はじめに
Lakeflow パイプライン エディター の概要は以下です。
現時点(2025/8)ではベータ版の機能となります。
実際に動かす処理は以下のチュートリアルを使用しました。
事前準備
今回の内容は Free Edition 環境で実行しています。
環境が準備できたら、チュートリアルの手順0に従ってデータをセットアップします。
パイプラインの作成
「ジョブとパイプライン」から「ETL パイプライン」を選択

「Lakeflow パイプラインエディター」をオン
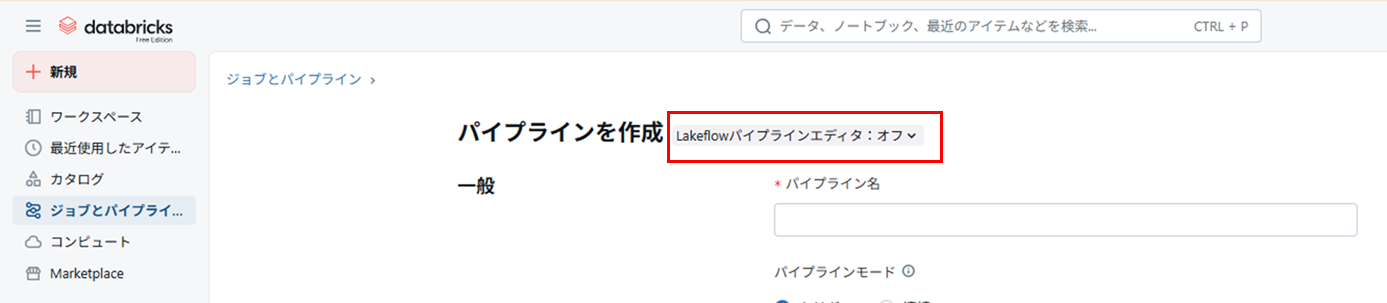
パイプライン名を入力、デフォルトのカタログ・スキーマを選択して「空のファイルで開始」を選択
(パイプライン名、カタログ・スキーマは後でも変えられるので適当で OK )
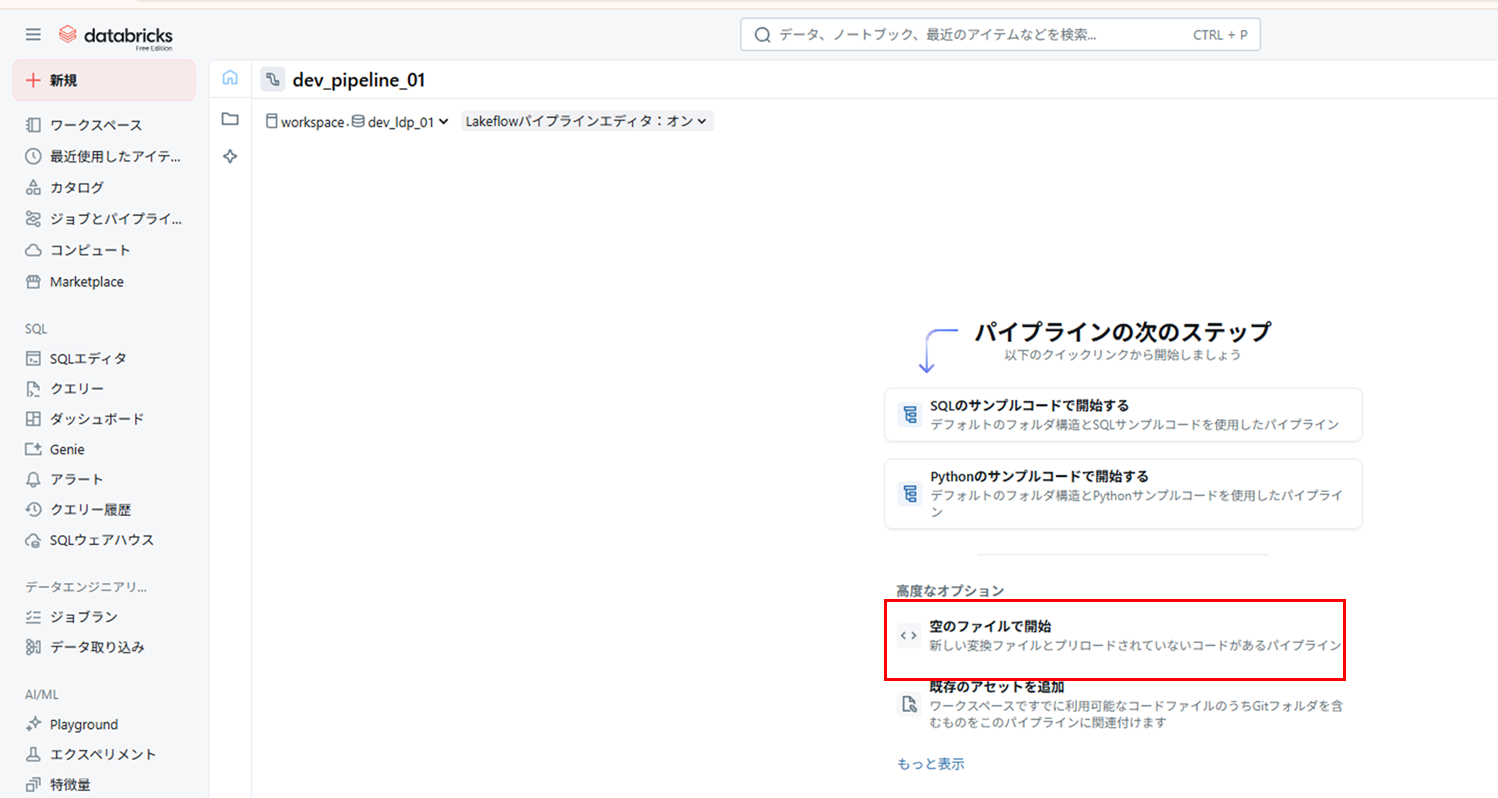
パイプラインのルートフォルダを選択(後からでも変更可能)
空のパイプラインが完成
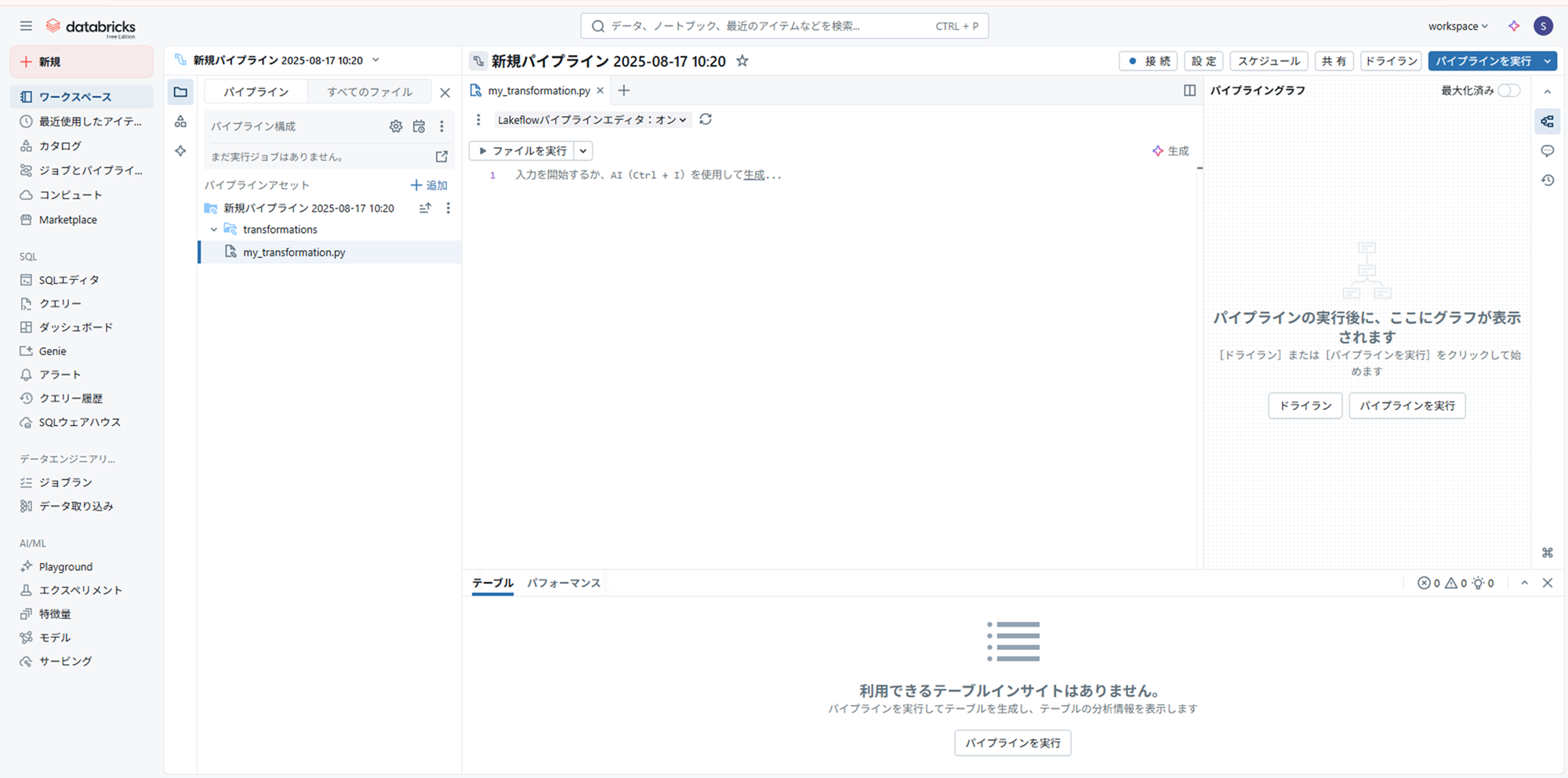
