メタ
この記事はNode学園2018にて話した内容を記事として編纂 +その後の変化を加筆修正したものです。
スライドはこちら。
https://speakerdeck.com/kazuyaseki/seo-for-spa-cfb3706f-ae1d-4c6f-a83f-96dc2452f32b
追記 2019/5/8
遂に Google bot が扱うレンダリングエンジンが Chrome 最新版(現時点では 74)相当となりました!
https://webmasters.googleblog.com/2019/05/the-new-evergreen-googlebot.html
ただタイムアウトなどのリスクは依然存在するので、信頼性を求めるならやはり Dynamic Rendering や SSR が選択肢になるのかなと言う気はしますが、そこまで要求が強くない場合にはあまり頑張らなくてよくなるのかなと思います。
また今回の変更に伴ってか、Google自身が JS 関連の問題をまとめた記事も作成してくれたので、こちらも合わせて読んでみるといいかもしれません。
https://developers.google.com/search/docs/guides/fix-search-javascript
はじめに
この記事はSPAを構築することを前提とした時に、立ちはだかるSEOの課題とそれに対する打ち手の考え方をまとめたものです。
「SPAにおけるSEO」は調査の難易度が謎に高く、何が正しいのか(主にSSRは必要なのかどうか)分からず困っている人も多いのではないでしょうか。また、Google検索エンジンという仕様が明らかではないものを対象とするため、どう調査してもある程度不確実性が残ってしまうことにあるのではと考えています。
この記事では私の力の限り調査した内容をまとめてみました。より良い技術選定の助力ができたら幸いです。
想定読者
- SPAの構築を検討していて、SEOの要求に答えなければいけない方
- 結局どうすればいいのか途方に暮れている方
スコープ
- SPAで「SEOの土台」を作ることについてフォーカスします。具体的なSEOテクニックについては触れません。
- 検索エンジンはGoogleのみを考慮しています。
免責
この記事は2019年5月段階での情報を元にしています。なるべく知りえた範囲で変わったことがあればアップデートしていくつもりですが、その点はご注意ください。SEO関連の話はスピード感伴って変わっていくのでウォッチしていきましょう。
目次
-
SEOとはなにか
まずはじめに、そもそも我々が呼んでいる「SEO」とは具体的になにを指しているのでしょうか?
現場では大きく次の3つの文脈が混ざって呼ばれていると思います。
- Search Engine Optimization - 検索結果のランキングを上げる
- Facebook OGP, Twitter Card - 外部サービスでの表示用の情報
- 構造化データ - 検索結果でリッチに表示されるための情報
Search Engine Optimization
これは大半の人が思い浮かべる「SEO」の定義でしょう。文字通り検索結果にて、より上位に表示されることを目指すことを指します。これを実現するためには最低限次の二点を満たしている必要があります。
- Google botにクロールされること
- HTMLが適切に解釈されること
これらができていないと、そもそもどんなSEOテクニックを施したところで意味がありません。
ちなみにですが、このうち「Google botにクロールされること」については「リンクを適切に貼りましょう」「sitemap作りましょう」など今回の主題とはそれた話しになるため、本記事では触れません。「HTMLが適切に解釈されること」についてはSPAにおいては課題があるため、後の項で触れていきます。
Facebook OGP, Twitter Card などのSNS用の情報
SNSなどでいい感じに表示されるために必要なメタデータの代表格がFacebook OGPとTwitter Cardです。
これらは"Search Engine"とはなにも関係がないのですが、おそらく<head> に <meta> を書くことから"SEO"の文脈で語られることが当たり前の世の中になってしまったので、ちゃんとこれについても触れていきます。
例として次のようなタグをHTMLに記述すると

Facebookなどにそのサイトのリンクが貼られた時、次のようにいい感じに表示してくれます。
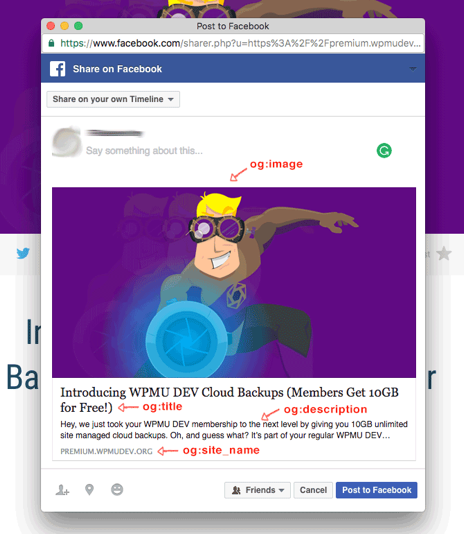
昨今SNSでの流入はプロダクトによっては検索エンジンをも超えるインパクトをもたらすため、非常に重要な機能となっています。
構造化データ
ざっくり言うと「検索結果でリッチに表示してくれるもの」です。
具体的な構造化データのリストについてはこちらをご参照ください。
検索ギャラリー | 検索 | Google Developers
これの代表格としてはAMPがあります。次のようなメタデータを埋め込んだり
<script type="application/ld+json">
{
"@context": "http://schema.org",
