元々は 前回の1記事 で終わらせる予定だったが、あまりに分量が増えたため分割することにした。
早速本題から。
[3] 実例としてMapboxデータと他所のデータをぶつけて可視化する
BIツールで見る可視化の手順
前回よく使い道も解らぬままHDAを作ってきたが、これは一体何のためにあるのか。
一旦Houdiniを離れ、或る「2次元の」可視化タスクを「BIツールを使って」実現する例に挙げて考えてみる。
例示のためにデータを集めてくるのもしんどいので、Tableauのサンプルを使わせてもらう。
これを手持ちのBIツールで実現しようとするとこうなる(飽く迄やり方の一例)。
例えばこういったマグニチュード別地震分布を作成したいとなった場合。
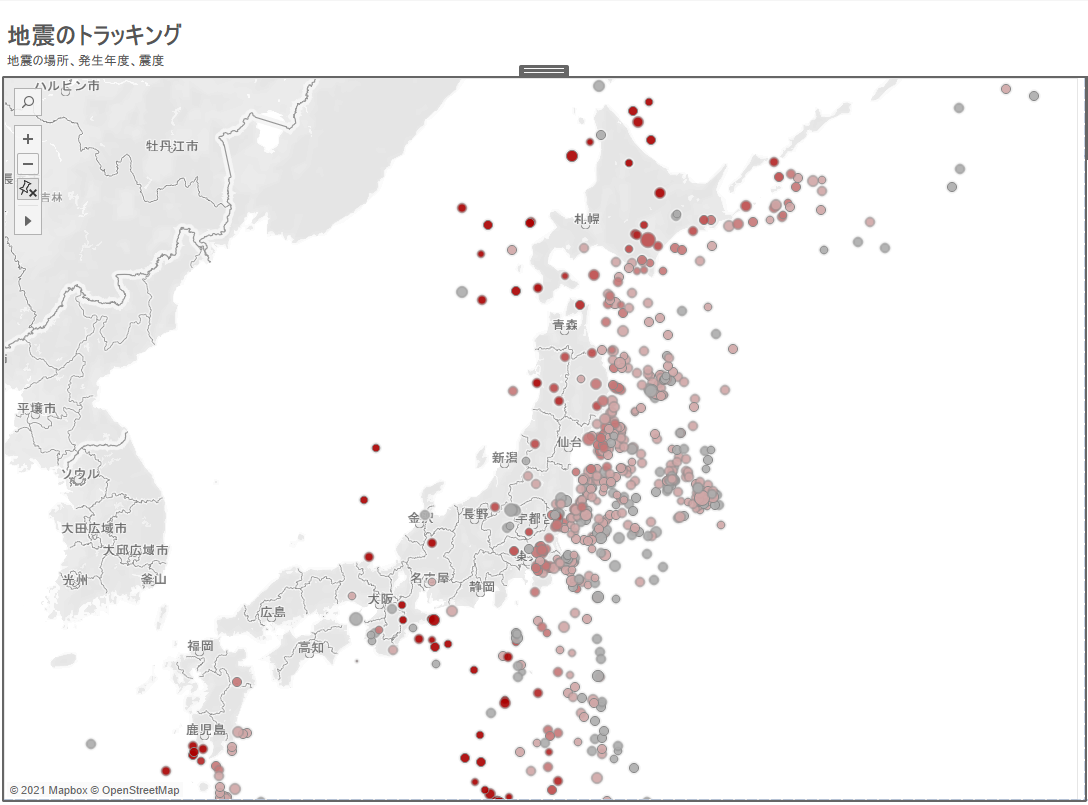
そしてググった結果、
・地震の発生日付・緯度経度情報・場所名のデータはある
・地震の発生日付・緯度経度情報・マグニチュードのデータはある
・なのにそれらが紐づいたデータがない…
みたいな状況だったとする(あくまで想定の話)。
それらのデータをそれぞれ持ってきて紐づけなければいけない。
そして持ってきたデータはけっこう汚いらしい…場所名に要らん半角入ってるし、緯度経度の値の桁数はばらばらだし、…
