はじめに
この記事はぼくのかんがえたさいきょうのデータセット~データセットを作って delika に登録しよう! by delika Advent Calendar 2022の参加記事です。
こんにちは、スクレイピングをしてみたいエンジニアや副業をお考えの方の皆さん
副業で稼げるのはどのようなテーマなのか、どのような仕事が募集されているのかを知りたいですよね?
そこで、今回は、スキルマーケットのココナラで募集されている動画編集の仕事を調査します。
データを収集するためには、webスクレイピングを活用します。収集したデータは、データクレンジングをして、形態素解析をしたのちdelicaというサービスを使って共有します。ぜひ、作成したデータセットを見てみてください!
データのスクレイピング
スクレイピングは、Webページからデータを収集する手法のことを指します。
利用規約で禁止しているページもあるので利用規約の確認は行ってください。
また、過度なリクエストはDoS攻撃になるので間隔は空ける様にしてください。
スクレイピングの手順としては、だいたい以下のステップがあります。
1.URL理解
スクレイピングを行うには、収集したいデータがあるWebページのURLを把握して、ページがどのように変わるかを把握することが大事です。
2.HTML構成理解
HTMLでは、見出しやリンクなどを記述することで、Webページの構成を表現します。スクレイピングを行うには、HTMLの記述方法を理解しておくことが重要です。
3.コーディング
最後に、スクレイピングを行うプログラムを書きます。言語やライブラリは様々ありますが、PythonやRubyなどのスクリプト言語を使ったり、SeleniumやBeautiful Soupなどのライブラリを使ったりすることがよくあります。今回はPythonのBeautiful Soupライブラリを用います。
1.URL理解
まずココナラを見てます。
今回は、ココナラのWebサイトで動画・アニメーション・撮影のカテゴリを収集することを考えます。
https://coconala.com/requests/categories/10?categoryId=10&page=1
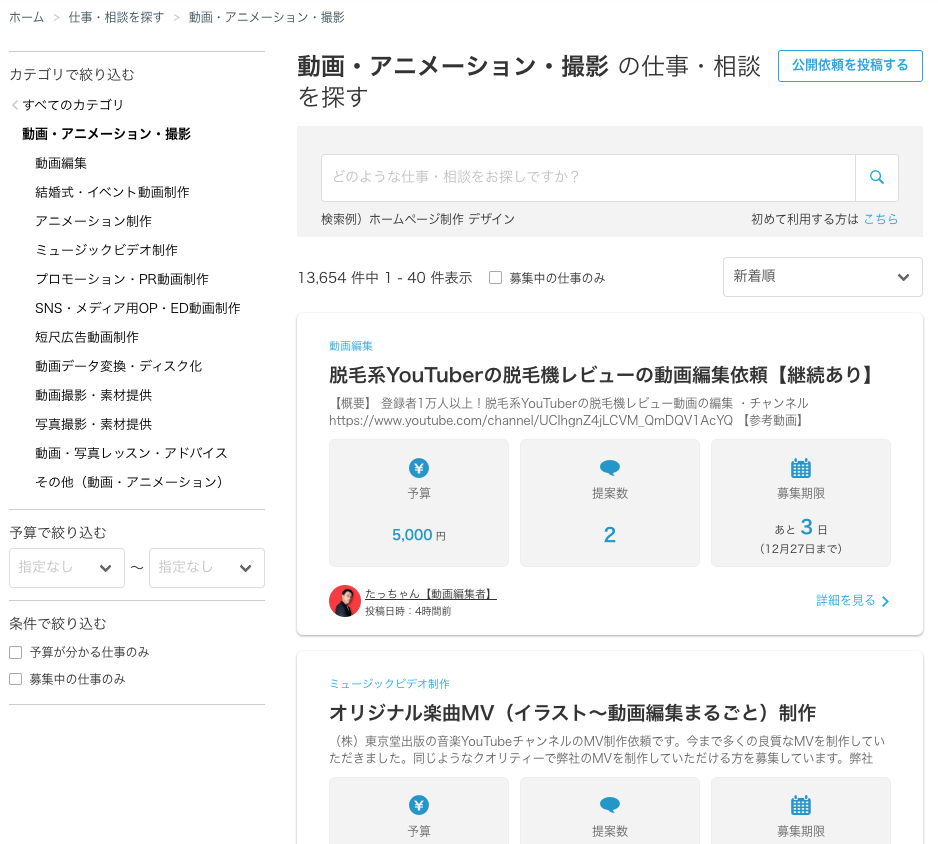
ココナラのWebサイトにアクセスして、categoryId=10及び、ページ番号がpageであることが分かりました。
さらに、342ページある(2022年12月24日時点)ことが分かりました。
今回は、342ページに渡って収集してみましょう。
2.HTML構成理解
今回は、タイトル、説明、予算の3項目をデータ収集することを考えます。
そのためには、HTMLを調べることで、どのクラスに分類されているかを理解する必要があります。
Chromeを使用している場合は、抽出したい要素にカーソルを当てて、右クリックして「検証」をすることで、その要素がどのクラスに分類されているか分かります。
以下の写真の様に、タイトルがc-itemInfo_titleだとわかります。
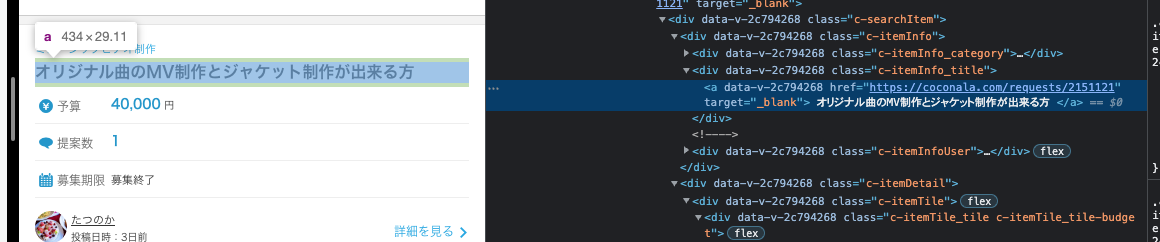
同様に説明と予算も探ることで、以下のクラスに分類されていることが分かります。
