Houdini Apprentice Advent Calendar 2021、22日目の記事。
尚ここでのデータベースとは比喩でありデータを蓄積する場所、くらいの意味合いである。
分かる人向けにタイトルをより正確に言い換えると、Houdiniを3D版BIツールとして使ってみようとした 辺りが妥当か。
日頃の作業をHoudiniで再現しようとしたという話なので、ノードや関数的にそもそもの用途ではないとか、より適切な書き方があるといった場合はご指摘頂けると大変助かります。
導入
題材: この記事で目指すところ
これ。
(というのを3通りの見せ方で切り替えている)Mapbox経由でHoudiniに読み込んだマップに緯度経度情報をキーに建物名を紐付け、建物名をビル上に表示し建物間の最短経路検索を実施するテスト
— シント (@shin_t_o_) December 21, 2021
attributeを元にプルダウンリストを作成しているので、動的な経路変更もできる pic.twitter.com/1HqDNdI5CP
とかこれ。
(今回はダミーデータを入れているが、保持できればこういう可視化もできるよ、という事例であってデータ自体の妥当性は問題ではない)特定のattribute値を元に分布の可視化をしてみるテスト スポットごとのfloat値なので混雑率とか消費電力とかが対象になるんかな
— シント (@shin_t_o_) December 21, 2021
リアルタイムで取得してアニメーション出来たらかっこ良さそう pic.twitter.com/pTYBfikzRj
或いはこれ。応用編。
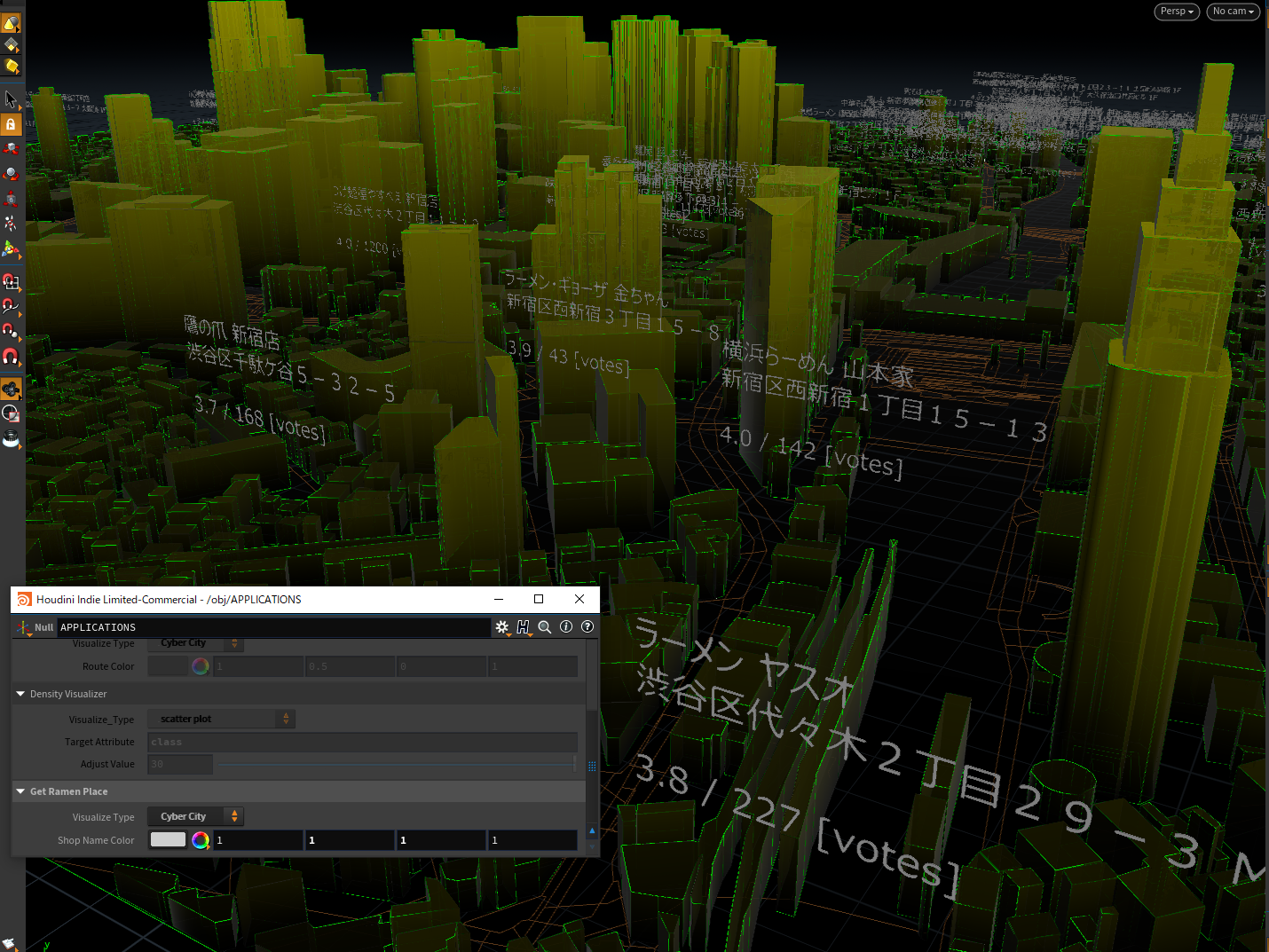
Google Maps PlatformのPlaces APIを元に緯度経度情報をベースに「ラーメン」でスポット情報を検索しておいて、Mapboxデータに紐づけたのちに店舗位置にお店情報を表示してみる、のやつ。
これら一連のツールを「Applications」という括り(のただのフォルダ分けだが)でまとめている。
要は 可視化のために足りない情報があれば、外から持ってきてattributeにくっつけてしまえ をやってみたという記事。
逆に言えば、 データを保持しているなら、それを利用したツール(単なるノード群でもHDAでも、モジュールでもアプリケーションでも良い)は好きなだけ作成できる。 Applicationと名付けたのはそういう背景がある。
去年の記事1に引き続きMapboxデータを利用しているが、それ自体に必然性はない。
【 3D × Data × Visualize 】に長らく興味があり、Houdini+Mapboxがデータテーブル的にとても扱いやすいのが主な理由。
