- マルチプロセス・マルチスレッドを実装かつ,並列数を調整
- ファイルなりシリアライズなりDBなりにオレオレCache機構を実装
これらを実装するのですが,この手の実装は「泥臭いメンテナンス地獄 ![]() 」にハマること待ったなし!なので,仕事では極力やりたくないです.8
」にハマること待ったなし!なので,仕事では極力やりたくないです.8
ところがどっこい,Scrapyの場合は,
- ダウンロード間隔の調整(DOWNLOAD_DELAYで秒単位チューニング)
- スレッド数のチューニング(CONCURRENT_REQUESTSで最大並列数を指定,ドメイン・IP毎でのチューニングも可)
- キャッシュの有効期限と保存場所・方法を指定して保存
設定ファイル「settings.py」を一ついじるだけでサクッと出来てしまいます!
以下が設定のSampleとなります.
このレベルだと事実上実装は不要となります(Scrapyのデフォルト機能のみで賄える).
# -*- coding: utf-8 -*-
# Scrapy settings for connpass project
#
# For simplicity, this file contains only settings considered important or
# commonly used. You can find more settings consulting the documentation:
#
# http://doc.scrapy.org/en/latest/topics/settings.html
# http://scrapy.readthedocs.org/en/latest/topics/downloader-middleware.html
# http://scrapy.readthedocs.org/en/latest/topics/spider-middleware.html
BOT_NAME = 'connpass'
SPIDER_MODULES = ['connpass.spiders']
NEWSPIDER_MODULE = 'connpass.spiders'
# Crawl responsibly by identifying yourself (and your website) on the user-agent
# USER_AGENT = 'connpass (+http://www.yourdomain.com)'
# Obey robots.txt rules
ROBOTSTXT_OBEY = True
# Configure maximum concurrent requests performed by Scrapy (default: 16)
CONCURRENT_REQUESTS = 2 # 並行リクエスト数(デフォルトは16)
# Configure a delay for requests for the same website (default: 0)
# See http://scrapy.readthedocs.org/en/latest/topics/settings.html#download-delay
# See also autothrottle settings and docs
DOWNLOAD_DELAY = 30 # ダウンロード間隔(デフォはゼロ秒!?)
# The download delay setting will honor only one of:
CONCURRENT_REQUESTS_PER_DOMAIN = 2
# CONCURRENT_REQUESTS_PER_IP = 16
# Disable cookies (enabled by default)
# COOKIES_ENABLED = False
# Disable Telnet Console (enabled by default)
# TELNETCONSOLE_ENABLED = False
# Override the default request headers:
# DEFAULT_REQUEST_HEADERS = {
# 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
# 'Accept-Language': 'en',
# }
# Enable or disable spider middlewares
# See http://scrapy.readthedocs.org/en/latest/topics/spider-middleware.html
# SPIDER_MIDDLEWARES = {
# 'connpass.middlewares.ConnpassSpiderMiddleware': 543,
# }
# Enable or disable downloader middlewares
# See http://scrapy.readthedocs.org/en/latest/topics/downloader-middleware.html
# DOWNLOADER_MIDDLEWARES = {
# 'connpass.middlewares.MyCustomDownloaderMiddleware': 543,
# }
# Enable or disable extensions
# See http://scrapy.readthedocs.org/en/latest/topics/extensions.html
# EXTENSIONS = {
# 'scrapy.extensions.telnet.TelnetConsole': None,
# }
# Configure item pipelines
# See http://scrapy.readthedocs.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
'connpass.pipelines.ConnpassPipeline': 300, # DB保存用のpipeline実装(後述)
}
# Enable and configure the AutoThrottle extension (disabled by default)
# See http://doc.scrapy.org/en/latest/topics/autothrottle.html
# AUTOTHROTTLE_ENABLED = True
# The initial download delay
# AUTOTHROTTLE_START_DELAY = 5
# The maximum download delay to be set in case of high latencies
# AUTOTHROTTLE_MAX_DELAY = 60
# The average number of requests Scrapy should be sending in parallel to
# each remote server
# AUTOTHROTTLE_TARGET_CONCURRENCY = 1.0
# Enable showing throttling stats for every response received:
# AUTOTHROTTLE_DEBUG = False
# Enable and configure HTTP caching (disabled by default)
# See http://scrapy.readthedocs.org/en/latest/topics/downloader-middleware.html#httpcache-middleware-settings
# キャッシュ設定(有効化, 1日保存)
HTTPCACHE_ENABLED = True
HTTPCACHE_EXPIRATION_SECS = 60 * 60 * 24
HTTPCACHE_DIR = 'httpcache'
# HTTPCACHE_IGNORE_HTTP_CODES = []
# HTTPCACHE_STORAGE = 'scrapy.extensions.httpcache.FilesystemCacheStorage'
その他にも便利かつ「提供者」「自分」にやさしい設定があります.
