* この記事の内容は以前の製品を基に書かれています。新しい製品(Oracle Database 23c および Graph Server 23.2)や新しい SQL 仕様を用いる場合にはこちらの記事を参照してください。

パート1とパート2では、Oracle Database がそれ単体でグラフ・データベースとして PGQL クエリを実行できること、また、CREATE PROPERTY GRAPH 文を用いることで表からグラフへの宣言的なマッピングが可能であること、などを解説しました。
このパートでは、Oracle Database に加えて Graph Server を導入することによって、パート2で定義したグラフをさらに広く活用する方法を紹介します。Graph Server とは、インメモリの高速グラフ分析フレームワークである Oracle Labs PGX にデータベースとの連携のためのコンポーネントを加えたもので、Oracle Database の全てのエディションで追加のライセンスなしに利用可能です。この Graph Server を Oracle Database と組み合わせたアーキテクチャを Oracle Graph の 3-tier 構成と呼んでいます。
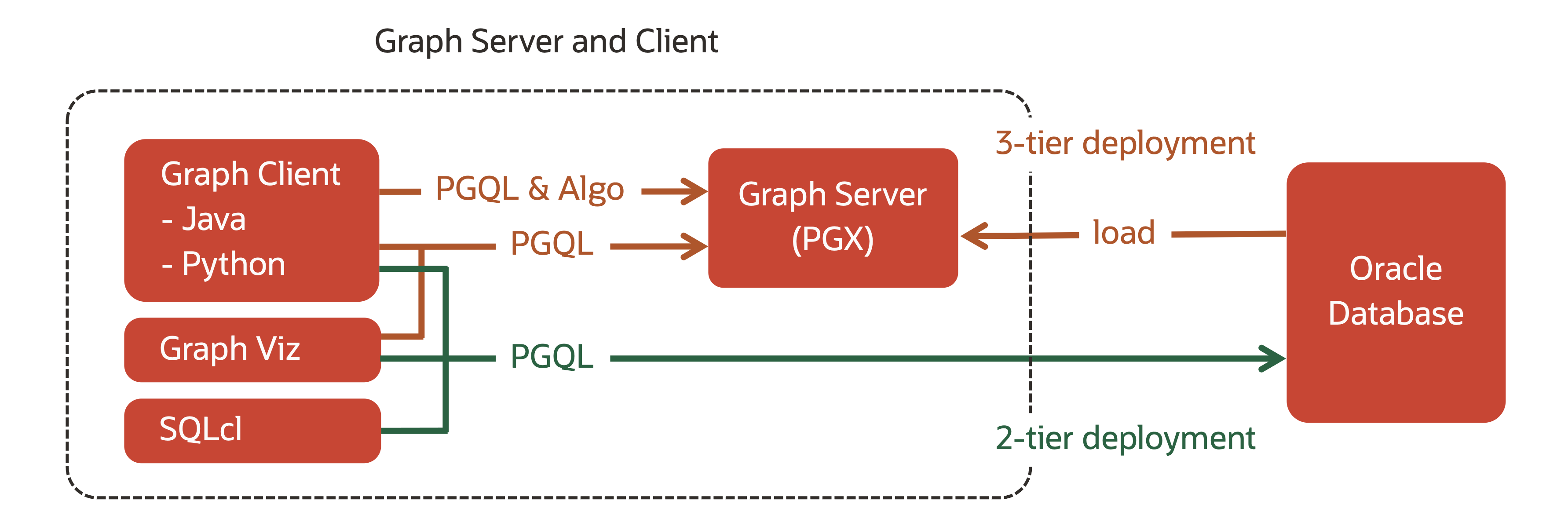
Graph Server へのグラフの読み込み
まずは Graph Server and Client のインストールされている OS 環境にログインします。例えば、こちらの記事で紹介している Docker コンテナを使う場合には以下のように Graph Server のコンテナにログインします。クラウド環境であれば SSH などを用いて接続してください。
$ docker exec -it graph-server /bin/bash
次に、既にインストールされている Python クライアント opg4py を使って同じホスト上で起動している Graph Server に接続します。
$ opg4py -b https://localhost:7007 -u graphuser
password: (Welcome1)
現在、データベースにはパート2で作成した GRAPH2 というグラフ(表データ上に PG ビューとして作成されている)がありますので、これを指定して読み込みます。変数名は同じにする必要はありませんが、わかりやすいので graph2 としておきます。
>>> graph2 = session.read_graph_by_name("GRAPH2", "pg_view")
この操作によって、データベース上の表データが読み込まれ、既に定義されているマッピングに従ってグラフに変換され、これが Graph Server のメモリ上に展開されます。
>>> graph2
PgxGraph(name: GRAPH2, v: 180, e: 3100, directed: True, memory(Mb): 0)
このグラフに対して PGQL クエリを実行してみます。
graph2.query_pgql("""
SELECT c.first_name, LABEL(e), a.acc_id
FROM MATCH (c:customer)-[e:owns]->(a:account)
WHERE c.cst_id = 10
""").print()
+--------------------------------+