いずれにしても、とある(長期的な)趣味プロジェクトの構成要素の1つという位置づけ。
例によって分量が増えすぎてこれ自体の解説はほぼ無い――――のだが、「既にあるデータをどう可視化するか」のチュートリアルは先駆者のおかげで豊富にあるので、そのデータをどう集めるかに主眼を置いている――――ということにしたい。
題材の起源: 目指していた方向性
限られた時間で目標物を表現できるほどの力が無かったので、動画の力を借りる。
中国のテクノロジー企業であるTencent社が、同社が開発した都市のデジタル・ツインが、健康問題の把握、大規模な公共イベントの監視、地域資源の確保などにどのように活用されているかを紹介しています(概要欄DeepL翻訳)
とされている此方の動画。
所謂デジタルツインだとかBIMだとかスマートシティだとか呼ばれる世界に近い思想なのかなと思っている。
後述するが、 可視化したい対象やアプリケーション等を作りたいとなったときに、それらで利用されるデータが格納・保持されているかどうか が重要となる。これは分析タスク全般で言える。
また、下記の2つの記事は大きなモチベーションを頂いた。
・@hasegawa_tさんによる HoudiniでData Visualization
・@jhorikawa_errさんによる Houdini+ローカルDB〜Qt+SQLiteを使った簡易システム構築〜
ところでお前は何者か
普段の業務でHoudiniを使うことはなく、趣味の範囲で触る程度なので知識にだいぶ偏りがある。
そもそもCG分野の業務からも長らく離れており、直近半年はとある機械学習案件の予測モデル構築やクレンジングワークフロー整備、バックエンドのヘルプ等を行っていた。
Houdini本来の用途であるレンダリングやマテリアル、シミュレーションの知識は皆無。
実行環境
環境構築含め詳細は補足項に記載しているので、ここでは簡易的なものを。
(因みにPythonコード自体は我流で覚えたので結構汚いところが多いはず)
OS : Windows 10
Houdini : Houdini Indie 19.0.383 (記事内でIndie要素無し)
Python : 3.7.4
Project Manager: pyenv 3.7.4 + poetry
HIPファイル / HDAファイル / その他コード
下記に適宜アップロード予定。
記事作成タイミングで例外処理が追い付かなかったため、完了次第順次追加していく想定。
関連ファイル
取り敢えず本題に。
[1] Houdiniで外部データを取り込んでみる: data_importer HDA
え、何で?スタイリッシュな画を創るんじゃなかったの?
