1.はじめに
どうも、ARIの名古屋支社に勤務している愛知県民です♪
(/・ω・)/
Qiitaで面白そうなイベントがやっていたので、参加ボタンをポチりました。
前回の記事ではアカウント作成等の基本的なことについて記載したので、
今回はデータセット(GoogleドライブやS3バケットの様にファイルを保存する場所)
を作成して、自分自身の残業時間を分析してみました!
delikaについて勉強中の方の参考になれば幸いです。
(*^^)v
2022/7/7追記
「delika最優秀賞」を受賞することができました!
ありがとうございます♪
2.用語の説明
2.1.delikaとは
上記イベントページでの記載を引用します。
GitHubがよく分からない人は、pixivに置き換えると分かりやすいと思います。
delikaはデータ版「GitHub」を目指して開発されたデータ共有プラットフォームです。
データの収集や分析もオープンな場で行うことで、より効率良く新たな価値創出につながると考え開発されました。個人が集めたデータは、一見単体では価値がないように見えるデータであっても、企業の分析者の視点で別のデータと組み合わせて分析することで、これまで世の中になかった新たな価値を生み出す可能性があります。「delika」はその化学反応を起こす場となります。
個人とチーム向けに無料のプランもありますので、ぜひ使ってみてください。
3.データセットを作成する
3.1.以下のURLにアクセスし、delikaにログインします。
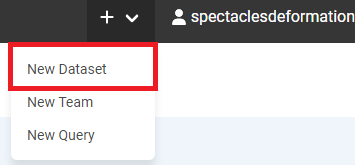
3.2.画面右上の「+」を選択し、「New Dataset」を選択します。
 |
|---|
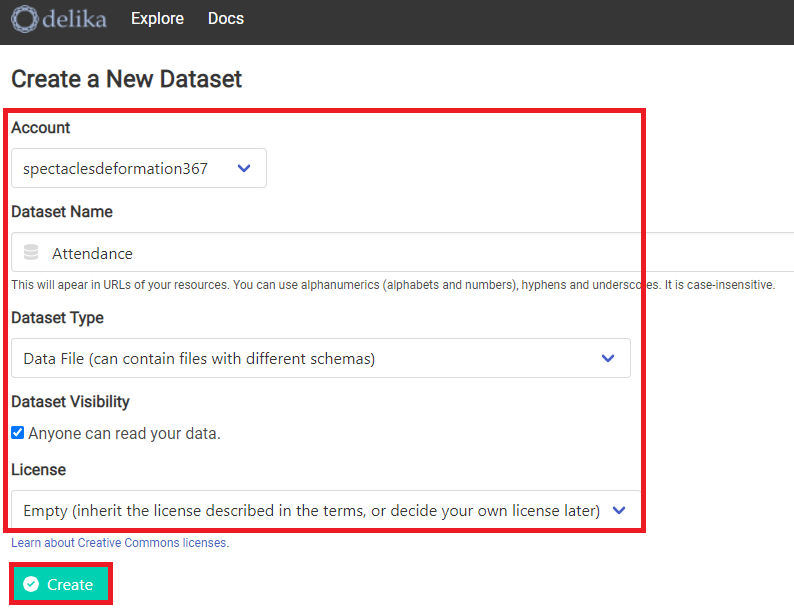
3.3.以下の表のとおりに設定し、「Create」を選択します。
※「Dataset Type」と「License」については選択肢の違いがよく分からなかったため、デフォルトとしています
| 項目 | 設定内容 |
|---|---|
| Account | (自分のアカウント名) |
| Dataset Name | (データセット名) |
| Data Type | Data File |
