この記事は、 RDBMS-GIS(地理情報・位置情報) Advent Calendar 2023 の25日目の内容になります。(が、遅れてしまって申し訳ありません...![]()
![]() )
)
背景
各DB(PostgreSQL/MySQL/SQLiteなど)での経路探索インターフェースについて調べようと思ったきっかけは色々ありますが、列挙すると以下のような形になります。
- FOSS4G Hokkaido 2018の懇親会で、@yyamasaki1 さんと、MySQLで Boost.Geometry でのジオメトリ演算に対応されたのなら、pgRoutingで利用している Boost Graph Library での経路探索とも相性が良いかもしれませんねとお話ししていたのを思い出した
- 最近では
MySQL shortest pathでググると、ノルウェー科学技術大学の以下の研究論文が引っかかった (※ただし、MySQL本体にはまだ取り込まれていない上に、アップストリーム側で未評価の可能性もあるので、以降の記述でも参考程度にお考えください) - FOSS4G Advent Calendar 2018 17日目の @yoh_chan さんの以下の記事で、SpatiaLiteでの実装内容が少し気になっていた
各DBでの最短経路探索インターフェース
経路探索には、多対多の最短経路探索や到達圏検索など、色々なバリエーションがありますが、最も基本的と思われる、1対1の最短経路探索(ダイクストラ法)について、各DBでのインターフェースがどうなっているのか調べてみました。
サンプルのネットワークデータ
サンプルのネットワークデータとしては、上記のMySQLのPRに含まれる、単体テストのネットワークデータを利用します。
ネットワークデータのノード・エッジテーブルの定義とデータ投入は以下のSQLを実行します。
CREATE TABLE nodes (
id INTEGER PRIMARY KEY,
x FLOAT,
y FLOAT
);
CREATE TABLE edges (
id INTEGER PRIMARY KEY,
from_id INTEGER,
to_id INTEGER,
cost FLOAT
);
INSERT INTO nodes VALUES
( 0, 0, 0), -- A 0
( 1, 2, 1), -- B 1
( 2, -1, -1), -- C 2
( 3, 2, -2), -- D 3
( 4, 1, 3), -- E 4
( 5, 4, 3), -- F 5
( 6, 4, 1), -- G 6
( 7, 3, -1), -- H 7
( 8, 6, 2), -- I 8
( 9, -2, 1), -- J 9
(10, -3, -2), -- K 10
(11, -1, 3); -- L 11
INSERT INTO edges VALUES
( 0, 0, 2, 1.5), -- A 0 -> C 2
( 1, 0, 3, 2.9), -- A 0 -> D 3
( 2, 0, 5, 5.0), -- A 0 -> F 5
( 3, 3, 1, 3.0), -- D 3 -> B 1
( 4, 2, 11, 2.0), -- C 2 -> L 11
( 5, 2, 10, 2.4), -- C 2 -> K 10
( 6, 2, 9, 2.4), -- C 2 -> J 9
( 7, 9, 4, 3.65), -- J 9 -> E 4
