0.前提
だいぶ期間が空いてしまいましたが前回の記事の続編(?)的なものです
https://qiita.com/sakudai/items/de164fa0b4d2c6480ee9
この記事を読むときは、上の記事を先に読むことをオススメします。
また、間違いなどありましたら教えて頂けるとありがたいです。
1.今回やること
強化学習では王道(?)の倒立振子をやりました。
解説は、スクリプトの解説を中心にやっていきます。
2. オブジェクトづくり
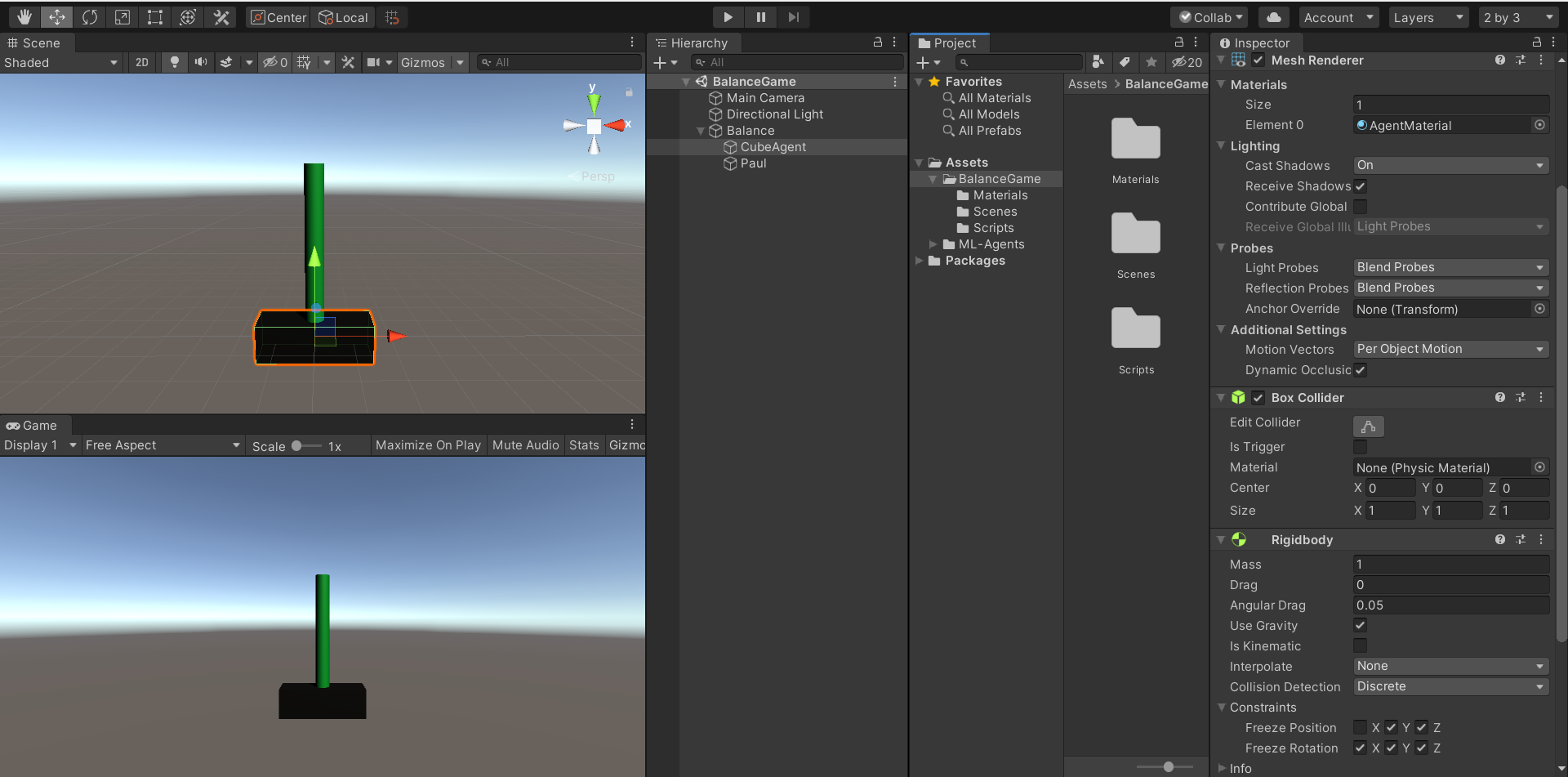
RigidBodyを付けたキューブの上に、RigidBodyを付けたポールを立てます。
環境の複製をしやすいように、キューブとポールを空オブジェクトの子供にしておいてください。
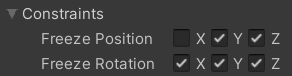
__キューブ__のRigidBodyは以下のように設定してください。
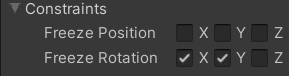
__ポール__のRigidBodyは以下のように設定してください。
3.本題
Agentスクリプトの作成
BalanceAgent(名前はお好きに)を作っていきます。
using UnityEngine;
using Unity.MLAgents; //書き忘れないように注意‼
using Unity.MLAgents.Sensors; //これも
public class BalanceAgent : Agent //Agentクラスを継承する
{
