0.初めに
夏季連休ということで、Deep Neural Networkで回帰問題を解いてみようと思います。
データセットはsklearnのCalifornia_housingを活用します。
1.データのインポート
sklearnのdatasetsからデータをインポートします。
import numpy as np
from sklearn.datasets import fetch_california_housing
cali_housing = fetch_california_housing(as_frame=True)
2.データの前処理
データの前処理で予測精度の80%は決まってしまうので、入念に調査することを心掛ける。
まずは入力因子・出力因子が何なのか観察する。
●入力因子は下記の8つ。
1列目:MedInc(所得) median income in block group
2列目:HouseAge(築年数) median house age in block group
3列目:AveRooms(部屋の数) average number of rooms per household
4列目:AveBedrms(ベッドルームの数) average number of bedrooms per household
5列目:Population(人口) block group population
6列目:AveOccup(世帯人数) average number of household members
7列目:Latitude(緯度) block group latitude
8列目:Longitude(経度) block group longitude
●出力因子(目的関数)は住宅価格[$100,000]とのこと。
The target variable is the median house value for California districts,
expressed in hundreds of thousands of dollars ($100,000).
●備考:データの欠損は無いとのこと。
Missing Attribute Values: None
詳細:https://inria.github.io/scikit-learn-mooc/python_scripts/datasets_california_housing.html
2-1.ヒストグラムでデータを観察
import matplotlib.pyplot as plt
cali_housing.frame.hist(figsize=(12, 10), bins=50, edgecolor="black")
plt.subplots_adjust(hspace=0.7, wspace=0.4)
多変量連関図で確認するので、サンプルコードだけで結果は割愛。
2-2.多変量連関図で確認
import seaborn as sns
# 多変量連関図
sns.pairplot(cali_housing.frame, size=1.0)
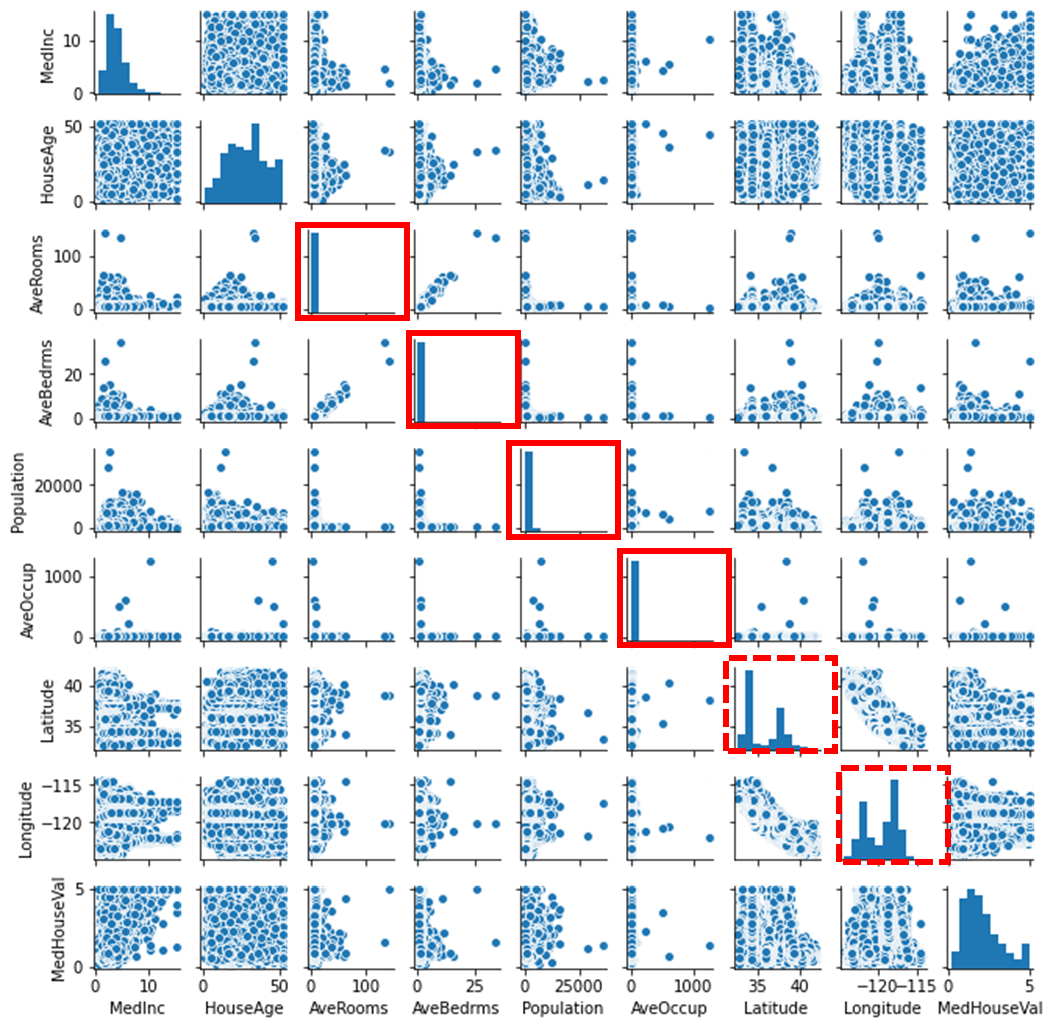
ぱっと見外れ値がある怪しい因子は下記4つ
ポイントはヒストグラムが正規分布ではなく、ピークが立っているモノは怪しい
・AveRooms
・AveBedms
・Population
・AveOccup
また、下記の2つは層別できそうだが、今回は重回帰分析で
解くわけではないので層別はしない。
・Latitude(緯度)
・Longitude(経度)
2-3.統計情報を確認
cali_housing.frame.describe()
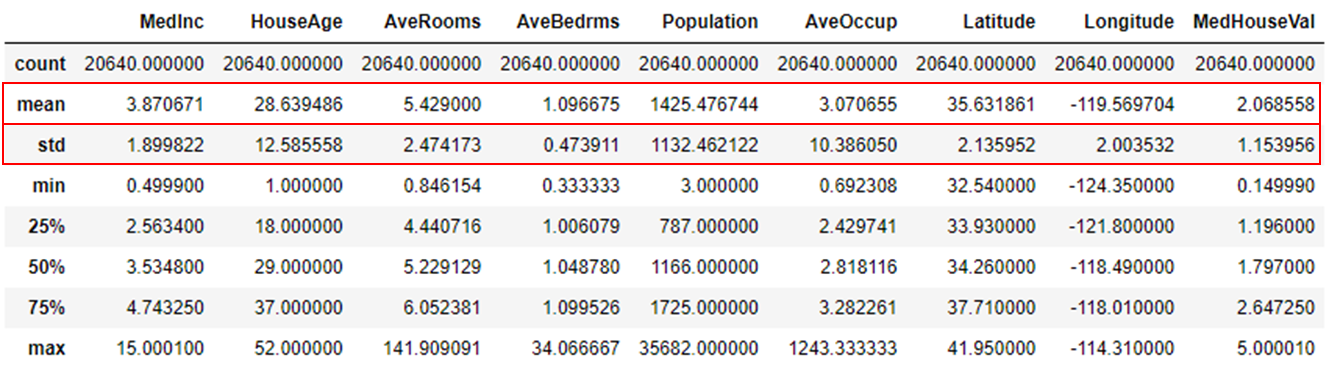
・AveRoomsの最大値が141部屋⇒部屋数が多すぎやしないか?
・AveBedmsの最大値が34部屋⇒こんなに寝室があるの怪しい?
・Populationの最大値が3万5千⇒人口はこれくらい行くのか?相場感がわからない。
・AveOccupの最大値が1243世帯⇒1つの住宅で1234世帯もいるの?集合住宅?