"@type": "NewsArticle",
"headline": "記事のタイトル",
"image": [
"eyecatch.jpg"
],
"datePublished": "2017-08-23T00:00:00+0900"
}
</script>
その他もろもろCSSをインラインで書くとかAMP指定のタグで書くなど様々な苦難を乗り越えることによってとてつもなく早いページと検索結果でのカルーセル内に表示される権利を勝ち得ることができます。

このように検索結果での表示をより意味のあるものにしてくれるものを構造化データと呼びます。
なお本記事ではこれ以降は対応方法が似通っていることと分けて呼ぶのがめんどくさいことから、OGP, Twitter Cardなどと構造化データはひっくるめて「メタ情報」と呼ぶようにしたいと思います。(一般的な呼び方ではないのでご注意ください。)
- SPAにおけるSEOの課題
それでは次にSPAを構築する際に、SEOの土台作りを阻害する課題たちを見て行こうと思います。
よくある誤解
ちょくちょく聞くこととして
- Google botはJSを実行しない
- Google botはAjaxを実行しない / 待たない
がありますが、これはどちらも誤解です。というより昔はそうだったのかもしれませんが今は違います。
まずJSの実行についてですが、こちらReactでの描画をFetch as GoogleというGoogleでのレンダリングを確認できるツールで検証してみました。左側がコードでHTMLには「I'm not React」 、Reactが実行されたら「I'm React」と表示するようになっています。

ちゃんとReactで描画している部分が表示されていますね。ただ、こちら問題なくJSを実行するためには「Chrome41で実行できること」を満たす必要があります。これについての詳細は後ほど述べます。
またAjaxについても検証してみました。fetch APIで呼んで結果を表示するだけのページです。

こちらもちゃんと結果が表示されています。
なので、これらが誤解であることは確認できたのですが、それ以外にいくつか落とし穴があります。次にそれらを順に見ていこうと思います。
課題1. Googleが描画に使うレンダリングエンジンの性能はChrome41相当
こちら冒頭の追記にも書きましたが、2019/5/8時点で Chrome 74 相当となりました。
https://webmasters.googleblog.com/2019/05/the-new-evergreen-googlebot.html
課題2. タイムアウト
当たり前といえば当たり前なのですが、Google botも忙しいのでいつまでも待ってくれるわけではありません。リクエストに時間がかかりすぎるとそもそもインデックスされなかったり、中途半端なところで描画が打ち切られる可能性があります。
検証: 何秒まで待ってくれるのか?
それでは気になるのが「何秒までなら待ってくれるのか?」という話ですが、これに関しては検証してくださった方がいらっしゃるのでその結果をパクりお借りしようと思います。
前提
- ElmでできたSPAサイト
- pushStateでページを変更している
検証内容
以下の3パターンをアップデートすることによってタイムアウトにかかる時間の検証
- 時間の表記(title, description, ページ内のテキスト) - 毎秒変化
- Type A Ajax call - 1, 3, 6, 10秒のdelayを持ったリクエスト
- Type B Ajax call - 1, 3, 6, 10秒のdelay後にリクエスト

確認方法
Fetch as Googleと"Natural"なGoogleのインデックスで結果を見ています。

Fetch as Googleとは能動的にGoogleにインデックスをリクエストできるツールで、その他実際にクロールと描画を行ってくれるのでデバッグにも便利なツールです。詳しくは下記のリンクをご参照ください。
ウェブサイト用 Fetch as Google を使用する - Search Console ヘルプ
結果
この方の検証では結果は次のようになりました。
- Fetch as Googleでは約5秒待ってくれる
- "Natural" なGoogleのクロールでは約20秒待ってくれる
なので余裕こくなら20秒くらい使っても大丈夫ですが、万全を期すなら5秒以内を目指したいところです(どんな環境で"5秒"なのかは不明ですが…)。
ちなみに中の人はタイムアウトについてなんと言及しているかという話なのですが、JavaScript Sites in Search Working Groupというメーリスの中で John Mueller さんというSEO界隈で著名な方は次のように仰っています。

ざっくり意訳すると「決まったタイムアウトはないけど5秒はいいターゲットだよ!」と仰っていますね。なので真の心の安寧が欲しいのであれば標準的な環境で5秒くらいでインデックスされて欲しい内容が描画されるようにする必要があります。
コラム: タイムアウトされたらインデックスしてくれないのか?