現実ってのは泥臭いんだ。良いからやるんだ。
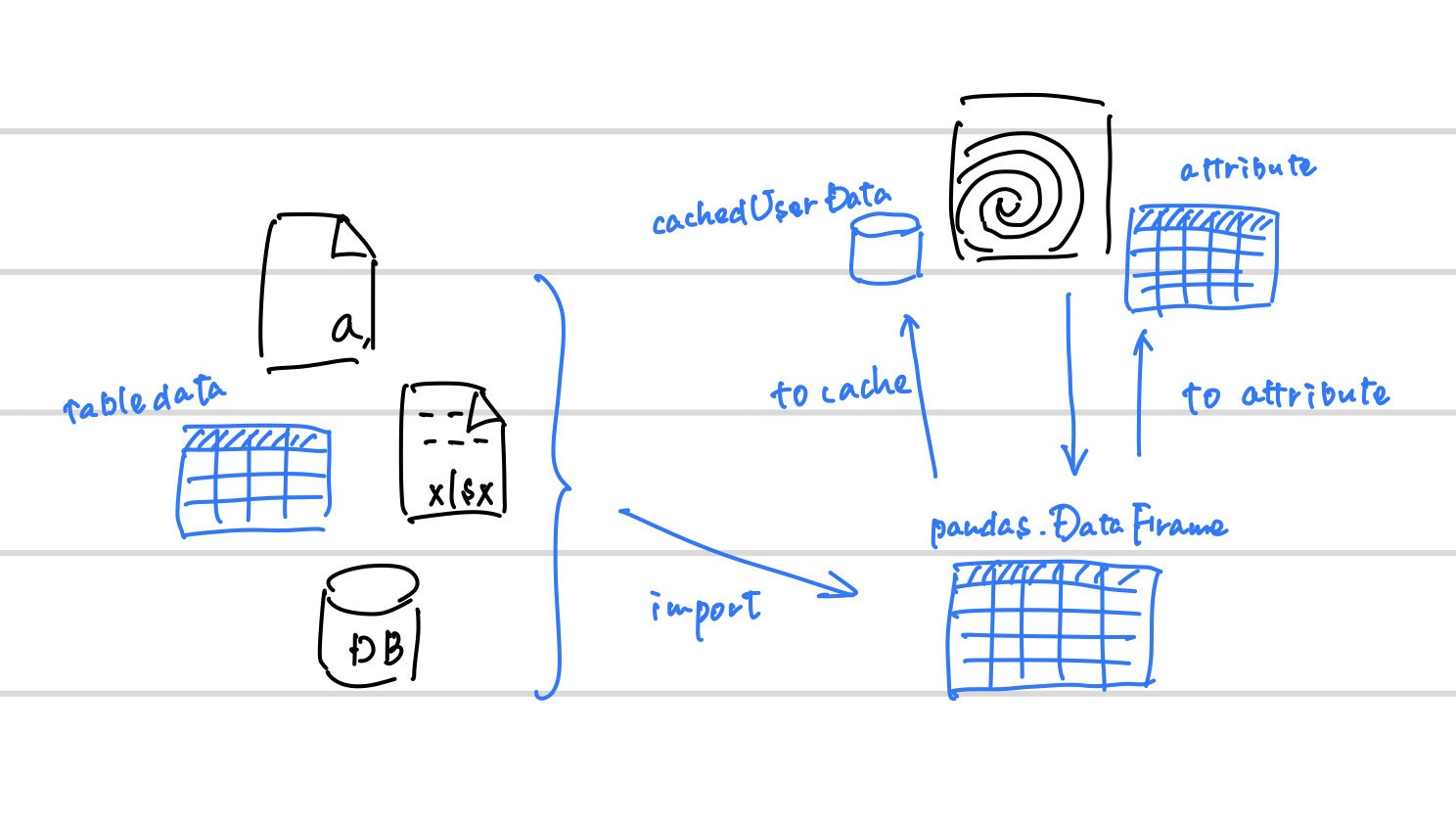
(1) 必要情報を入力後に各種データソースに接続し、
(2) (そのまま(point | prim attribute)に | ローカルキャッシュデータに) 格納する
の各パターンを選べる data_importer というHDAを作成する。
こんなイメージで。
(1) データへの接続
今回想定したデータソースは取り急ぎCSVファイル、Excelファイル、PostgreSQLの3通り。
一応補足しておくが、現時点で「どのデータソースに接続できるか」自体は重要ではない。上記3つである必然性もない。
Pythonで書くなりその他ノードを呼び出せばいい話なので、接続先パターンは必要に応じて追加可能。
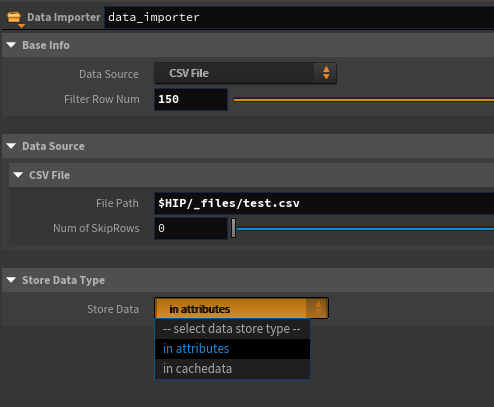
CSVデータの取り込み
既に Table Import SOP というノードが存在するわけだが、今回作ろうとしているのはこれの拡張版のためCSV取り込みも自作する。
簡易実装のため、設定可能な項目は本家ノードよりも少ない。
# Data Source: CSV File を選択時に呼ばれる関数
def read_csv() -> pd.DataFrame:
return pd.read_csv(
hou.ch("../csv_filepath"),
skiprows=hou.ch("../csv_skiprows"),
# encoding="cp932", # エンコーディング周り絶賛苦戦中なので仮置き
# header=None, # 設定項目を増やすならこういう項目、の案
)
HDAのガワはこんな感じ。
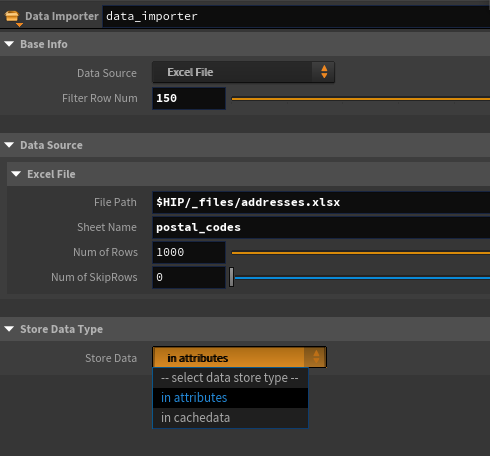
Excelデータの取り込み
# Data Source: CSV File を選択時に呼ばれる関数
def read_excel() -> pd.DataFrame:
return pd.read_excel(
hou.ch("../excel_filepath"),
sheet_name=hou.ch("../excel_sheetname"),
skiprows=hou.ch("../excel_skiprows"),
# nrows=hou.ch("../excel_nrows"),
# header=None,
)
HDAのガワはこんな感じ。
PostgreSQLデータの取り込み
def read_postgres() -> pd.DataFrame:
""" PostgreSQL実行用
"""
conn_conf: dict = {
"host": hou.ch("../host"),
"port": hou.ch("../port"),
"dbname": hou.ch("../dbname"),
"user": hou.ch("../user"),
"password": hou.ch("../password"),
}
_flg = get_blank_flg(conf=conn_conf)
# host, port, ... の各設定箇所に値が入ると接続処理開始
if _flg:
_conn = get_conn(conf=conn_conf)
return pd.read_sql(
sql="SELECT * FROM " + hou.ch("../postgres_table") + " limit" + str(hou.ch("../data_size")) + ";",
con=_conn
)
else:
return None
HDAのガワはこんな感じ。
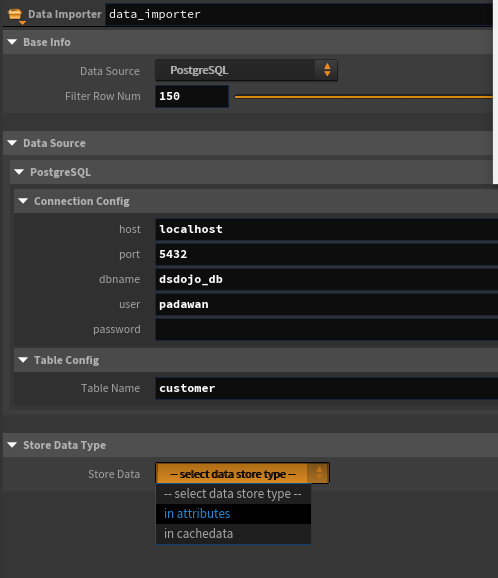
本題とは関係ないが、データサイエンス100本ノック 内のDockerでたまたまPostgreSQLが立ち上がっていたのでその時の設定情報が入っている。
(2) データの格納