明らかに外れ値のような気がしますので、これらの4因子はすべて±2σでカット条件をかけます。
3.外れ値の除外
df=cali_housing.frame
#標準偏差の取得
ar_std=df['AveRooms'].std()
ab_std=df['AveBedrms'].std()
pop_std=df['Population'].std()
ao_std=df['AveOccup'].std()
#平均値の取得
ar_mean=df['AveRooms'].mean()
ab_mean=df['AveBedrms'].mean()
pop_mean=df['Population'].mean()
ao_mean=df['AveOccup'].mean()
#±2σを設定する
limit_low=ar_mean - 2*ab_std
limit_high=ar_mean + 2*ab_std
limit_low1=ab_mean - 2*ab_std
limit_high1=ab_mean + 2*ab_std
limit_low2=pop_mean - 2*pop_std
limit_high2=pop_mean + 2*pop_std
limit_low3=ao_mean - 2*ao_std
limit_high3=ao_mean + 2*ao_std
#±2σでカットする
newdf=df.query('@limit_low < AveRooms < @limit_high')
newdf1=newdf.query('@limit_low1 < AveBedrms < @limit_high1')
newdf2=newdf1.query('@limit_low2 < Population < @limit_high2')
newdf3=newdf2.query('@limit_low3 < AveOccup < @limit_high3')
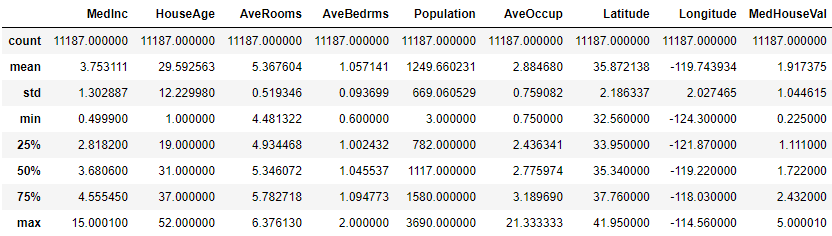
#統計情報確認
newdf3.describe()
# 多変量連関図
sns.pairplot(newdf3, size=1.0)
それなりにデータが整った

4.正規化(Min-Max法)で正規化する
機械学習では正規化することが精度向上には必要である
本検討ではDNNでモデル化するので、しっかりと正規化しておくことにする。
def minmax_norm(df):
return (df - df.min()) / ( df.max() - df.min())
df_minmax_norm = minmax_norm(newdf3)
ちなみに正規化を戻すのは下記
正規化したものを戻すコード
def minmax_trans(dfn,df):
return (dfn*(df.max()-df.min())+df.min())
#df_minmax_normは正規化したデータセット
#newdf3は正規化する前のデータセット
df_minmax_trans = minmax_trans(df_minmax_norm,newdf3)
5.訓練データとテストデータ、未知データに分割
通常、訓練データとテストデータに分けるだけだが、
今回は遊びの問題設定として、
未知データを精度良く予測することを問題として設定するために3つに分けておく。
from sklearn.model_selection import train_test_split
#入力因子と出力因子のx,yにそれぞれ代入
x=df_minmax_norm.iloc[:,:8]
y=df_minmax_norm.iloc[:,8:9]
#全体データから20%を未知データにsplit
x_know,x_unknown,y_know,y_unknown=train_test_split(x,y,test_size=0.2)
#既知データから80%を訓練データ、残りをテストデータに分割
x_train,x_test,y_train,y_test=train_test_split(x_know,y_know,test_size=0.2)
