Livebook 上で VegaLite を使って、埼玉県オープンオープンデータの 「【埼玉県】新型コロナウイルス感染症の発生状況【参考】」 を描画してみました。まずはローカルにあるCSVファイルを読み込むところから、試行錯誤をしました。全体的にもう少しスマートなやり方があるかもしれませんが、参考までに。
関連記事
VegaLite で埼玉県を切る( Elixir, Livebook) - Qiita
Vega-Lite の View Composition (Elixir, Livebook) - Qiita
VegaLite の基礎 (Elixir, Livebook) -Qiita
Livebook 事始め (Elixir) - Qiita
1. ローカルファイルを読み込む
VegaLite で扱う data は data_from_url/1 で簡単にリモートから取り込むことができました。しかし data がローカルにある場合はどうすればよいでしょうか? 私の場合、うまい解決策が見つからなかったので、 Elixir の CSV ライブラリ NimbleCSV を使って、強引に取り込みました。もっとスマートな手がある気がするのですが。
NimbleCSV
前の記事で作ったグラフをもう一度描いてみたいと思います。
まず、seattle-weather.csv ファイルを Livebook プロジェクトのトップに置きます。
以下の、インストールを行います。
Mix.install([
{:vega_lite, "~> 0.1.6"},
{:kino_vega_lite, "~> 0.1.4"},
{:jason, "~> 1.2"},
{:nimble_csv, "~> 1.1"}
])
alias VegaLite, as: Vl
alias NimbleCSV.RFC4180, as: CSV
以下の部分が CSVファイルの取り込みプログラムです。CSVヘッダーの処理とか数値変換とか、汎用性はありません。
data =
"seattle-weather.csv"
|> File.stream!()
|> CSV.parse_stream()
|> Enum.map(fn
[date, precipitation, temp_max, temp_min, wind, weather] ->
%{date: date,
precipitation: String.to_float(precipitation),
temp_max: String.to_float(temp_max),
temp_min: String.to_float(temp_min),
wind: String.to_float(wind),
weather: weather}
# x -> IO.inspect(x)
end)
以下のコードは、以前のものと全く同じです。
Vl.new()
|> Vl.data_from_values(data)
|> Vl.mark(:bar)
|> Vl.encode_field(:x, "date", time_unit: :month, type: :ordinal, title: "Month of the year")
|> Vl.encode(:y, aggregate: :count, type: :quantitative)
|> Vl.encode_field(:color, "weather", type: :nominal, title: "Weather type",
scale: [domain: ["sun", "fog", "drizzle", "rain", "snow"],
range: ["#e7ba52", "#c7c7c7", "#aec7e8", "#1f77b4", "#9467bd"]])
結果は全く同じです。

2. 埼玉県のコロナ感染状況を描いてみる
埼玉県のオープンデータのサイトから、コロナ感染状況データのCSVをダウンロードします。colo.csv と名付けて Livebook のプロジェクトのトップに置きます。漢字コードがSJISになっているので UTF-8 に変換します。
data =
"colo.csv"
|> File.stream!()
|> CSV.parse_stream()
|> Enum.map(fn
[no, date, age, sex, city] ->
%{no: no, date: date, age: age, sex: sex, city: city}
# x -> IO.inspect(x)
end)
Vl.new()
|> Vl.data_from_values(data)
|> Vl.mark(:line)
|> Vl.encode_field(:x, "date", time_unit: [unit: :monthdate, step: 7], type: :ordinal)
|> Vl.encode(:y, aggregate: :count, type: :quantitative)