自分にやさしく〜目的のコードだけサクッと書く&動かす
Scrapyでは一つのドメインに対して1..n個のクローラー兼スクレイパー(Spider)を実装します.
Webサイトの場合はページ構造を追ってxpathやcssセレクタを駆使して泥臭いコードを書くわけですが,
今回はJSONという決まった綺麗な構造データなのでたったこれだけの実装で済みます.
具体的にはconnpassのAPIリファレンスの内容をほぼ写経で終わります.
# -*- coding: utf-8 -*-
import json
import scrapy
from connpass.items import EventItem
class ApiSpider(scrapy.Spider):
name = 'api'
allowed_domains = ['connpass.com']
start_urls = []
def __init__(self, **kwargs):
# パラメータにクエリ文字列があれば設定
if not kwargs:
self.start_urls.append('https://connpass.com/api/v1/event/')
else:
# connpassのapi仕様に合わせてクエリにする
query = '&'.join(['{k}={v}'.format(k=k, v=v) for k, v in kwargs.items()])
self.start_urls.append('https://connpass.com/api/v1/event/?{}'.format(query))
def item_event(self, event: dict)-> EventItem:
"""
イベント情報
:param event: イベント情報(APIの戻り)
:return: Scrapyのイベントアイテム
"""
i = EventItem() # Itemのクラスは自分で作る,とはいえほぼ構造体
i['event_id'] = event.get('event_id')
i['title'] = event.get('title')
i['description'] = event.get('description')
i['catch'] = event.get('catch')
i['hash_tag'] = event.get('hash_tag')
i['event_url'] = event.get('event_url')
i['started_at'] = event.get('started_at')
i['ended_at'] = event.get('ended_at')
i['limit'] = event.get('limit')
i['event_type'] = event.get('event_type')
i['series'] = json.dumps(event.get('series'), ensure_ascii=False)
i['address'] = event.get('address')
i['place'] = event.get('place')
i['lat'] = event.get('lat')
i['lon'] = event.get('lon')
i['owner_id'] = event.get('owner_id')
i['owner_nickname'] = event.get('owner_nickname')
i['owner_display_name'] = event.get('owner_display_name')
i['accepted'] = event.get('accepted')
i['waiting'] = event.get('waiting')
i['updated_at'] = event.get('updated_at')
return i
def parse(self, response):
"""
responseを取得
仕様は以下を参照
https://connpass.com/about/api/
"""
body = json.loads(response.body) # bodyはそのままtext→JSONからDictionaryを作っておしまい
events = body.get('events', [])
for event in events:
yield self.item_event(event)
このSpiderでは戻り値を勉強会(event)単位で戻しています.
戻したeventは一行ずつSQLite3に保存していますがこれもこのぐらいの実装で終わります.