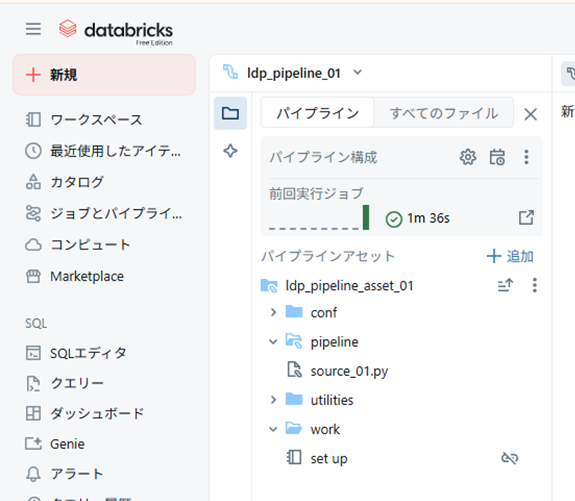
フォルダ構成は以下のようにしてみました。
- ldp_pipeline_asset_01:ルートフォルダ
- pipeline:パイプラインソースコードフォルダ(パイプラインで実際に動くコードを格納する場所)
- conf など:普通のフォルダ(モジュールとして使うファイル等を格納する場所、例としてここでは work フォルダにデータをセットアップしたノートブックを置いてます)
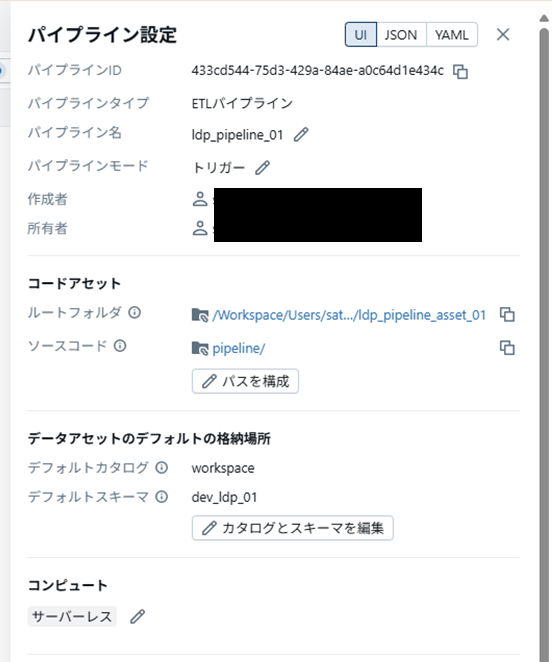