これに関してはちゃんと検証できていないのですが、仮説としては「一度Paintingが行われるまで」にエラーやタイムアウトが起きるかどうかが分岐点になるのではと考えています。

先ほどの検証にて途中で描画が打ち切られてもインデックスはされることが証明されています。ただ、エラーが起きたり遅すぎる場合インデックスされない事例というのも多々あります。おそらくこれを分けているのが上記のブラウザのレンダリングプロセスにおいて一度でもPaintingにまで至ったかなのではないかと考えています。一度でも描画されていれば、そのあとでエラーが起きたりタイムアウトが発生してもとりあえずはインデックスされると。
これが正しい場合、いい面もあれば悪い面もあって、ちゃんとFetch as Googleなどでテストをしていないと不完全な情報をインデックスさせてしまっていることに気づかないリスクがあります。後ほど紹介する打ち手たちを選ぶ際に、ここに信頼性を求めるかどうかが一つの分岐点となります。
コラム: Lazy Loadingについて
社内で「Lazy Loadingする画像はインデックスされるのか」という質問を受けたのでそれについて触れておきます。
まずLazy Loadingも大きくやり方は二通りあり、「時間差で(例えばDocumentがreadyになった後)画像の読み込みを開始する」か「スクロールなどでユーザの視界に入った時に読み込みを開始する」(基本こっちな気はしますが)があります。
まず前者に対しては「タイムアウトまでに読み込まれるかどうかによる」という答えになります。そして後者に関してはいくつか対応策があるらしく、noscriptタグに記述する方法やpaginated loadingと呼ばれるスクロールに応じてURLを変化させる手法があるそうです。
私自身試したことがないため、詳しくは下記をご参照いただければ。
- Lazy Load画像をSEO対応させる2つの方法――noscriptと構造化データ #io18 #io18jp | 海外SEO情報ブログ
- Google、SEOに適したLazyloadの仕様を公開 | 海外SEO情報ブログ
課題3. メタ情報はサーバ側から返ってくる時点で描画されている必要がある
FacebookやTwitterではリンクが貼られた時、そのリンク先のJSをわざわざ実行はしてくれません。なので、これらに関してはなんらかの方法でサーバ側から返ってくる時点で描画している必要があります。
課題4. Render Queueによるインデックスの遅延
JSを実行するサイトはHTMLだけの静的なサイトとは異なり、すぐにインデックスされる訳ではなく、一度 Render Queue というものに処理が移譲されます。
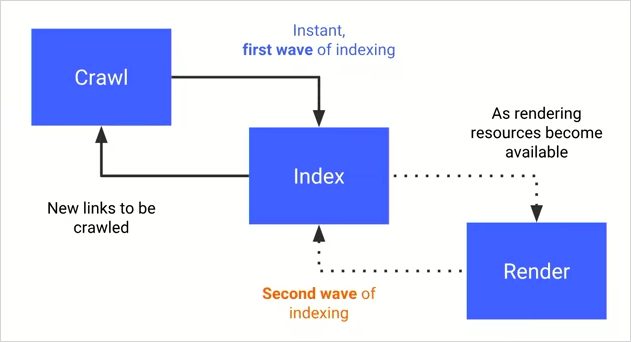
参考:JavaScriptによるnoindex挿入をGoogleは推奨せず、JSレンダリングはセカンドウェーブのインデックス
Googleは最初の静的なページだけがクロールとほぼ同時にインデックスされるものを「First Wave」、Render Queueが空いてから順次実行され、インデックスされるものを「Second Wave」と呼んでいるようです。
Queueの名の通り入ったものから順に処理される訳ですが、問題は処理が開始されるまでの時間です。
数分ということもあれば1週間かかることもあるそうです。なので、ある程度Fetch as Googleによるリクエストでカバーはできるかもしれませんが、頻繁に更新され、すぐにインデックスして欲しいようなサイトではクリティカルな問題となります。
Render Queueに入れられるものとそうでないものの違いは?
こちらGoogleの中の人でないと検証のしようがない気もしますが、おそらくscriptタグがあるかどうかな気はします。
コラム: 課題に対するGoogleのアップデートはあるの?