( 8, 4, 5, 4.0), -- E 4 -> F 5
( 9, 5, 8, 2.4), -- F 5 -> I 8
(10, 5, 6, 2.0), -- F 5 -> G 6
(11, 0, 7, 3.2), -- A 0 -> H 7
(12, 7, 6, 2.3), -- H 7 -> G 6
(13, 8, 6, 2.3), -- I 8 -> G 6
(14, 1, 6, 2.0); -- B 1 -> G 6
ネットワークデータを図示したものは以下のような形になり、
- 論文PDF内の23ページ目の図:
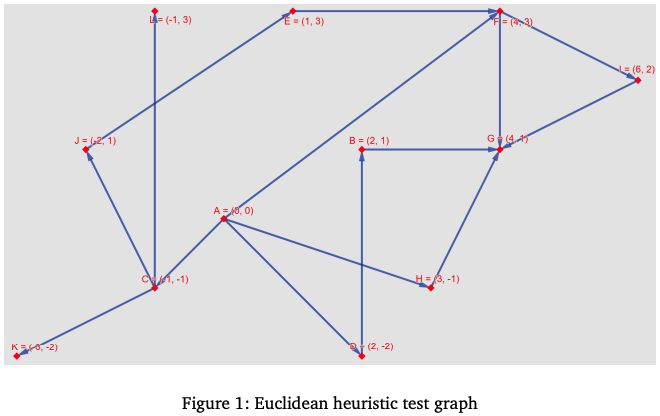
ノードA(id=0)からノードG(id=6)への最短経路とトータルコストは以下のようになります。
A 0 -> H 7 -> G 6 : 5.5
PostgreSQL/pgRouting
まずは業務でも使ったことのあるPostgreSQL/pgRoutingから確認してみます。
pgRoutingのドキュメントは 公式 と ワークショップ がありますが、ざっと概要を知るには、OSGeoLiveの pgRoutingのクイックスタート文書 が良いかもしれません。
pgRoutingのDockerイメージは、ここ数年提供されておらず、最新版を利用しようとするとビルドが必要になります。
私のmacOS環境(M1 Mac)では、Homebrewでも brew install pgrouting を実行して最新版(3.6.1)をインストール可能なのですが、最短経路探索関数実行時にクラッシュするなど問題も見られたため、以下のようにして最新版をビルドしてインストールしました。
% git clone git@github.com:pgRouting/pgrouting.git
% cd pgrouting
% git checkout -b 3.6.1 refs/tags/v3.6.1
% mkdir build
% cd build
% cmake ..
% make
% make install
- データベースを作成してpsqlで接続
% createdb -U postgres routing_example % psql -U postgres routing_example - サンプルのネットワークデータ にあるSQLをコピー&ペーストして実行
- pgRouting拡張機能を有効化
CREATE EXTENSION pgrouting CASCADE; - ダイクストラ法による最短経路探索を実行
SELECT * FROM pgr_dijkstra( 'SELECT id, from_id AS source, to_id AS target, cost, cost AS reverse_cost FROM edges', 0, 6, directed => true ); - 結果が以下のようにテーブル形式で出力されることを確認
seq | path_seq | start_vid | end_vid | node | edge | cost | agg_cost -----+----------+-----------+---------+------+------+------+---------- 1 | 1 | 0 | 6 | 0 | 11 | 3.2 | 0 2 | 2 | 0 | 6 | 7 | 12 | 2.3 | 3.2 3 | 3 | 0 | 6 | 6 | -1 | 0 | 5.5 (3 rows)