| first_name | LABEL(e) | acc_id |
+--------------------------------+
| Laura | OWNS | 10 |
| Laura | OWNS | 90 |
+--------------------------------+
データベースと同様に PGQL クエリを実行できることがわかります。
経路探索クエリの実行
データベースでも PGQL クエリは(SQL クエリにリライトされることで)実行できますが、グラフが Graph Server のメモリに展開されていることにより、一部のクエリが高速化することを期待できます。経路探索はその一例です。
次のクエリは TOP K SHORTEST 句を使うことでふたつの口座間(acc_id が 10 のものと 50 のもの)のパスを短い方から K 個(ここでは 5 個)だけ取得します。COUNT(a) = COUNT(DISTINCT a) という条件を入れることで、同じ口座を二回以上経由するパスを省いています。
graph2.query_pgql("""
SELECT ARRAY_AGG(a.acc_id) AS acc_ids
, ARRAY_AGG(t.txn_id) AS txn_ids
, ARRAY_AGG(t.amount) AS amounts
FROM MATCH TOP 5 SHORTEST ((a1) (-[t:transferred_to]->(a))* (a2))
WHERE a1.acc_id = 10 AND a2.acc_id = 50
AND COUNT(a) = COUNT(DISTINCT a)
""").print()
+------------------------------------------+
| acc_ids | txn_ids | amounts |
+------------------------------------------+
| [62, 50] | [1025, 6212] | [100.0, 900.0] |
| [62, 50] | [1025, 6227] | [100.0, 500.0] |
| [62, 50] | [1044, 6212] | [200.0, 900.0] |
| [62, 50] | [1044, 6227] | [200.0, 500.0] |
| [62, 50] | [1041, 6212] | [300.0, 900.0] |
+------------------------------------------+
全ての送金の金額が 500 よりも上という条件を入れることもできます。
graph2.query_pgql("""
SELECT ARRAY_AGG(a.acc_id) AS acc_ids
, ARRAY_AGG(t.txn_id) AS txn_ids
, ARRAY_AGG(t.amount) AS amounts
FROM MATCH TOP 5 SHORTEST
((a1) (-[t:transferred_to]->(a) WHERE t.amount > 500)* (a2))
WHERE a1.acc_id = 10 AND a2.acc_id = 50
AND COUNT(a) = COUNT(DISTINCT a)
""").print()