| Anyone can read your data | (他の人がデータを読み取るのを許可するか) |
| License | Enpty |
 |
|---|
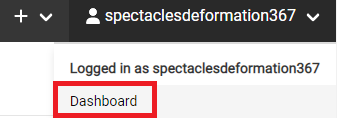
3.4.画面右上のアイコンを選択し、「Dashboard」を選択します。
 |
|---|
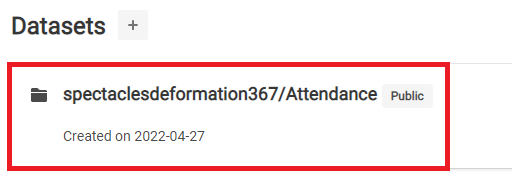
3.5.データセットが作成されていることを確認します。
 |
|---|
4.データセットにファイルをアップロードする
4.1.データセットの管理画面から、「Upload Files」を選択します。
 |
|---|
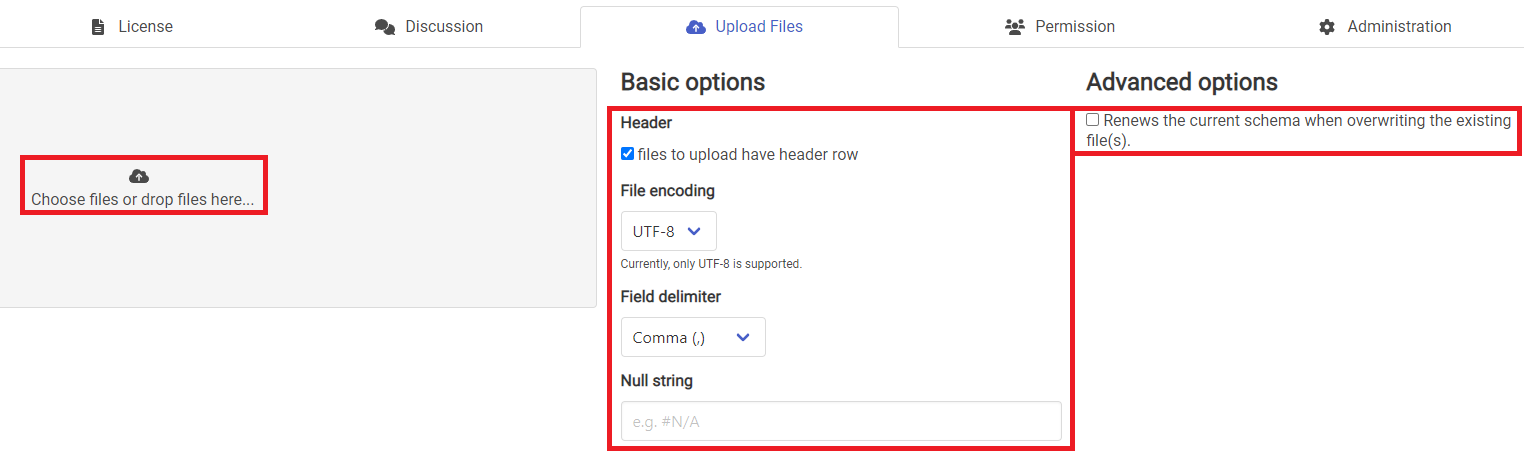
4.2.以下の表のとおりに設定し、「Choose files or drop files here...」を選択します。
| 項目 | 設定内容 |
|---|---|
| Header | (アップロードするファイルにヘッダーが含まれる場合はチェックあり) |
| File encoding | UTF-8 |
| Field delimiter | (アップロードするファイルの区切り文字を選択) |
| Null string | (NULL文字の表記を記載) |
| Renews the current schema when overwriting the existing file(s) |
チェックなし |
 |
|---|
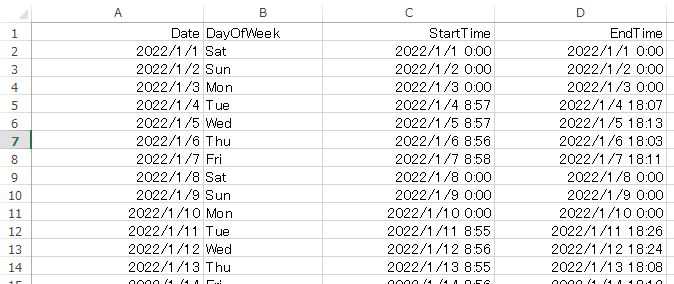
4.3.アップロードするファイルを選択します。
今回は例として、自分自身の2022年1月~4月の業務実績をまとめた、以下のcsvファイルをアップロードしました。
各列は左から日付、曜日、業務開始時刻、業務終了時刻となっています。
 |
|---|
また、5節にはこちらのデータを使用して、SQL文をたたいた結果を記載します。
4.4.データセットの管理画面からアップロードしたファイルを選択します。
 |
|---|
4.5.アップロードしたファイルの内容が表示されることを確認します。
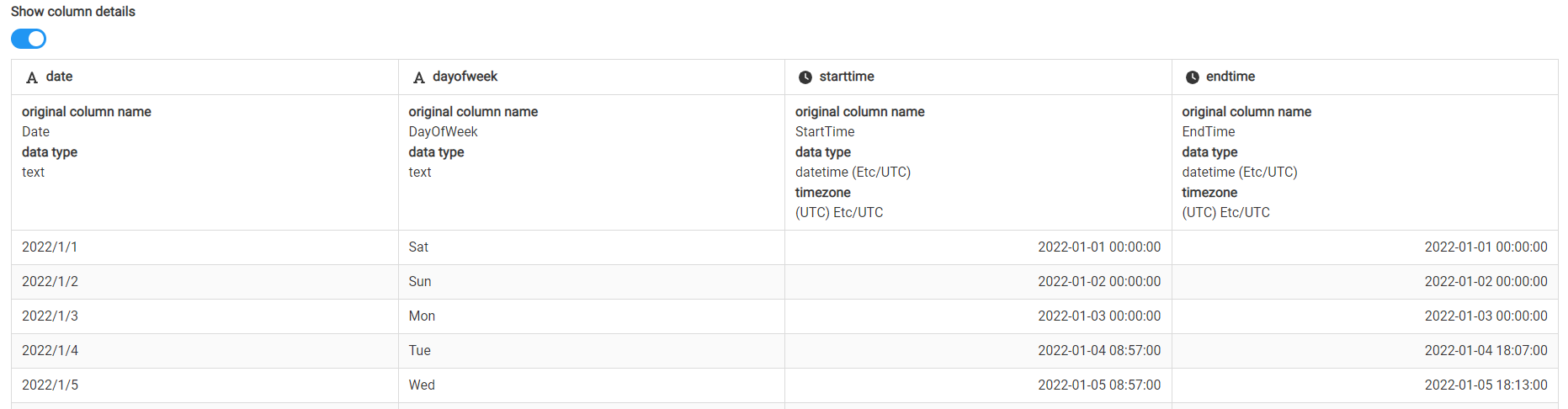 |
|---|
5.自分自身の残業時間を分析する