結果の node 列の値で最短経路のノードが、 A 0 -> H 7 -> G 6 の順となること、また、最終行の agg_cost 列の値でトータルのコストが 5.5 となることが分かります。
SQLite/SpatiaLite
次に、 @yoh_chan さんの以下の記事を参考に、SQLite/SpatiaLiteでの最短経路探索を確認してみます。
なお、こちらも私のmacOS環境(M1 Mac)のHomebrewで brew install spatialite-tools を実行してインストールすることは可能でしたが、pgRoutingと同様に最短経路探索実行時にクラッシュする問題が見られたため、QGIS 3.34に同梱されているSpatiaLiteモジュールを使用しました。
- QGISのブラウザパネルの [SpatiaLite] を右クリックして [データベースを作成...] を選択し、任意のフォルダを選択してファイル名に
routing_exampleを指定し、保存
- ブラウザパネルの [SpatiaLite] 配下に、作成した
routing_example.sqliteが表示されることを確認
- 上記を右クリックしてSQL実行することも可能と思われるものの、表示されるウィンドウが小さいため、QGISツールバーのメニューから [データベース] / [DB マネージャ...] を選択
- DBマネージャ画面で左側の [SpatiaLite] から作成した
routing_example.sqliteを選択し、しばらくすると右側に接続情報が出るのを確認
- ツールバーで左から2つ目の [SQLウィンドウ] ボタンをクリックし、クエリビューを表示
-
サンプルのネットワークデータ にあるSQLを上のテキストエリアに貼り付けて [実行] ボタンをクリック
- 以下のSQLを上のテキストエリアに貼り付けて [実行] ボタンをクリックし、
edgesテーブルから経路探索用のVirtualRoutingテーブルを作成SELECT CreateRouting( 'routing_net_data', 'routing_net', 'edges', 'from_id', 'to_id', NULL, 'cost', NULL, 0, 1 );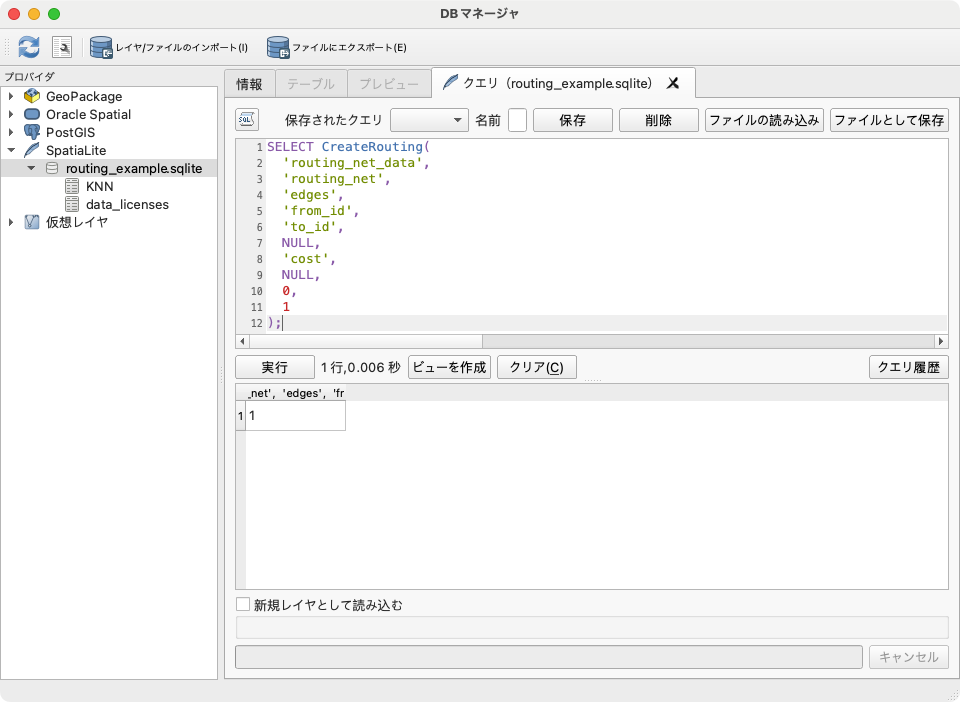
- 以下のSQLを上のテキストエリアに貼り付けて [実行] ボタンをクリックし、ダイクストラ法による最短経路探索を実行
SELECT * FROM "routing_net" WHERE "NodeFrom" == 0 AND "NodeTo" == 6;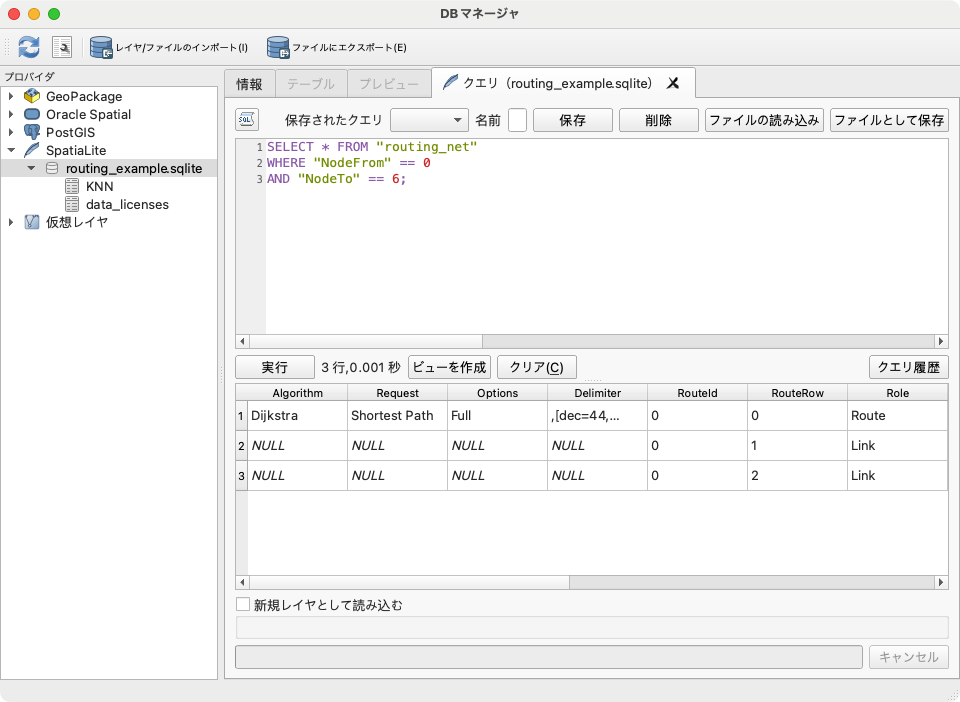
- 結果列に不要な情報も含まれているので、SQLを少し整形して再実行
SELECT RouteRow, Role, LinkRowid, NodeFrom, NodeTo, Cost FROM "routing_net" WHERE "NodeFrom" == 0 AND "NodeTo" == 6;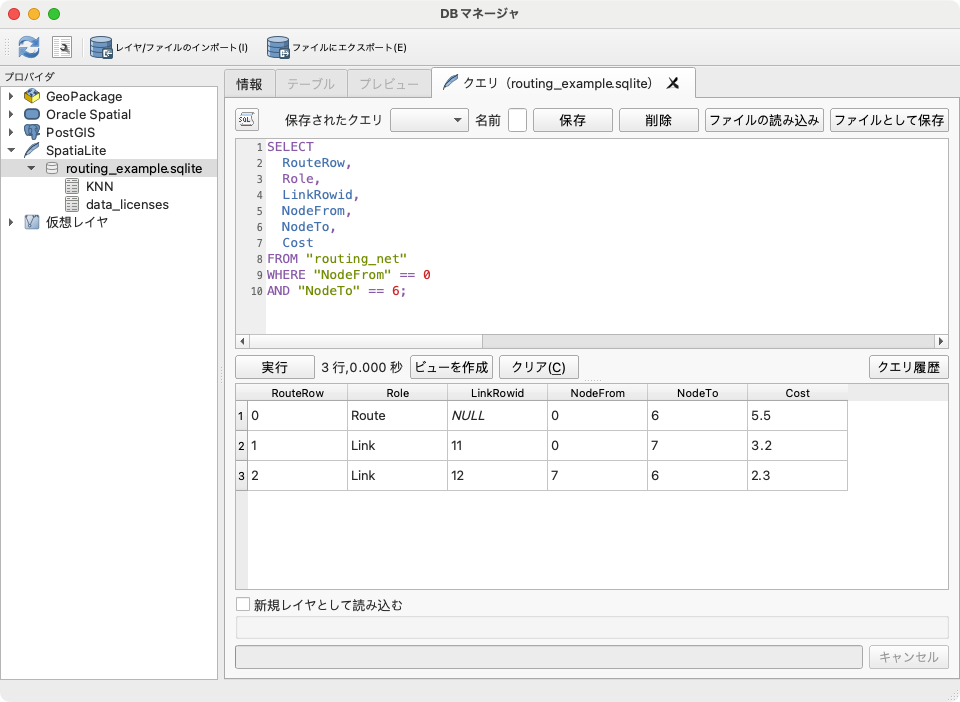
1行目の Role == 'Route' 行の Cost 列の値がトータルの5.5となること、また、 Role == 'Link' 行の NodeFrom/NodeTo 列の値で最短経路のノードが、 A 0 -> H 7 -> G 6 の順となることが分かります。