np.savetxt("x_train_ori.csv",x_train,delimiter=',')
np.savetxt("x_test_ori.csv",x_test,delimiter=',')
np.savetxt("x_unknown.csv",x_unknown,delimiter=',')
np.savetxt("y_train_ori.csv",y_train,delimiter=',')
np.savetxt("y_test_ori.csv",y_test,delimiter=',')
np.savetxt("y_unknown.csv",y_unknown,delimiter=',')
6.DNNで学習する
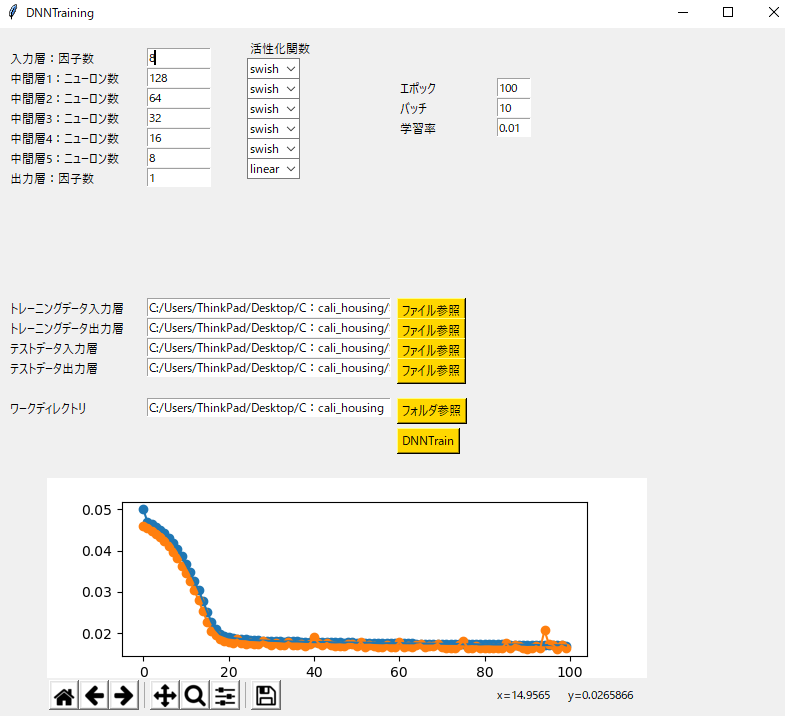
ニューロン数・中間層、活性化関数をパラスタした学習させる。
調整できるようにパラスタしたい項目はGUI(tkinter)で作成しておいた。
今回は中間層5層、
入力層8→ニューロン数128→64→32→16→8→出力層1で設定。
活性化関数はswishで。ちなみにMish、ReLUなども変更できるようにしておきました。
トレーニングデータ入力層*.csv(今回はx_train_ori.csv)
トレーニングデータ出力層*.csv(今回はy_train_ori.csv)
テストデータ入力層*.csv(今回はx_test_ori.csv)
テストデータ出力層*.csv(今回はy_test_ori.csv)
DNNTrainをクリックし、学習が終わるとmy_modelで保存する仕様で設計してあります。
下記にサンプルコードあります。長いので格納してます。tkinterは面倒ですね…![]()
👈コチラから DNNをパラスタできるGUI
import tkinter as tk
import tkinter.font as font
import os
import pandas as pd
import numpy as np
import csv
import tensorflow as tf
import subprocess
import math
import matplotlib as plt
from tkinter import *
from tkinter import ttk
from scipy.interpolate import griddata
from matplotlib.figure import Figure
from matplotlib.backends.backend_tkagg import FigureCanvasTkAgg, NavigationToolbar2Tk
from tensorflow.keras import layers
from IPython.display import Image
from tensorflow.keras.layers import Activation
from tensorflow.keras.utils import get_custom_objects
#============================================================================
class Mish(Activation):
'''
Mish Activation Function.
.. math::
mish(x) = x * tanh(softplus(x)) = x * tanh(ln(1 + e^{x}))
Shape:
- Input: Arbitrary. Use the keyword argument `input_shape`
(tuple of integers, does not include the samples axis)
when using this layer as the first layer in a model.
- Output: Same shape as the input.
