
この記事では銀行の送金データをグラフとして扱う方法と、それによってどのような分析ができるかを見ていきたいと思います。金融機関における不正検知は現在のグラフ・データベースの主要な活用ユースケースの一つであり、マネーロンダリング対策といった観点でも期待されているため、今後も活用範囲が拡がるだろうと推測しています。
* この記事は、以前の記事を現在の製品(Oracle Database 23c および Graph Server 23.2)に合わせて書き換えたものです。
なぜグラフ?
では、なぜ銀行送金のようなトランザクションをグラフとして扱うと便利になり得るのか、まずは机上で考えてみたいと思います。例えば、次のような、顧客表、口座表、取引表で構成された銀行取引のデータセットがあるとして(おそらくとても一般的な)次の 2 つの質問に答えたいとします。
- Bob と Charlie の間にはお金の流れがあるか。直接の取引がなくても、他の口座を介して間接的にお金の流れがあると言える場合もあります。
- 取引のクラスターがあるか。つまり、一部のアカウントの間で頻繁に取引が行われ、それらのアカウントと他のアカウントの間では取引が少ないというパターンがあるかどうかです。
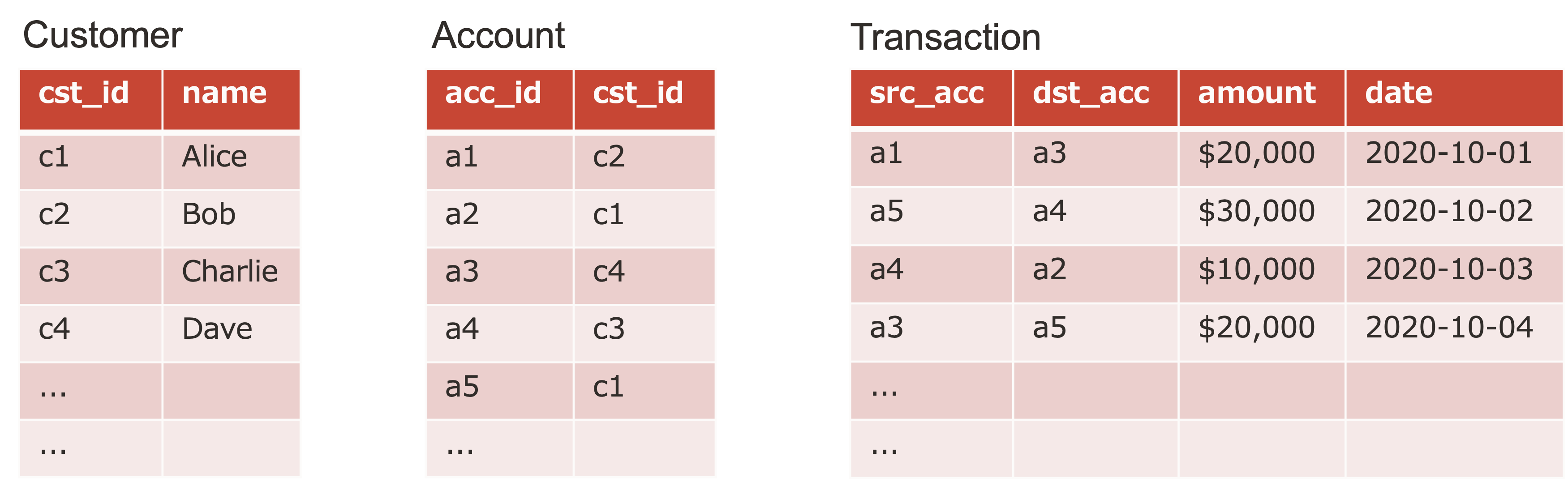
