Motive
twitter分析ページを作成して約2年が経ちました。従来はTwitterAPIで取得したデータをMySQLにストックしていましたが、 あるテーブルは約2億レコードと膨大になってしまったためorder by でなくてもselect count(*) from TWEET などといったシンプルなSQLでも約数十分かかります。システム構造もEC2にMySQLを導入したサーバーにデータを追加してたので、仮に /etc/my.cnf でメモリサイズを最大化し、EC2自体の t3.micro から t3.large に変更しても限界があります。
それで解決方法としてはGoogle Cloud Service の Bigquery を使うこととしました。利点としては数テラのかなり大きめのテーブルでも約数10秒で結果が出力されることです。金額はクエリを使うごとに発生はして、数テラのかなり大きめのテーブルを全てのカラムを使ってクエリをかけた場合は結構かかります。しかし、数カラムだけを使ってwhereで使うデータを制限すれば金額がかからないので問題ないと思っています。
ここで問題になるのは数億あるテーブルをどのようにBigqueryへ移行するかです。 普通であればmysqldumpでjsonにoutputしてGCPのストレージに転送すればいいのですが、jsonを作成するのにかなり時間がかかることとテーブルの中にツイート文を扱っているので特殊文字が対応しない可能性がありそうです。ここでは、大規模なデータ処理が可能なpysparkを使ってファイルを出力し、Bigqueryへ転送する方法を紹介したいと思います。
Preparetion
pyspark の導入方法
anaconda上でpysparkをインストールしました。
conda install -c conda-forge pyspark
AWS EC2
データ移行前のEC2のタイプはt3.microを使っていましたがこのままではメモリ不足になってしました。結果としては、t3.xlarge(メモリ16GB)までアップグレードしないと無理だったです。いくらpyspark内で分散処理をしようとしても巨大なテーブルをメモリ上にのせる必要があったみたいです。
GCP Bigquery
移行先のテーブルに追加するデータセットを作成します。リージョンは適宜決める。
Method
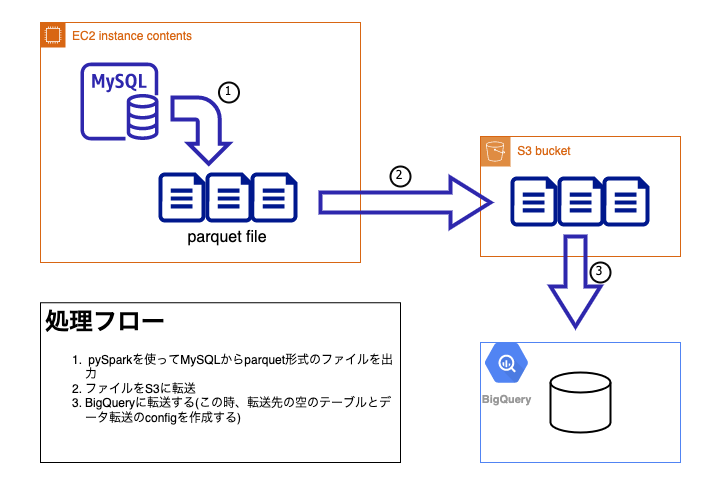