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: http://doc.scrapy.org/en/latest/topics/item-pipeline.html
import sqlite3
from scrapy.exceptions import DropItem
class ConnpassPipeline(object):
CREATE_TABLE_EVENT ="""
CREATE TABLE event (
event_id integer primary key,
title text,
catch text,
description text,
event_url text,
hash_tag text,
started_at date,
ended_at date,
_limit integer,
event_type text,
series text,
address text,
place text,
lat real,
lon real,
owner_id integer,
owner_nickname text,
owner_display_name text,
accepted integer,
waiting integer,
updated_at date,
create_date date,
update_date date
)
"""
INSERT_EVENT = """
insert into event(
event_id,
title,
catch,
description,
event_url,
hash_tag,
started_at,
ended_at,
_limit,
event_type,
series,
address,
place,
lat,
lon,
owner_id,
owner_nickname,
owner_display_name,
accepted,
waiting,
updated_at,
create_date,
update_date
)
values(
?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,
datetime('now', 'localtime'),
datetime('now', 'localtime')
)
"""
DATABASE_NAME = 'connpass.db'
conn = None
def __init__(self):
"""
Tableの有無をチェック,無ければ作る
"""
conn = sqlite3.connect(self.DATABASE_NAME)
if conn.execute("select count(*) from sqlite_master where name='event'").fetchone()[0] == 0:
conn.execute(self.CREATE_TABLE_EVENT)
conn.close()
def open_spider(self, spider):
"""
初期処理(DBを開く)
:param spider: ScrapyのSpiderオブジェクト
"""
self.conn = sqlite3.connect(self.DATABASE_NAME)
def process_item(self, item, spider):
"""
成績をSQLite3に保存
:param item: Itemの名前
:param spider: ScrapyのSpiderオブジェクト
:return: Item
"""
# Spiderの名前で投入先のテーブルを判断
if spider.name == 'api':
# ひたすらイベントを投入
self.conn.execute(
self.INSERT_EVENT,(
item['event_id'],
item['title'],
item['description'],
item['catch'],
item['event_url'],
item['hash_tag'],
item['started_at'],
item['ended_at'],
item['limit'],
item['event_type'],
item['series'],
item['address'],
item['place'],
item['lat'],
item['lon'],
item['owner_id'],
item['owner_nickname'],
item['owner_display_name'],
item['accepted'],
item['waiting'],
item['updated_at'],
)
)
self.conn.commit()
else:
raise DropItem('spider not found')
return item
def close_spider(self, spider):
"""
終了処理(DBを閉じる)
:param spider: ScrapyのSpiderオブジェクト
"""
self.conn.close()
処理開始(open_spider)および処理終了(close_spider)もシグナルで繋いで拾ってくれるので,開発者は必要なイベント(DBを開く・閉じる,保存する,ロールバックするetc...)をそれぞれにあわせて書いておしまいです.
フルスタックなフレームワーク故,お作法や独特の構造に慣れるまで時間が必要な欠点はありますが,なれるとちょっとしたAPIクライアントは数時間で出来ちゃうのでオススメです!(私はこのサンプルを小一時間で作りました)
Rettyではどう活用しているのか
この手法は,Rettyの本番サービス(バックエンド)の一部として実際に運用しています.
具体的にはRettyと提携しているサービス(主に予約系)のREST APIをCallしてデータ保存するバッチをScrapy+Luigiで実装しています(すべてでは無いですが).
していることをざっくり書くと,
- 提携しているサービスのREST APIを呼び出して一次キャッシュ(ファイルおよびSQLite3)に保存
- 一次キャッシュのデータからサービス用のデータ(RDS)を作成,Retty内の飲食店情報とひも付け
- サービス用のデータは予約導線(提供元に送客,コース表示など)に活用
といったことをしています.10
ちなみに実運用はAWS ECS(Elastic Container Service)で行っています(つまりDockerでやってます).
ざっくりなパイプライン(概念)にまとめるとこんな感じです.
