
前編では、Oracle Database 23c がサポートする最新の SQL を用いて、表データからグラフを作成できること、グラフパターンを用いたクエリを実行できることなどを解説しました。
後編では、Oracle Database に加えて Graph Server を導入することによって、前編で作成したグラフをさらに広く活用する方法を紹介します。Graph Server とは、インメモリの高速グラフ分析フレームワークである Oracle Labs PGX にデータベースとの連携のためのコンポーネントを加えたもので、Oracle Database の全てのエディションで追加のライセンスなしに利用可能です。

Graph Server へのグラフの読み込み
まずは Python で Graph Server に接続します。
from opg4py import graph_server
from pypgx import setloglevel
from getpass import getpass
setloglevel("ROOT", "WARN")
base_url = "http://localhost:7007"
username = "graphuser"
password = getpass("Password: ")
instance = graph_server.get_instance(base_url, username, password)
session = instance.create_session("test")
analyst = session.create_analyst()
print(session)
PgxSession(id: 5eb2cb7d-f00c-40fe-ac1f-97c353492ec7, name: jupyter)
現在、データベースには前編で作成した BANK_GRAPH というグラフがあるので、これを指定して読み込みます。この操作によって、グラフが Graph Server のメモリ上に展開されます。
graph = session.read_graph_by_name("BANK_GRAPH", "pg_sql")
print(graph)
PgxGraph(name: BANK_GRAPH, v: 360, e: 6230, directed: True, memory(Mb): 0)
このグラフに対してクエリを実行してみます。現在、Graph Server がサポートしているのは PGQL(https://pgql-lang.org/)という SQL と似ていて異なる言語です。SQL にグラフ構文が導入される前には、Oracle Database と Graph Server は PGQL のみに対応していましたが、今後は SQL の標準に対応していく予定です。
graph.query_pgql("""
SELECT c.first_name, LABEL(e), a.acc_id
FROM MATCH (c:customer)-[e:owns]->(a:account)
WHERE c.cst_id = 10
""").print()
+--------------------------------+
| first_name | LABEL(e) | acc_id |
+--------------------------------+
| Laura | OWNS | 10 |
| Laura | OWNS | 90 |
+--------------------------------+
SQL と PGQL との構文の違いはありますが、データベースと同様にグラフを用いたパターンマッチングを実行できることがわかります。
経路探索クエリの実行
Graph Server を使うと、グラフがメモリ上に効率的な形式で展開されていることにより、一部のクエリが高速化することを期待できます。経路探索はその一例です。
次のクエリは TOP K SHORTEST 句を使うことでふたつの口座間(acc_id が 10 のものと 50 のもの)のパスを短い方から K 個(ここでは 1 個)だけ取得します。COUNT(a) = COUNT(DISTINCT a) という条件を入れることで、同じ口座を二回以上経由するパスを省いています。
