この記事は Retty Advent Calendar 4日目です.
昨日は@flum1025さんのGoogle Homeと会話してみるでした.
Webなエンジニアのための「Pythonデータラングリング」入門
Rettyでサーバサイドエンジニアをしています,nakagawa(@shinyorke)ともうします.
Rettyではアライアンス関連のバックエンド開発およびデータ整備を,プライベートでは野球の統計分析をPythonを駆使してやっています. 1
このエントリーでは明日からでも現場で使える,「Pythonデータラングリング」術を簡単に紹介したいと思います.
言いたいことを3行でまとめると
- 受け取ったデータのチェックやおためし利用,APIの使い方・戻り値チェックにPythonオススメ2
- データ操作もAPI呼び出しもデータ保存も数行のコードでイケる
- 手元にJupyter環境を用意しておくと何かと取り回しが良くて便利
データラングリング(Data Wrangling) #とは
データ(Data)を飼いならす(Wrangling,アメリカ英語 3 )という意味の造語です.
意味合い的には,データの統計分析や機械学習,ディープラーニング...といった事を行う前の,
- データ取得(CSV・JSONなどの構造データ,REST APIの戻り値,得体の知れないPDF,etc...)
- データ型を整える,行列を整える,ゴミを取る,欠損値の補填etc...ひと言で言うと「前処理」
ことを意味しています.
がしかし,データサイエンティストだけでなく,Webなエンジニアも,
- 外部および提携先のAPIを使ってデータを取得する&サービスに取り込む.
- 定期的に受信するデータ(CSVやXMLなど)をサービス内で使う.
- ...といった調査・開発の前にデータの中身をチェックしたり,処理を実装する前にお試しで動かしてみたり.
といった業務・プロダクトづくりは当然の用に発生するので,必ずしもデータサイエンスのためだけのものではない!と思っています.
なお,「データラングリング」という言葉は,英語圏では90年代から使われ,日本でもR界隈のコミュニティで使われていた言葉とのことです,今年オライリー・ジャパン社からでた「Pythonではじめるデータラングリング 」でPython界隈にも輸入されたみたいです. 4
データラングリングとはなんぞや?等,詳しく気になる方は上記オライリー本もしくは,上記本の書評を兼ねた解説をこちらのエントリーに載せていますので,どうぞご参考になればと思います(手前味噌). 5
Pythonではじめるデータラングリング〜Jupyter,pandas,requestsを添えて
データラングリングそのものは得意な言語・好きな環境でやるのがベストです.
...といいつつ,当方Pythonistaかつ,Pythonは伝統的にデータの扱いに強いかつ楽するライブラリが豊富に揃っているので,今回は以下のPythonライブラリを駆使したデータラングリング例を紹介します.
- Jupyter(ブラウザベースの実行環境)
- pandas(データ操作ライブラリ,スプレッドシート的な処理をPythonコードでガリガリ動かせる)
- requests(人間に優しいhttpクライアント)
なお,インストール・実行等の例はすべてMac OS(Sierra)を想定しています.
【事前準備】Anacondaのインストール&使う
今回はPythonの実行環境・パッケージ管理としてAnacondaを使います.
こちらからご自身お使いのOSにあったイメージをダウンロード&インストールしましょう.
インストール後,以下のコマンドで仮想環境を作ります(質問はすべて「Y」で答える).
$ conda create -n advent-calendar2017 python=3.6
なお,仮想環境の使い方はこんな感じです.
$ source activate advent-calendar2017
(advent-calendar2017) $ which python
/Users/hoge/anaconda3/envs/advent-calendar2017/bin/python
(advent-calendar2017) $ source deactivate
$ which python
/usr/bin/python
Jupyter,pandas,requestsを入れる
仮想環境に入った後,condaコマンドでインストールします
$ source activate advent-calendar2017
(advent-calendar2017) $ conda install -y jupyter notebook pandas requests
Jupyterの起動・停止
jupyterコマンドで起動,停止はCtrl + Cで抜けます
(advent-calendar2017) $ jupyter notebook
起動すると,ブラウザが立ち上がり,ここからコードを書いて実行ができるようになります.