Examples:
>>> X = Activation('Mish', name="conv1_act")(X_input)
'''
def __init__(self, activation, **kwargs):
super(Mish, self).__init__(activation, **kwargs)
self.__name__ = 'Mish'
def mish(inputs):
return inputs * tf.math.tanh(tf.math.softplus(inputs))
get_custom_objects().update({'Mish': Mish(mish)})
#============================================================================
class Application(tk.Frame):
def __init__(self, master=None):
super().__init__(master)
self.master = master
self.master.title('DNNTraining')
#matplotlib配置フレーム
self.frame=tk.Frame(self.master)
self.fig=Figure(figsize=(6,2),dpi=100)
self.ax1=self.fig.add_subplot(1,1,1)
self.fig_canvas= FigureCanvasTkAgg(self.fig, self.frame)
self.toolbar = NavigationToolbar2Tk(self.fig_canvas,self.frame)
self.fig_canvas.get_tk_widget().pack(fill=tk.BOTH,expand=True)
#self.fig_canvas.get_tk_widget().place(x=800,y=100)
self.frame.place(x=50,y=450)
#フォント定義
myfont2=tk.font.Font(family="Meiryou",size=8,underline=True)
#入力数・ニューロン数・出力数定義
self.setnin = tk.Entry(self.master,width=10)
self.setn1 = tk.Entry(self.master,width=10)
self.setn2 = tk.Entry(self.master,width=10)
self.setn3 = tk.Entry(self.master,width=10)
self.setn4 = tk.Entry(self.master,width=10)
self.setn5 = tk.Entry(self.master,width=10)
self.setnout = tk.Entry(self.master,width=10)
#入力・ニューロン数・出力数の初期値
self.setnin.insert(0,"3")
self.setn1.insert(0,"1024")
self.setn2.insert(0,"512")
self.setn3.insert(0,"256")
self.setn4.insert(0,"128")
self.setn5.insert(0,"64")
self.setnout.insert(0,"1")
#入力数・ニューロン数・出力数
self.setnin.place(x=150,y=20)
self.setn1.place(x=150,y=40)
self.setn2.place(x=150,y=60)
self.setn3.place(x=150,y=80)
self.setn4.place(x=150,y=100)
self.setn5.place(x=150,y=120)
self.setnout.place(x=150,y=140)
#入力・ニューロン数・出力のラベル
lbl_setnin=tk.Label(self.master,text="入力層:因子数")
lbl_setn1=tk.Label(self.master,text="中間層1:ニューロン数")
lbl_setn2=tk.Label(self.master,text="中間層2:ニューロン数")
lbl_setn3=tk.Label(self.master,text="中間層3:ニューロン数")
lbl_setn4=tk.Label(self.master,text="中間層4:ニューロン数")
lbl_setn5=tk.Label(self.master,text="中間層5:ニューロン数")
lbl_setnout=tk.Label(self.master,text="出力層:因子数")
lbl_setnin.place(x=10,y=20)
lbl_setn1.place(x=10,y=40)
lbl_setn2.place(x=10,y=60)
lbl_setn3.place(x=10,y=80)
lbl_setn4.place(x=10,y=100)
lbl_setn5.place(x=10,y=120)
lbl_setnout.place(x=10,y=140)
#活性化関数プルダウン
lbl_seta=tk.Label(self.master,text="活性化関数")
module = ('sigmoid','linear','tanh','ReLU','swish','Mish')
self.seta1 = ttk.Combobox(self.master,width=5,values=module)
self.seta2 = ttk.Combobox(self.master,width=5,values=module)
self.seta3 = ttk.Combobox(self.master,width=5,values=module)
self.seta4 = ttk.Combobox(self.master,width=5,values=module)