+-----------------------------------------------------------+
| acc_ids | txn_ids | amounts |
+-----------------------------------------------------------+
| [49, 58, 50] | [1022, 4900, 5805] | [800.0, 700.0, 900.0] |
| [49, 58, 50] | [1018, 4900, 5805] | [800.0, 700.0, 900.0] |
| [49, 58, 50] | [1021, 4900, 5805] | [700.0, 700.0, 900.0] |
| [61, 62, 50] | [1007, 6111, 6212] | [700.0, 800.0, 900.0] |
| [61, 62, 50] | [1047, 6111, 6212] | [900.0, 800.0, 900.0] |
+-----------------------------------------------------------+
経路の始点と終点を同じノード(a1)とすれば、循環している経路を探し出すことができます。
graph2.query_pgql("""
SELECT ARRAY_AGG(a.acc_id) AS acc_ids
, ARRAY_AGG(t.txn_id) AS txn_ids
, ARRAY_AGG(t.amount) AS amounts
FROM MATCH TOP 5 SHORTEST
((a1) (-[t:transferred_to]->(a) WHERE t.amount > 500)* (a1))
WHERE a1.acc_id = 10
AND COUNT(a) = COUNT(DISTINCT a)
""").print()
+------------------------------------------+
| acc_ids | txn_ids | amounts |
+------------------------------------------+
| <null> | <null> | <null> |
| [25, 10] | [1014, 2531] | [900.0, 700.0] |
| [25, 10] | [1028, 2531] | [900.0, 700.0] |
| [49, 10] | [1022, 4902] | [800.0, 600.0] |
| [49, 10] | [1018, 4902] | [800.0, 600.0] |
+------------------------------------------+
経路の可視化
Graph Visualization ツールは Graph Server 上のグラフも可視化することができるので、求められたパスを可視化してみます。Graph Server のメモリ上のグラフはセッションごとに管理されているため、まず、Python クライアントのセッション ID を確認しておきます。
メモリ上のグラフはセッションごとに管理されているため、まず、Python クライアントのセッション ID を確認しておきます。
>>> session
PgxSession(id: bee563a9-7378-4ec2-a8a0-00dcdd69672e, name: OPGShell)