graph.query_pgql("""
SELECT ARRAY_AGG(a.acc_id) AS acc_ids
, ARRAY_AGG(t.txn_id) AS txn_ids
, ARRAY_AGG(t.amount) AS amounts
FROM MATCH TOP 1 SHORTEST (a1) (-[t:transferred_to]->(a))+ (a2)
WHERE a1.acc_id = 10 AND a2.acc_id = 50
AND COUNT(a) = COUNT(DISTINCT a)
""").print()
+--------------------------------------+
| acc_ids | txn_ids | amounts |
+--------------------------------------+
| [59, 50] | [1015, 5916] | [100, 500] |
+--------------------------------------+
全ての送金の金額が 800 よりも上で、5 ホップ以上といった条件を加えることもできます。
graph.query_pgql("""
SELECT ARRAY_AGG(a.acc_id) AS acc_ids
, ARRAY_AGG(t.txn_id) AS txn_ids
, ARRAY_AGG(t.amount) AS amounts
FROM MATCH TOP 1 SHORTEST (a1) (-[t:transferred_to]->(a) WHERE t.amount > 800){5,} (a2)
WHERE a1.acc_id = 10 AND a2.acc_id = 50
AND COUNT(a) = COUNT(DISTINCT a)
""").print()
+---------------------------------------------------------------------------------+
| acc_ids | txn_ids | amounts |
+---------------------------------------------------------------------------------+
| [23, 5, 33, 11, 50] | [1031, 2302, 507, 3314, 1121] | [700, 600, 700, 900, 700] |
+---------------------------------------------------------------------------------+
さらに、経路の始点と終点を同じノード(a1)とすれば、循環している経路を探し出すことができます。
graph.query_pgql("""
SELECT ARRAY_AGG(a.acc_id) AS acc_ids
, ARRAY_AGG(t.txn_id) AS txn_ids
, ARRAY_AGG(t.amount) AS amounts
FROM MATCH TOP 1 SHORTEST (a1) (-[t:transferred_to]->(a) WHERE t.amount > 800){5,} (a1)
WHERE a1.acc_id = 10
AND COUNT(a) = COUNT(DISTINCT a)
""").print()
+-----------------------------------------------------------------------------------+
| acc_ids | txn_ids | amounts |
+-----------------------------------------------------------------------------------+
| [25, 20, 37, 77, 10] | [1028, 2528, 2005, 3712, 7714] | [900, 900, 900, 900, 900] |