3つほど事例を挙げ、pandas.DataFrame という二次元の表形式データ(=テーブルデータ)を表す型にして返却する関数を書いた。余談だが日々のデータ加工でも、DataFrameに取り敢えず取り込んでから各種処理や計算、可視化という流れをしょっちゅう繰り返している。
次章の「データの結合」を考えたときに、全てをattributeベースで考えても良いのだが…
- 表データの編集はDataFrameで行う
- 一通りの編集がおわってからattributeに反映する
方針のが軽量で良さそう。
いずれにしても(適用タイミングの違いで)両方必要となるのでそれぞれまとめる。
attributeへの格納
此方は @hasegawa_t さんの【Houdini】PythonSOPでのデータ読み込みコードの最適化 に於けるhoupandasをほぼそのまま使わせて頂いた。
参考リンク集と区別して直接紹介させて頂く。
何故か私の環境では特定のカラムのdtypeがint, boolの場合にset_attrib_value()部でエラーが生じてしまったため、あまり綺麗ではないが下記に書き換えて運用した。幾つかのデータで試してみたがどうも型判定周りでエラーを起こす頻度が高く、分岐処理をもっと増やさないといけなそう。
def set_attrib_value(self, points, attrib_dict, debug=False):
- for row, point in enumerate(points):
- for column in attrib_dict.keys():
- attrib_value = self.at[row, column]
+ for column in attrib_dict.keys():
+ for point, attrib_value in zip(points, self[column].__iter__()):
ローカルキャッシュデータへの格納
前述の
表データの編集はDataFrameで行う
のために、hou.Nodeクラスでノードを跨いだキャッシュデータを一時的に保存するsetCachedUserData を採用してみた2。
コードは次項で載せるとして、ここではdocsの文章を引用する。
このノードインスタンス上に名前付き値を追加/設定します。 setUserDataとは違い、このメソッドを使用した値セットは、HIPファイルと一緒に保存されません。
(中略)
この名前/値のペアは、HIPファイルと一緒に保存されません。 クック間で一時的な値を保存するPythonで実装されたノードは、その後のクックに対してそれらを再計算しないようにするのに役に立ちます。
全体
今回開通を最優先としたかなりの簡略版なので、例外は確認次第修正というハリボテ感溢れるコードになっている。
データバリデーションをほぼ掛けておらず、実運用を考えるとまだまだ分岐処理が増えることが想定される。
database_importer 全体コード
import numpy as np
import pandas as pd
import unicodedata as ud
import psycopg2
# 適切な場所に配置してimport
import houpandas as hp
node = hou.pwd()
geo = node.geometry()
# ======================
# general function
# ======================
def can_start_to_process() -> bool:
return (
hou.ch("../datasource")!="default_val" and
hou.ch("../store_data_in")!="default_val"
)
def check_columns_is_valid(columns: list) -> bool:
for col in columns:
if ud.east_asian_width(col[0])!="Na":