このセッション ID を使って Graph Visualization にログインします。

GRAPH2 を選択して先の経路探索クエリを実行します。返される結果はグラフで表示できないため表で表示されます。
SELECT ARRAY_AGG(a.acc_id) AS list_of_accounts
, ARRAY_AGG(ID(t)) AS list_of_transactions
, ARRAY_AGG(t.amount) AS list_of_amounts
FROM MATCH TOP 5 SHORTEST ((a1) (-[t:transferred_to]->(a) WHERE t.amount > 500)* (a2))
WHERE a1.acc_id = 10 AND a2.acc_id = 50
AND COUNT(a) = COUNT(DISTINCT a)
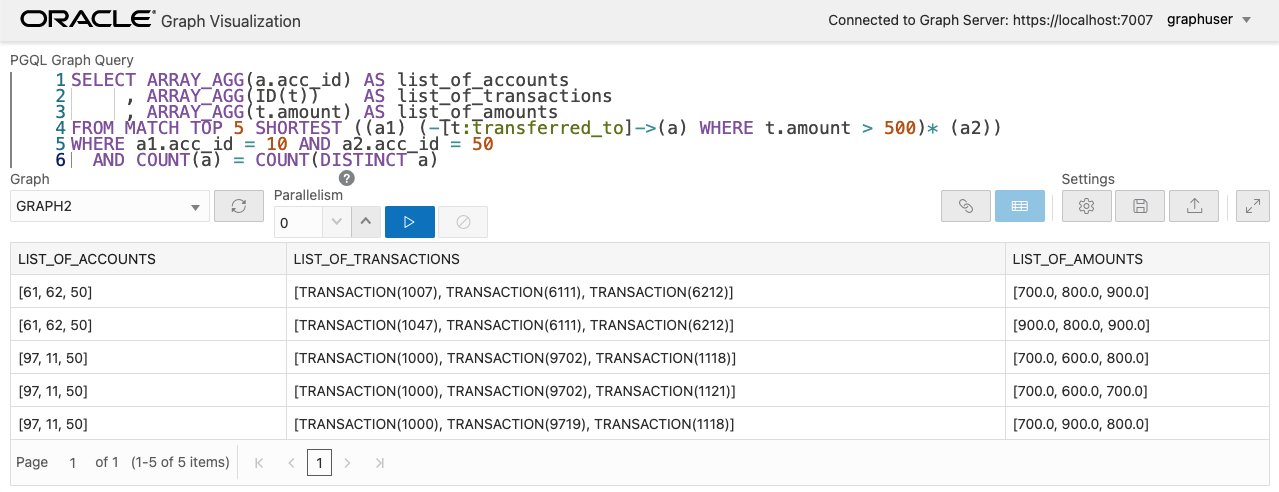
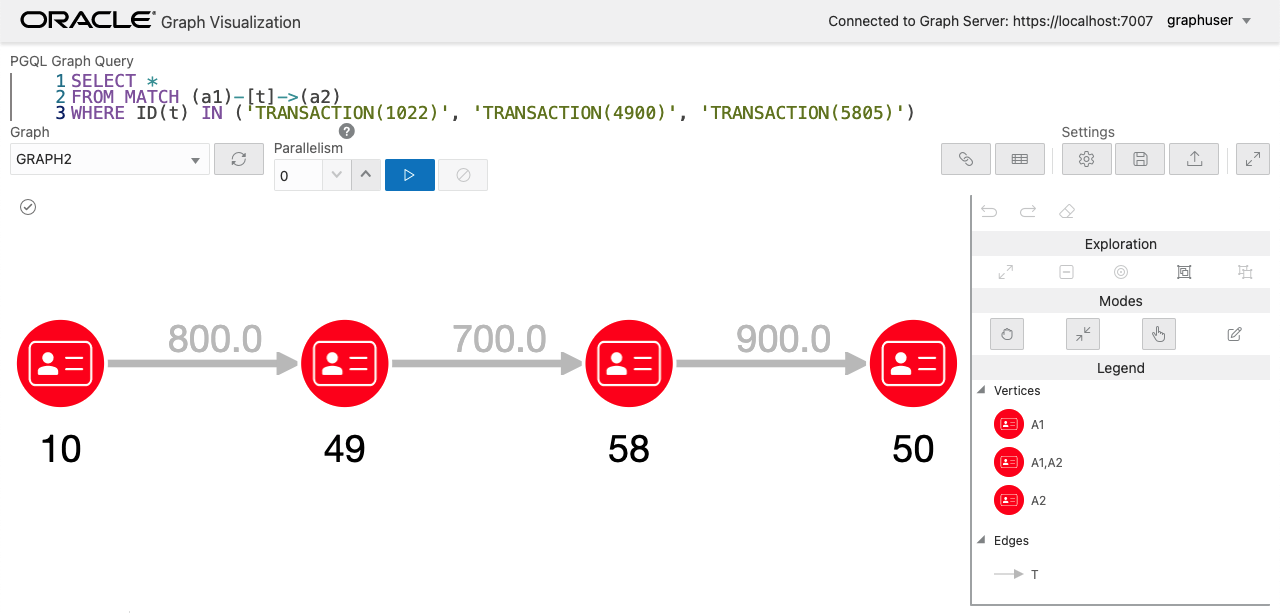
結果として取得されたパスのひとつに着目して、これに含まれるエッジの ID を用いることでこのパスを可視化することができます。実際のシステムではこれらのクエリとその間のロジックはアプリケーション層で実装されることになるかと思います。
SELECT *
FROM MATCH (a1)-[t]->(a2)
WHERE ID(t) IN ('TRANSACTION(1022)', 'TRANSACTION(4900)', 'TRANSACTION(5805)')
グラフ・アルゴリズムの実行
Graph Server には多くのグラフ・アルゴリズムが含まれていますが、ここではまず有名なページランク・アルゴリズムを実行してみましょう。
>>> analyst.pagerank(graph2)
VertexProperty(name: pagerank, type: double, graph: GRAPH2)
このアルゴリズムでは、計算結果はノードのプロパティ pagerank の値として double 型で格納されます。
さらに次数中心性も見てみましょう。これは単純に接続されているエッジの総数です。入ってくるエッジと出ていくエッジそれぞれの総数も計算しておきます。
analyst.degree_centrality(graph2)
analyst.in_degree_centrality(graph2)
analyst.out_degree_centrality(graph2)
結果は PGQL クエリで取得できるので便利です。クエリとアルゴリズムを同じインターフェイスから使えるのは Graph Server の特長です。
graph2.query_pgql("""
SELECT
a.acc_id
, a.pagerank
, a.degree
, a.in_degree
, a.out_degree
FROM MATCH (a)
ORDER BY a.pagerank DESC
LIMIT 10
""").print()
+-----------------------------------------------------------------+
| acc_id | pagerank | degree | in_degree | out_degree |