ちょうど先週Chrome Dev Summitで「Making Modern Web Content Discoverable for Search」というトークがあり、そこで検索エンジンシステムに対するアップデートに関する展望が終盤に述べられていました。

今レンダーのプロセスだけ分けてしまっているが、JSを実行するサイトでもすぐにインデックスできるようにクロールと統合すること、そしてレンダリングエンジンの性能をモダンなChromeと同等にすることが挙げられています。
なので、時期は不明ですが今回紹介した課題のうち「Render Queueによるインデックスの遅延」は将来的には解消されそうです。それまでは対策が必要ですね。
動画のリンクはこちらです。
Making Modern Web Content Discoverable for Search (Chrome Dev Summit 2018)
まとめ
本項ではSPAにおけるSEOの課題を紹介しました。
- タイムアウト
- メタ情報はサーバ側から返ってくる時点で描画されている必要がある
- Render Queueによるインデックスの遅延
次にこれらの課題を解決するためにどんな打ち手があるのかを見ていきます。
- どんな解決策があるのか
解決策1. Chrome41対策
Chrome ver 74相当になったので、大体のケースでGoogle bot専用に特別に対応はいらないと思うのですが、下記にちゃんと描画されるのかの検証の方法を記述します。
検証の仕方
先ほど軽く触れたFetch as Googleが正攻法なテストの仕方です。
しかしFetch as Googleは1日10回までという制限があるのと、またお使いいただいたことのある方なら一度は目にしたことがあると思いますが「一時的にアクセスできません」というエラーがちょくちょく発生します。これは原因の特定が難しく、サイト自体に問題があることもあればそうでないこともあります。ググると「1日待ちましょう」のような解決策を見つけることができます(実際私も数日置いてリトライしたらなんか取れたみたいな経験があります)。
なので「無制限にテストしたい!」そんなあなたにGoogleの中の人がpuppeteerのツールを作ってくれました。こちらのrepositoryの内、google_search_features.jsというスクリプトが該当します。
SEOに役立つ、Googlebotのレンダリングを検証する4つの方法 | 海外SEO情報ブログ
解決策2. メタ情報のみSSR
メタ情報のみをサーバ側で描画して返すのも一手です。メタ情報はReactやVueなどのViewライブラリなどを実行せずともURLに応じて描画できる部分なので、そこまでコストを書けずに実現できます。状況にもよりますが、自前でスクリプト書くのでもそこまで手間にはならないでしょう。

豆知識. Nuxtのspa modeでサーバ立てると実はメタのとこだけはSSRしてくれてる
NuxtはSSRのみならず、それが提供してくれるフレームワークが魅力だと思うので、spa modeを使っている方もそこそこいると思っているのですが、実はこのspa mode、Nuxtサーバーで動かしているとメタのとこだけはSSRしてくれています。
spa modeの場合は nuxt.config.js 内に書かれているものを表示するだけで、APIからタイトルを取得する様な場合やURLベースで動的に変更するようなものについてはssr modeが必要でした。 @geerpm さんご指摘ありがとうございました<(_ _)>
解決策3. Dynamic Rendering
今年のGoogle I/Oで発表され、テクニカルSEO界隈では話題になった(らしい)手法です。そのセッションの動画はこちら。ただ"発表され"と言っても、手法自体は以前から存在しており、prerender.ioやrendertronと呼ばれるものがそれに該当します。
prerender.ioを例にあげると次のように動作します。

ざっくり言うと「Headless Chromeで実行した結果をキャッシュしといて、Usea Agentで見分けてbotだったらキャッシュから返す」という感じですね。
これであれば前項で挙げた課題は全てクリアできます。そもそもbot側でJSを実行させる必要がないのでChrome41対策は不要ですし、キャッシュから即座に返すのでタイムアウトも心配いりません。サーバ側でレンダリングしているのでメタ情報も大丈夫です(でも対応必要なサービスのUAのホワイトリスト管理は必要そう)。
でもこれbotに返すのはキャッシュからなので当然速いですが、実ユーザに返すものが遅い場合SEOの評価ってどうなるんでしょうね?