下記の流れでデータ移行しました。
ひとつのテーブルに対してファイルをひとつ作るのは無理だったので、データ取得した日のタイムスタンプを使って1ヶ月単位に分割してファイルを出力しました。
- [GCP]bigqueryで空のテーブルを作成する
- [AWS]pysparkを使ってデータをparquet形式のファイルとしてoutputする
- [AWS]parquetファイルをS3に転送する
- [GCP]bigqueryのデータ転送を使って設定を作成する
Detail
[GCP]bigqueryで空のテーブルを作成する
- テーブルを追加したいデータセットから「テーブルを作成」を選ぶ
- カラムとテーブル名を入力してテーブルを作成する
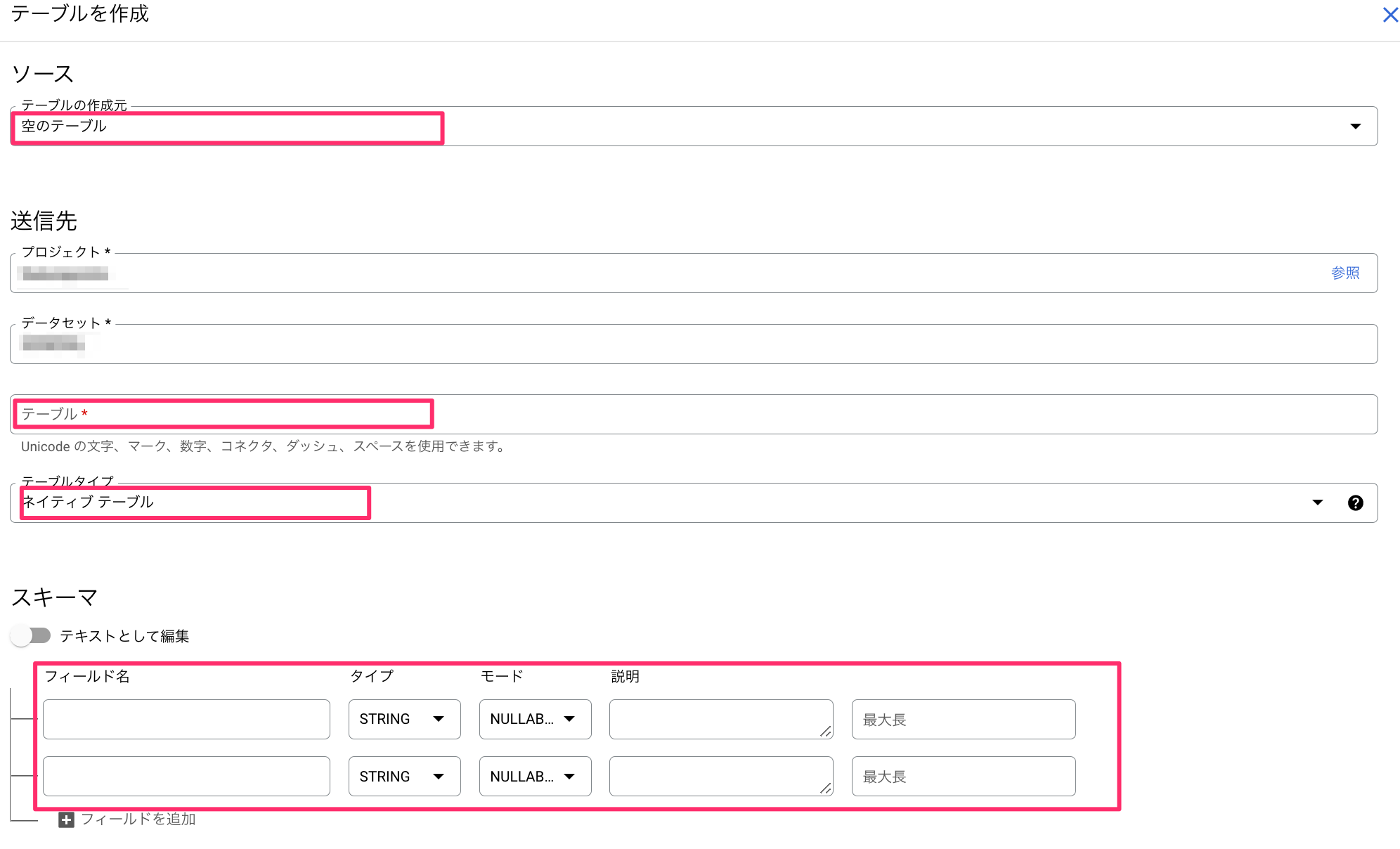
- テーブルの作成元:空のテーブル
- テーブルタイプ:ネイティブテーブル
[AWS]pysparkを使ってデータをparquet形式のファイルとしてoutputする
from pyspark.sql import SparkSession
import argparse
import os
import time
JDBC_URL = "jdbc:mysql://[***データベース ホスト名***]/[***データベース データベース名***]"
DRIVE_CLASS = "com.mysql.cj.jdbc.Driver"
DB_USER = "[***データベース ユーザ名***]"
DB_PASSWORD = "[***データベース パスワード***]"
def main():
parser = argparse.ArgumentParser()
parser.add_argument('table_name', help='テーブル名')
parser.add_argument('begin', help='where from')
parser.add_argument('end', help='where to')
parser.add_argument('output', help='出力されるフォルダ名')
args = parser.parse_args()
start = time.time()
print(f"{args.table_name}:{args.begin}:{args.end}")
#pyspark 初期設定