+-----------------------------------------------------------------+
| 41 | 0.019603664018674367 | 102 | 62 | 40 |
| 33 | 0.015104950170843338 | 108 | 58 | 50 |
| 5 | 0.014983680499273774 | 92 | 42 | 50 |
| 24 | 0.014966074159304933 | 89 | 49 | 40 |
| 36 | 0.014897989873184218 | 71 | 41 | 30 |
| 40 | 0.014860174576443065 | 72 | 32 | 40 |
| 23 | 0.014700205912993914 | 84 | 54 | 30 |
| 73 | 0.0141410094293568 | 77 | 47 | 30 |
| 30 | 0.013816617289907915 | 102 | 52 | 50 |
| 32 | 0.013339752300665857 | 42 | 32 | 10 |
+-----------------------------------------------------------------+
アルゴリズムで追加された新しいプロパティは Graph Visualization からも確認することができます。例えば、pagerank の値に応じてノードのサイズを変更するように設定することもできます。
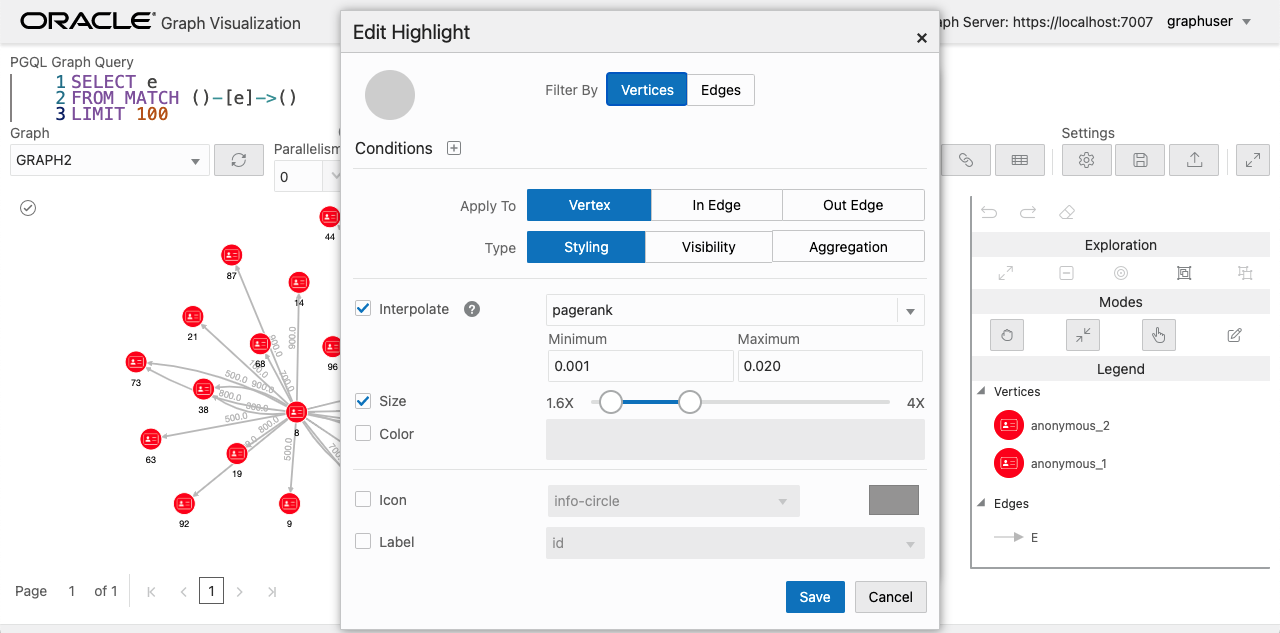
よく見るとノードによってサイズが異なっています。
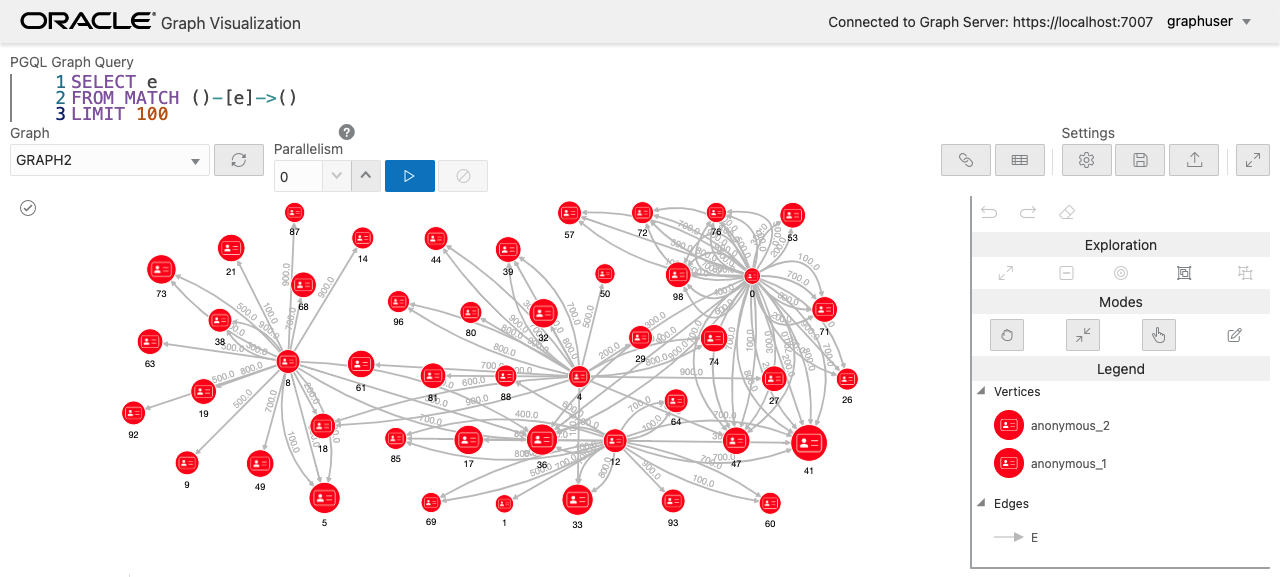
グラフからグラフへの変換
前項ではアルゴリズムを用いてノードの重要度を求めましたが、よくよく考えるともう少し検討しておかなければいけないことがあります。このグラフでは、顧客ノードと口座ノード、所有エッジと送金エッジがあるわけですが、もしも「送金という関係性に着目した口座の重要度」を求めたいのであれば、顧客ノードや所有エッジは計算に含むべきではありません。また、ふたつの口座間には複数の送金エッジが張られていることが多々ありますが、アルゴリズムによってはこのような重複エッジがないほうが計算が効率的であったり妥当な結果を得られたりします。そこで、ここでは PGQL クエリを使ってグラフを変換する方法を紹介します。
まず、現在メモリ上にあるグラフ(graph2)はアルゴリズム実行によって新しいプロパティが追加されているので、初期状態に戻すために再度データベースからグラフを読み込みます。
graph2 = session.read_graph_by_name("GRAPH2", "pg_view")
次のクエリは顧客ノードを削除するものです。このとき、端点の片方または両方のノードが削除されて「宙ぶらりんになった」エッジも同時に削除されます。
graph3 = graph2.clone_and_execute_pgql("""
DELETE c FROM MATCH (c:customer)
""")
80 個のノードと 100 個のエッジが削除されたことがわかります。
>>> graph3
PgxGraph(name: sub-graph_xx, v: 100, e: 3000, directed: True, memory(Mb): 0)