MySQL
MySQLはまだ経路探索が実装されていないのと、ローカル環境でのビルドに自信がなかったため実際に確認したわけではありませんが、以下のPR内容の修正がそのまま取り込まれると仮定した場合、
Add ST_SHORTEST_DIR_PATH by Erik-Kaasboll-Haugen · Pull Request #403 · mysql/mysql-server
SQLクエリと結果のインターフェースは以下のようになると思われます。
- SQLクエリ
SELECT ST_SHORTEST_DIR_PATH(id, from_id, to_id, cost, NULL, 0, 6) FROM edges; - 結果行
{"cost": 5.5, "path": [{"id": 11, "cost": 3.2}, {"id": 12, "cost": 2.3}], "visited_nodes": ?}
(※ visited_nodes には、処理中に探索したノード数が入るはずです。(最大で nodes テーブルのレコード数:12))
MSSQL (SQL Server)
MSSQL(SQL Server)でも、少し調べて見ると、2019以降では経路探索が可能なようでした。
- 最短パス (SQL Graph) - SQL Server | Microsoft Learn
- グラフの処理 - SQL Server and Azure SQL Database | Microsoft Learn
- MATCH (SQL グラフ) - SQL Server | Microsoft Learn
が、GIS機能の拡張としてよりは、サンプルにあるように、もっと汎用的なグラフ構造を意図しているようで、上記の他のDBほど手軽には扱えなさそうでした...。
Docker+sqlcmdでトライしたものの、だいぶ癖が強く、私には馴染めなさそうでしたが、一応確認手順を貼っておきます。
- Docker:SQL Server on Linux 用のコンテナーのインストール - SQL Server | Microsoft Learn
- コマンドラインでSQL Serverを使う最低限のメモ #SQLServer - Qiita
- DockerよりSQL Server起動
% docker pull mcr.microsoft.com/mssql/server:2022-latest % docker run -e "ACCEPT_EULA=Y" -e "MSSQL_SA_PASSWORD=Passw0rd" \ -p 1433:1433 --name sql1 --hostname sql1 \ -d \ mcr.microsoft.com/mssql/server:2022-latest % docker exec -it sql1 "bash" $ /opt/mssql-tools/bin/sqlcmd -S localhost -U SA -P "Passw0rd" - sqlcmdモードに入るので、データベースを作成
create database routing_example; go use routing_example; go - ノード・エッジテーブルを作成して、サンプルデータを投入