- タイトル:
c-itemInfo_title - 説明:
c-itemInfo_description - 予算:
d-requestPrice_emphasis
3.コーディング
まずは、1ページの内容を抽出します。
import requests
import pandas as pd
from tqdm import tqdm
from bs4 import BeautifulSoup
import time
cols = ['title', 'description','cost']
df = pd.DataFrame(columns=cols)
url ="https://coconala.com/requests/categories/10?categoryId=10&page="+str(1)
soup = BeautifulSoup(requests.get(url).content, 'html.parser')
title = soup.find_all(class_="c-itemInfo_title")
description = soup.find_all(class_="c-itemInfo_description")
cost = soup.find_all(class_="d-requestPrice_emphasis")
for i in range(len(title)):
text = title[i].contents[0].contents[0]
text_temp = text.replace('\n', '')
title[i] = text_temp.replace(' ', '')
for i in range(len(description)):
text = description[i].contents[0]
text_temp = text.replace('\n', '')
description[i] = text_temp.replace(' ', '')
for i in range(len(cost)):
text = cost[i].contents[0]
text_temp = text.replace('\n', '')
cost[i] = text_temp.replace(' ', '')
cost = cost[:40]
df_temp = pd.DataFrame(columns=cols)
df_temp['title'] =title
df_temp['description'] =description
df_temp['cost'] =cost
df = pd.concat([df, df_temp], ignore_index=True)
しかし、結果が返ってきません。。
調査したところ、headerを登録しないリクエストは拒否している可能性があるみたいです。
なので、以下のようにheadersを登録した上でヘッダーを含めたリクエストを送ってみます。
headers = {
"User-Agent": "Mozilla/5.0 Chrome/103.0.0.0 Safari/537.36"
}
