Background
[OpenCV][C++]テンプレートマッチングを使って複数検出してみた、ではOpenCVのTemplateMatchingを使ってクリボーを検出していました。用意したクリボーの画像を上から下へ走査して形状が類似しているエリアを算出するのですが、上部の雲がクリボーと似ているらしくて雲とクリボーが一緒に出てくると雲の方が先に検出がかかってしまいました。
大雑把に類似度の高いエリアをトリミングして、その後でテンプレート画像とヒストグラムか背景差分を使って判定はできそうなのですが、今回は趣向を変えてyolov3を使った物体検出をしてみます。
Device
- CPU AMD Ryzan 5 1400
- GPU GeForce GTX960
- Mother Board MSI B450 GAMING PLUS MAX B450
- Memory DDR4 8G × 4枚 = 32G
- CUDA 10.0
- cuDNN 7.4
Environment
必要なライブラリをインストールだーと思って、pytorch 公式を見るとanacondaベースで話が進んでいます。今までは python3 -m venv [envname]で仮想環境を作ってその中で必要なパッケージをpipを使ってインストールしていたのですが、DeepLearning系のライブラリは他のパッケージとの依存性が結構ありそうなのでanaconda 使うことにします。
conda install pytorch==1.6.0 torchvision==0.7.0 cudatoolkit=10.1 -c pytorch
cudaの環境は10.0のままですが、cudatoolkitのバージョンを10.1でセットしても問題なく学習はできました。GPU周りの設定は少しバージョンが違うと動作の段階でエラーになってしまうので、本当であれば合わせた方がいいです。
pytorch + yolov3
PyTorch-YOLOv3を使います。
git cloneしてデータセットとweightファイルをダウンロードします。
cocoなので相当重いです。
git clone https://github.com/eriklindernoren/PyTorch-YOLOv3
cd PyTorch-YOLOv3/
sudo pip3 install -r requirements.txt
cd weights/
bash download_weights.sh
cd data/
bash get_coco_dataset.sh
その後で、動作するか確認します。
python3 test.py --weights_path weights/yolov3.weights
それで問題なさそうであれば、デフォルト設定であるもので物体検出できるか確認します。
検出したい画像をdata/samplesに格納して、detect.pyで実行します。
python3 detect.py --image_folder data/samples/
ワークフォルダ直下に outputフォルダが生成されるので、中身を見てみると物体検出でマークされた画像が格納されています。
Annotation
デフォルトではcocoをデータセットとして使った学習済みのweightファイルがあり、80の物体を検出することができます。今回は開発者個人が検出させたい物体があった場合の機械学習方法を書いていきます。
流れとしては、対象の物体がある画像を100枚を用意し、それぞれの画像にどの場所に何の物体があるかをAnnotation(注釈、ラベル付け)して、最後にtrain.pyで実行して学習します。
データセットは、Backgroundで書いた通りSuper Mario Bros (NES) Level 1-1の動画を使います。何のデータを使って機械学習をすればいいかを考えて悩むのですが、1つの結論として著作権が大丈夫そうなゲーム動画を使うのが良さそうです。というのは現実で撮った画像よりもゲームの方が決まった固定のキャラが繰り返し登場し、形状もいくつかのパターンしかないので学習結果がすぐに得られやすいと思います。また、動画なので1秒あたり約30~60画像に落とし込むことができるので容易に取得できます。
それで、annotationをつけるのにlabelmeのツールを使います。
作業用PCはMacなので、homebrewでQt5をインストールして、pipで本体をインストールします。
brew install pyqt
pip install labelme
labelmeを起動する前に、訓練用データを用意します。
今回はSuper Mario Bros (NES) Level 1-1の23-28秒の動画を抜き出し、下記の方法で連番の画像に落とし込んでいます。
訓練用データ

wget https://raw.githubusercontent.com/wkentaro/dotfiles/f3c5ad1f47834818d4f123c36ed59a5943709518/local/bin/video_to_images