+-----------------------------------------------------------------------------------+
経路をホップごとに行として結果を得たい場合には、ONE ROW PER STEP というキーワードを使います。
graph.query_pgql("""
SELECT ELEMENT_NUMBER(e) AS element
, src.acc_id AS src_acc_id
, dst.acc_id AS dst_acc_id
, e.amount
FROM MATCH TOP 1 SHORTEST (a1) (-[t:transferred_to]->(a) WHERE t.amount > 800){5,} (a1)
ONE ROW PER STEP (src, e, dst)
WHERE a1.acc_id = 10
AND COUNT(a) = COUNT(DISTINCT a)
ORDER BY element ASC
""").print()
+--------------------------------------------+
| element | src_acc_id | dst_acc_id | amount |
+--------------------------------------------+
| 2 | 10 | 25 | 900 |
| 4 | 25 | 20 | 900 |
| 6 | 20 | 37 | 900 |
| 8 | 37 | 77 | 900 |
| 10 | 77 | 10 | 900 |
+--------------------------------------------+
経路の可視化
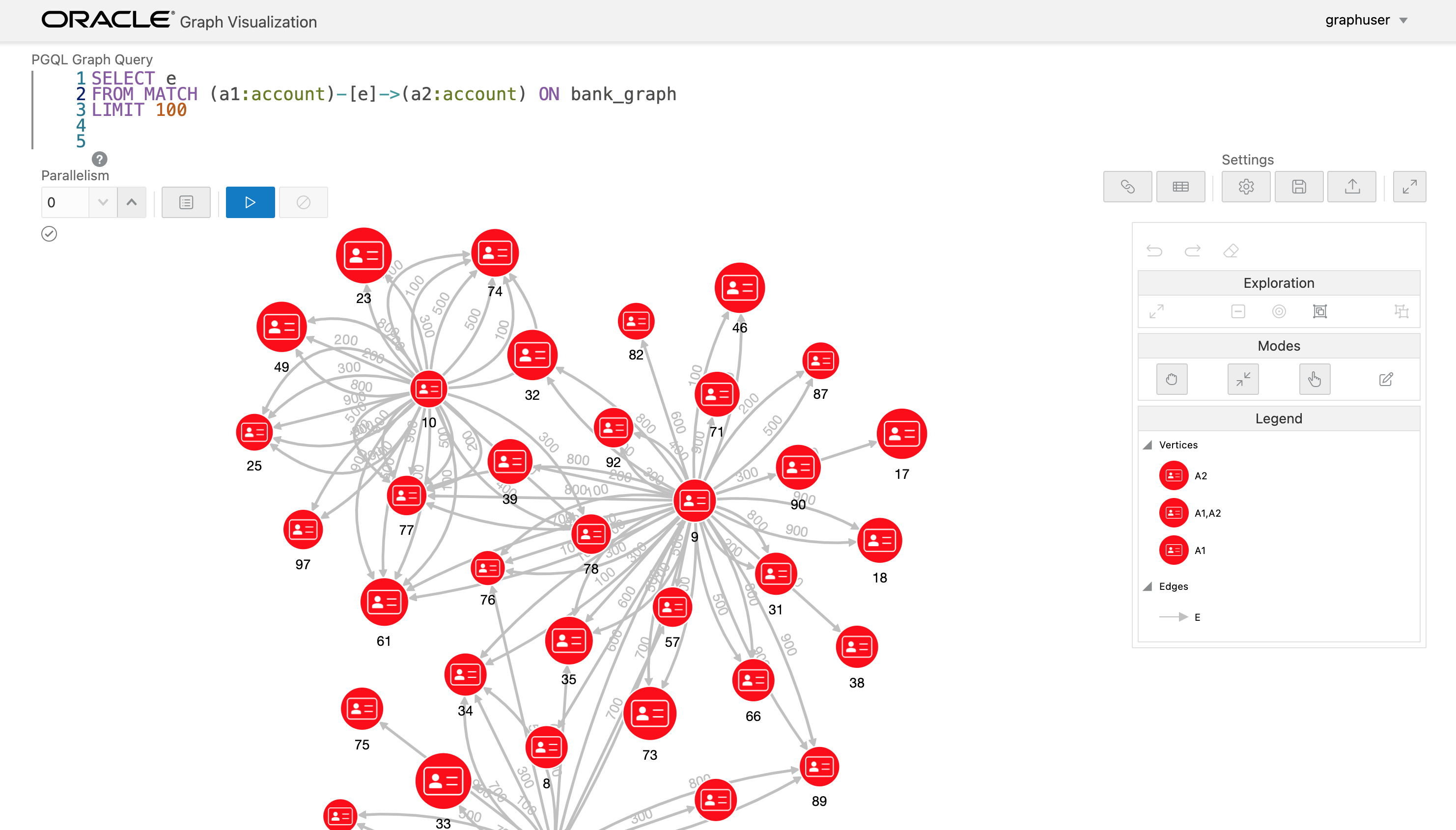
Graph Visualization ツールは Graph Server 上のグラフも可視化することができるので、求められたパスを可視化してみます。Graph Server のメモリ上のグラフはセッションごとに管理されているため、まず、Python クライアントのセッション ID を確認しておきます。
メモリ上のグラフはセッションごとに管理されているため、まず、Python クライアントのセッション ID を確認しておきます。
print(session)
PgxSession(id: bee563a9-7378-4ec2-a8a0-00dcdd69672e, name: test)
このセッション ID を使って Graph Visualization にログインします。

このクエリは上のセクションの最後のクエリを多少変更したものです。可視化のため、全てのエッジ e を返す(それによって接続されたノードも返される)ようにしておき、対象となるグラフを ON bank_graph のようにクエリ内で指定しています。
SELECT e
FROM MATCH TOP 1 SHORTEST (a1) (-[t:transferred_to]->(a) WHERE t.amount > 800){5,} (a1)
ONE ROW PER STEP (src, e, dst)
ON bank_graph
WHERE a1.acc_id = 10
AND COUNT(a) = COUNT(DISTINCT a)

グラフ・アルゴリズムの実行
Graph Server には多くのグラフ・アルゴリズムが含まれていますが、ここではまず有名なページランク・アルゴリズムを実行してみましょう。
>>> analyst.pagerank(graph)
VertexProperty(name: pagerank, type: double, graph: GRAPH)
このアルゴリズムでは、計算結果はノードのプロパティ pagerank の値として double 型で格納されます。
さらに次数中心性も見てみましょう。これは単純に接続されているエッジの総数です。入ってくるエッジと出ていくエッジそれぞれの総数も計算しておきます。
analyst.degree_centrality(graph)