複数の送金エッジがある場合、これらをひとつにまとめます。その際、いくつの送金があったかという情報は残しておきたいので cnt という新しいプロパティを追加しておきます。格納される値は整数(integer)なのですが、後に実行するアルゴリズムが double に対応したものなので、このプロパティの型は double としておきます。
>>> graph3.create_edge_property("double", "cnt")
EdgeProperty(name: cnt, type: double, graph: sub-graph_xx)
この時点では新しいプロパティ cnt の値は全て 0 になっています。
graph3.query_pgql("""
SELECT t.cnt, COUNT(t)
FROM MATCH ()-[t:transferred_to]->()
GROUP BY t.cnt
ORDER BY t.cnt ASC
""").print()
+----------------+
| cnt | COUNT(t) |
+----------------+
| 0.0 | 3000 |
+----------------+
次のクエリは、口座のペアごとに(方向も考慮して)送金エッジがひとつ以上あれば、新しいエッジを作成します。このとき、新しいエッジの cnt プロパティに送金エッジの数を格納しておきます。
graph4 = graph3.clone_and_execute_pgql("""
INSERT EDGE e BETWEEN a1 AND a2 LABELS ( transferred_to ) PROPERTIES ( e.cnt = COUNT(t) )
FROM MATCH (a1)-[t:transferred_to]->(a2)
GROUP BY a1, a2
""")
この時点で、cnt が 0 のエッジはもとの送金エッジ、それ以外が新しく追加したエッジです。
graph4.query_pgql("""
SELECT t.cnt, COUNT(t)
FROM MATCH ()-[t:transferred_to]->()
GROUP BY t.cnt
ORDER BY t.cnt ASC
""").print()
+----------------+
| cnt | COUNT(t) |
+----------------+
| 0.0 | 3000 |
| 1.0 | 682 |
| 2.0 | 485 |
| 3.0 | 328 |
| 4.0 | 55 |
| 5.0 | 17 |
| 6.0 | 6 |
| 7.0 | 2 |
| 9.0 | 1 |
+----------------+
cnt が 0 のエッジは集計前の送金エッジなので削除してしまいます。
graph5 = graph4.clone_and_execute_pgql("""
DELETE t
FROM MATCH ()-[t:transferred_to]->()
WHERE t.cnt = 0
""")
新しく追加された送金エッジのみが残りました。
graph5.query_pgql("""
SELECT t.cnt, COUNT(t)
FROM MATCH ()-[t:transferred_to]->()
GROUP BY t.cnt
ORDER BY t.cnt ASC
""").print()
+----------------+