soup = BeautifulSoup(requests.get(url, headers = headers).content, 'html.parser')
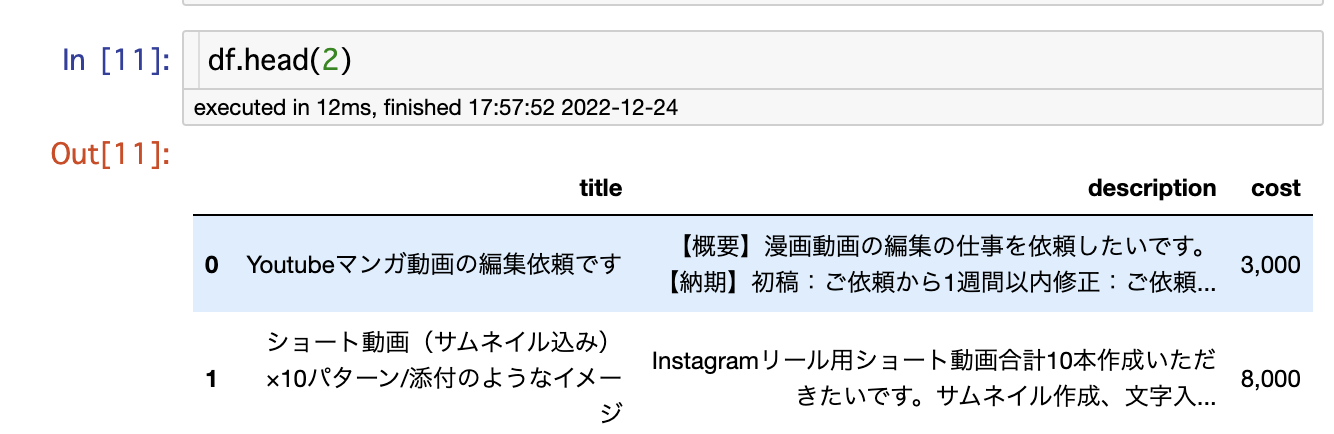
以下の様に結果が想定通り返ってきました。
全ページ スクレイピングサンプルコード
import requests
import pandas as pd
from tqdm import tqdm
from bs4 import BeautifulSoup
import time
cols = ['title', 'description','cost']
df = pd.DataFrame(columns=cols)
url ="https://coconala.com/requests/categories/10?categoryId=10&page="+str(1)
headers = {
"User-Agent": "Mozilla/5.0 Chrome/103.0.0.0 Safari/537.36"
}
cols = ['title', 'description','cost']
df = pd.DataFrame(columns=cols)
for i in tqdm(range(342)):
url ="https://coconala.com/requests/categories/10?categoryId=10&page="+str(1)
soup = BeautifulSoup(requests.get(url, headers = headers).content, 'html.parser')
title = soup.find_all(class_="c-itemInfo_title")
description = soup.find_all(class_="c-itemInfo_description")
cost = soup.find_all(class_="d-requestPrice_emphasis")
cost = cost[:40]
for i in range(len(title)):
text = title[i].contents[0].contents[0]
text_temp = text.replace('\n', '')
title[i] = text_temp.replace(' ', '')
for i in range(len(description)):
text = description[i].contents[0]
text_temp = text.replace('\n', '')
description[i] = text_temp.replace(' ', '')
for i in range(len(cost)):
text = cost[i].contents[0]
text_temp = text.replace('\n', '')
cost[i] = text_temp.replace(' ', '')
cost = cost[:40]
df_temp = pd.DataFrame(columns=cols)
df_temp['title'] =title