self.seta5 = ttk.Combobox(self.master,width=5,values=module)
self.setaout = ttk.Combobox(self.master,width=5,values=module)
#活性化関数プルダウン初期値
self.seta1.current(4)
self.seta2.current(4)
self.seta3.current(4)
self.seta4.current(4)
self.seta5.current(4)
self.setaout.current(1)
lbl_seta.place(x=250,y=10)
self.seta1.place(x=250,y=30)
self.seta2.place(x=250,y=50)
self.seta3.place(x=250,y=70)
self.seta4.place(x=250,y=90)
self.seta5.place(x=250,y=110)
self.setaout.place(x=250,y=130)
#学習率、バッチ、エポック、
lbl_LR=tk.Label(self.master,text="学習率")
lbl_batch=tk.Label(self.master,text="バッチ")
lbl_epoch=tk.Label(self.master,text="エポック")
module2=('mae','loss')
self.settar=ttk.Combobox(self.master,width=10,values=module2)
module3=('SGD')
self.setopti=ttk.Combobox(self.master,width=10,values=module3)
self.setLR=tk.Entry(self.master,width=5)
self.setbatch=tk.Entry(self.master,width=5)
self.setepoch=tk.Entry(self.master,width=5)
lbl_epoch.place(x=400,y=50)
lbl_batch.place(x=400,y=70)
lbl_LR.place(x=400,y=90)
self.setepoch.place(x=500,y=50)
self.setbatch.place(x=500,y=70)
self.setLR.place(x=500,y=90)
self.setepoch.insert(0,"100")
self.setbatch.insert(0,"10")
self.setLR.insert(0,"0.01")
#self.settar.place(x=500,y=10)
#self.setopti.place(x=500,y=50)
#ファイル参照ボタン
lbl_ptrin=tk.Label(self.master,text="トレーニングデータ入力層")
lbl_ptrout=tk.Label(self.master,text="トレーニングデータ出力層")
lbl_ptein=tk.Label(self.master,text="テストデータ入力層")
lbl_pteout=tk.Label(self.master,text="テストデータ出力層")
lbl_pwork=tk.Label(self.master,text="ワークディレクトリ")
self.ptrin = tk.Entry(self.master,width=40)
self.ptrout = tk.Entry(self.master,width=40)
self.ptein = tk.Entry(self.master,width=40)
self.pteout = tk.Entry(self.master,width=40)
self.pwork = tk.Entry(self.master,width=40)
ptrin_btn=tk.Button(self.master,text="ファイル参照",command=self.file_ref,bg="gold")
ptrout_btn=tk.Button(self.master,text="ファイル参照",command=self.file_ref2,bg="gold")
ptein_btn=tk.Button(self.master,text="ファイル参照",command=self.file_ref3,bg="gold")
pteout_btn=tk.Button(self.master,text="ファイル参照",command=self.file_ref4,bg="gold")
pwork_btn=tk.Button(self.master,text="フォルダ参照",command=self.dirdialog_clicked,bg="gold")
Start_btn=tk.Button(self.master,text="DNNTrain",command=self.startNNTrain,bg="gold")
lbl_ptrin.place(x=10,y=270)
lbl_ptrout.place(x=10,y=290)
lbl_ptein.place(x=10,y=310)
lbl_pteout.place(x=10,y=330)
lbl_pwork.place(x=10,y=370)
ptrin_btn.place(x=400,y=270)
ptrout_btn.place(x=400,y=290)
ptein_btn.place(x=400,y=310)
pteout_btn.place(x=400,y=330)
pwork_btn.place(x=400,y=370)
#ファイルパス
self.ptrin.place(x=150,y=270)
self.ptrout.place(x=150,y=290)
self.ptein.place(x=150,y=310)