となると、「可視化するためのデータを結合・加工(=クレンジング)」するフェーズが必要になる。
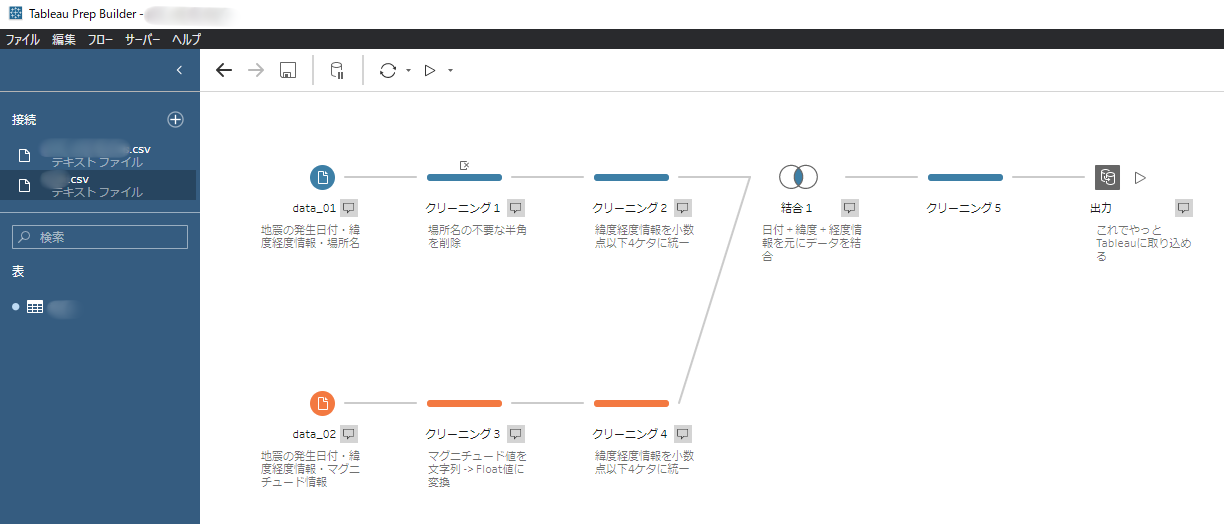
改めてこのデータをTableau Desktopに取り込んで、地図データ形式にして発生場所をプロット、マグニチュード値の大きさでグラデーションを指定すればOK、みたいな話。
詳細な手順はBIツールによって異なるし、別にBIツールを使わなくてもPythonだとかRとかで実現できるのでイメージの参考程度に。
ここで注意すべきは 思考の順序としては「完成イメージ -> 必要なデータの準備」だが、実際の作業としては「必要なデータの準備 -> 可視化」だという点。
前回作成したHDAはHoudiniにとってのこの「必要なデータの準備」機能を拡張するもの、みたいな位置づけになる。
さて、これを「3次元に」拡張し、「Houdini(と作成したHDA)を使って」やってみた、というのが今回の話。
今回作成したHDAを用いた可視化の手順
もうすでにけっこうお腹いっぱいな感じがあるので、ラーメンの事例だけ軽く説明する。