df_temp['description'] =description
df_temp['cost'] =cost
df = pd.concat([df, df_temp], ignore_index=True)
time.sleep(5)
注意
スクレイピングは間隔を十分に空けるようにしてください。
最低でも3~5秒は空けましょう。
無事データの収集ができましたね。
データのクレンジング
概要把握
まずは、収集できたデータの確認を行います。df.sample(n=10)を入力します。
これにより、収集したデータのサンプルを10件表示することができます。
サイト構成が途中で変わってることはほとんど無いと思いますが、意図しないデータが収集されていないか確認します。

次に、データの全体傾向を把握するためにdf.describe()
を入力します。
これにより、データの統計量を表示することができます。
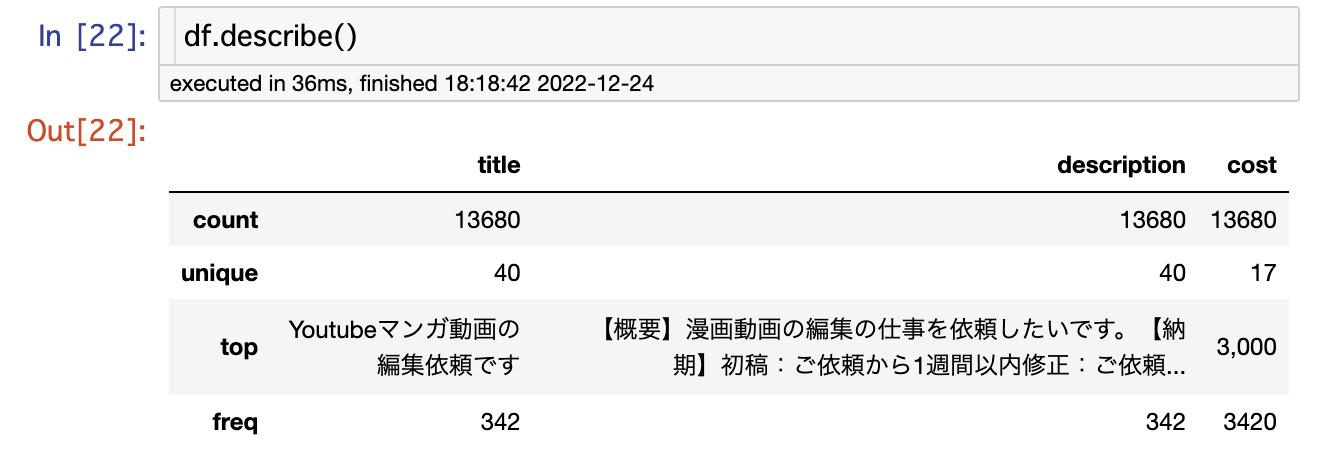
数値データの場合は、標準偏差、最大値、最小値、四分位数も表示されるのですが、全カラム数値以外の型と認識されているのでこちらの値は出ていませんね。
形態素解析
収集したデータから、どのようなテーマが人気があるかを分かるようにするために、タイトルや説明に入力されている文章から名詞のみを抽出します。
そのために、MeCabライブラリを使用して形態素解析を行います。
import MeCab
import re
def get_word_str(text):
mecab = MeCab.Tagger()
parsed = mecab.parse(text)
lines = parsed.split('\n')
lines = lines[0:-2]
word_list = []
for line in lines:
tmp = re.split('\t|,', line)
# 名詞のみ対象
if tmp[1] in ["名詞"]:
# さらに絞り込み
if tmp[2] in ["一般", "固有名詞"]:
word_list.append(tmp[0])
return "," . join(word_list)
df['title_noun']=df['title'].apply(get_word_str)
df['description_noun']=df['description'].apply(get_word_str)
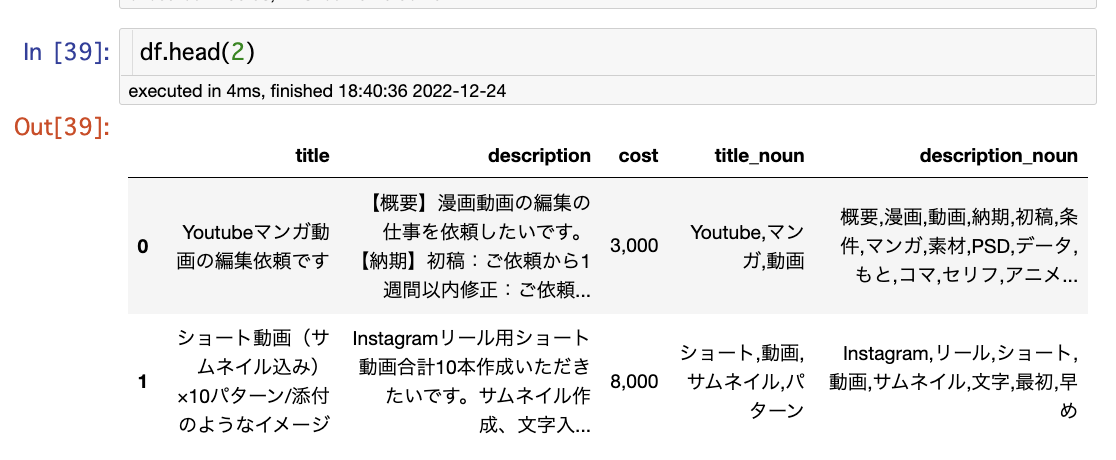
df.head(2)
以下の様に列が追加されていることが分かりますね。
ワードクラウド表示
形態素解析した結果を元に人気のある依頼を探ってみます。
動画の依頼なので動画関連の文字は出ないように制御をかけます。
from wordcloud import WordCloud
import matplotlib.pyplot as plt
merge_title_noun=""
merge_description_noun=""
for i in range(len(df)):
merge_title_noun=merge_title_noun+df['title_noun'][i]