self.pteout.place(x=150,y=330)
self.pwork.place(x=150,y=370)
Start_btn.place(x=400,y=400)
#ファイルパス
def file_ref(self):
self.target_file = tk.filedialog.askopenfilename(filetypes=[("csvファイル","*.csv")])
self.ptrin.insert(0,self.target_file)
def file_ref2(self):
self.target_file2 = tk.filedialog.askopenfilename(filetypes=[("csvファイル","*.csv")])
self.ptrout.insert(0,self.target_file2)
def file_ref3(self):
self.target_file3 = tk.filedialog.askopenfilename(filetypes=[("csvファイル","*.csv")])
self.ptein.insert(0,self.target_file3)
def file_ref4(self):
self.target_file4 = tk.filedialog.askopenfilename(filetypes=[("csvファイル","*.csv")])
self.pteout.insert(0,self.target_file4)
def dirdialog_clicked(self):
self.target_file5 = tk.filedialog.askdirectory()
self.pwork.insert(0,self.target_file5)
def startNNTrain(self):
INPUT_FEATURES = int(self.setnin.get())#数値に変換すること
LAYER1_NEURONS = int(self.setn1.get())
LAYER2_NEURONS = int(self.setn2.get())
LAYER3_NEURONS = int(self.setn3.get())
LAYER4_NEURONS = int(self.setn4.get())
LAYER5_NEURONS = int(self.setn5.get())
OUTPUT_RESULTS = int(self.setnout.get())
print("debug",OUTPUT_RESULTS)
#変数
func1=self.seta1.get()
func2=self.seta2.get()
func3=self.seta3.get()
func4=self.seta4.get()
func5=self.seta5.get()
func11=self.setaout.get()
print("debug",func11)
#sequential
model=tf.keras.models.Sequential()
model.add(layers.Dense(input_shape=(INPUT_FEATURES,),name='layer1',units=LAYER1_NEURONS,activation=func1))
model.add(layers.Dense(name='layer2',units=LAYER2_NEURONS,activation=func2))
model.add(layers.Dense(name='layer3',units=LAYER3_NEURONS,activation=func3))
model.add(layers.Dense(name='layer4',units=LAYER4_NEURONS,activation=func4))
model.add(layers.Dense(name='layer5',units=LAYER5_NEURONS,activation=func5))
######################################################################################
model.add(layers.Dense(name='layout',units=OUTPUT_RESULTS,activation=func11))
#model完了
model.summary()
LOSS='mse'
METRICS=['mae']
OPTIMIZER=tf.keras.optimizers.SGD
LEARNING_RATE=float(self.setLR.get()) #学習率0.01
model.compile(optimizer=OPTIMIZER(learning_rate=LEARNING_RATE),loss=LOSS,metrics=METRICS)
X_train = np.loadtxt(self.target_file,skiprows=1,delimiter=',')
Y_train = np.loadtxt(self.target_file2,skiprows=1,delimiter=',')
X_valid = np.loadtxt(self.target_file3,skiprows=1,delimiter=',')
Y_valid = np.loadtxt(self.target_file4,skiprows=1,delimiter=',')
BATCH_SIZE=int(self.setbatch.get())
EPOCHS=int(self.setepoch.get())
#es = tf.keras.callbacks.EarlyStopping(monitor='val_loss',patience=20)
print("####setup#####")
print("TrainingData_INPUT",self.target_file)
print("TrainingData_OUTPUT",self.target_file2)