spark = SparkSession.builder.config("spark.jars", "/usr/share/java/mysql-connector-java.jar")\
.config("spark.driver.memory", "2g")\ #メモリ設定
.master("local").appName("PySpark_MySQL_test")\
.getOrCreate()
#MySQLに接続し、ターゲットテーブルをもとにデータフレームを作成
df = spark.read.format("jdbc").option(
"url", JDBC_URL).option(
"driver", DRIVE_CLASS).option(
"user", DB_USER).option(
"password", DB_PASSWORD).option("dbtable", args.table_name).load()
#範囲指定する
df_filtered = df.filter(f"'{args.begin}' <= created_at and created_at < '{args.end}'")
print(df_filtered.count())
#parquetファイルを作成
df_filtered.write\
.parquet(os.path.join(os.path.dirname(os.path.abspath(__file__)), args.output))
elapsed_time = (time.time() - start) / 60
print(f"処理時間:{elapsed_time}分")
if __name__ == "__main__":
main()
ポイントとしてはpysparkの設定時にドライバのメモリを設定する部分です。 デフォルトは1GBなので実行環境内でのメモリを増設している場合はそれ相応の数字にする必要があります。この時は前述の通りEC2t3.xlargeでメモリが16GBあったので12GBに設定しました。
また、一度にファイル作成すると膨大に時間がかかるかメモリがオーバーフローするので、whereで数ヶ月単位で区切ってparquetファイルを出力しています。
[AWS]parquetファイルをS3に転送する
aws cli を使ってparquetファイルをS3に転送します。
aws s3 cp XXXXXXXXX.parquet s3://[バケット名]/XXXXX/