右上の「設定」を選択すると、コードアセットやデフォルトのカタログ・スキーマを変更できます。
処理の作成
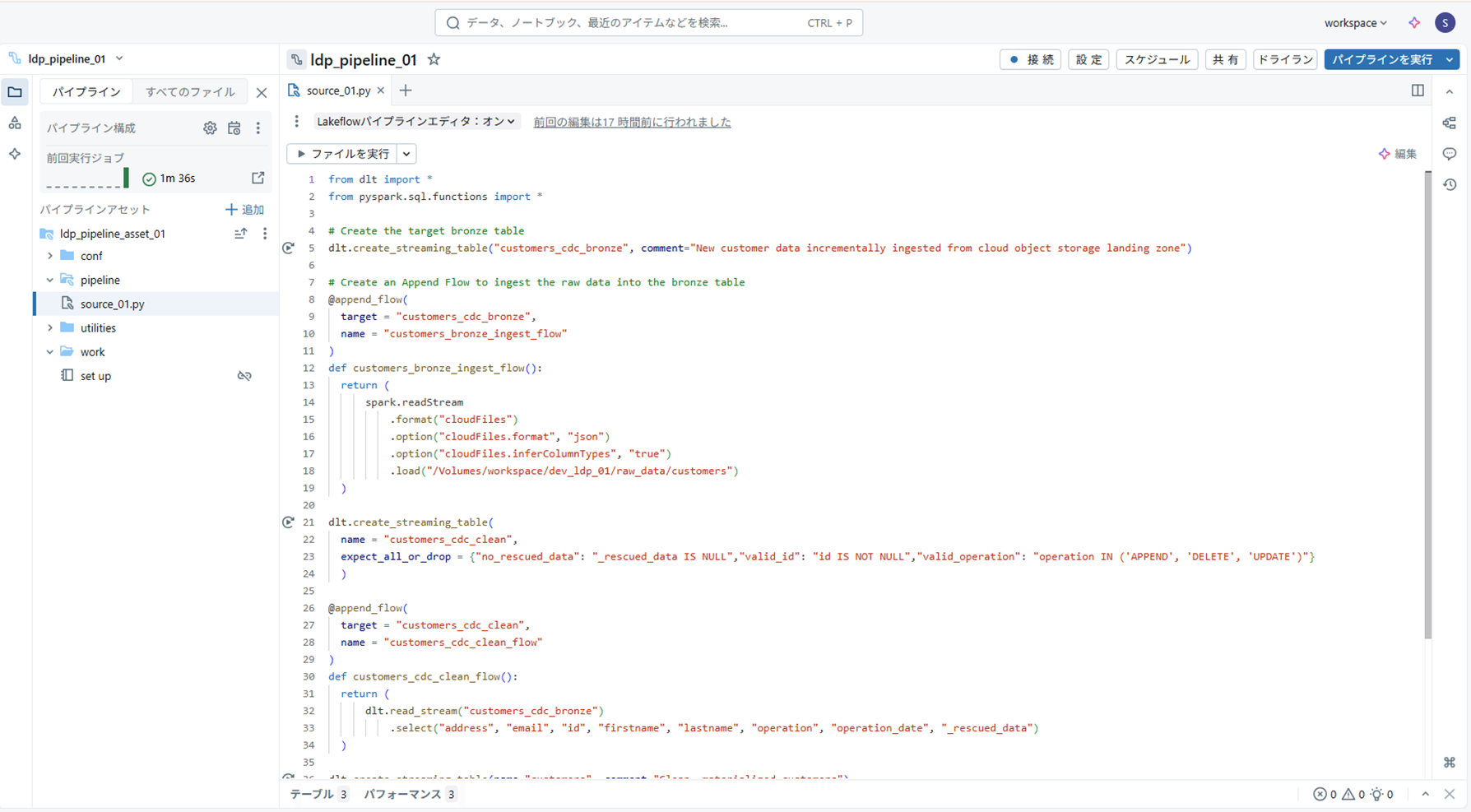
ソースコードフォルダ配下の py ファイルに、チュートリアルの手順2~手順4の Python コードを貼り付け
( Volume パス等はご自身の環境に合わせて適宜修正してください)
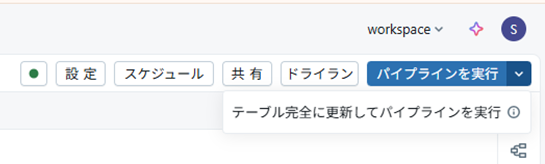
実行方法は3種類