Google Maps PlatformのPlaces APIは、Google Map上のデータを取得できるAPIの1つ。
Google Maps Platformから事前にデータを収集
その中でもNearby Search1は「或る指定位置(緯度経度)や指定半径を元に、特定のワードの検索結果を表示する」API。
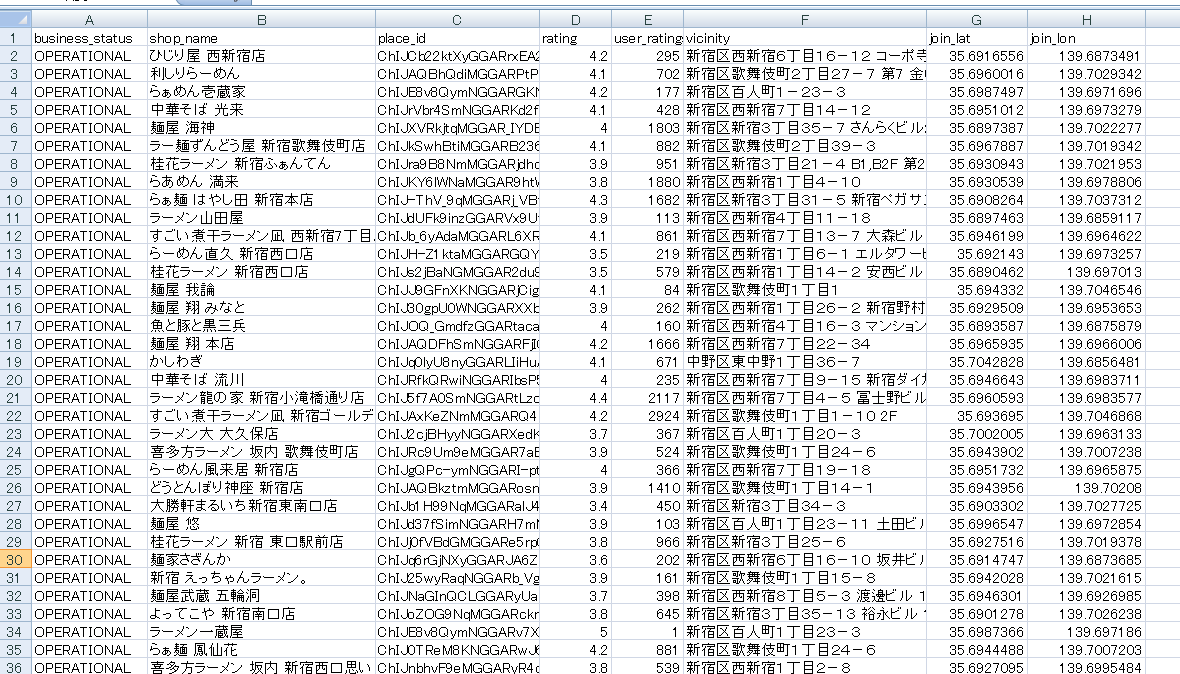
これを元に、事前に新宿駅周辺のラーメン屋の情報をゲットしcsvに保存しておく(登録方法や使い方は各種参考サイトを確認のこと2 3 4)。
因みに保存したデータはこんな感じ。
作成したHDAを用いてMapboxデータと紐づけ
有難いことに、Mapbox経由データは緯度・経度情報を持っている。
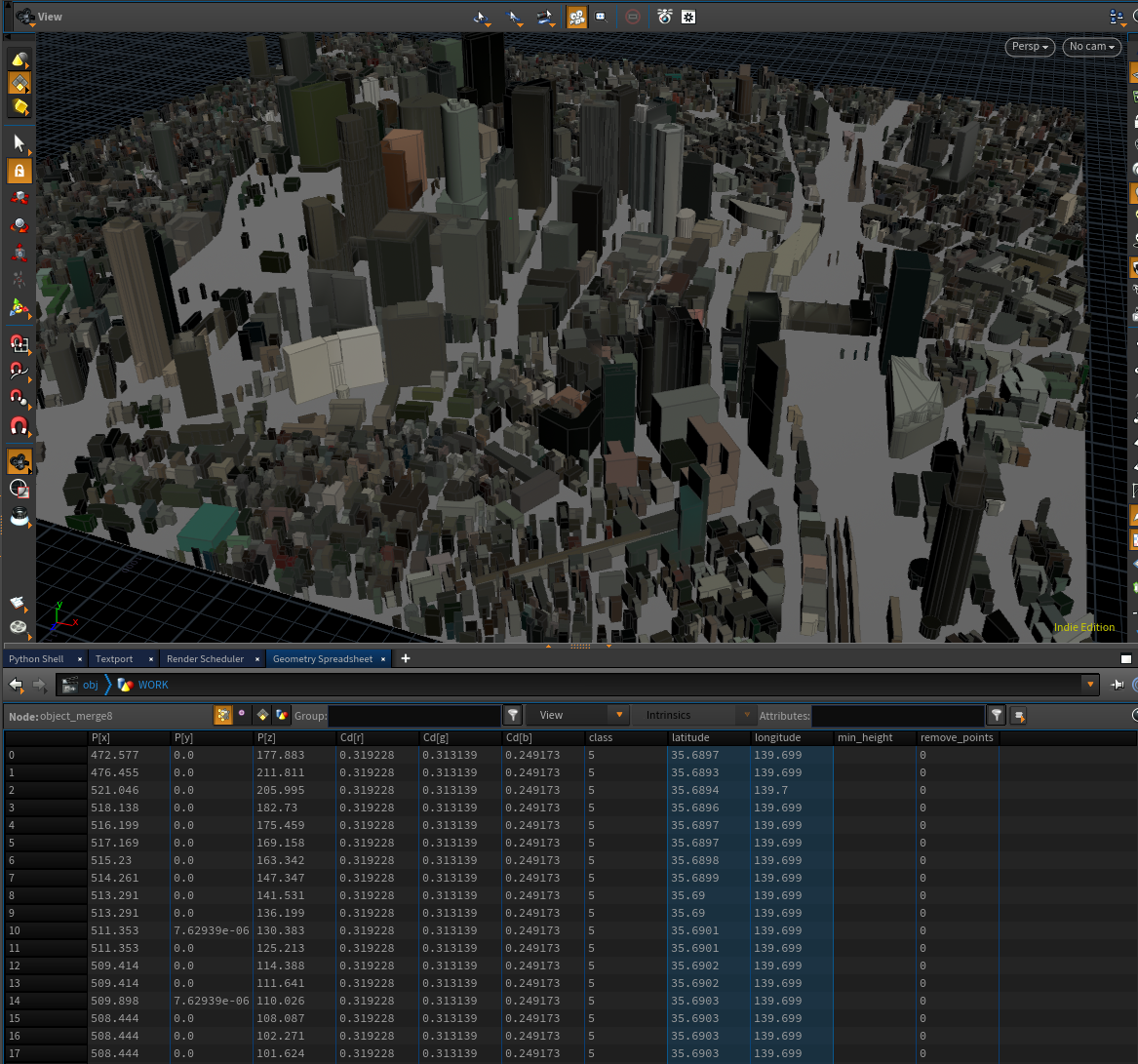
なのでそれを一旦DataFrameに変換、キャッシュに保存し、ラーメンデータcsvを読み込んだDataFrameと結合する。
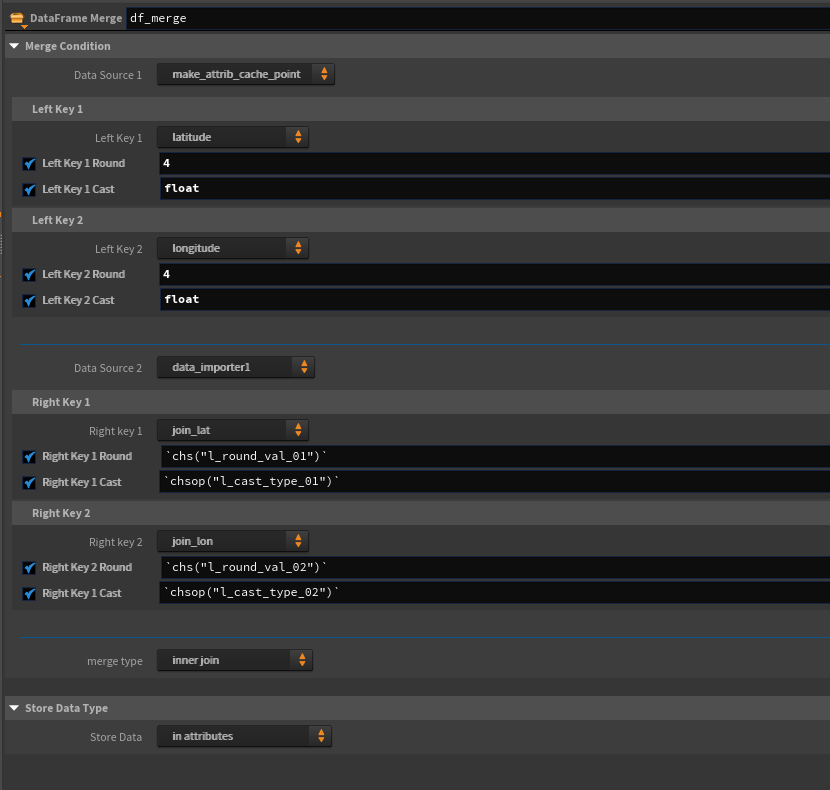
(本当は緯度経度を用いた結合は精度の問題があるのであまりやりたくないが、他に紐づけられるキーがない。。)