| cnt | COUNT(t) |
+----------------+
| 1.0 | 682 |
| 2.0 | 485 |
| 3.0 | 328 |
| 4.0 | 55 |
| 5.0 | 17 |
| 6.0 | 6 |
| 7.0 | 2 |
| 9.0 | 1 |
+----------------+
それでは、変換されたグラフに対して、上と同様に中心性を計算します。
analyst.pagerank(graph5)
analyst.degree_centrality(graph5)
analyst.in_degree_centrality(graph5)
analyst.out_degree_centrality(graph5)
結果を PGQL で取得します。以前とは異なる計算結果が得られているはずです。
graph5.query_pgql("""
SELECT
a.acc_id
, a.pagerank
, a.degree
, a.in_degree
, a.out_degree
FROM MATCH (a)
ORDER BY a.pagerank DESC
LIMIT 10
""").print()
+-----------------------------------------------------------------+
| acc_id | pagerank | degree | in_degree | out_degree |
+-----------------------------------------------------------------+
| 41 | 0.015927856082418812 | 52 | 27 | 25 |
| 33 | 0.01572808354417436 | 55 | 28 | 27 |
| 73 | 0.01467580042697759 | 44 | 22 | 22 |
| 53 | 0.014544138405858852 | 45 | 21 | 24 |
| 59 | 0.014241045755115847 | 41 | 24 | 17 |
| 49 | 0.014199578954729926 | 29 | 21 | 8 |
| 47 | 0.014141568475804285 | 43 | 22 | 21 |
| 5 | 0.013433911533465633 | 46 | 21 | 25 |
| 68 | 0.012841252743896187 | 43 | 20 | 23 |
| 90 | 0.01278925469055179 | 38 | 22 | 16 |
+-----------------------------------------------------------------+
最後に重み付きのページランクも試してみます。エッジのプロパティ cnt に送金の回数という情報を持っているので、これを重みとして扱い、cnt が大きいほどより強くページランクが伝播するようにします。次のようにして、エッジ・プロパティを第2引数に指定してアルゴリズムを実行します。
cnt = graph5.get_edge_property("cnt")
analyst.weighted_pagerank(graph5, cnt)
結果を先のページランクのものと比較すると順位に違いが見られることがわかります。