return False
return True
# ======================
# data extractors
# ======================
# select nothing
def return_default():
return None
# PostgreSQL
def get_conn(conf: dict):
return psycopg2.connect(**conf)
def get_blank_flg(conf: dict) -> bool:
""" 設定情報が全て埋まっていればTrue / それ以外はFalse
"""
return np.array(conf.values()!="").all()
def read_postgres() -> pd.DataFrame:
""" PostgreSQL実行用
"""
conn_conf: dict = {
"host": hou.ch("../host"),
"port": hou.ch("../port"),
"dbname": hou.ch("../dbname"),
"user": hou.ch("../user"),
"password": hou.ch("../password"),
}
_flg = get_blank_flg(conf=conn_conf)
# host, port, ... の各設定箇所に値が入ると接続処理開始
if _flg:
_conn = get_conn(conf=conn_conf)
return pd.read_sql(
sql="SELECT * FROM " + hou.ch("../postgres_table") + " limit" + str(hou.ch("../data_size")) + ";",
con=_conn
)
else:
return None
# CSV File
def read_csv() -> pd.DataFrame:
return pd.read_csv(
hou.ch("../csv_filepath"),
skiprows=hou.ch("../csv_skiprows"),
# encoding="cp932",
# header=None,
)[: hou.ch("../data_size")]
# Excel File
def read_excel() -> pd.DataFrame:
return pd.read_excel(
hou.ch("../excel_filepath"),
sheet_name=hou.ch("../excel_sheetname"),
skiprows=hou.ch("../excel_skiprows"),
# nrows=hou.ch("../excel_nrows"),
# header=None,
)[: hou.ch("../data_size")]
# ======================
# composite functions
# ======================
# "Data Source" selector -> return dataframe
def get_datasource(source: str):
switcher: dict = {
"default_val": return_default,
"postgresql": read_postgres,
"csv_file": read_csv,
"excel_file": read_excel
}
return switcher[source]
# check dataframe before return
def data_checker(df: pd.DataFrame) -> pd.DataFrame:
""" 後続処理に渡す前に諸々チェック
1. カラム名がアルファベットのみでなければエラー終了
2. カラム名が大文字の場合小文字に変換
処理追加時はこの関数内に追加
"""