コラム: クローキングについて
ブラックハットSEOの一つとしてクローキングというものがあります。これはGoogle botに対してと実ユーザに対して違うページを返すことを指していて、バレたらペナルティが科せられます。例えばbotにはそれっぽい感じのメディアサイトのHTMLを返しておいて、ユーザには危険な感じのアダルトサイトを見せるなどしたらユーザにとっては最悪の体験ですよね。なのでそういったサイトはそもそも検索結果に表示させてたくないというのがGoogleの意図です。
これを聞いて「え?Dynamic Renderingは大丈夫なん?」と思われた方がいらっしゃるかもしれません。個人的な見解としては「botとユーザに返すものがそんなに違いなければ多分大丈夫」となります。
Fetch as Googleを見ても分かる通り、Googleはなんらかの方法で実ユーザが見ている画面をレンダリングしています。その画面のHTMLとbotが取得したHTMLを比較して、差分が大き過ぎる場合にクローキングと判定しているのでしょう。具体的なアルゴリズムを公開してくれている訳ではないので、ある程度不確実性は残りますが、Google自身がわざわざ推している手法であることからそんなに違いがなければ多分ペナルティはくらわないでしょう。(と信じたい)
解決策4. Static Site Generator
最近JAM Stackと呼ばれ話題のStatic Site Generator(長いのでこれ以降はSSGって呼ぼうと思います)も一つの打ち手です。
SSGでは事前にReactなどで作られたページでJSを実行しておき、生成されたHTMLを配信します。一度クライアントで描画されたあとはルーティングをクライアントに移譲することができるので初期体験もよくしつつSPAのいいところも活かせるのが魅力です。

個人的にはSEOしたいページで認証が必要なページはほぼほぼないと思うので、新規ユーザが流入するところだけSSGで作って、実ユーザに対する体験向上を目指しつつSEOの土台も作れる打ち手として今後盛り上がっていきそうな予兆を感じています。Gatsby使いたい。
解決策5. SSR(Server Side Rendering)
みんな大好きSSR。SPAでのSEOと言えば必ず話題に上がる手法です。
フレームワークとしてはNuxt.js と Next.jsが有名です。SSRは文字通りサーバ側でVueやReactなどを実行してHTMLを生成してから返すことを指します。