print("TestData_INPUT",self.target_file3)
print("TestData_OUTPUT",self.target_file4)
print("Layer Number",5)
print("BATCH",BATCH_SIZE)
print("EPOCH",EPOCHS)
print("Learning Rate",LEARNING_RATE)
print("####setup#####")
#学習途中の重みを保存
cp_callback = tf.keras.callbacks.ModelCheckpoint(
#cp_callback = tf.keras.callbacks.Mode(
filepath=self.target_file5,
save_weights_only=True)
hist = model.fit(x=X_train,
y=Y_train,
validation_data=(X_valid,Y_valid),
batch_size=BATCH_SIZE,
epochs=EPOCHS,
verbose=1,
#callbacks=[es,cp_callback]
callbacks=[cp_callback]
)
######################################################################
# モデル全体を SavedModel として保存
model.save('my_model')
######################################################################
#plt.figure(self.fig_canvas)
train_loss = hist.history['loss']
print("debug",train_loss)
valid_loss = hist.history['val_loss']
print("debug",valid_loss)
epochs = len(train_loss)
#x=range(epochs)
#y=train_lossでプロットさせる
plotx=range(epochs)
ploty=train_loss
ploty2=valid_loss
self.fig2=self.ax1.scatter(plotx,ploty)
self.fig2=self.ax1.plot(plotx,ploty)
self.fig3=self.ax1.scatter(plotx,ploty2)
self.fig3=self.ax1.plot(plotx,ploty2)
#self.fig3=self.ax1.scatter(plotx,ploty2)
print("debug",epochs)
print("range(debug)",range(epochs))
self.fig_canvas.draw()
#plt.show()
exit()
#=============================================================================
root = tk.Tk()
root.geometry("800x800")
app = Application(master=root)
app.mainloop()
7.学習を終えたDNNで予測する
#学習を終えたモデルをロードする
new_model = tf.keras.models.load_model('my_model')
# アーキテクチャを確認
new_model.summary()
#未知データをロード
X_test = np.loadtxt("x_unknown.csv",skiprows=0,delimiter=',')
#予測する
pred_y=new_model.predict(X_test)
#予測を終えたデータを保存する
np.savetxt("pred_y.csv",pred_y,delimiter=',', )
8.評価する
RMSE(Root Mean Squared Error)を評価してみる。
import matplotlib.pyplot as plt
from sklearn.metrics import mean_squared_error
#未知データがActual
y_act=np.loadtxt("y_unknown.csv",skiprows=0,delimiter=',')
#予測データをload
y_pred=np.loadtxt("pred_y.csv",skiprows=0,delimiter=',')
#RMSEを計算
rmse = mean_squared_error(y_true,y_pred, squared=False)
# 結果確認
plt.figure(figsize=(5,5))
plt.xlim(0,1)
plt.ylim(0,1)
plt.plot(y_pred,y_act, 'o')
plt.title('RMSE: {:.3f}'.format(rmse))
plt.xlabel('Predict')
plt.ylabel('Actual')
plt.grid()
plt.show()
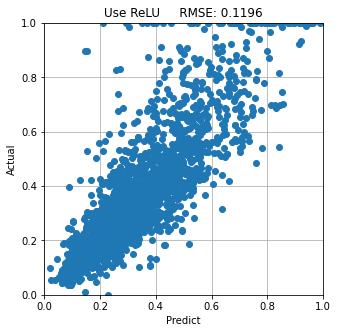
<ReLUを使用したモデルで予測したとき>
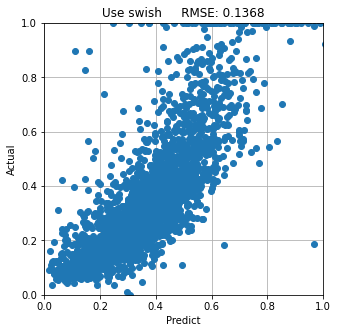
<Swishを使用したモデルで予測したとき>
<Mishを使用したモデルで予測したとき>
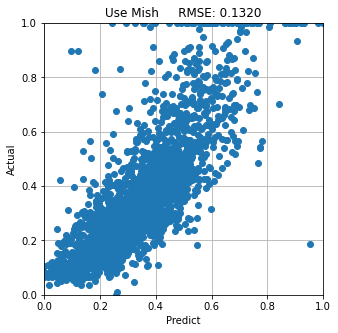
本検討では 優 ReLU>Mish>Swish 劣 の順でした。
最後に
まだどこかに外れ値がありそうだと感じます。
やはりデータの前処理は重要ですね。
もう一度外れ値・データの前処理をしっかりやって、
DNNの層数・ニューロン数の最適条件を洗い出しても面白そうですね
最後まで読んで頂きましてありがとうございます