はじめに
以前、S3上のデータを取得するためにDuckDBを利用する記事を書きました。
しかし、そちらでは Cloud9 を使っており、今から試そうと思うとなかなか難しいです。(Cloud9 帰ってきてくれ…!)
ということで、比較的サクッと使える CloudShell を使って同じことを試してみたいと思います。
DuckDBとは
DuckDBは、組み込み型のOLAP(分析向け)データベース管理システムです。OSSとして公開されており、以下のような特徴があります。
- 多様なファイル形式に対応:CSV、JSON、Parquet、Excelなど、様々なフォーマットをインポート・エクスポート可能
- 豊富なAPIサポート:Python(Pandas連携も可能)をはじめ、多様な言語から利用可能
- 軽量・高速:ローカル環境でサクッと分析できる
詳細は以下をご覧ください。
CloudShell とは
端的に言いますと、ブラウザから直接使えるコマンドライン環境です。
今回詳細は省きますが、こちらの記事を参照していただければイメージがつかめると思います。
CloudShellでDuckDBを使ってみる
それでは、実際にCloudShell上でDuckDBをセットアップし、S3上のデータを分析してみましょう。
Step 0:データの準備
雑に Claude にテストデータを作ってもらい、それらを S3 に置きました。

Step 1:DuckDBのインストール
CloudShellで以下のコマンドを実行します。
curl https://install.duckdb.org | sh
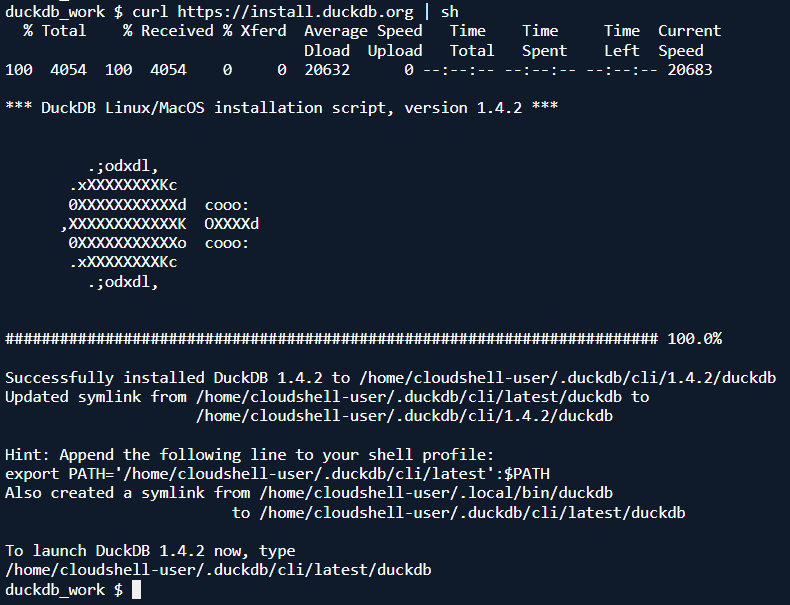
これだけでDuckDBが使えるようになります(ダックかわいい)。インストール方法の詳細は以下の Installation ページをご確認ください。
以下コマンドで実行することができます。
duckdb

Step 2:httpfs拡張のインストールと認証設定
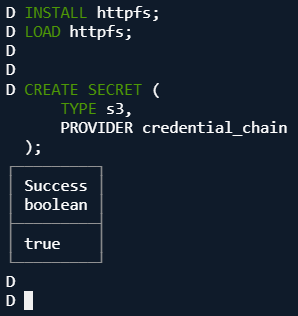
S3にアクセスするために、httpfs拡張をインストールし、クレデンシャルを設定します。
-- httpfs拡張のインストールと読み込み
INSTALL httpfs;
LOAD httpfs;
-- クレデンシャルの設定
CREATE SECRET (
TYPE s3,
PROVIDER credential_chain
);
これらのコマンドの詳細は以下のページを参照してください。
Step 3:テーブルの作成
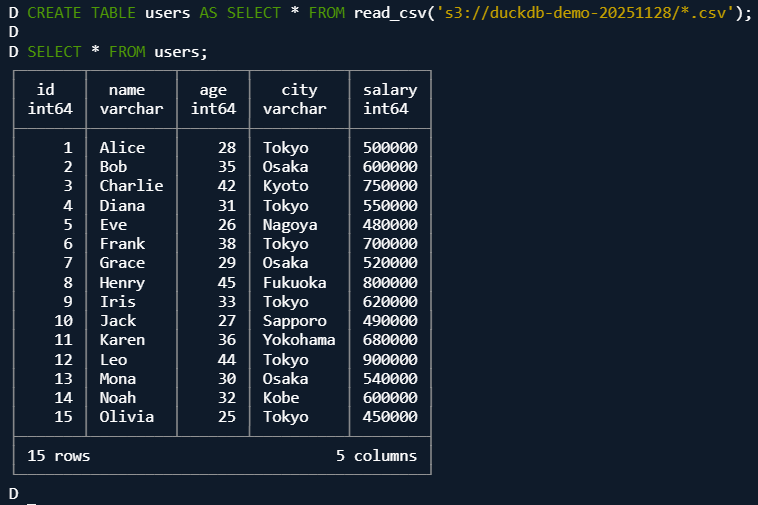
S3上のファイルからテーブルを作成してみます。
CREATE TABLE users AS SELECT * FROM read_csv('s3://duckdb-demo-20251128/*.csv');
Step 4:クエリの実行
あとは通常のSQLでクエリを実行できます。
SELECT * FROM users;
SELECT * FROM users ORDER BY salary DESC, age DESC;

きちんと値を取得できていることが分かります。
(おまけ)直接S3の情報を探索
先ほどはいったんテーブルを作成してデータを覗いていましたが、直接見ることもできます。
SELECT * FROM read_csv('s3://duckdb-demo-20251128/data1.csv') limit 3;
SELECT * FROM read_csv('s3://duckdb-demo-20251128/*.csv');

うまくいかないときは
S3へのアクセスがうまくいかない場合は、一度ローカルにファイルをコピーしてから処理する方法もあります。
aws s3 cp s3://duckdb-demo-20251128/data1.csv data

read_csv に渡すパスを変えるだけで、基本的には同じ要領でデータを扱うことができます。
SELECT * FROM read_csv('data/*.csv');
また、認証周りについて知りたい方は、以下の記事がとても参考になります。
まとめ
DuckDBは軽量で様々なデータ形式に対応しており、ちょっとしたデータ分析に最適なツールです。
- コストを気にせず何度でもクエリを試せる
- 環境構築も簡単
- S3のデータに直接アクセスして分析可能
- 状況によってはローカルにまるっとデータを落として、そこから分析する使い方もあり
今回触れませんでしたが、大規模データの定期的な分析など Athena が適している場合もありますので、ユースケースに応じて適切にツールを使い分けていくことが大切だと思います。
ありがとうございました。