「New」ボタンをポチると,インタプリタ的な画面が立ち上がります.
データラングリングをしてみる
業務のデータは使えない(察し)なので,オープンデータ等で代用します.
なお,今回紹介したコードはこちらにGistとして公開しているので気になる方はぜひご活用ください.
csvを取り込む・操る
pandasで取り込むことにより,
- 取り込み(import)
- データ検索・加工
- 出力
が割とアッサリできてしまいます.
以下は野球のデータ(メジャーリーグのオープンデータ,Sean Lahman)を用いた例です. 6
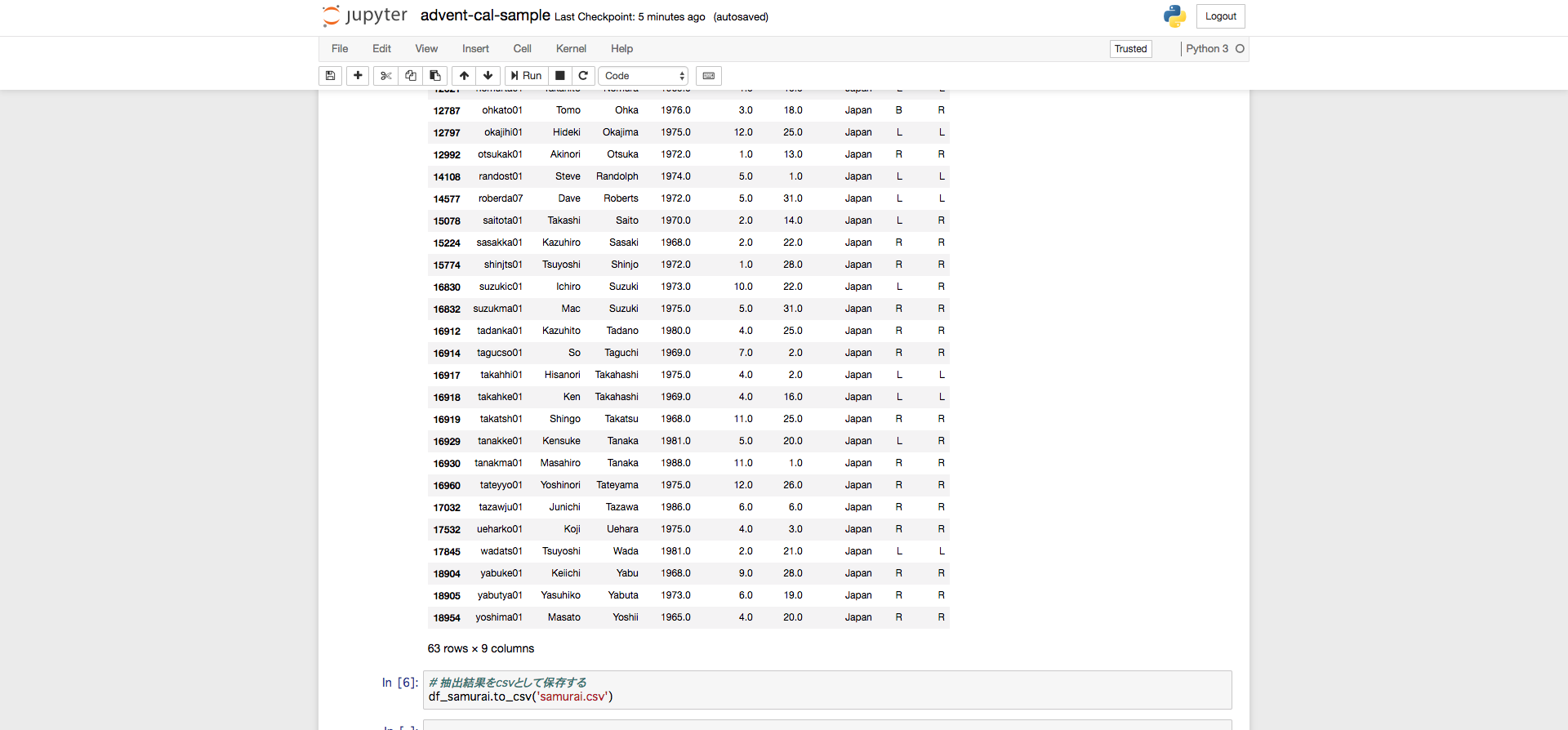
import pandas as pd
# データを読み込む
df = pd.read_csv('./Master.csv')
# データのカラムを確認する
df.columns
# 日本生まれの選手(元を含む)を抽出する
df_samurai = df[['playerID', 'nameFirst', 'nameLast', 'birthYear', 'birthMonth', 'birthDay', 'birthCountry', 'bats', 'throws']].query('birthCountry=="Japan"')
# 抽出結果をcsvとして保存する
df_samurai.to_csv('samurai.csv')
Jupyterだとこれらのコードの実行結果を見ながら対話的に確認ができます,楽ですね!