CREATE TABLE nodes (id INT PRIMARY KEY, x FLOAT, y FLOAT) AS NODE; go CREATE TABLE edges (cost FLOAT) AS EDGE; go INSERT INTO nodes VALUES ( 0, 0, 0), ( 1, 2, 1), ( 2, -1, -1), ( 3, 2, -2), ( 4, 1, 3), ( 5, 4, 3), ( 6, 4, 1), ( 7, 3, -1), ( 8, 6, 2), ( 9, -2, 1), (10, -3, -2), (11, -1, 3); go INSERT INTO edges VALUES ((SELECT $node_id FROM nodes WHERE id = 0), (SELECT $node_id FROM nodes WHERE id = 2), 1.5); go INSERT INTO edges VALUES ((SELECT $node_id FROM nodes WHERE id = 0), (SELECT $node_id FROM nodes WHERE id = 3), 2.9); go INSERT INTO edges VALUES ((SELECT $node_id FROM nodes WHERE id = 0), (SELECT $node_id FROM nodes WHERE id = 5), 5.0); go INSERT INTO edges VALUES ((SELECT $node_id FROM nodes WHERE id = 3), (SELECT $node_id FROM nodes WHERE id = 1), 3.0); go INSERT INTO edges VALUES ((SELECT $node_id FROM nodes WHERE id = 2), (SELECT $node_id FROM nodes WHERE id = 11), 2.0); go INSERT INTO edges VALUES ((SELECT $node_id FROM nodes WHERE id = 2), (SELECT $node_id FROM nodes WHERE id = 10), 2.4); go INSERT INTO edges VALUES ((SELECT $node_id FROM nodes WHERE id = 2), (SELECT $node_id FROM nodes WHERE id = 9), 2.4); go INSERT INTO edges VALUES ((SELECT $node_id FROM nodes WHERE id = 9), (SELECT $node_id FROM nodes WHERE id = 4), 3.65); go INSERT INTO edges VALUES ((SELECT $node_id FROM nodes WHERE id = 4), (SELECT $node_id FROM nodes WHERE id = 5), 4.0); go INSERT INTO edges VALUES ((SELECT $node_id FROM nodes WHERE id = 5), (SELECT $node_id FROM nodes WHERE id = 8), 2.4); go INSERT INTO edges VALUES ((SELECT $node_id FROM nodes WHERE id = 5), (SELECT $node_id FROM nodes WHERE id = 6), 