private Rigidbody m_cubeRigidBody = null;
[SerializeField,Header("ポールオブジェクト")]
private GameObject m_paulObj = null;
private Rigidbody m_paulRigidbody = null;
private void Awake()
{
m_cubeRigidBody = GetComponent<Rigidbody>();
m_paulRigidbody = m_paulObj.GetComponent<Rigidbody>();
}
//インスタンス生成時に呼ばれるメソッド
public override void Initialize()
{
}
//状態の提供を行う
public override void CollectObservations(VectorSensor sensor)
{
//キューブのX座標を取得
sensor.AddObservation(gameObject.transform.localPosition.x);
//ポールのZ方向の傾きを取得
sensor.AddObservation(m_paulObj.transform.rotation.eulerAngles.z);
//ポールのZ方向の角速度を取得
sensor.AddObservation(m_paulRigidbody.angularVelocity.z);
}
//ステップ毎にアクションを行う
public override void OnActionReceived(float[] vectorAction)
{
//入力に応じて移動する
m_cubeRigidBody.AddForce(new Vector3(vectorAction[0] * 10, 0, 0));
if (transform.localPosition.x < -10f || 10f < transform.localPosition.x)
{
//キューブが10以上中心からズレたら罰を与えてエピソード終了
AddReward(-1f);
//エピソード終了
EndEpisode();
return;
}
if (m_paulObj.transform.localPosition.y < transform.localPosition.y)
{
//ポールが落ちたら罰を与えてエピソード終了
AddReward(-1f);
//エピソード終了
EndEpisode();
return;
}
if (330f < m_paulObj.transform.rotation.eulerAngles.z || m_paulObj.transform.rotation.eulerAngles.z < 30f)
{
//ポールの傾きが30度未満なら報酬を与える
AddReward(0.01f);
}
else
{
//ポールが30度以上傾いたら罰を与えてエピソード終了
AddReward(-1f);
//エピソード終了
EndEpisode();
return;
}
}
//エピソード開始時の初期化
public override void OnEpisodeBegin()
{
//キューブを初期位置に戻す