表構造を前提に考える場合、最初の質問に答えるには当然ながら表同士の結合が必要です。関連が見つかるまでのホップ数が多ければ、それだけ多くの結合が必要になります。2 番目の質問に答えるのは難しく、表データからグラフを構築してクラスターを決定するための手続き型のプログラムが必要になるはずです。
それでは、グラフとして扱う場合を考えてみます。
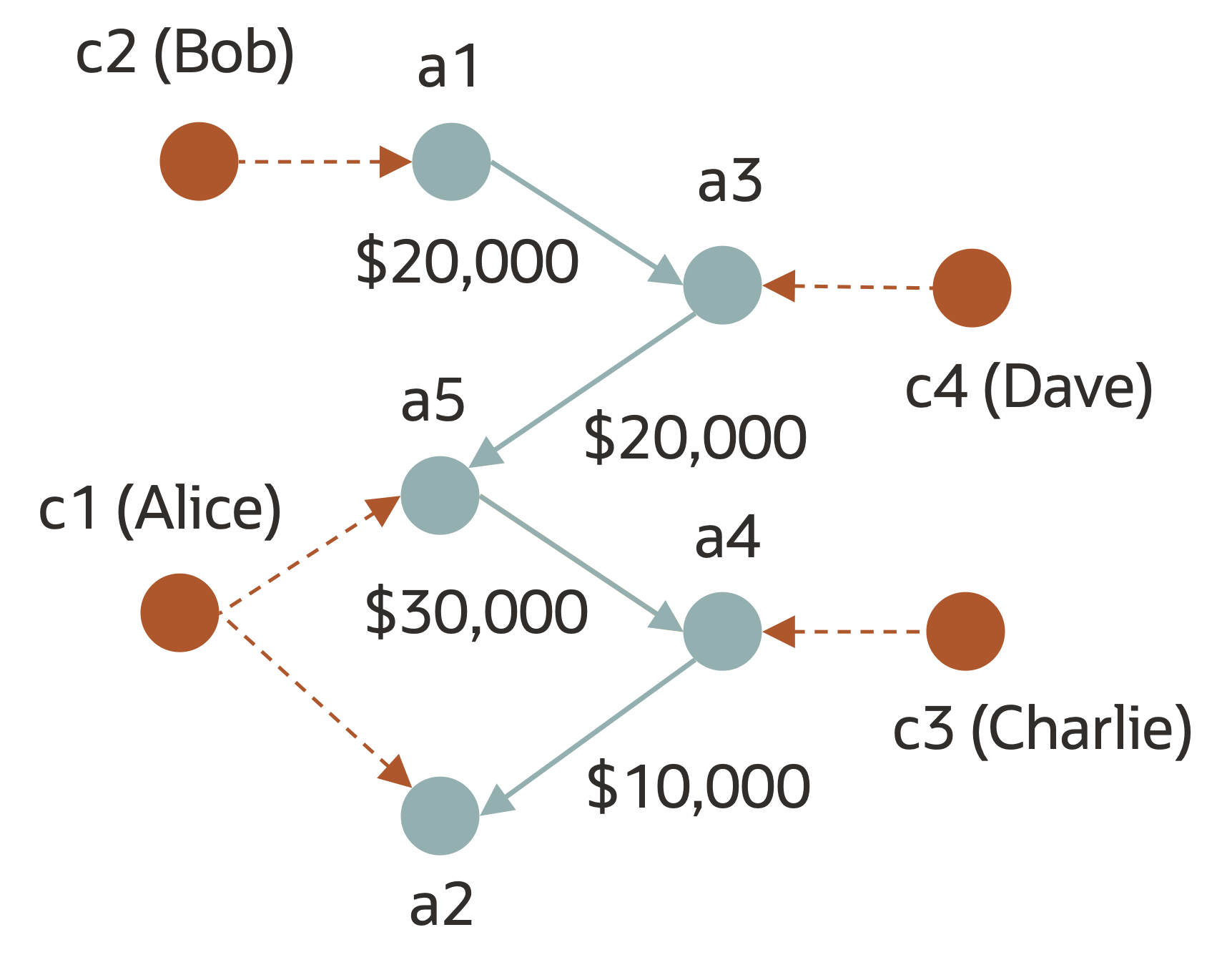
グラフにはノードとエッジという 2 つの構造があるので、先の 3 つの表の情報をグラフとして表現する場合には、取引を口座間のエッジとすることができます。その場合、次の図のように直感的な表現になるため、ひとつめ質問に答えるには、アカウント a1 から a3 、a5、そして a4 へとエッジを辿ればいいことがわかります。理想的には a1 と a4 の間のパスを検索するための効率的な手法が提供されていて欲しいです。
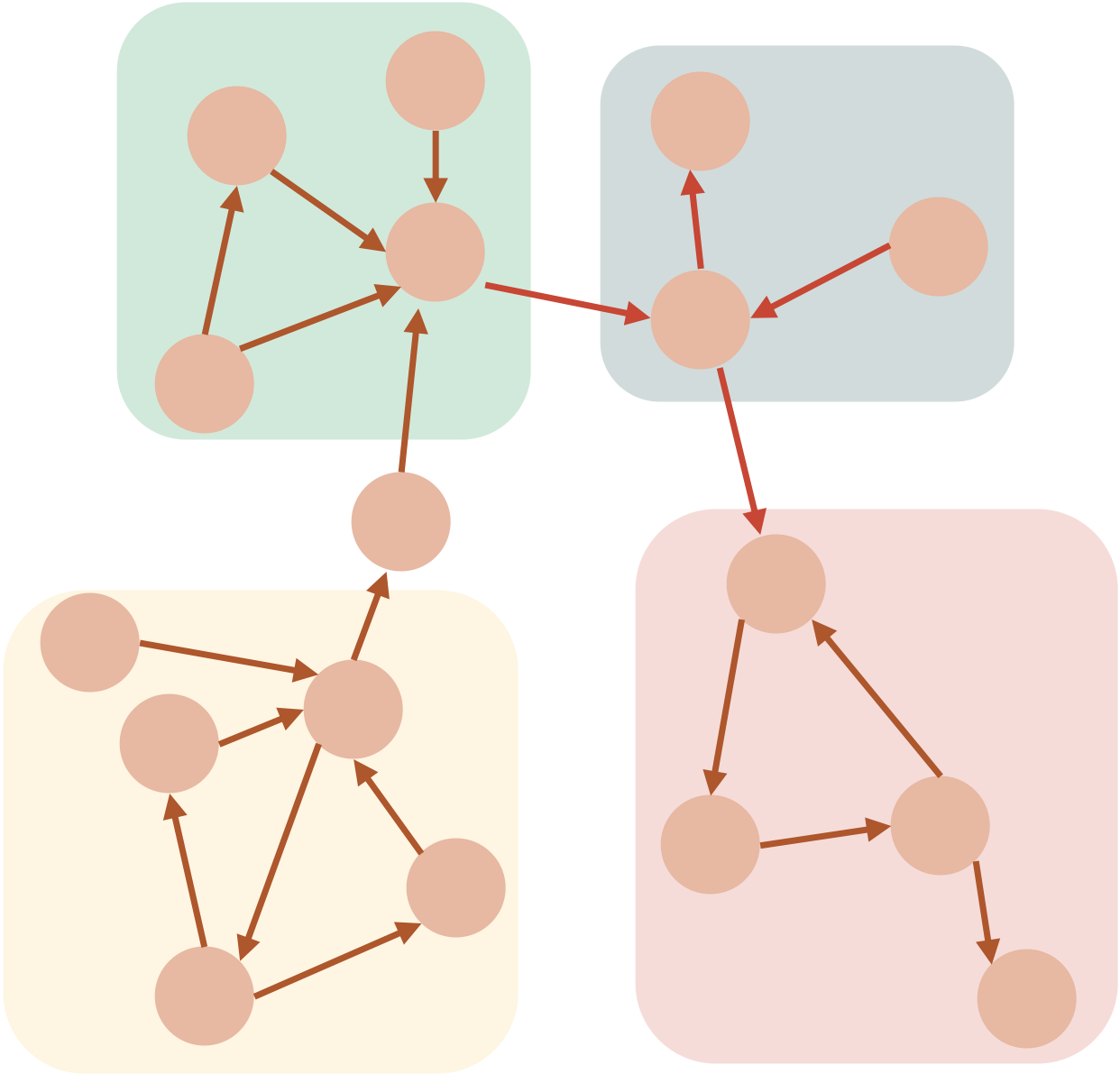
ふたつめの質問に答えるためには、グラフ・アルゴリズムを使って取引による繋がりをもとにクラスターを見つける必要があります。このようなクラスタリングのアルゴリズムは多く提案されており、コミュニティ検出とも呼ばれます。
グラフの作成
Oracle Database 23c では SQL にグラフを作成する構文(= CREATE PROPERTY GRAPH)が導入されたので、これを用いて表データからグラフを作成します。23c より前のバージョンでも PGQL という言語で同様のことができるので、それについては後半で補足する予定です。
CREATE PROPERTY GRAPH bank_graph
VERTEX TABLES (
bank_customer
KEY (cst_id)
LABEL customer
PROPERTIES (cst_id, first_name, last_name)
, bank_account
KEY (acc_id)
LABEL account
PROPERTIES (acc_id)
)
EDGE TABLES (
bank_transaction
KEY (txn_id)
SOURCE KEY (acc_id_src) REFERENCES bank_account (acc_id)
DESTINATION KEY (acc_id_dst) REFERENCES bank_account (acc_id)
LABEL transferred_to
PROPERTIES (txn_id, datetime, amount)
, bank_account AS bank_account_owns
KEY (acc_id)
SOURCE KEY (cst_id) REFERENCES bank_customer (cst_id)
DESTINATION KEY (acc_id) REFERENCES bank_account (acc_id)
LABEL owns
);
Property graph created.