2.0); go INSERT INTO edges VALUES ((SELECT $node_id FROM nodes WHERE id = 0), (SELECT $node_id FROM nodes WHERE id = 7), 3.2); go INSERT INTO edges VALUES ((SELECT $node_id FROM nodes WHERE id = 7), (SELECT $node_id FROM nodes WHERE id = 6), 2.3); go INSERT INTO edges VALUES ((SELECT $node_id FROM nodes WHERE id = 8), (SELECT $node_id FROM nodes WHERE id = 6), 2.3); go INSERT INTO edges VALUES ((SELECT $node_id FROM nodes WHERE id = 1), (SELECT $node_id FROM nodes WHERE id = 6), 2.0); go - 最短経路探索を実行
SELECT * FROM (SELECT node1.id AS node1_id, STRING_AGG(CONVERT(NVARCHAR(max), ISNULL(node2.id, 'N/A')), '->') WITHIN GROUP (GRAPH PATH) AS node_ids, LAST_VALUE(node2.id) WITHIN GROUP (GRAPH PATH) AS last_node, SUM(edges.cost) WITHIN GROUP (GRAPH PATH) AS total_cost FROM nodes AS node1, edges FOR PATH, nodes FOR PATH AS node2 WHERE MATCH(SHORTEST_PATH(node1(-(edges)->node2)+)) AND node1.id = 0) AS q WHERE q.last_node = 6; go - 結果が以下のように表示されることを確認 (※見やすいように整形しています)
node1_id node_ids last_node total_cost -------- --------- ---------- ----------- 0 5->6 6 7.0 (1 rows affected)
他と異なり、 A 0 -> H 7 -> G 6 でなく A 0 -> F 5 -> G 6 の経路となっていて、トータルコストも 7.0 となっていますが、SQL Serverが内部で利用しているアルゴリズムによるものかは不明です...。
おわりに
以上、ざっと各DBでの経路探索インターフェースについて調べてみました。
同じ最短経路探索でも、DBによってクエリ・出力インターフェースががらっと変わっていて、この辺りはPostGISなどのジオメトリ演算と異なり、OGCによるSimple Feature仕様の経路探索版がなかったことによる影響なのかもと思いました。
他に、SpatiaLiteのインターフェースもグラフバイナリを保持して高速化を図っているように思われ、遅いと言われるpgRoutingでの高速化のアイデアにも繋がりそうに思いました。
MySQLでも経路探索機能が近い将来正式に追加されて、盛り上がっていくと良いなぁと思っています。 ![]()
それでは、良いお年を!