埼玉県 の中でも、さいたま市 の占める割合はどんなものでしょうか。Layer を使って、埼玉県全体のグラフ に、さいたま市のグラフ を重ね合わせます。赤いラインが さいたま市 です。
Vl.new()
|> Vl.layers([
Vl.new()
|> Vl.data_from_values(data)
|> Vl.mark(:line)
|> Vl.encode_field(:x, "date", time_unit: [unit: :monthdate, step: 7], type: :ordinal)
|> Vl.encode(:y, aggregate: :count, type: :quantitative),
Vl.new()
|> Vl.data_from_values(data)
|> Vl.transform(filter: "datum.city === 'さいたま市'")
|> Vl.mark(:line)
|> Vl.encode_field(:x, "date", time_unit: [unit: :monthdate, step: 7], type: :ordinal)
|> Vl.encode(:y, aggregate: :count, type: :quantitative)
|> Vl.encode(:color, value: "#db646f")
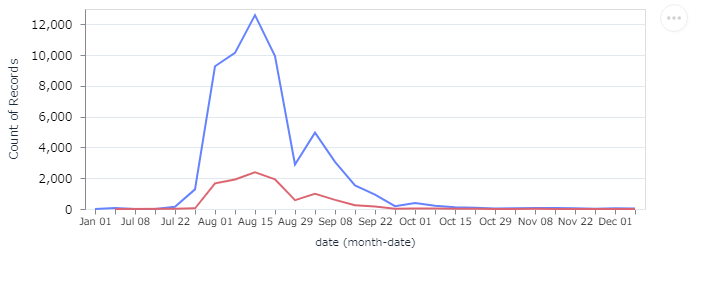
年代によるグラフを考えます。生データには「10代」とか漢字で入力されていますし、未就学児 とかで入力されているものもあります。それと性別で色分けしていますが、これも 不明 とか 調査中
とか、人間の目で見ることしか考えていないデータとなっています。コンピュータ処理を前提としていないのですね。
Vl.new()
|> Vl.data_from_values(data)
|> Vl.mark(:bar)
|> Vl.encode_field(:x, "age", type: :ordinal)
|> Vl.encode(:y, aggregate: :count, type: :quantitative)
|> Vl.encode_field(:color, "sex", type: :nominal)

次に、市町村 ごとの感染状況を見たいと思います。
topnum = 30
header = Enum.map(1..topnum, & String.pad_leading(Integer.to_string(&1)<>".", 3, "0"))
counter = Enum.frequencies_by(data, & &1.city)
counter = Enum.sort(counter, fn {_, v1}, {_, v2} -> v1> v2 end)
counter = Enum.zip_with(header, counter,
fn i, {k, v} -> %{city: i<>k, counter: v} end)
Vl.new()
|> Vl.data_from_values(counter)
|> Vl.mark(:bar)
|> Vl.encode_field(:y, "city", type: :nominal)
|> Vl.encode_field(:x, "counter", type: :quantitative)
埼玉県は 市町村 が多いので 感染が多い順にトップ30 だけ表示したいと思います。

以下 data の前処理部分を解説していきます。このような処理は Livebook で書いていくと大変楽に書けることが実感できました。 実験しながら書いていけるので。Enumは大変便利なので、多用しています。
y 軸は市町村名がマップされますが、名前でソートされてしまいます。ソートをコントロールするために「さいたま市」を「01.さいたま市」などと名前の前に順位の数字を追加する処理を行います。String.pad_leading/3 で3桁の0パディングを実現しています。2桁数字+ dot で3桁です
header = Enum.map(1..topnum, & String.pad_leading(Integer.to_string(&1)<>".", 3, "0"))
header = ["01.", "02.", ..,"20."]
Enum.frequencies_by/2 で data の中の市町村の頻出数を計算します。一発ですね。
counter = Enum.frequencies_by(data, & &1.city)
counter = %{"八潮市" => 922, "上尾市" => 1596, "あきる野市" => 1, "杉戸町" => 276, "五霞町" => 1, ...}
counter のキーは無視してバリューのみでソートします。
counter = Enum.sort(counter, fn {_, v1}, {_, v2} -> v1> v2 end)
counter = [{"さいたま市", 10687}, {"川口市", 5771}, {"川越市", 2752}, {"越谷市", 2690}, {"所沢市", 2538}, {"草加市", 2486}, {"春日部市", 1883}, ...]
以下のコードで最終的なマップリストを作り出します。市町村の名前の前に2桁の数字がついていることに注意してください。zip 関数に初めて出会ったのは確か Haskell の例題で、最初は使い方が良くわからなかったのですが、今となっては便利なものだと思います。
counter = Enum.zip_with(header, counter,
fn i, {k, v} -> %{city: i<>k, counter: v} end)
counter ~ [%{city: "01.さいたま市", counter: 10687}, %{city: "02.川口市", counter: 5771}, %{city: "03.川越市", counter: 2752}, %{city: "04.越谷市", counter: 2690}, %{city: "05.所沢市", counter: 2538}, %{city: "06.草加市", counter: 2486}, %{city: "07.春日部市", counter: 1883}, ...]
単にグラフを書くよりも、データの取り込みや、データの前処理が結構面倒だと感じました。
今回は以上です。