さて、本節ではいよいよSQLをたたいて、残業時間を分析してみたいと思います!
再掲となりますが、対象のデータは自分自身の2022年1月~4月の業務実績で、
各列は左から日付、曜日、業務開始時刻、業務終了時刻となっています。
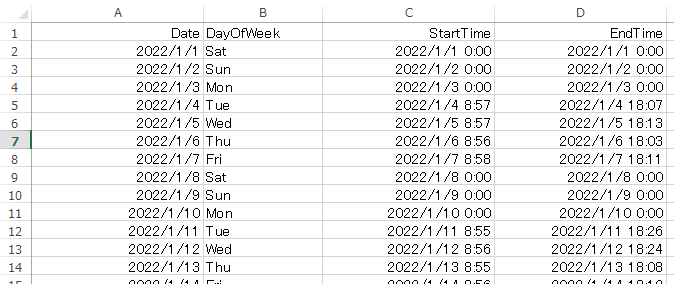 |
|---|
5.1.四か月間の平均を計算してみる
まずは、平均的に毎日どのくらい残業しているか計算してみたいと思います。
5.1.1.データセットの管理画面から、「Show example query」を選択します。
 |
|---|
5.1.2.以下のSQL文をコピペし、「Run Query」を選択します。
※定時は9:00~18:00(休憩1時間含む)のため、DATETIME.DIFF_MINUTEの結果から540分(9時間)を引き、残業時間を出しています。
※データには休日が含まれているので、WHERE句で開始時刻の時間が「0」であるものを除外しています。
SELECT
AGGREGATE.AVG(overtime)
FROM(
SELECT
t.date,
t.dayofweek,
t.starttime,
t.endtime,
DATETIME.DIFF_MINUTE(t.starttime , t.endtime) - 540 AS overtime
FROM
[spectaclesdeformation367/Attendance/202201-202204.csv] t
WHERE
DATETIME.EXTRACT_HOUR(t.starttime) > 0
)
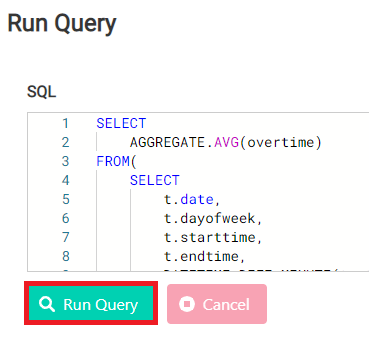 |
|---|
5.1.3.「Result」タブを選択し、結果を確認します。
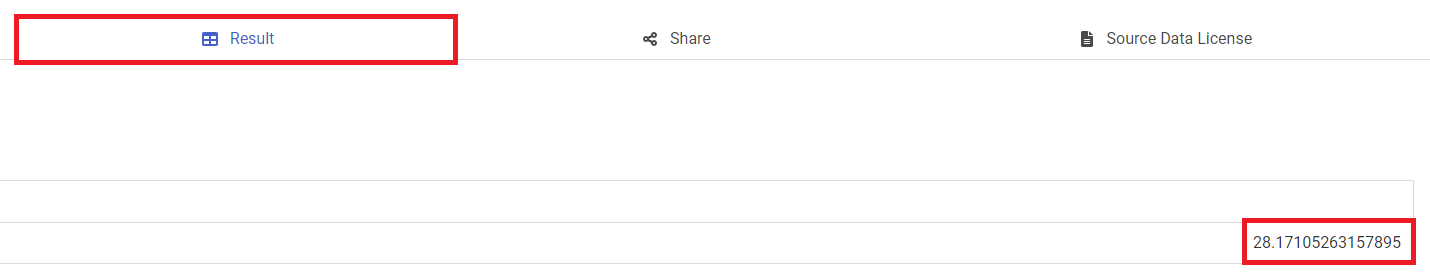 |
|---|
毎日約28分残業しているという結果となりました!(他の人と比べて少なめ・・・なはず?)
5.2.月ごとの残業時間を計算してみる
次は月ごとの残業時間を計算してみて、どうなるか試してみます。
5.2.1.先ほど記載したSQL文のWHERE句を以下のように変更します。
※「'%/1/%'」の部分で1月だけに限定しています。
WHERE
DATETIME.EXTRACT_HOUR(t.starttime) > 0