pip install imageio imageio-ffmpeg tqdm
python video_to_images your_video.mp4
実行すると、 your_video フォルダができるてその中に連番画像が格納されています。
これで訓練用データが揃ったので、先程のフォルダパスを指定してlabelmeを起動します。
labelme ./your_video
あとは、もくもくと物体のラベルと領域を指定します。
150枚程ありました。
yolov3で学習する場合は、boundingboxと四角形で範囲指定するだけでいいのですが、後でsegmentationで学習するDNNを扱うかもしれないので無駄に領域指定してます![]()
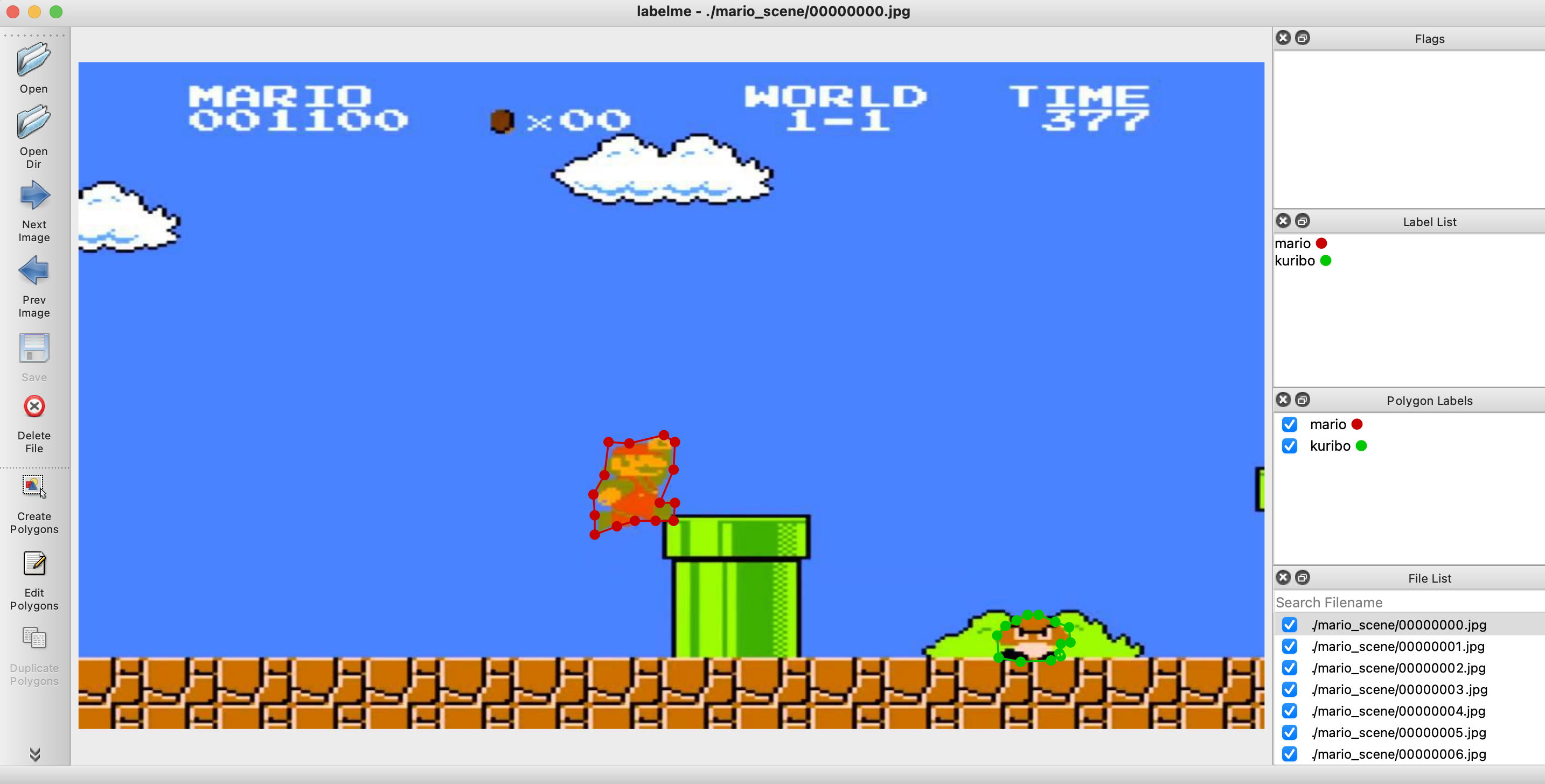
物体につけたラベルと領域はjsonファイルとして画像を読み込んだフォルダ先に生成されます。
完了後は、圧縮ファイルにしておきます。
tar -zcvf output.tar.gz ./your_video
Training
訓練データが用意できたので、次は機械学習をしてみます。
まず、configファイルを作ります。ここでは __ignore__ を含めるとクラス数は3つなので、<num-classes> =3で設定します。
実行後は、config/yolov3-custom.cfgがアウトプットされます。
cd config/
bash create_custom_model.sh <num-classes>
config/custom.dataを開いてクラス数を設定します。
classes=3
train=data/custom/train.txt
valid=data/custom/valid.txt
names=data/custom/classes.names
data/custom/classes.names を開いて物体名をリスト化します。デフォルトではtrainしか書かれてないと思います。
__ignore__
mario
kuribo
次に圧縮した訓練用データフォルダを直下に置いて解凍します。
tar -zxvf output.tar.gz
解凍したフォルダから画像をdata/custom/images/へ移動させます。
デフォルトはdata/custom/images/に電車の画像があるので削除します。
rm data/custom/images/train.jpg
mv ./your_video/*.jpg data/custom/images/
次にラベル情報が書かれているjsonファイルをもとに、[クラスID] [物体の中心座標x] [物体の中心座標y] [物体の幅] [物体の高さ]に書き換えます。このとき、元データではなく全体の画像に対する比率[0,1.0]を出力します。書き換えたファイルはdata/custom/labels/に生成します。
import os
import json
import numpy as np
def treat(filepath, classes):
with open(filepath, "r") as fin:
src = json.load(fin)
dst = []
for item in src["shapes"]:
txt = item["label"]
#各座標の平均値を計算
cx, cy = np.mean(np.array(item["points"]), axis=0)
#画像全体の長さを1.0とした場合の比率を計算
cx_norm = cx / src["imageWidth"]
cy_norm = cy / src["imageHeight"]
#物体の幅・高さを計算
min_x, min_y = np.min(np.array(item["points"]), axis=0)
max_x, max_y = np.max(np.array(item["points"]), axis=0)
rect_width = (max_x - min_x) / src["imageWidth"]
rect_height = (max_y - min_y) / src["imageHeight"]
#クラスIDを検索
idx = list(filter(lambda x: x[1] == txt, classes))[0][0]
#配列にして整形
dst.append([idx, cx_norm, cy_norm, rect_width, rect_height])
return dst
最後にdata/custom/train.txt(訓練用)とdata/custom/valid.txt(評価用)にそれぞれdata/custom/images/に格納したファイルパスを書き込みます。比率は (訓練用):(評価用)=8:2がちょうどいいと思います。
data/custom/images/00000000.jpg
data/custom/images/00000001.jpg
data/custom/images/00000002.jpg
data/custom/images/00000003.jpg