また「SEOの信頼性を求めるならSSR」みたいなイメージが持たれていると思うのですが、実は前述のDynamic Renderingと比較すると劣る部分があり、タイムアウトのリスクがあります。
こちらオウチーノ様の事例を引用するのですがSSRしただけではインデックスはされず、パフォーマンスを改善したところインデックスされるようになったと仰っています。
Rails+ReactなSPAサイトでSEOをしようとしてぶつかった壁
スライドの中身を見ている限りCode Splittingなどを行なってパフォーマンス改善に繋げたところインデックスされるようになったとのことです(それで言うとSSGも同じ理屈でSPAのJSが大きすぎるとインデックスされないのかもしれません)。
Dynamic RenderingのようにSEO用にHTML作ってそれで終わり、ではなくSSRは実ユーザに対しての体験向上も目指した技術であるためSSRで全てをまかなおうとすると要件がバッティングすることもあるかもしれません。ちゃんとCode SplittingしておけばOKな気もしますが、「SSRしておけばSEOは大丈夫」と考えるのはいささか危険です。
- 要求パターンごとの解決策の選び方
課題と打ち手についてみてきましたが、最後に要求パターンごとにどうやって打ち手を選べばいいかを考えてみます。
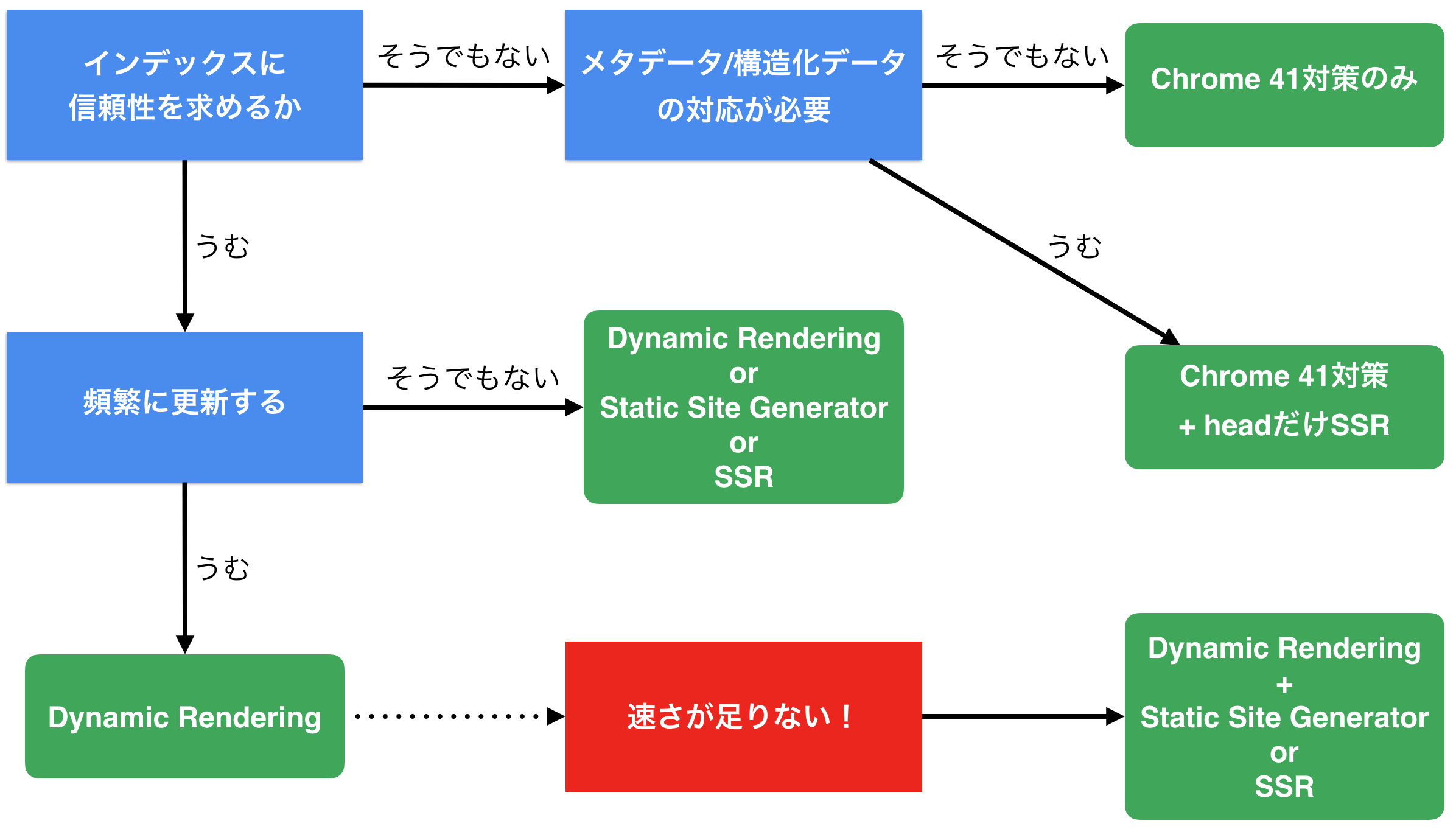
まずは次の3つの問いを考えてみましょう。
- インデックスに信頼性を求めるか
- メタ情報の対応が必要/不要
- 頻繁に更新される & すぐにインデックスしてほしいかどうか
1.インデックスに信頼性を求めるか
要するに「とりあえずインデックスされればいいよ」くらいなのか「ビジネスにクリティカルなので、なるべくすぐに確実にインデックスされてほしい」くらいの温度感なのかどうかという話です。
ここであまりこだわらないようであれば、Dynamic Rendering, SSG, SSRなどの方法は選択肢としては取らなくてよくなるでしょう。
ただ注意点なのが、Chrome41対策のみを選択した場合、膨大なSPAのJSファイルを実行するためタイムアウトの危険性は多分に伴います。もし「常にインデックスが失敗する」ようであれば、Code Splittingなどでしっかりパフォーマンス改善を行なっていくか、他の手法を取り入れることも視野に入れるべきと思います。
2.メタ情報の対応が必要/不要
必要な場合はなんらかの方法でサーバ側でメタ情報を描画しなくてはなりません。