gameObject.transform.localPosition = Vector3.zero;
//キューブの速度を初期化
m_cubeRigidBody.velocity = Vector3.zero;
//ポールを初期位置に戻す
m_paulObj.transform.localPosition = new Vector3(0f, 2.5f, 0f);
//ポールの速度を初期化
m_paulRigidbody.velocity = Vector3.zero;
//ポールの角度を初期化
m_paulObj.transform.localRotation = Quaternion.Euler(0f, 0f, 0f);
//ポールの角度をランダムに決める
float l_startAngle = Random.Range(-0.5f, 0.5f);
//直立を避ける
if(l_startAngle == 0) { l_startAngle = 0.1f; }
//ポールに傾きを与える
m_paulRigidbody.angularVelocity = new Vector3(0f, 0f, l_startAngle);
}
//ユーザー操作用
public override void Heuristic(float[] actionsOut)
{
actionsOut[0] = Input.GetAxis("Horizontal");
}
}
スクリプト貼り付け
キューブにBalanceAgentを貼り付けます。
__Packages/ML Agents/Runtime__にあるDecision Requesterをキューブに貼り付けます。
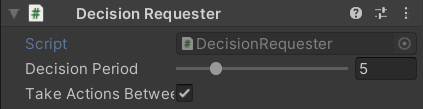