merge_description_noun=merge_description_noun+df['description_noun'][i]
merge_title_noun=merge_title_noun.replace(',', ' ')
merge_description_noun=merge_description_noun.replace(',', ' ')
#インストールしたフォントを入力
font_path = ""
title_name = "coconala_title_wordcloud"
wc = WordCloud( stopwords={'動画ショート','動画','動画オリジナル'},font_path=font_path,width=1920, height=1080).generate(merge_title_noun2)
plt.imshow(wc)
plt.axis('off')
plt.show()
# 画像保存(テキストファイル名で)
wc.to_file(title_name + ".png")
#インストールしたフォントを入力
font_path = ""
descripition_name = "coconala_description_wordcloud"
wc = WordCloud( stopwords={'動画ショート','動画','動画オリジナル'},font_path=font_path,width=1920, height=1080).generate(merge_title_noun2)
plt.imshow(wc)
plt.axis('off')
plt.show()
# 画像保存(テキストファイル名で)
wc.to_file(descripition_name + ".png")
結果は以下の様になりました。
出現頻度が多い単語が大きく表示されますね。
タイトルの解析結果

説明の解析結果

YoutubeやTikTokといった動画プラットフォームへの投稿のための動画作成や切り抜き、テロップ、サムネイル作成が多いことが分かりますね。
delicaへのデータ登録
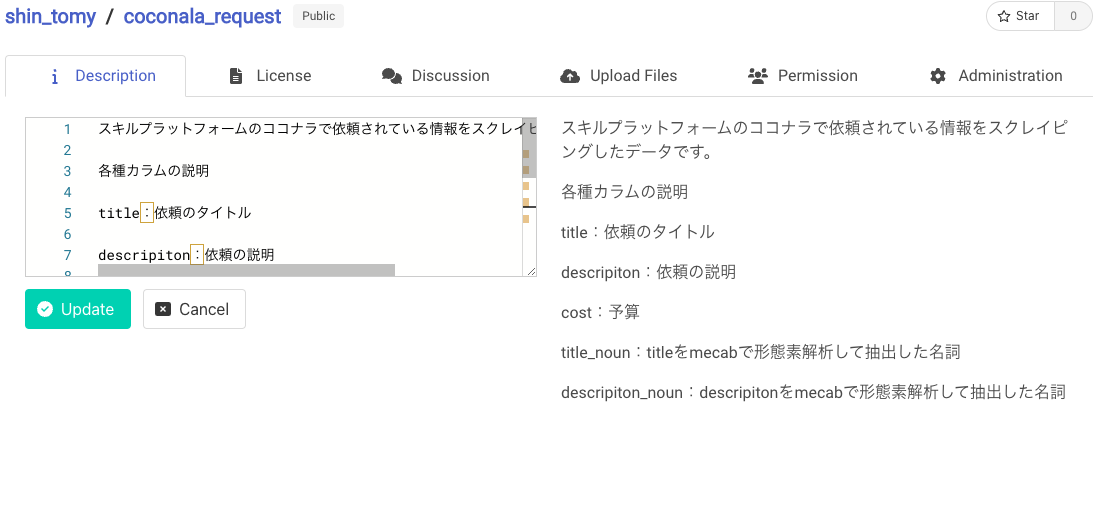
それでは、作ったデータをdelicaに登録してみます。
こちらの記事を参考にしながら登録してみます。
カラムの説明を入力する欄がなかったので、説明欄に記入しました。
登録したデータのURLは以下になります。是非使ってみてください!
https://delika.io/shin_tomy/coconala_request
終わりに
今回はココナラの動画カテゴリで依頼のあるデータをスクレイピング、クレンジング、解析、delicaへ共有しました。
以下の人はぜひ公開したデータを使ってみてください。
- 違う切り口で解析をしてみたい人
- 別のデータと組み合わせてみたい人
「delica」では、様々なデータが「public」データとして公開されています。これを有効活用することで、データ収集や前処理にかかる時間を短縮できる可能性があります。
「delica」のサービスが発展すれば、スクレイピングする必要がなくなるかもしれません。そのためにも、このサービスの発展を望んでいます。