AND t.date LIKE '%/1/%'
5.2.2.先ほどと同様にSQLを実行します。
5.2.3.同様に2,3,4月のSQLも実行します。
5.2.4.結果を以下に記載します。(平均残業時間は小数点第一位で四捨五入しています。)
| 項目 | 平均残業時間(分) |
|---|---|
| 全体 | 28 |
| 1月 | 27 |
| 2月 | 30 |
| 3月 | 31 |
| 4月 | 24 |
全体の平均と比べて、月ごとの平均もあまり変わらないということが分かりました!
5.3.曜日ごとの残業時間を計算してみる
次は曜日ごとの残業時間を計算してみて、どうなるか試してみます。
5.3.1.先ほど記載したSQL文のWHERE句を以下のように変更します。
※「'Mon'」の部分で月曜日だけに限定しています。
WHERE
DATETIME.EXTRACT_HOUR(t.starttime) > 0
AND t.dayofweek = 'Mon'
5.3.2.先ほどと同様にSQLを実行します。
5.3.3.同様に火曜日~金曜日のSQLも実行します。
5.3.4.結果を以下に記載します。(平均残業時間は小数点第一位で四捨五入しています。)
| 項目 | 平均残業時間(分) |
|---|---|
| 全体 | 28 |
| 月曜日 | 46 |
| 火曜日 | 11 |
| 水曜日 | 21 |
| 木曜日 | 34 |
| 金曜日 | 33 |
おっ、少し偏りが出てきました。
平均化すると、月曜日が最も残業が多く、火曜日が最も少ない結果となりました。
ではなぜこの結果になったかですが、
月曜日は土日で休んで回復しているので、残業が多くなりがち(仕事する元気がある)で、
火曜日は月曜残業したのでその反動で、早く終わっているのではないかと考えています。
自分自身は、意識的に月曜日に残業しようとしたり、火曜日に残業抑えようとは考えていないので、意外な結果でした♪
(月曜日は残業減らすようにします・・・)
6.おわりに
ここまで読んで下さり、ありがとうございます!!!
(^^)
全体、月ごと、曜日ごとで分析してみて、曜日ごとで結果が分かれたのが以外でした。
他の人のデータを使うとまた違う結果になると思うので、是非皆さんも試してみてください♪
(:3_ヽ)_