# 1.
if not check_columns_is_valid(df.columns):
raise AttributeError("Columns must be alphabets.")
# 2.
df.rename(columns=str.lower, inplace=True)
return df
# ======================
# MAIN part
# ======================
if can_start_to_process():
# check dataframe before make attributes
raw_df: pd.DataFrame = data_checker(
# data extract -> filter df size
df=get_datasource(source=hou.ch("../datasource"))()
)
# select data store type
if hou.ch("../store_data_in")=="in_attributes":
# dataframe -> houdataframe
df: hp.HouDataFrame = hp.HouDataFrame(raw_df)
# houdataframe -> houdini attributes
df.to_geometry(geo)
print("set attributes from data source.")
elif hou.ch("../store_data_in")=="in_df_cache":
# dataframe -> session cache data
cache_node = hou.node("../..")
cache_node.setCachedUserData(hou.node("../").name(), raw_df)
print("set cachedUserData from data source.")
[2] 取り込んだデータ群を結合してみる: df_merge HDA
まず作る
説明は後回しにして、まず作る。
前章にてローカルキャッシュデータにpoint|prim attributeをDataFrame形式で保存したが、ここでは「それを取り出して結合し再度キャッシュデータに保存する/attributeに戻す」HDAを作成する。
一見ややこしいが、要は内部で pandas.merge() 3 4を実行するだけのHDAとなる。
ExcelでVLOOKUP/XLOOKUPを実行したことがある人はイメージが付きやすいと思うが、各所で集めたデータ同士を紐付ける必要がある場面は少なくない。SQLにおけるJOINのpandas版、で通じる人も居るかもしれない。
参考リンクのほうが参考になるので、需要があるか解らないが図解。
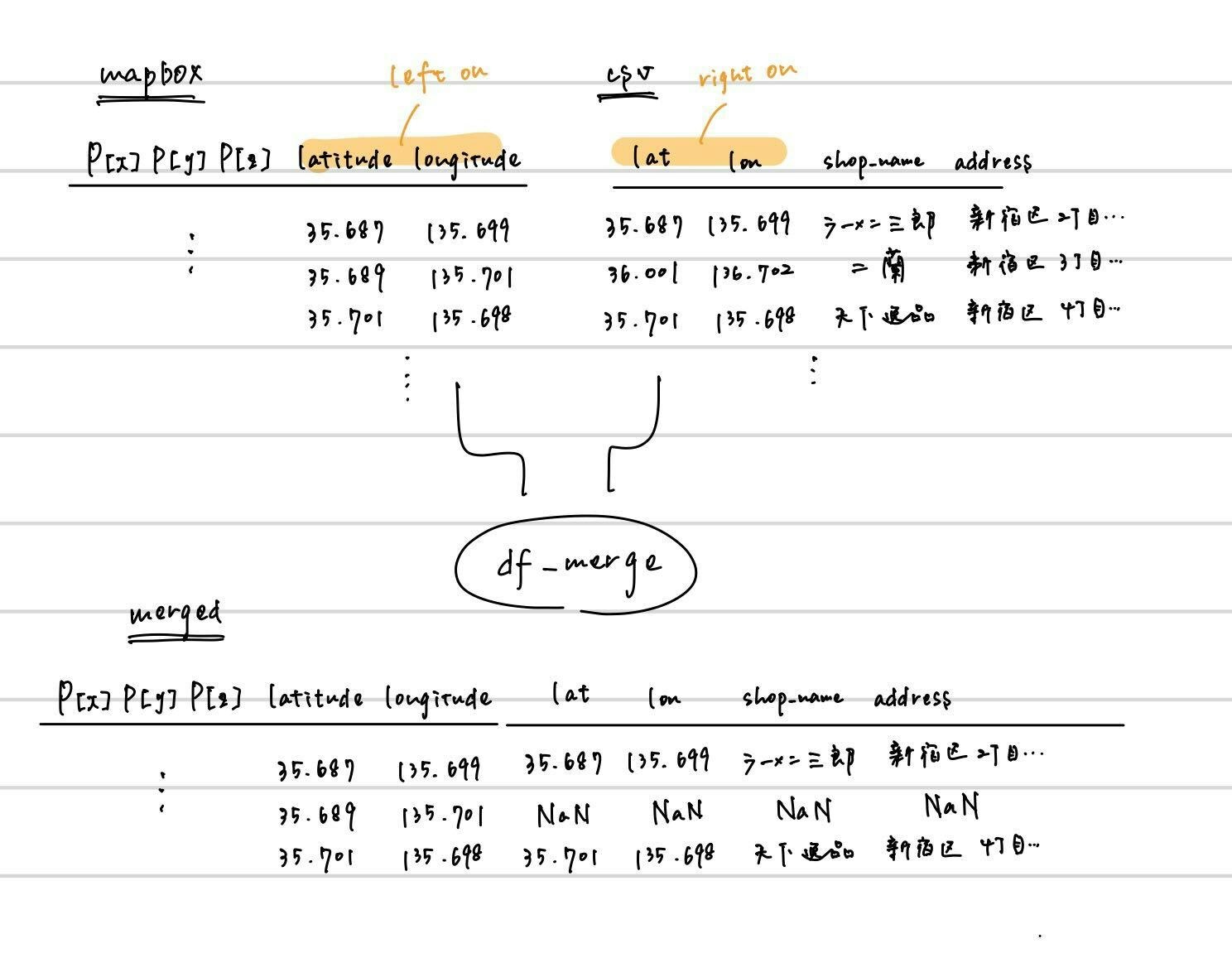
実行するだけ…と言いつつ場合分けをしていたら結構なボリュームになってしまった。
めちゃくちゃ汚いので要改修。一応貼るだけ貼っておく。
df_merge 全体コード
import pandas as pd
import houpandas as hp
node = hou.pwd()
geo = node.geometry()
n = hou.node("../..")
# 処理開始用判定フラグ
_flg: bool = (
hou.ch("../df_left")!="left_default"
and hou.ch("../merge_left_on_01")!="merge_left_on_default"
and hou.ch("../df_right")!="right_default"
and hou.ch("../merge_right_on_01")!="merge_right_on_default"