Decision Periodはアクション決定を何フレーム毎に行わせるか。
Take Actions Betwee~は決定をしないフレームの時にアクションを行うかのフラグです。
※Decision Periodが1の時はフラグによる変化がありません。
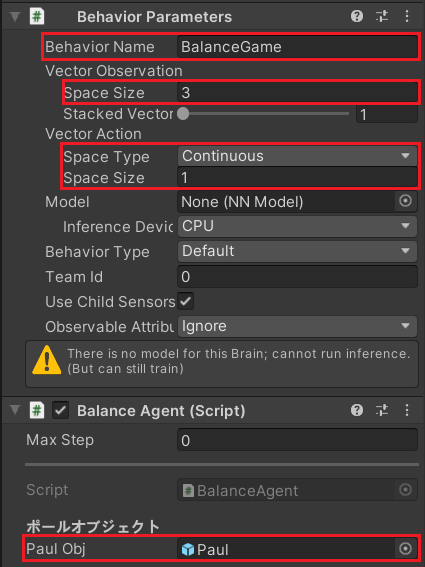
赤枠で囲った4ヵ所を画像のように変更してください。
yamlファイルの作成
__ML-Agentsフォルダ/config/ppo__の中にBalanceGame.yamlを作成します。
※txtファイルを作成して、拡張子を変更してください。
behaviors:
BalanceGame:
trainer_type: ppo
hyperparameters:
batch_size: 64
buffer_size: 12000
learning_rate: 0.0003
beta: 0.001
epsilon: 0.2
lambd: 0.99
num_epoch: 3
learning_rate_schedule: linear
network_settings:
normalize: true
hidden_units: 128
num_layers: 2
vis_encode_type: simple
reward_signals:
extrinsic:
gamma: 0.99
strength: 1.0
keep_checkpoints: 5
max_steps: 500000
time_horizon: 1000