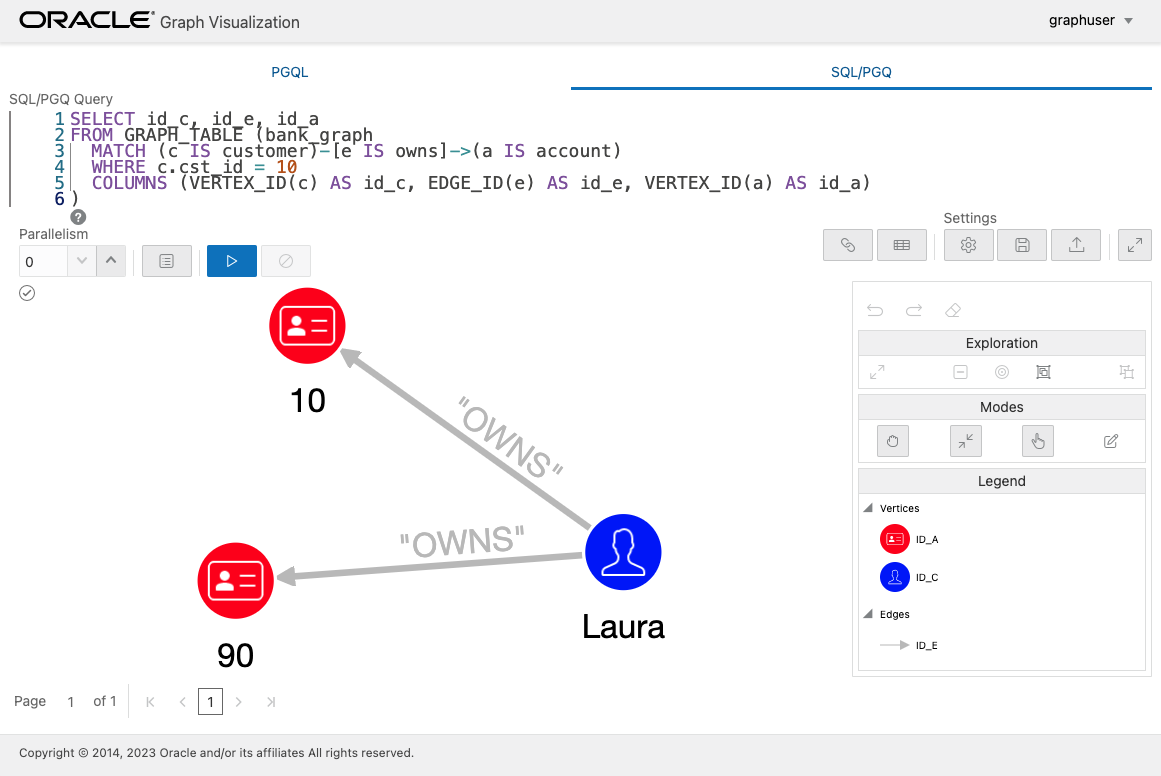
まずは、CST_ID = 10 の顧客が持っている口座を確認します。
SELECT * FROM GRAPH_TABLE (bank_graph
MATCH (c IS customer)-[e IS owns]->(a IS account)
WHERE c.cst_id = 10
COLUMNS (c.cst_id, c.first_name, a.acc_id)
);
CST_ID FIRST_NAME ACC_ID
---------- ---------- ----------
10 Laura 10
10 Laura 90
検索と可視化
それではいくつかのクエリとその可視化を試してみます。データベースに付属の可視化ツールを使う際には、上のクエリを少し変更して、ノードとエッジの ID を取得するようにします。
SELECT *
FROM GRAPH_TABLE (bank_graph
MATCH (c IS customer)-[e IS owns]->(a IS account)
WHERE c.cst_id = 10
COLUMNS (VERTEX_ID(c) AS id_c, EDGE_ID(e) AS id_e, VERTEX_ID(a) AS id_a)
)
この顧客の名前は Laura でふたつの口座を持っていることがわかります。
次に Laura の送金先を全て表示してみます。マッチングのパターンにもう 1 ホップぶんのエッジとノードを増やすことになります。パターンの中にアカウントが 2つ出てくるので a と a1 のように別の変数を使っています。
SELECT DISTINCT *
FROM GRAPH_TABLE (bank_graph