graph5.query_pgql("""
SELECT
a.acc_id
, a.pagerank
, a.weighted_pagerank
FROM MATCH (a)
ORDER BY a.pagerank DESC
LIMIT 10
""").print()
+------------------------------------------------------+
| acc_id | pagerank | weighted_pagerank |
+------------------------------------------------------+
| 41 | 0.015927856082418812 | 0.02090853868414549 |
| 33 | 0.01572808354417436 | 0.016067973689548414 |
| 73 | 0.01467580042697759 | 0.015001994965949424 |
| 53 | 0.014544138405858852 | 0.011917160588132424 |
| 59 | 0.014241045755115847 | 0.01275290770633708 |
| 49 | 0.014199578954729926 | 0.013315017840049879 |
| 47 | 0.014141568475804285 | 0.01222283230220626 |
| 5 | 0.013433911533465633 | 0.016221144544670288 |
| 68 | 0.012841252743896187 | 0.011829108962126801 |
| 90 | 0.01278925469055179 | 0.011897751825643397 |
+------------------------------------------------------+
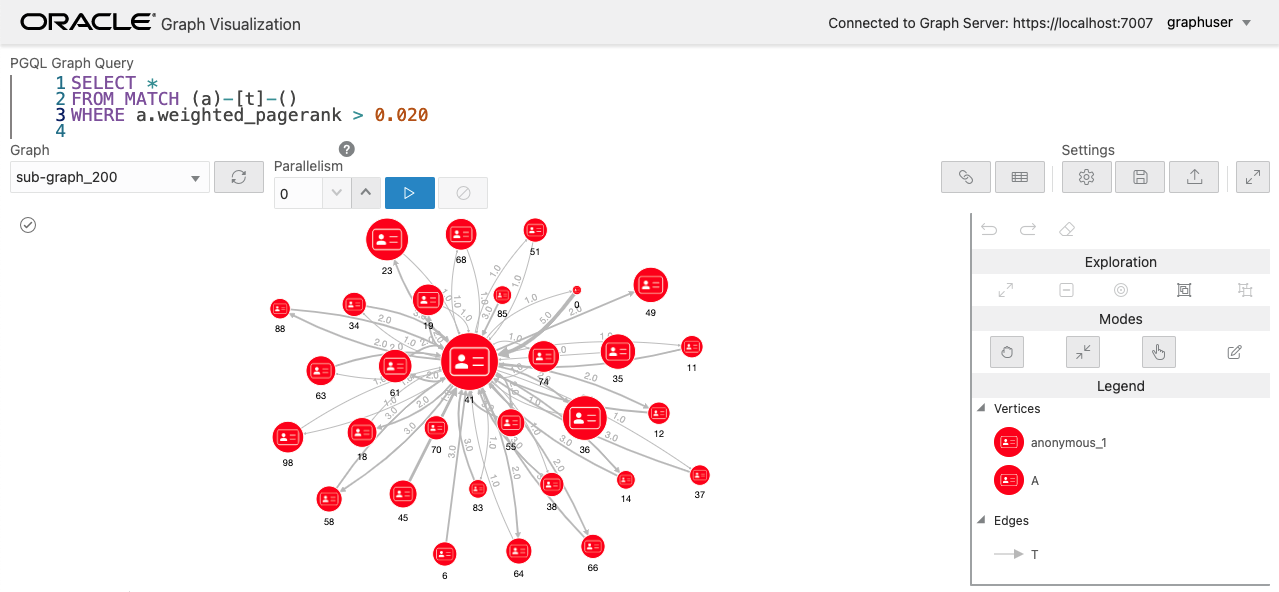
Graph Visualization ツールから新しく作成された変換後のグラフにもアクセスできるので、重み付きページランクが最も高いノードとそれに接続されたノードを可視化してみましょう。ここでエッジの太さは重みを表しています。
SELECT *
FROM MATCH (a)-[t]-()
WHERE a.weighted_pagerank > 0.020
今回は、データベース上で定義したグラフを Graph Server に読み込み、Graph Server 上のメモリに展開されたグラフに対して、経路探索クエリやグラフ・アルゴリズムが実行できることを確認しました。表データをベースにグラフを宣言的に定義できるようにしておき、それをインメモリのグラフ分析フレームワークとシームレスに連携させる、という 3-tier 構成の目指すところもお伝えできたかと思います。
また最後には、PGQL の更新クエリを使うことで分析に合わせてグラフを変換する方法を紹介しました。実のところ、今回のグラフの変換は、データベース上で SQL を使って集計しておくことでも簡単に実現できるのですが、一方で、複数ホップのパスをエッジに変換する際などにはとても強力な方法です。こういったケースもおいおい紹介させて頂きます。
※ 冒頭画像 Photo by Eduardo Soares on Unsplash(編集済み)