(Google Maps Platform側で保持している place_id という概念は素晴らしいと思った。可能ならどの情報も全てこれで紐づけたい)
補足・余談
Houdini + Python実行環境
今回poetryのお試しも兼ねて、此方の記事5を参考にさせて頂きvenv内に必要なものを導入した。
自分の場合 $HOUDINI_PATH/scripts/456.py は下記で置き換えている。
site_packages_path = hou.text.expandString("$HIP/.venv/Lib/site-packages")
執筆時点で追加したpackageは以下
pandas
numpy
openpyxl
psycopg2
jupyter
jupyterに関しては普段の癖で、「取り敢えず叩いてみる」を実行しやすいので入れている。導入は必須ではない。
BIツールとは
或る種の高機能Excelのようなデータ整備/可視化用のソフトウェアといったところ。
私個人、そのツール群でもTableauというソフトウェアを長く利用していて、Houdiniでも似たようなこと出来ないかなという切り口でこの記事を書いてみた。
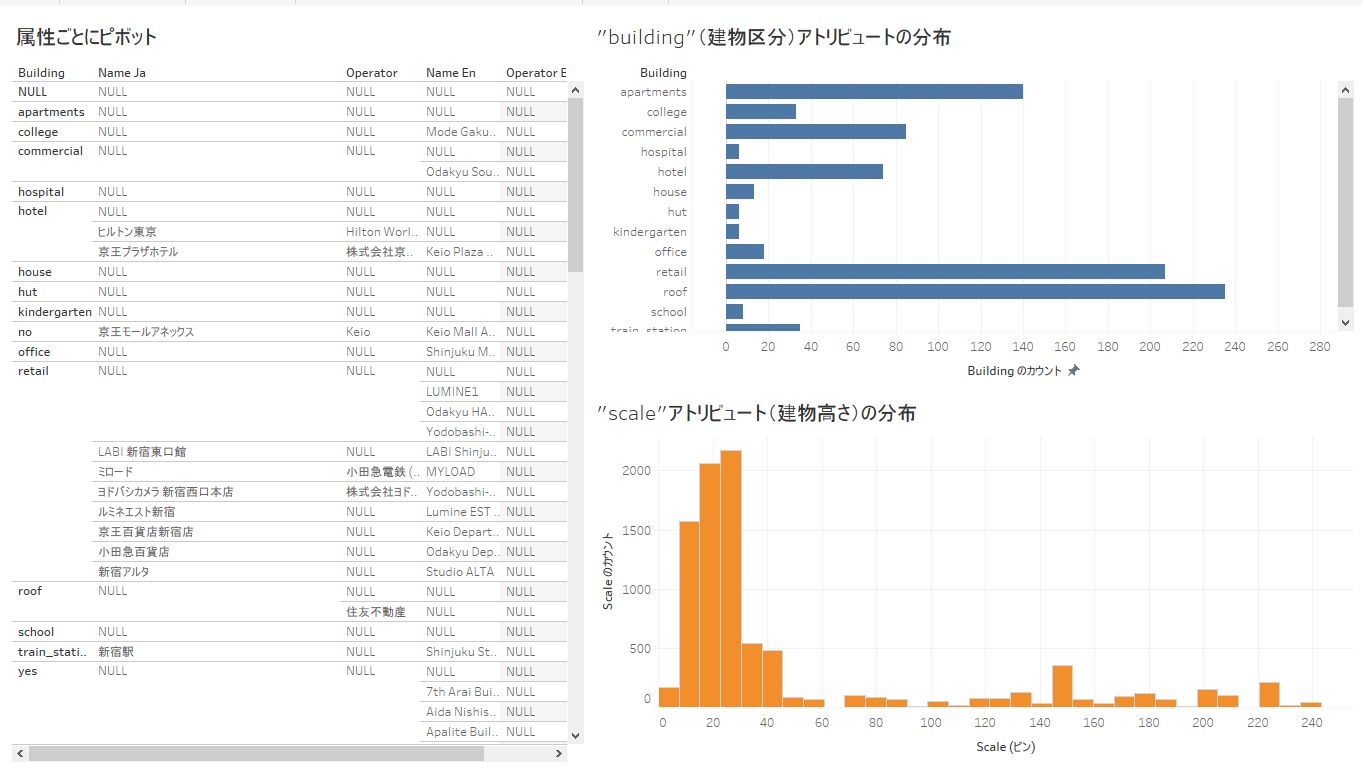
因みにPrimitiveをCachedUserDataとして保存、csv(でなくともよいのだが)を経由して出力しBIツールで読み込んでみるとこんな感じになる。取り敢えずドラッグしてみただけなので何か有意義な結果が得られているわけではない。
分析処理とHoudiniの接点
2Dと3Dの事例のところで伝わっていると嬉しいのだが…
実はHoudiniと分析(特にデータクレンジングの過程)の処理上の共通点はけっこう多いと言うのが個人的な印象。
これらを
[ 元の何か ] --(何かしらの加工1)-> --(何かしらの加工2)-> --(何かしらの加工3)-> … -> [ 出力される何か ]
という観点で見ると、データクレンジングもHoudiniやUnrealEngine等ののノードベースツールも適用先が異なるだけで似たようなものかなと思っている。
(因みに私がドハマリしているFactorioやSatisfactoryといった工場シミュレーションゲームも括れる、と思っている。)
この辺りの「処理」を繋いでいく世界というのは関数型スタイルと呼ばれる世界と密接に繋がっているらしい。
…が浅学で触れていい世界でないことも把握しているので、その辺りの説明は先達の記事6 7を参考にされたい。