data/custom/images/00000004.jpg
data/custom/images/00000005.jpg
data/custom/images/00000006.jpg
data/custom/images/00000007.jpg
data/custom/images/00000008.jpg
data/custom/images/00000009.jpg
data/custom/images/00000010.jpg
data/custom/images/00000011.jpg
data/custom/images/00000012.jpg
data/custom/images/00000013.jpg
data/custom/images/00000014.jpg
data/custom/images/00000015.jpg
...
設定は一通り終わったので、train.pyを実行します。
python3 train.py \
--model_def config/yolov3-custom.cfg \
--data_config config/custom.data \
--batch_size 2 \
--img_size 32 \
--epochs 200 \
--pretrained_weights weights/darknet53.conv.74
batch_sizeのデフォルトは8、img_sizeは416ですがマシン性能が弱いとメモリエラーが出てしまいます。自分のPCもGPUのメモリは4GBしかないのでアウトでした。その場合は、値を下げると正常に学習が進みます。
学習結果は checkpoints/に各エポックごとにyolov3_ckpt_{エポック数}.pthが出力されます。
Detect Objects
まず、物体検出用の画像データを準備します。ここでは、Super Mario Bros (NES) Level 1-1のスタートからゴールまでの動画フレームを使います。動画から連番画像に変換する方法は訓練用データで作成したのと同様にvideo_to_imagesスクリプトを使います。トータルで1501の画像を取得することができました。
それで、detect.pyを使って検出をかけてみます。
python3 detect.py --image_folder ./data/mario_1-1/ \
--weights_path ./checkpoints/yolov3_ckpt_199.pth \
--model_def config/yolov3-custom.cfg \
--class_path data/custom/classes.names
--image_folderでテストしたい画像が入っているフォルダのパスを指定して、--weights_pathには学習で生成されたファイルを使います。結果は outputファイルに格納されます。
(239) Image: './data/mario_1-1/00000239.jpg'
+ Label: mario, Conf: 0.99997
...

あとは、連番画像から動画に変換して完了です。
最初はffmpegで ffmpeg -r 30 -i %8d.png -vcodec libx264 -pix_fmt yuv420p -r 60 out.mp4 として変換をかけたのですが画質が極端に落ちてしまいました。
(ffmpegで連番画像から動画生成 / 動画から連番画像を生成 ~コマ落ちを防ぐには~を参照)
なので、OpenCVを使って動画に変換しました。
import cv2
import os
def main():
is_png = lambda x : os.path.splitext(x)[1] == ".png"
imgs = list(filter(is_png, os.listdir()))
imgs.sort()
width = 480
height = 270
fps = 30
fmt = cv2.VideoWriter_fourcc('m', 'p', '4', 'v')
writer = cv2.VideoWriter('output.mp4', fmt, fps, (width, height))
#resize
for img in imgs:
mat = cv2.imread(img)
dst = cv2.resize(mat, dsize=(width, height))
writer.write(dst)
writer.release()
if __name__ == "__main__":
main()
Consequence
↓クリックするとyoutubeでスタートからゴールまでの検出する様子が動画で見れます。

- ファイアマリオは学習してないのですが、風貌が似ているのでmarioと識別しています。
- ちびマリオは学習していないため、高さが似ているためかクリボーと誤認識する場合があります。
- ブロック、宝箱、ノコノコなどを物体の検出対象にするとさらに精度は良くなると思います。