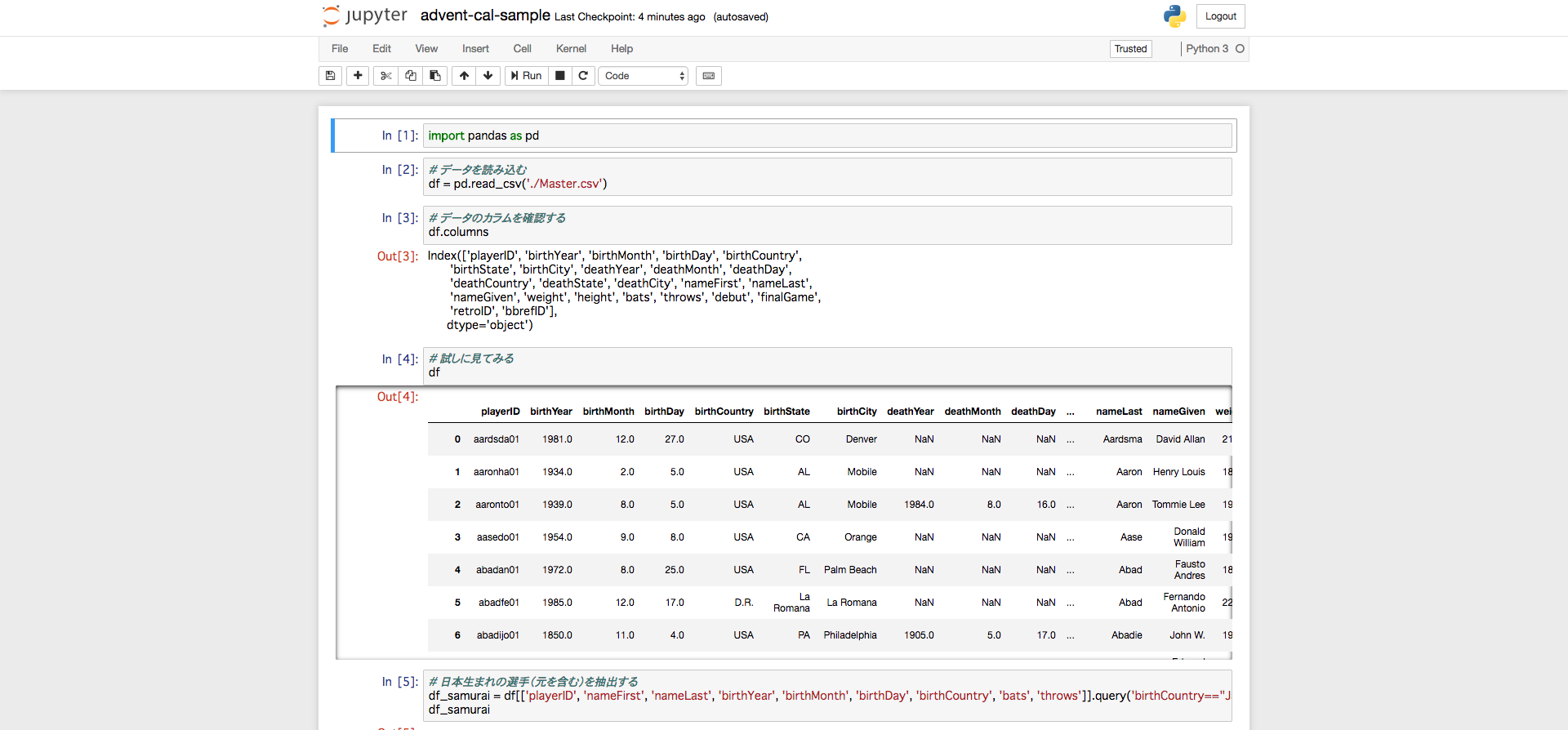
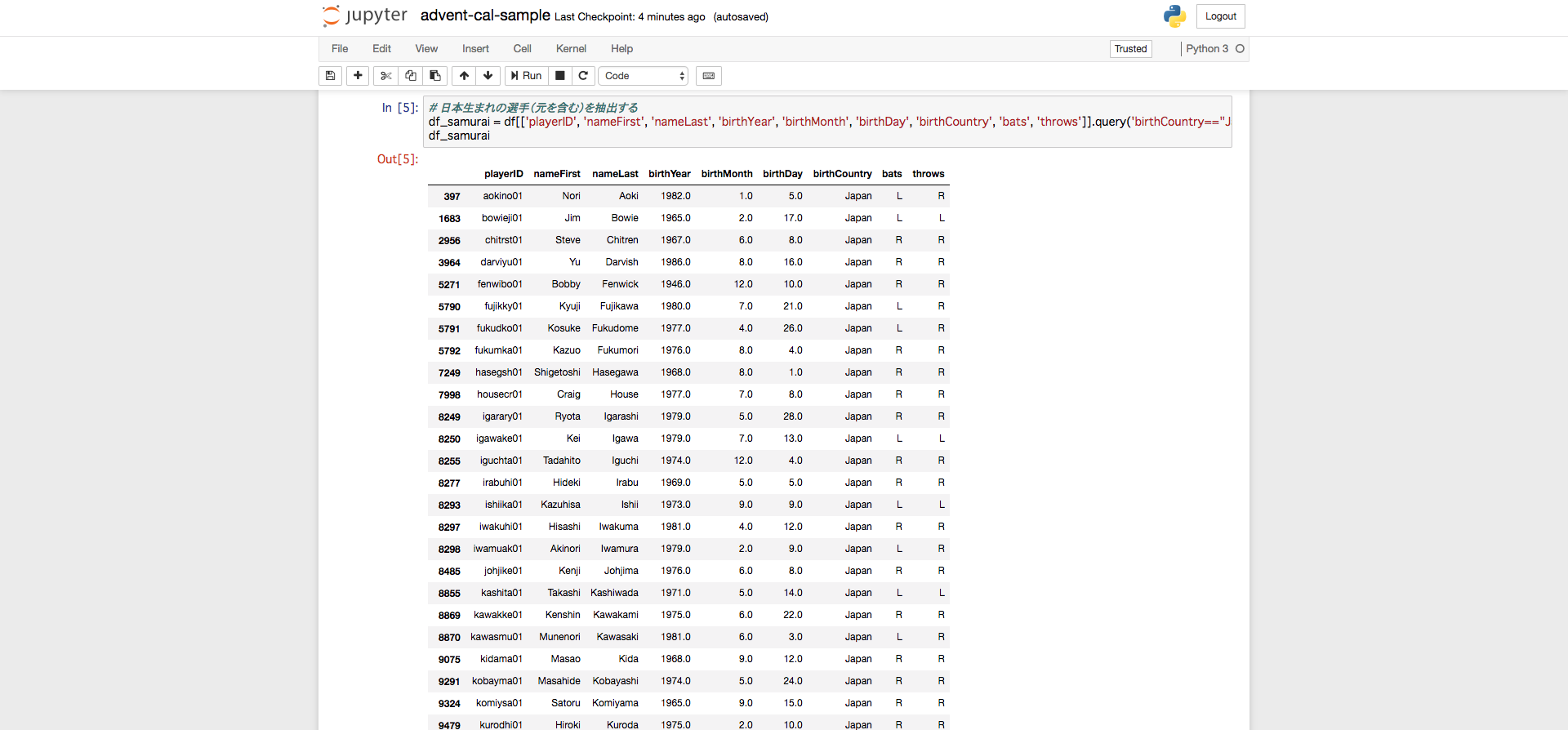
実際の業務では,
- 貰ったCSVやデータのdumpを読み込み,件数・中身をチェック
- 適当にQUERYを書いたり,filterしてみたりして欠損値や異常値を見つける
- プロダクト(Webアプリやバッチ)を作る前に簡単なプロトタイプを実装・確認する
- 調査結果をcsvやSQLのダンプとして保存&共有する
といった目的でフル活用しています.