summary_freq: 12000
threaded: true
各ハイパーパラメータについて詳しく知りたい方は下の記事を参考にしてみて下さい。
https://note.com/npaka/n/n7a5ff13eb91d
学習の開始
学習を始める前にまずは環境を複製しましょう。
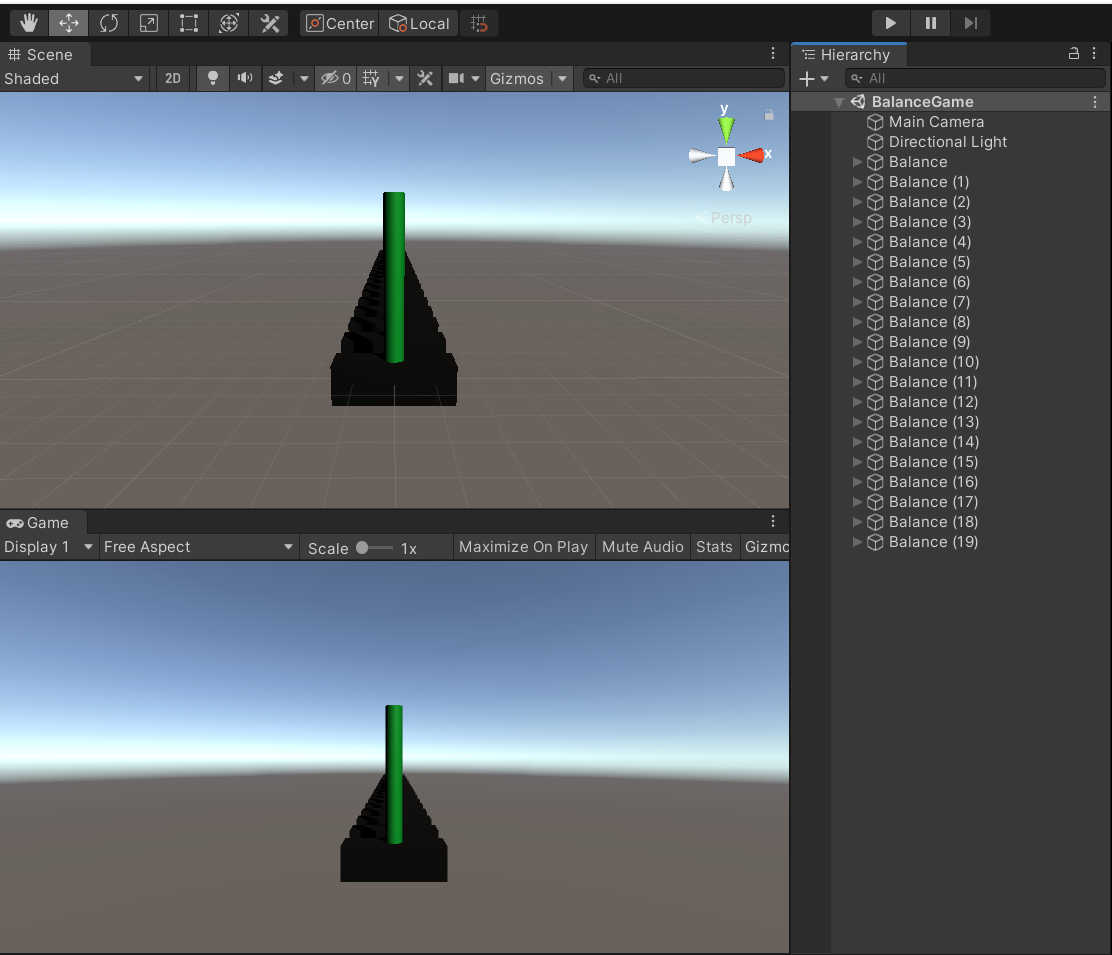
お互いに干渉しないようにZ方向に少しずつ離しておきましょう
これで準備は完了です。
さっそく学習を始めていきましょう。
mlagents-learn config/ppo/BalanceGame.yaml --run-id=[名前]
学習の始め方や、学習結果の反映方法などは前の記事を参考にして下さい。
https://qiita.com/sakudai/items/de164fa0b4d2c6480ee9
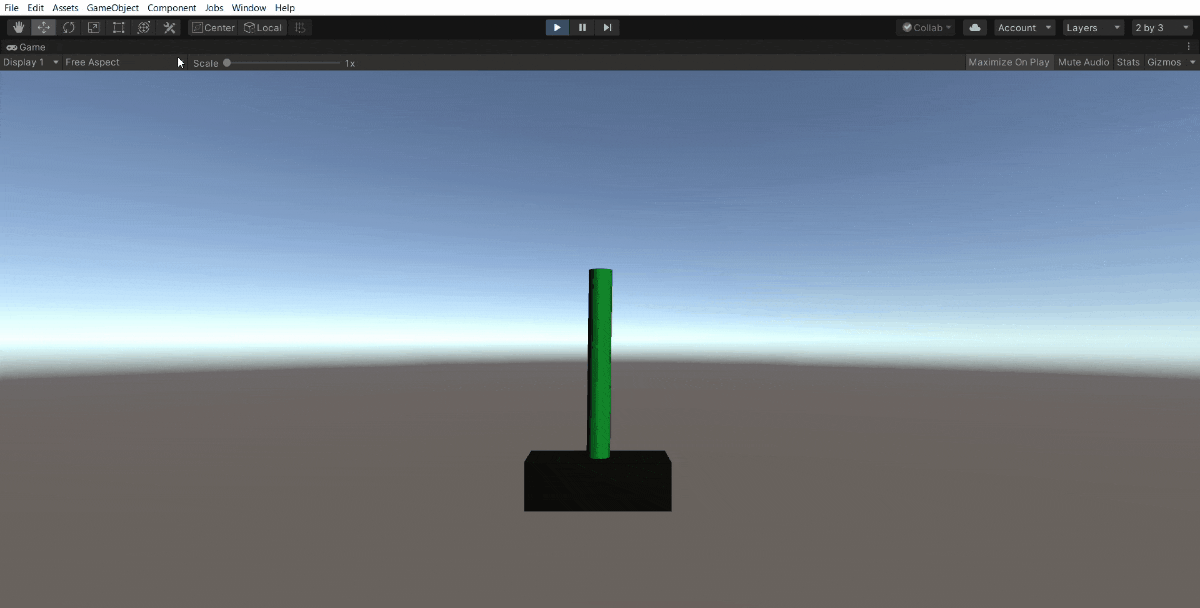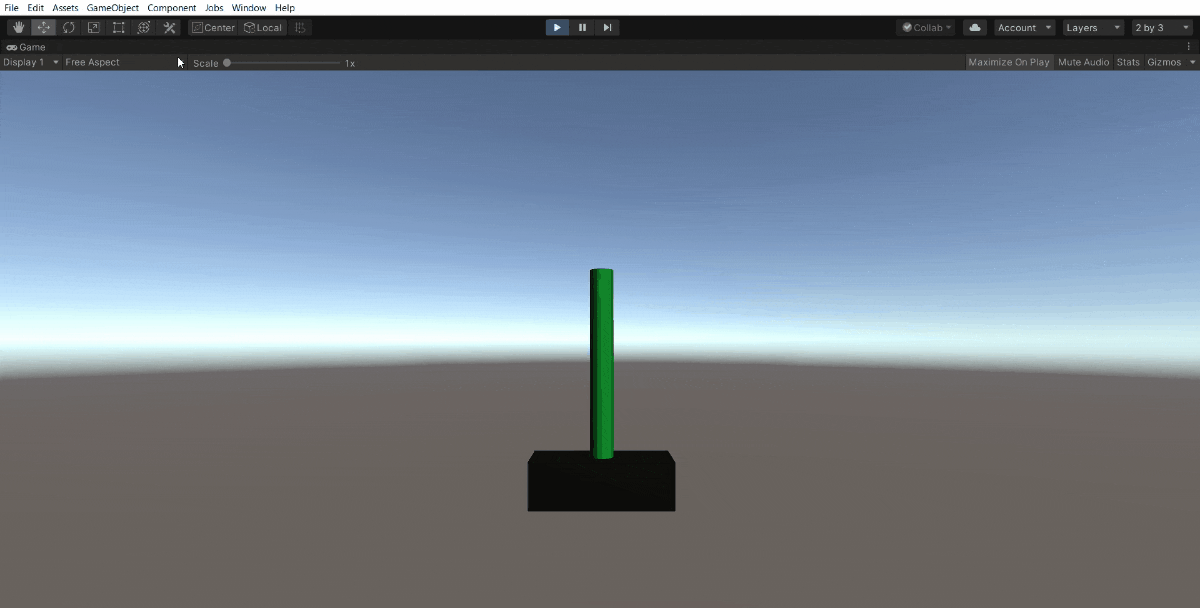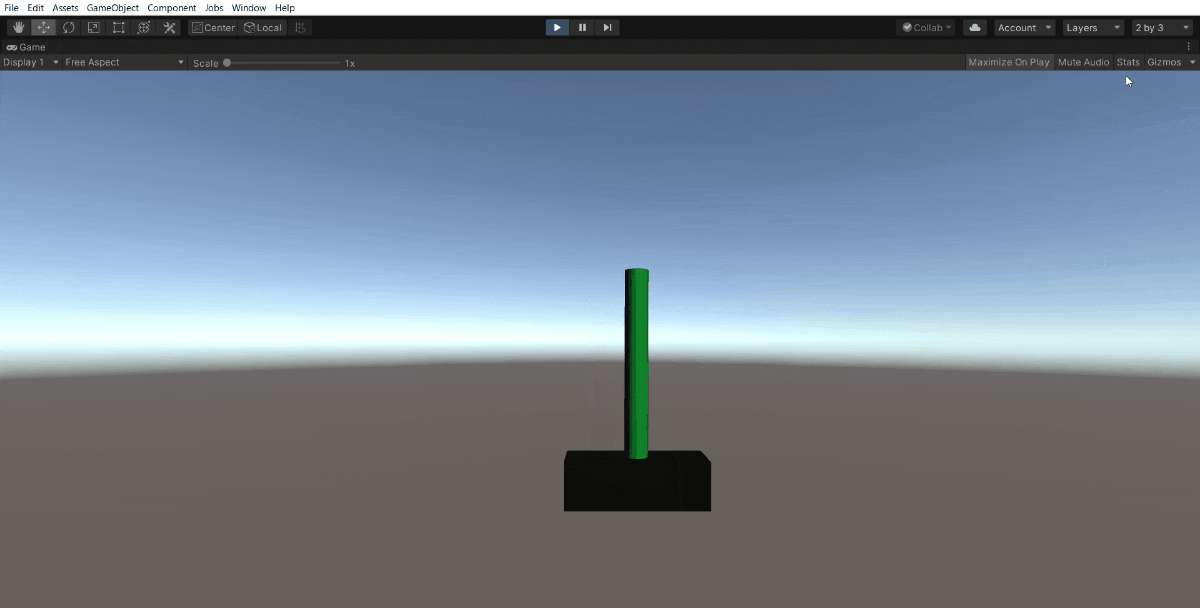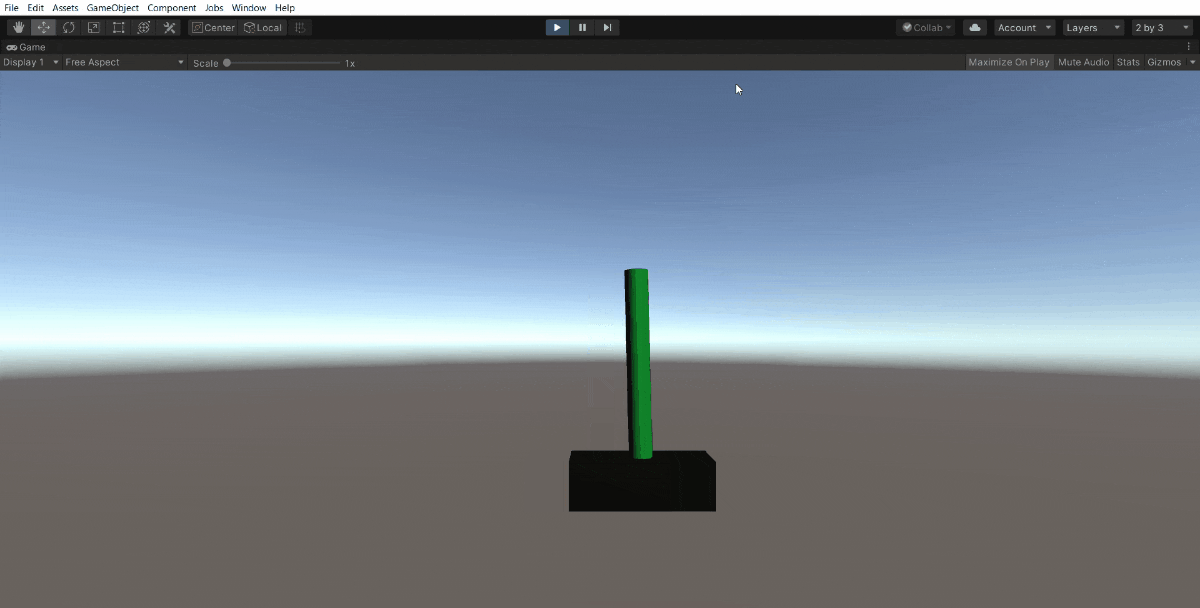
50万ステップでこうなりました。
ほとんど落とすことなく続けられます。
おわりに
最後まで読んでいただきありがとうございます。
もし、わからない点や、間違っている点がございましたら教えていただけたら幸いです。
また、少しでもためになったと思った方はLGTMしてくださると次以降のやる気に繋がりますのでお願いします!