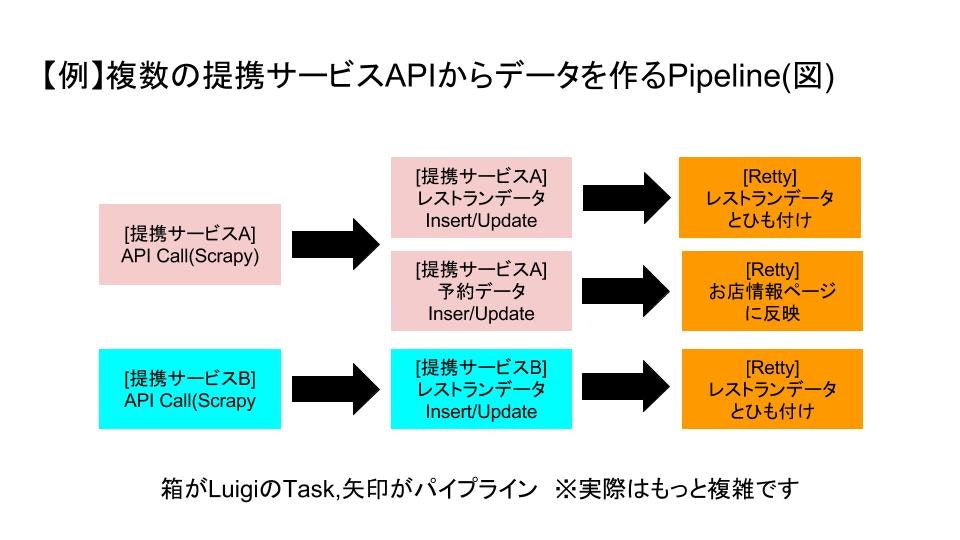
なお,Pythonの場合,Beautifulsoupやrequestsなど,APIを呼んでクロールする「だけ」ならもっと楽に書ける・作れるライブラリがありますが,
- API呼び出し・クレンジング(前処理)・データ保存がひとつのフレームワークで完結する
- フレームワーク故,過度な「オレオレ実装」「独自フレームワーク化」を回避可能
- 過度なAPI Callで提携先に迷惑をかけない
- Scrapy(+Luigi)は社内で使えるPythonistaが複数人いる11
といった,ビジネスおよび保守要件そして「ひとにやさしく」を重視し,Scrapy(とLuigi)を選択しました.
この話の続きは...
複数のScrapyプロジェクト+Luigiでワークフローをいい感じに作る例をどこかに書き残したいと思います.
Retty Advent Calendarは...既に満席なので急遽,クリスマスイヴに空きができたので12,続きはまた今度公開します!
結び
サイト提供者にやさしさを!そして開発をもっと楽に!!
明日は @saku さんの「swiftで丸画像をパフォーマンス高く表示する方法」です,お楽しみに!
(&24日にもう一度書くのでよろしくどうぞ!)
-
いわゆるひとつの野球の人です. ↩
-
これは個人的な見解ですが,スクレイピング・クローリングに頼るのは最終手段で,本来的にはAPIがあったらAPIを使うべきですよといいたい(開発・運用コストとか諸々考えるとね). ↩
-
ホントそう思っていて,知らない(技量がない)から起こり得る不幸なのかなと. ↩
-
PyCon JP 2016でこの発表を聞いてガチでScrapyやろうと思いました,すっごくわかりやすいのでオススメ. ↩
-
公式のチュートリアルよりも優しいかも,これもオススメ. ↩
-
こちらは今年(2017)4月のPyCon mini Kumamoto 2017で登壇・発表しました, スクレイピングからRedashを使った分析を一気通貫に見たい方は是非どうぞ. ↩
-
この表現は,requests(Python)のドキュメントや,Python関連の本でたまに出てきます&私はこの表現が大好きです. ↩
-
プログラミングの練習・実力アップ的な課題としては最高なのですが,得てしてこの手のコードは「書いた人しかわからない」オレオレ実装になるので容易に負債化するんじゃないかと思ってます,自分も昔のやらかしでその手のコードが(ry ↩
-
その他にも,実行時のオプション引数として渡す方法や,spiderクラスの「custom_settings」に直接指定する方法もあります(settings.pyの内容より,引数が優先される),プロジェクト構成的にsettings.pyの定義がキツイときに有効. ↩
-
余談ですが,APIの仕様を確認したり,プロトタイピングをしたり...をJupyter notebookやrequestsで充分リハーサルしてやりました,前回のエントリーを参照. ↩
-
Luigiは以前からバックエンドで活用,事例の発表もいくつかあります.また,新卒〜若手を中心にPython使いが複数人いるため,堂々とPythonを使えるのは大きな利点です(しかもPython3ベースです) ↩
-
12/19現在,24日に急遽代打として入ることになりました,助け合い大事!(なお別のAdvent Calendarもある模様) ↩