設計・実装が確定する前のお試しとして,凄くやりやすいのでオススメです.
必ずしもデータサイエンティストの道具ではない!Webのエンジニアでも使えるんだぜ!!と覚えてもらえるとうれしいです. 7
なお,JupyterのKernel(実行エンジンのこと,OSのことではない)を別に入れる事により,Python以外の言語(Rubyなど)でも可能です.
REST APIを呼ぶ
Pythonにはrequestsという「人間に優しい」Interfaceを持ったhttpクライアントがあり,その場で中身をチェックできるJupyterと共に使うとデバッグがとてもはかどります.
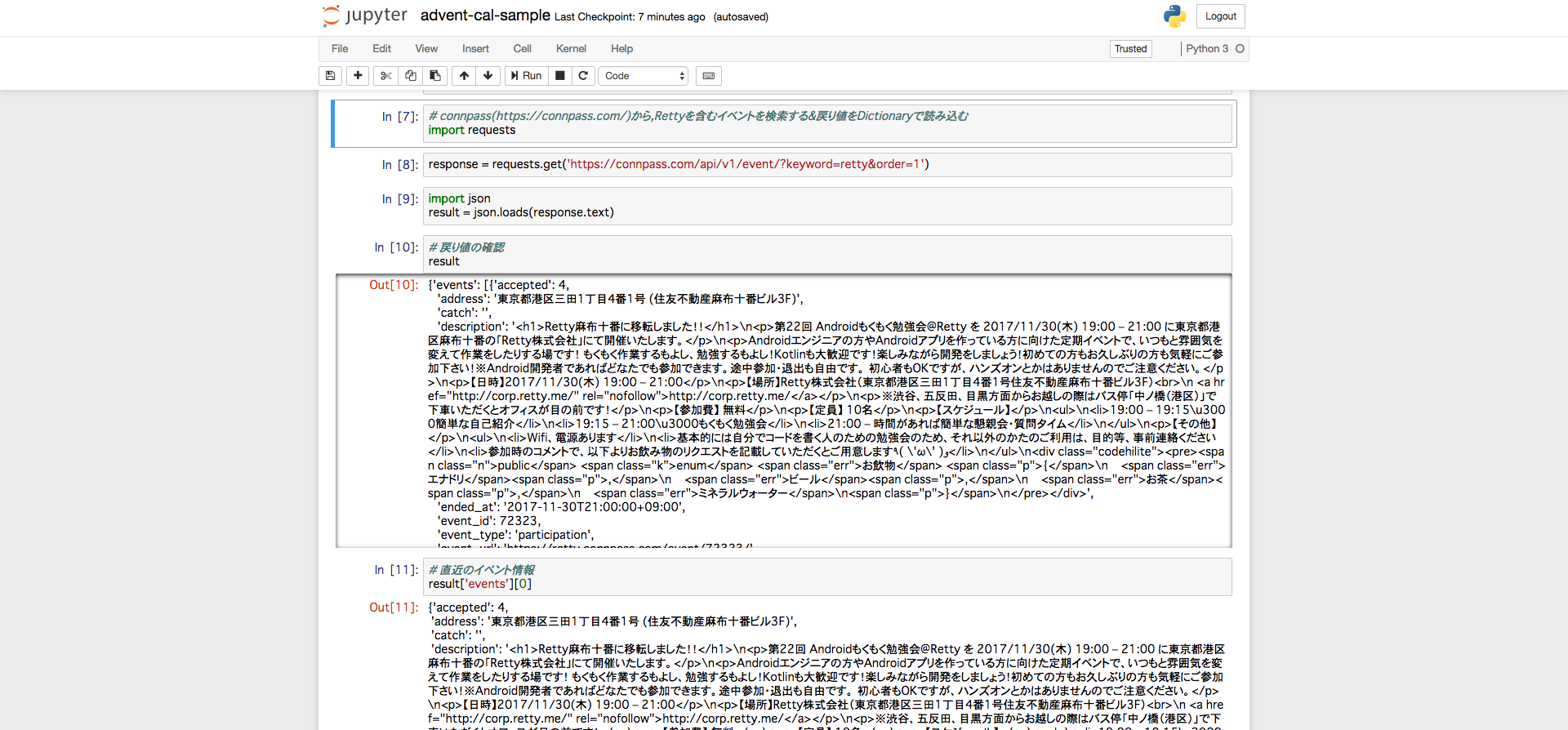
Rettyでももくもく会などでお世話になっているconnpassのAPIを使った例です.