awsのコマンドがなければ pip3 install awscli でpipインストールします。
[GCP]bigqueryのデータ転送を使って設定を作成をする
S3のフォルダに格納したparquetファイルをBigqueryに転送します。Bigqueryには「データ転送」の機能があるのでこれを使います。
- 「データ転送」を選ぶ
- 「転送を作成」を選ぶ
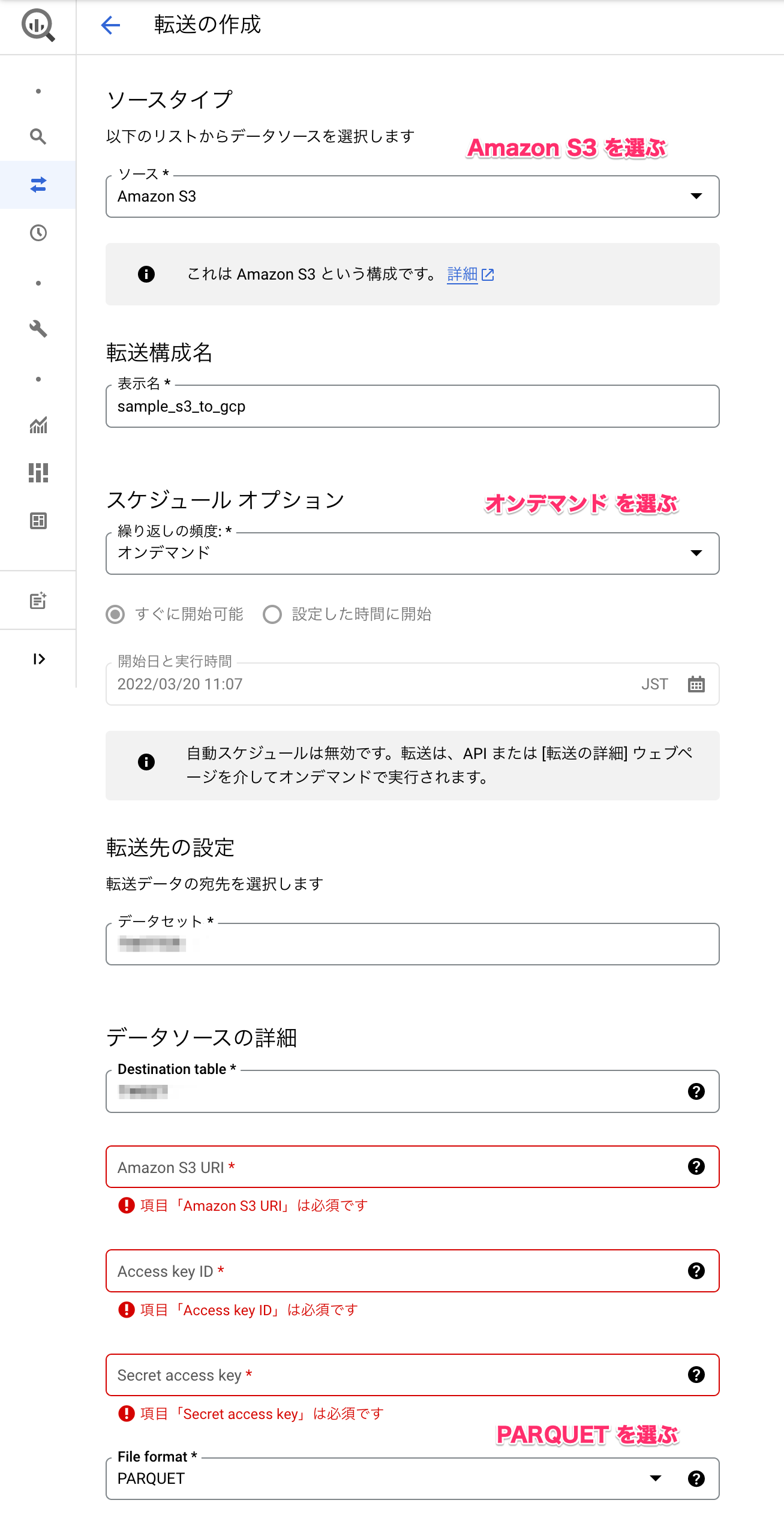
- 設定を記述して「保存」を押す
| カテゴリ | 項目 | 選択項目 or 記述例 |
|---|---|---|
| ソースタイプ | ソース | Amazon S3 (固定) |
| 転送構成名 | 表示名 | sample_s3_to_gcp |
| スケジュールオプション | 繰り返しの頻度 | オンデマンド (固定) |
| 転送先の設定 | データセット | <対象のデータセット> |
| データソースの詳細 | Destination Table | <対象のテーブル> |
| Amazon S3 URL | <送信元S3のparquetファイルリンク> | |
| Access key ID | ||
| Secret access key | ||
| File Format | PARQUET(固定) |
このときに事前にIAM(Identity and Access Management)からユーザ作成とAmazonS3FullAccessの権限が付与されたIAMロールが必要になります。「Access key ID」「Secret access key」の取得方法については、AWS アクセスキーを作成するを参照し、csvファイルをダウンロードしてください。
- リストから作成した設定を選び、「今すぐ転送を実行」を選んで転送を実行する。
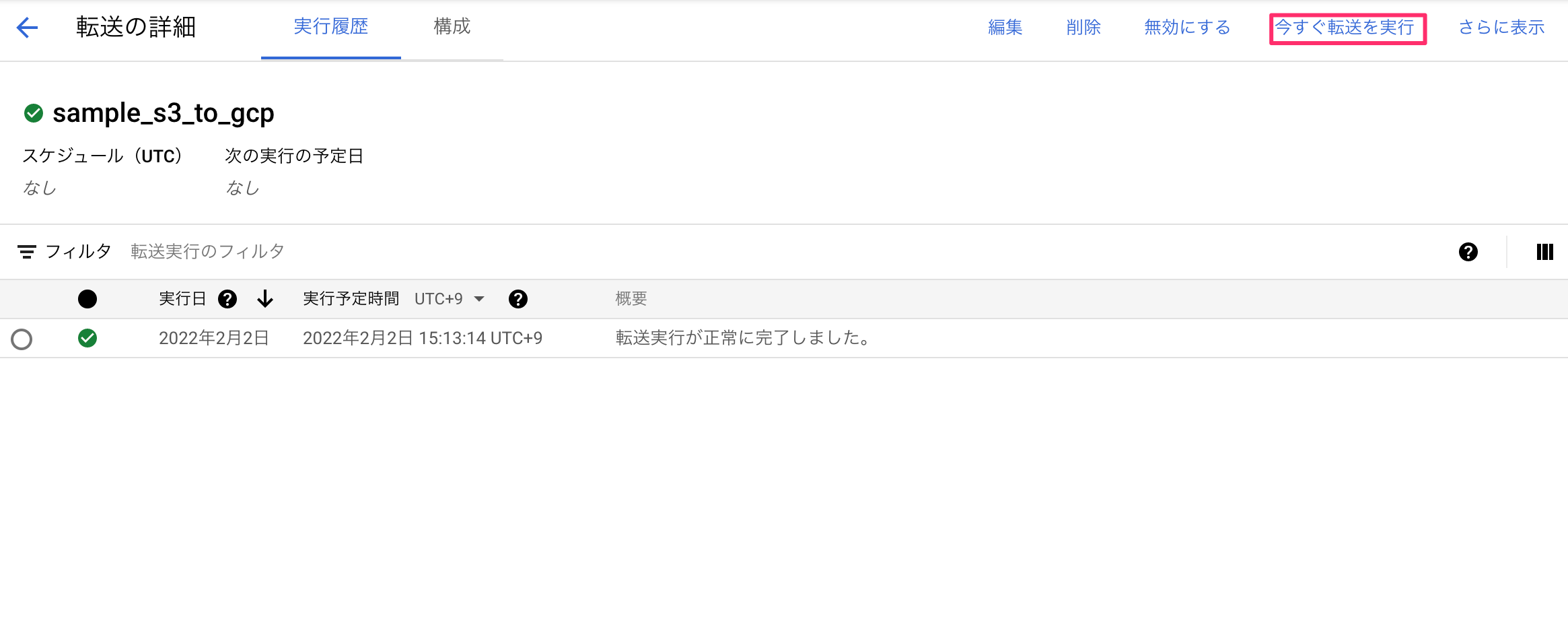
ここまでできれば転送されるまで少し待てば転送先のテーブルにデータ移行ができてると思います。
PostScript
今回はS3を経由してデータ転送する方法を紹介しましたが、後ほど試した方法でGCPのGoogle Cloud Storage経由でデータ転送すると空のテーブルを手動で作成することなく、自動でテーブルにデータ転送されるみたいです。次回はGoogle Cloud Storage経由でデータ転送する方法を紹介したいと思います。