はじめに
やぁ、唐突で悪いんだけどこれを見て欲しい。

これはラジオ体操をしている動画を部分的に切り取ったものなんだ。
こいつを【下記の処理】をして・・・
こうじゃ
左からポーズを取らせた画像、ポーズの基となった画像、後述するpix2pix用学習画像



いやったあああああああ!!!ラジオ体操してる奴に好きなポーズを取らせられた!!!!
追記
JOJO立ちもさせた。
スピード感を追及するあまりカメラがブレたみたいになってる

追記 20181213
動画も作りました

どんなことをしているか
やっている内容を説明するためにまずopen poseについて説明する。
open poseとは以下のような人物画像を与えるとその人物の骨格情報を取得できるものである(私の思い込みかも)。
下記画像を参照して欲しい。
この図は左の画像を読み込んで右の画像を出力する、という例である。
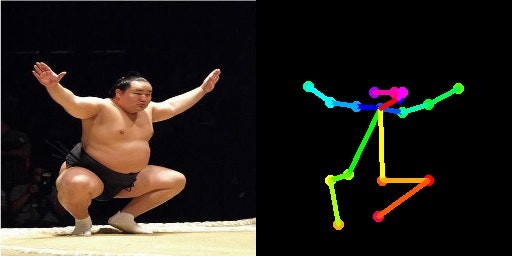
こうして生成された元の画像とボーンの画像の組をpix2pixという2つの画像の対応関係を学習するような学習機にかける
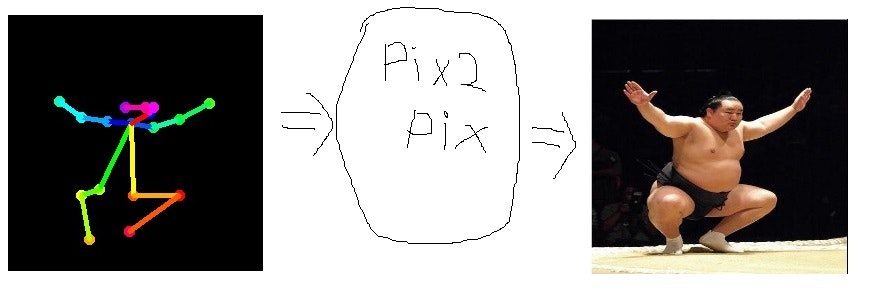
これによってボーン画像を与えられるとそのポーズを作成するモデルの作成ができる。
この記事で行っていることは上記動画でこのモデルを作成し、任意の画像のボーン情報をモデルに与えて、そのポーズを取っている画像を生成しているという訳。
画像を用意するうえでの注意点
画像を生成するというタスクのため、以下の要素を含むことが求められます。
・学習データ用の動画中の背景が同じこと
・学習データ用の動画中の服装が同じこと
・ポーズ生成用画像のボーンが人間離れしていないこと
参考サイト
以下にこれを作成するにあたり参考にさせて頂いた方々を紹介します。まことにありがとうございました。
open pose
・【OpenPose】〇〇の画像をアップすると近い構図の〇〇の画像が送られてくる。を自動化してみた。
・GPU無しで画像のみから人間のボーン推定が出来るtf-openposeを導入する
pix2pix
・pix2pix を動かしてみる
終わりに
現状、生成されたポーズを取っている画像が画質が大変荒い、これを改善するにはpix2pixのチューニングを真面目に行う必要があると思われる。
この記事の方法を使用すると二つの動画の中の人同士を入れ替えるようなことが十分可能であると考えられる。
後を自分でやってみたいという人のために以下に実装を示す。
実装
実装自体は下記の処理フローにのっとって作られるがここではopen poseとpix2pixの使用方法はもっと良い記事がごろごろありそうなので割愛します。
1.動画から静止画を全部切り出す
2.1.の動画をopen poseにかけてpix2pixの学習用のデータを作成する
3.2の画像でpix2pixを学習
動画から静止画を全部切り出す
import cv2
import numpy as np
movie = cv2.VideoCapture("動画のパス")
ret, movie_frame = movie.read()
frame_count=0
while True:
# retは画像を取得成功フラグ
movie_ret, movie_frame = movie.read()
if( movie_frame is None ):
break
# フレームの保存処理
cv2.imwrite("./image/"+str(frame_count)+".jpg",movie_frame)
frame_count+=1
# キャプチャを解放する
movie.release()
cv2.destroyAllWindows()
pix2pixの学習用のデータを作成する
import argparse
import sys
import time
import math
from tf_pose import common
import cv2
import numpy as np
from tf_pose.estimator import TfPoseEstimator
from tf_pose.networks import get_graph_path, model_wh
import glob
import inspect
images_path=1で作った静止画群のフォルダまでのパス
path_list=glob.glob(images_path+"/*")
# 画像で最も大きい人間のボーンを取得する関数
def getBiggestHuman(humans):
maxNum=0
maxHuman=humans[0]
for human in humans:
tempNum=0
#パーツインデックス取得
keys=list(human.body_parts.keys())
temp=human.body_parts[keys[0]]
tempX=temp.x
tempY=temp.y
keys = keys[1:]
for i in keys:
parts = human.body_parts[i]
tempNum += math.sqrt((tempX-parts.x)**2 + (tempY-parts.y)**2 )
if tempNum > maxNum:
maxNum=tempNum
maxHuman=human
return maxHuman
# pix2pix用の画像を作成する関数
def makeData(humans, orig_image, save_path):
hu = getBiggestHuman(humans)
kuronuri_image=np.zeros_like(orig_image)
if len(hu.body_parts.keys()) >= 17:
image = TfPoseEstimator.draw_humans(kuronuri_image, [hu], imgcopy=False)
image=cv2.hconcat([orig_image,image])
cv2.imwrite(save_path,image)
w, h = 256,256#ここは1で作った画像の縦横サイズを指定
e = TfPoseEstimator(get_graph_path('cmu'), target_size=(w, h))
for path in path_list:
orig_image = common.read_imgfile(path, None, None)
humans = e.inference(orig_image, resize_to_default=(w > 0 and h > 0), upsample_size=4.0)
save_path = #保存するフォルダへのパス
makeData(humans=humans, orig_image=orig_image, save_path=save_path)