responseはjsonなので,Pythonのjsonライブラリ(標準ライブラリです)でDictionaryにして扱っています.
# connpass(https://connpass.com/)から,Rettyを含むイベントを検索する&戻り値をDictionaryで読み込む
import requests
response = requests.get('https://connpass.com/api/v1/event/?keyword=retty&order=1')
import json
result = json.loads(response.text)
notebookにするとこんな感じです.
pandasの時と同様,その場でチェックできるのがすごく楽です!
結び
今回はcsvおよびAPIの扱いという簡単な例でのご紹介でした.
コマンドプロンプトやシェルでやるのもOKですが,ブラウザで手軽に対話的に
データを見ながらやれるJupyter(とPythonのエコシステム)をちょっと覚えるだけで面倒くさいデータの確認やデバッグがはかどるのでオススメです! 8
Rettyでは徐々にPythonを使える・興味あるエンジニアが増えており,私が主催しているPythonもくもく自習室@Rettyオフィスにも有志の社員が参加・運営に協力してもらっているなど,(Kotlin勢に負けず劣らず)盛り上がってきています. 9
個人的にはPythonを今以上に社内公用語にするのと,ちょっとしたコードの共有や設計・アルゴリズムの議論をJupyter notebookでできるようなコミュニケーションが沢山できるよう,普及活動頑張りたいと思っています.
明日は@YutaSakataさんの「Android のコンパイル済み Layout Xml を Web 経由で差し込めるようにした話」です
-
むしろ「野球の人」と言ったほうが通りが良いかも?「Python 野球」もしくは「セイバーメトリクス」でググろう ↩
-
Rettyにおける私のメインミッションで,基盤をScrapy+Luigiで作っています...この話は別の日のエントリーにて! ↩
-
他にも「頑張ってなんとかする」という意味もあるそうです.なお,イギリス英語ではニュアンスが異なるので用法には注意が必要とのこと. ↩
-
Python界隈では初かもしれないけど,英語圏では90年代から,R界隈では2,3年前から言われていたみたいですよー...というご指摘を頂いたので訂正させてもらいました. ↩
-
Pythonでデータを扱う人は必読と言っていいくらいの名著だと思ってます ↩
-
このデータの全容および,何ができるのかについてはPyConJP 2014「Pythonではじめる野球プログラミング」で紹介させてもらいました,気になる方はどうぞ. ↩
-
「ワイ,機械学習エンジニアになるンゴ」志望の方はこれぐらいスラで触れないと辛いことは覚えておいたほうが良いと思う,TensorFlowのチュートリアルとかをやる前に. ↩
-
Jupyter上でPHPを触れるらしく,この記事用に試す構想がありましたがタイムアップのため断念orz Jupyter-PHP メインのプロダクトがPHPなのでこれ触れるともっと楽できそう. ↩
-
毎度毎度応募人数オーバーで嬉しい悲鳴ですありがとうございます! ↩