analyst.in_degree_centrality(graph)
analyst.out_degree_centrality(graph)
結果は PGQL クエリで取得できるので便利です。クエリとアルゴリズムを同じインターフェイスから使えるのは Graph Server の特長です。
graph.query_pgql("""
SELECT
a.acc_id
, a.pagerank
, a.degree
, a.in_degree
, a.out_degree
FROM MATCH (a)
ORDER BY a.pagerank DESC
LIMIT 10
""").print()
+-----------------------------------------------------------------+
| acc_id | pagerank | degree | in_degree | out_degree |
+-----------------------------------------------------------------+
| 41 | 0.019603664018674367 | 102 | 62 | 40 |
| 33 | 0.015104950170843338 | 108 | 58 | 50 |
| 5 | 0.014983680499273774 | 92 | 42 | 50 |
| 24 | 0.014966074159304933 | 89 | 49 | 40 |
| 36 | 0.014897989873184218 | 71 | 41 | 30 |
| 40 | 0.014860174576443065 | 72 | 32 | 40 |
| 23 | 0.014700205912993914 | 84 | 54 | 30 |
| 73 | 0.0141410094293568 | 77 | 47 | 30 |
| 30 | 0.013816617289907915 | 102 | 52 | 50 |
| 32 | 0.013339752300665857 | 42 | 32 | 10 |
+-----------------------------------------------------------------+
アルゴリズムで追加された新しいプロパティは Graph Visualization からも確認することができます。例えば、pagerank の値に応じてノードのサイズを変更するように設定することもできます。
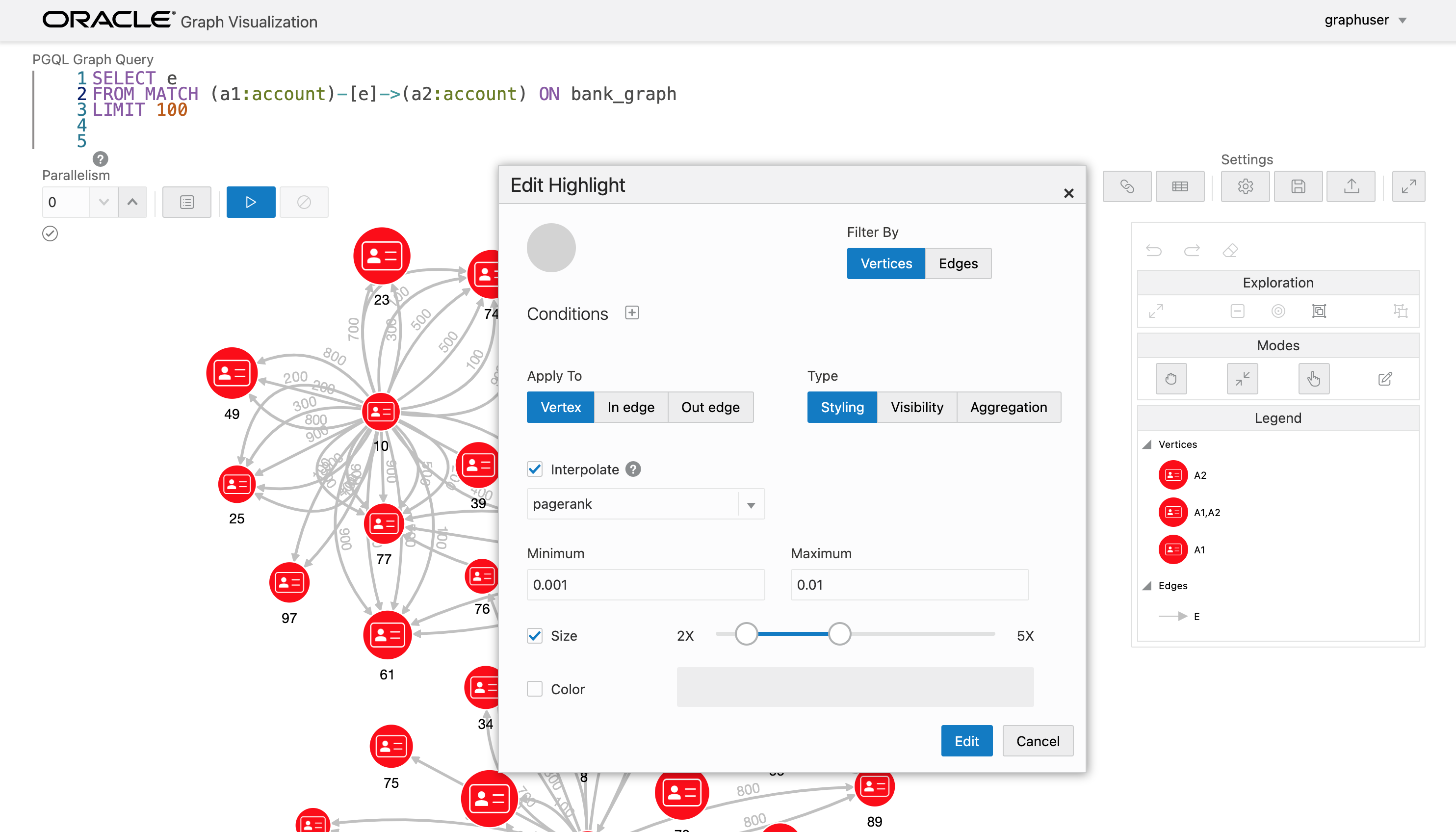
よく見るとノードによってサイズが異なっています。
今回は、データベース上で定義したグラフを Graph Server に読み込み、Graph Server 上のメモリに展開されたグラフに対して、経路探索クエリやグラフ・アルゴリズムが実行できることを確認しました。表データをベースにグラフを宣言的に定義できるようにしておき、それをインメモリのグラフ分析フレームワークとシームレスに連携させる、という構成の目指すところもお伝えできたかと思います。
以前のバージョンの場合
Oracle Database 23c より前のバージョンをお使いの場合でも、前編および上記と同様の分析が可能です。
- 前編で紹介した SQL 2023 のパターンマッチングは従来の Oracle Database ではサポートされていませんが、代わりに Graph Client ライブラリを使うことで、グラフを作成して PGQL クエリを実行することが可能です。
- 後編で紹介した Graph Server を用いた分析方法はバックエンドのデータベースによらず同様です。ただし、Graph Client ライブラリを使用して作成したグラフを読み込むときには
pg_sqlをpg_viewに置き換えます。graph = session.read_graph_by_name("BANK_GRAPH", "pg_view")
詳しくはドキュメントを参考にしてください。
※ 冒頭画像 Photo by Eduardo Soares on Unsplash(編集済み)