- ドライラン:実際には処理されずにコードを確認できる
- パイプラインを実行(デフォルト更新):新しいレコードを処理
- テーブルを完全に更新して~~(フルリフレッシュ):すべてのレコードを再処理
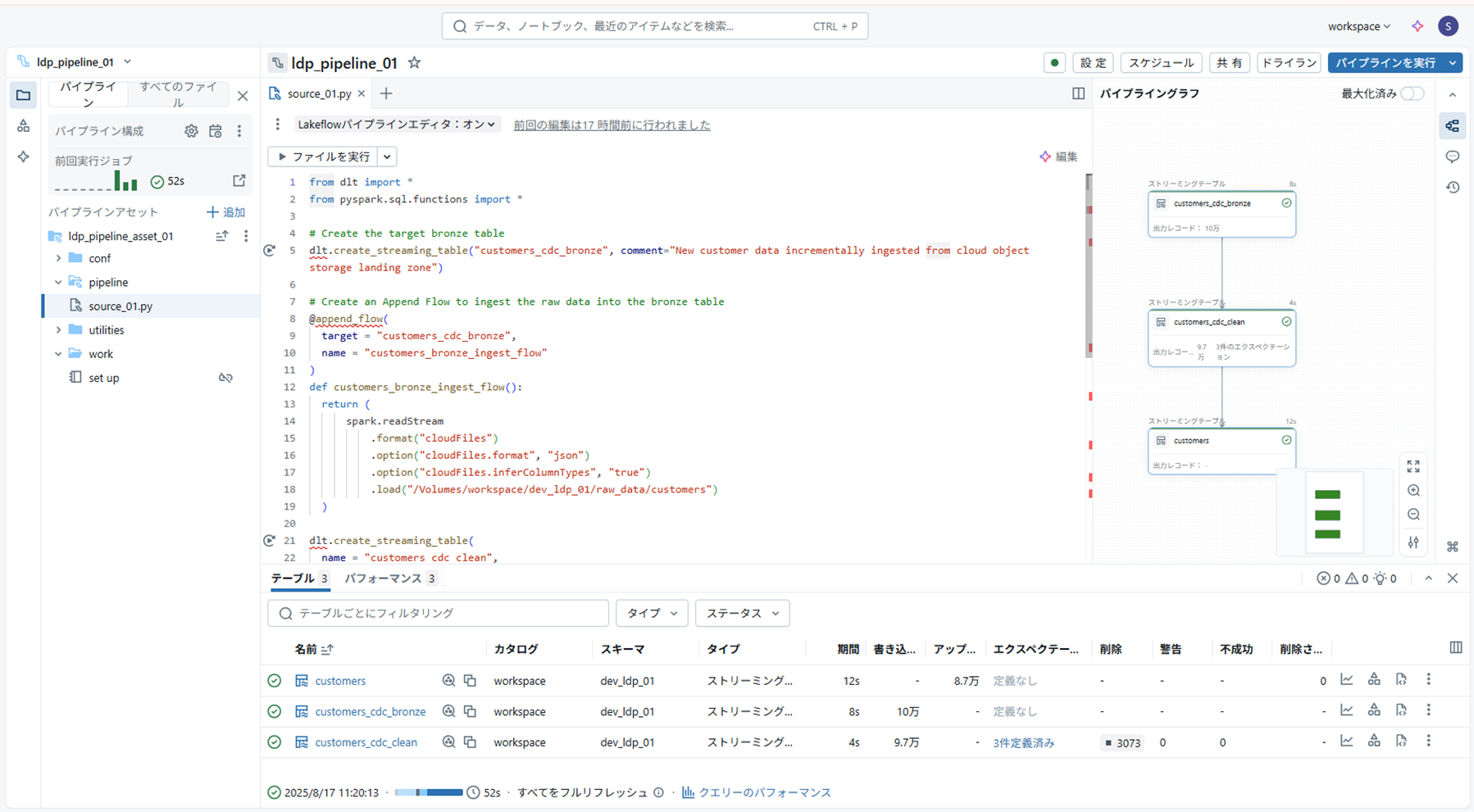
実行結果は以下のように確認できます。
Tips
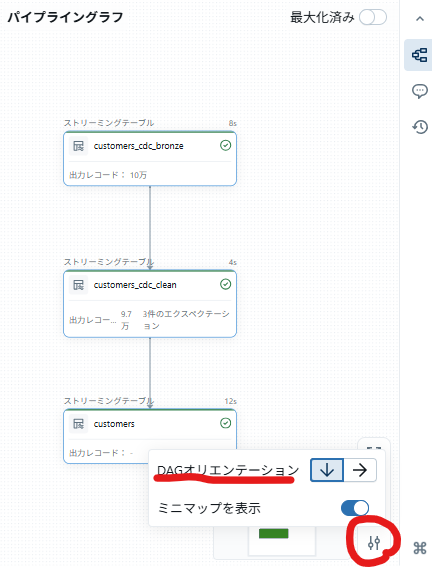
- DAG は縦型にすると見やすいです
- ソースコードはノートブックではなくファイルが推奨されています