MATCH (c IS customer)-[e IS owns]->(a IS account)-[t IS transferred_to]->(a1 IS account)
WHERE c.cst_id = 10
COLUMNS (
VERTEX_ID(c) AS id_c,
EDGE_id(e) AS id_e,
VERTEX_ID(a) AS id_a,
EDGE_id(t) AS id_t,
VERTEX_ID(a1) AS id_a1
)
)
いくつかの口座に対しては、ふたつの口座の両方から送金をしていることがわかります。
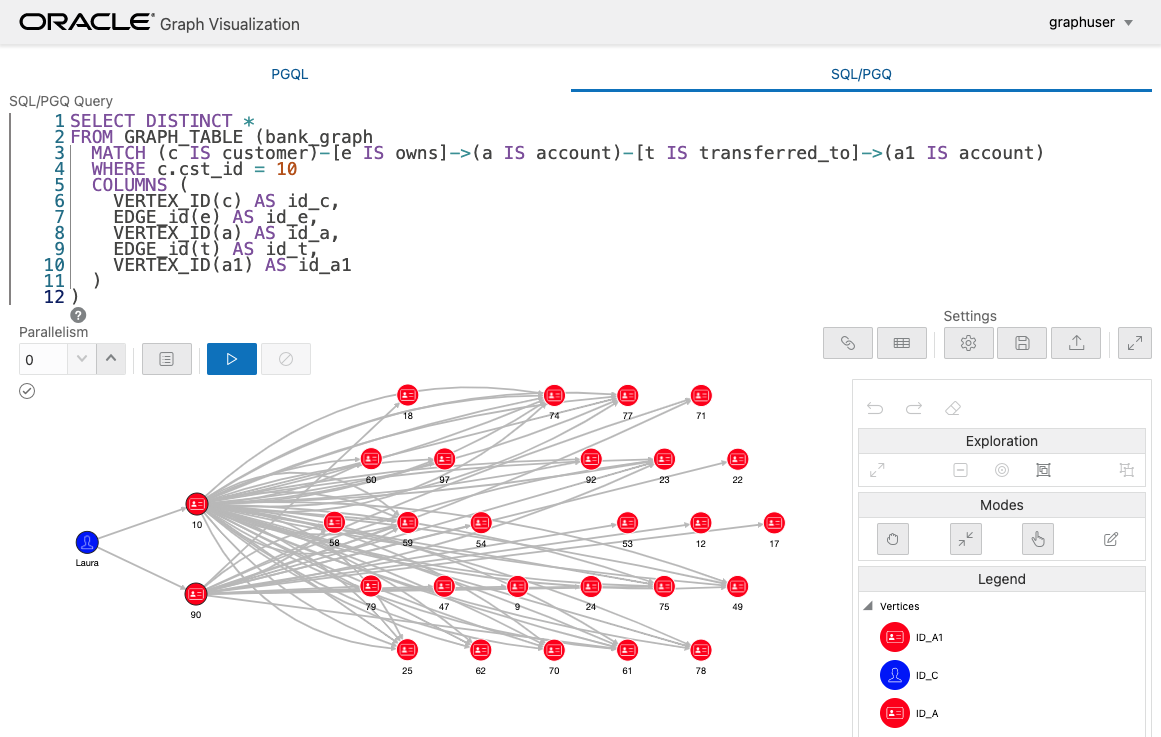
それでは、口座間の送金だけに着目して、acc_id = 10 のアカウントから 3 ホップで戻ってくるようなパターンを探してみます。さらに、これらの送金は時間的にもこの順序で、送金額は常に 500 以上という条件も付けてみます。
SELECT DISTINCT *
FROM GRAPH_TABLE (bank_graph
MATCH (a1)-[t1 IS transferred_to]->(a2)
, (a2)-[t2 IS transferred_to]->(a3)
, (a3)-[t3 IS transferred_to]->(a1)
WHERE a1.acc_id = 10
AND t1.amount > 500 AND t2.amount > 500 AND t3.amount > 500
AND t1.datetime < t2.datetime AND t2.datetime < t3.datetime
COLUMNS (
VERTEX_ID(a1) AS id_a1, EDGE_ID(t1) AS id_e1
, VERTEX_ID(a2) AS id_a2, EDGE_ID(t2) AS id_e2