もし「とりあえずインデックスされればいいよ」で「OGPは表示したい」である場合はメタ情報だけSSRなどの対策を取る必要があります。
3.頻繁に更新される & すぐにインデックスしてほしいかどうか
頻繁に更新され、且つそれがなるべく早くインデックスされてほしい場合はRender Queueでの遅延は無視できないものとなるでしょう。この場合はDynamic RenderingなどでHTMLだけを返すようにする工夫が必要となります。
図
何個か図を作ってみました。社内を説得する際にご活用ください。
フローチャート
テーブルマトリクス
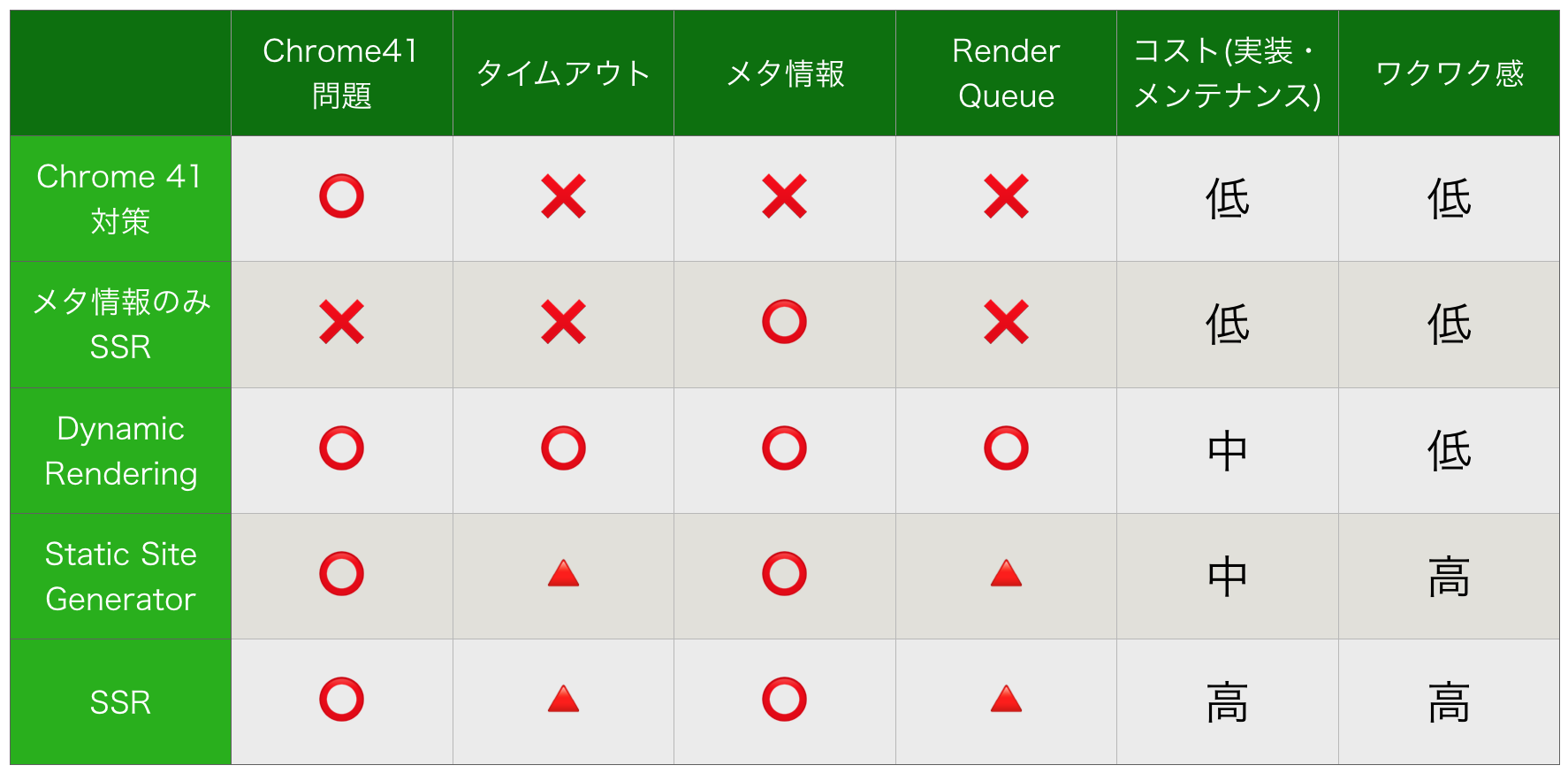
Twitterでよく見るタイプのマトリクス
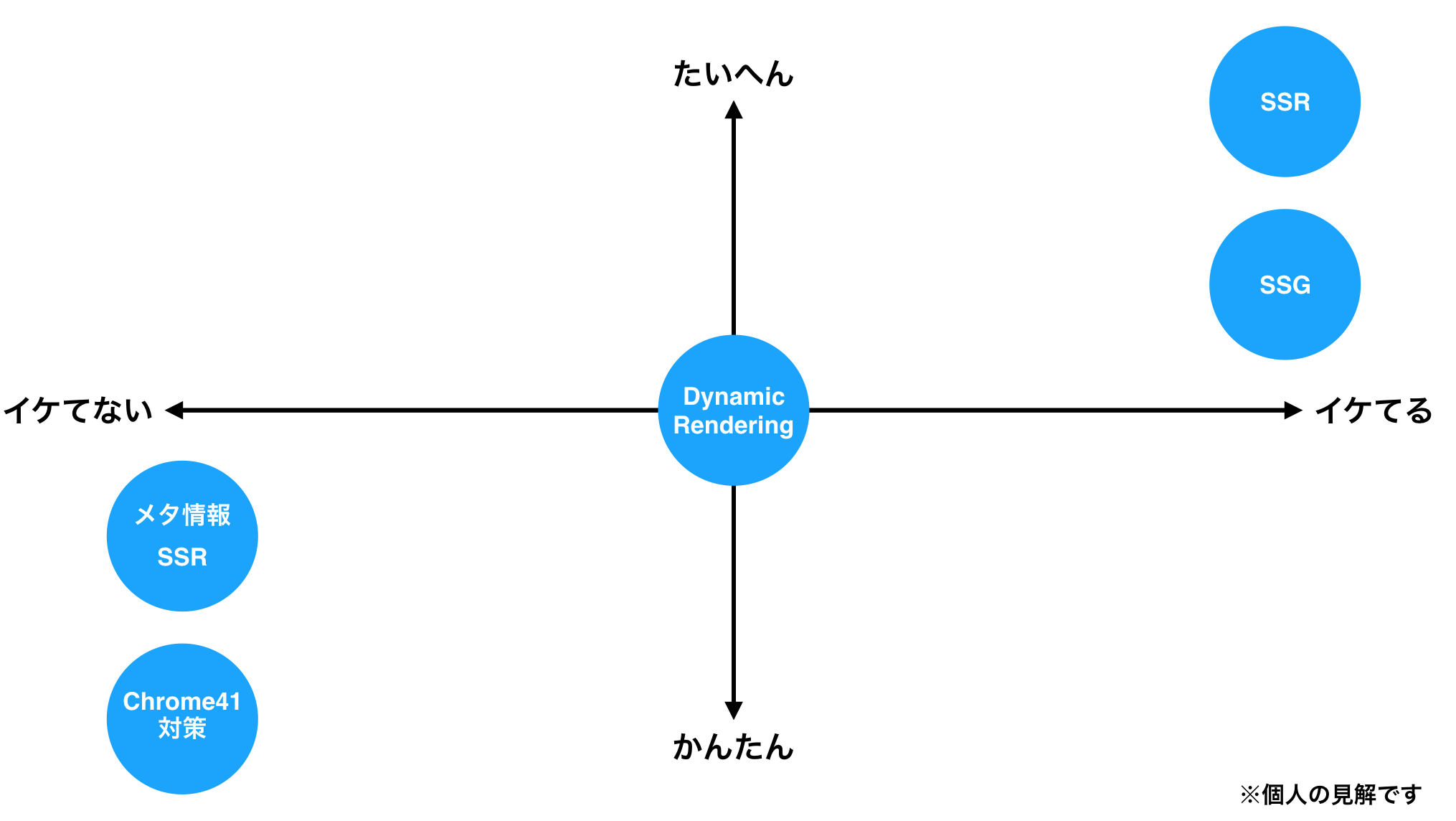
結局SSRは必要 / 不要?
多分この問いがみんな気になっているのではと思っているので、若干脈絡ないですが私見を述べておきます。
結論から言うと、SEO観点だけで言えば不要だと思います。
実装がDynamic Rendering よりコストが高い上に、作り方によってはタイムアウトのリスクもあります。
なのでSSRを選ぶ際には他のパフォーマンスなどでの観点が主となると思います。例えば、ユーザ認証が必要な部分でのFMPの最適化ができる手法は私が知る限りではSSRしか存在しません。なのでそういった部分での最適化がビジネス的に重要なのであれば有力な選択肢となり得るでしょう。
また、先ほどの図でもチラッと書きましたが、一つしか選べないという訳でもないので、要求によっては Dynamic Rendering + SSR という構成もありえるのかなと考えています。
おわりに
ユーザにとって「いいもの」を作っていこう
Googleは「First and foremost, we focus on the user.」と20周年のブログで述べました。
https://www.blog.google/products/search/improving-search-next-20-years/
検索エンジンの仕様の変更は一貫して「ユーザにとってより良い検索結果を表示するため」です。なので基本的に「ユーザによりよい体験を提供すること」がSEOに繋がります。
例えば、今回タイムアウトのリスクを減らすためにはパフォーマンスを上げる必要があることをお伝えしましたが、そもそもパフォーマンスはSEOの重要な評価指標の一つです。いいパフォーマンスはいいユーザ体験につながるからです。なので単純にインデックスされればいいという場合は別ですが、ちゃんと順位を上げていきたい場合にはリスク云々以前にパフォーマンスを上げなければいけません。