and hou.ch("../merge_type")!="mrege_default"
)
# 全ての設定値についてBool判定をするのが面倒なのでここでまとめて
if _flg:
# 結合対象DataFrame
df_left: pd.DataFrame = n.cachedUserData(hou.ch("../df_left"))
df_right: pd.DataFrame = n.cachedUserData(hou.ch("../df_right"))
# JOIN KEYの作成
_on_l1: str = hou.ch("../merge_left_on_01")
_on_l2: str = hou.ch("../merge_left_on_02")
_on_r1: str = hou.ch("../merge_right_on_01")
_on_r2: str = hou.ch("../merge_right_on_02")
# KEYの数によりstr, listで分岐
if _on_l2!="merge_left_on_default":
_on_l = [ _on_l1, _on_l2 ]
else:
_on_l = _on_l1
if _on_r1!="merge_right_on_default":
_on_r = [ _on_r1, _on_r2 ]
else:
_on_r = _on_r1
# 桁数調整
if hou.ch("../l_round_01"):
df_left[_on_l1] = round(df_left[_on_l1], int(hou.ch("../l_round_val_01")))
df_right[_on_r1] = round(df_right[_on_r1], int(hou.ch("../r_round_val_01")))
if hou.ch("../l_round_02"):
df_left[_on_l2] = round(df_left[_on_l2], int(hou.ch("../l_round_val_02")))
df_right[_on_r2] = round(df_right[_on_r2], int(hou.ch("../r_round_val_02")))
# 型調整
if hou.ch("../l_cast_01"):
df_left[_on_l1] = df_left[_on_l1].astype(str(hou.ch("../l_cast_type_01")))
df_right[_on_r1] = df_right[_on_r1].astype(str(hou.ch("../r_cast_type_01")))
if hou.ch("../l_cast_02"):
df_left[_on_l2] = df_left[_on_l2].astype(str(hou.ch("../l_cast_type_02")))
df_right[_on_r2] = df_right[_on_r2].astype(str(hou.ch("../r_cast_type_02")))
raw_df: pd.DataFrame = pd.merge(
df_left,
df_right,
left_on=_on_l,
right_on=_on_r,
how=hou.ch("../merge_type")
)
# この辺りは使いまわし
if hou.ch("../store_data_in")=="in_attributes":
# dataframe -> houdataframe
df: hp.HouDataFrame = hp.HouDataFrame(raw_df)
# houdataframe -> houdini attributes
df.to_geometry(geo)
print("set attributes from data source.")
elif hou.ch("../store_data_in")=="in_df_cache":
# dataframe -> session cache data
cache_node = hou.node("../..")
cache_node.setCachedUserData(hou.node("../").name(), raw_df)
print("set cachedUserData from data source.")
ノードの見た目としてはこんな感じ。
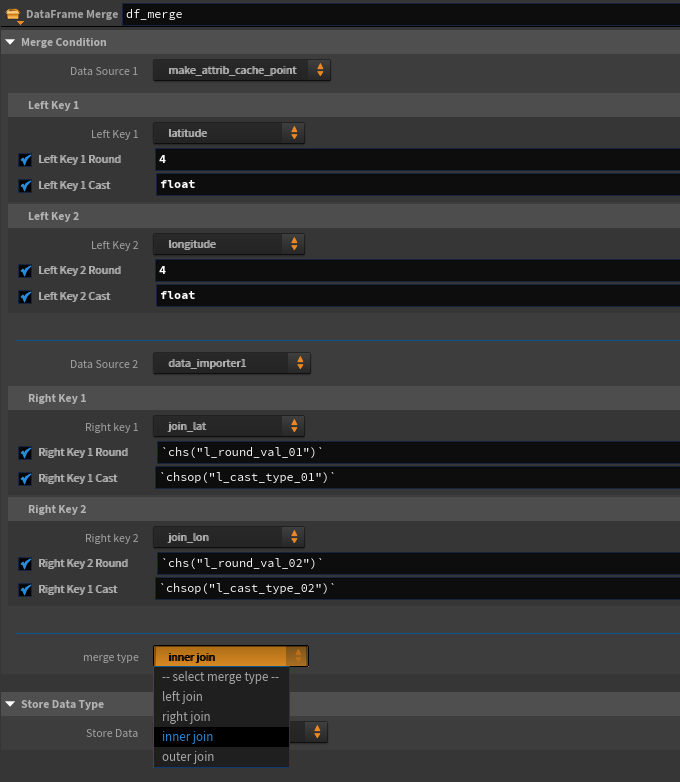
なおKeyのプルダウンは選択したデータソースのattribute / カラムのリストが入るように、下記のようなMenu Scriptを組んでいる。
# ----------------------
# メニューの例(1)
# ----------------------
# キャッシュデータに保存されているデータたちを呼び出してメニューに追加
n = hou.node("..")
menu = []
menu += ["left_default", "-- select data source --"]
for item in n.cachedUserDataDict().keys():
menu += [item, item]
return menu
# ----------------------
# メニューの例(2)
# ----------------------
# 例1で呼ばれたキャッシュデータが持っているカラムを呼び出しメニューに追加
menu = []
menu += ["merge_left_on_default", "-- select merge key --"]
try:
n = hou.node("..")
df_left = n.cachedUserData(hou.ch("./df_left"))
for column in df_left.columns:
menu += [column, column]
return menu
except AttributeError:
return menu
[3] 実例としてMapboxデータと他所のデータをぶつけて可視化する
ここからが本題な訳だが、分量が多すぎるので分割することに。。
-> 次記事: Houdiniのattributeをデータベースにして都市データを扱ってみる(2. 解説・余談編)