技術的な制約から今回のような”対策”をある程度しなくてはならないのは確かですが、それ以外は「ユーザに良質なコンテンツを提供すること」がSEOのコアとなってくることは間違いないでしょう。
Googleの「Don't be evil」を信じましょう😇
参考にしたリソースたち
最後に私が調べる際に参考にしたサイトたちを載せます。
JS siteのSEO情報
-
JavaScript Sites in Search Working Group
- JS siteでのSEO関連のトラブルや質問ができるメーリスです。
-
YouTube - GoogleWebmaster
- たまに日本でもOffice Hourというライブ配信をやっていて質問ができたりします。
-
海外SEO情報ブログ - 海外のSEO対策で極めるアクセスアップ術
- 神サイトです。多分これちゃんと毎日追ってるだけでエキスパートになれる。
Dynamic Rendering
- Headless Chrome: an answer to server-side rendering JS sites | Tools for Web Developers | Google Developers
- Deliver search-friendly JavaScript-powered websites (Google I/O '18) - YouTube
- ダイナミック レンダリングの使用方法 | 検索 | Google Developers
- Prerender - AngularJS SEO, ReactJS SEO, or VueJS SEO
Googleのレンダリング事情
- Google 検索でのレンダリング | 検索 | Google Developers
- SPA and SEO: Google (Googlebot) properly renders Single Page Application and execute Ajax calls
メタ情報のSSR
- GAになったLambda@Edgeを使ってSPAをSSR無しでOGPとかに対応させてみる
- Lambda@Edge – Intelligent Processing of HTTP Requests at the Edge | AWS News Blog