, VERTEX_ID(a3) AS id_a3, EDGE_ID(t3) AS id_e3
)
)
acc_id が 10 > 75 > 77 というパスのみ、このようなパターンが存在することがわかりました。
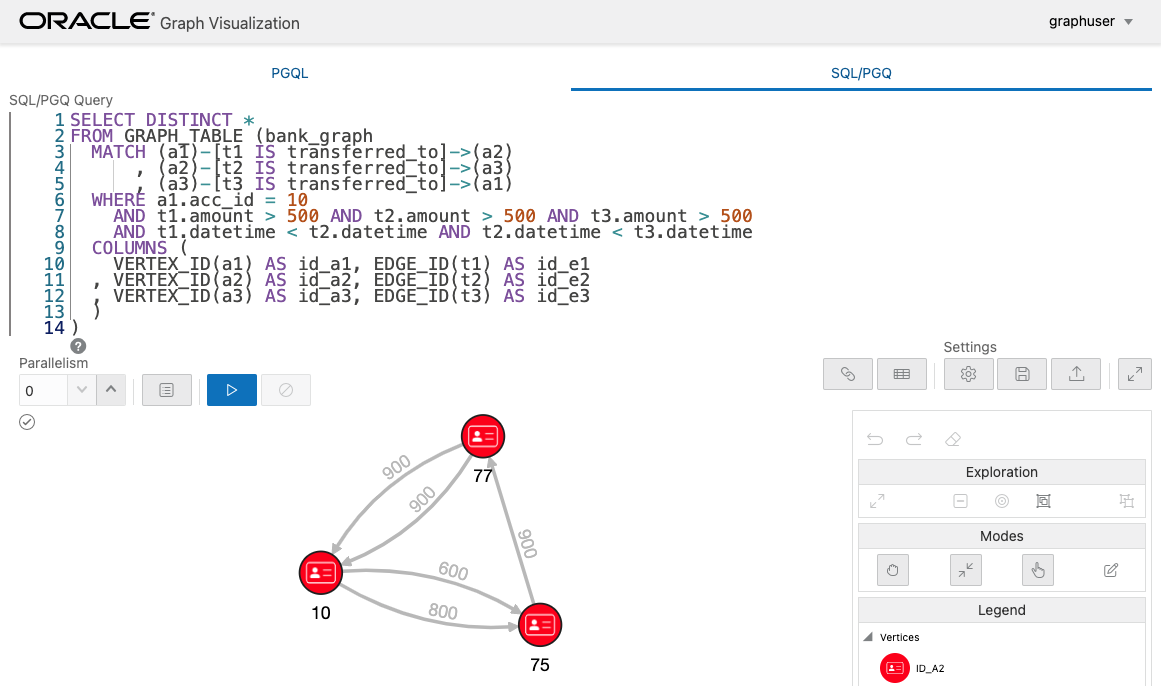
同様に 4 ホップのときも試してみます。
SELECT DISTINCT *
FROM GRAPH_TABLE (bank_graph
MATCH (a1)-[t1 IS transferred_to]->(a2)
, (a2)-[t2 IS transferred_to]->(a3)
, (a3)-[t3 IS transferred_to]->(a4)
, (a4)-[t4 IS transferred_to]->(a1)
WHERE a1.acc_id = 10
AND a1.acc_id != a3.acc_id AND a2.acc_id != a4.acc_id
AND t1.amount > 500 AND t2.amount > 500
AND t3.amount > 500 AND t4.amount > 500
AND t1.datetime < t2.datetime
AND t2.datetime < t3.datetime
AND t3.datetime < t4.datetime
COLUMNS (
VERTEX_ID(a1) AS id_a1, EDGE_ID(t1) AS id_e1
, VERTEX_ID(a2) AS id_a2, EDGE_ID(t2) AS id_e2
, VERTEX_ID(a3) AS id_a3, EDGE_ID(t3) AS id_e3
, VERTEX_ID(a4) AS id_a4, EDGE_ID(t4) AS id_e4
)
)
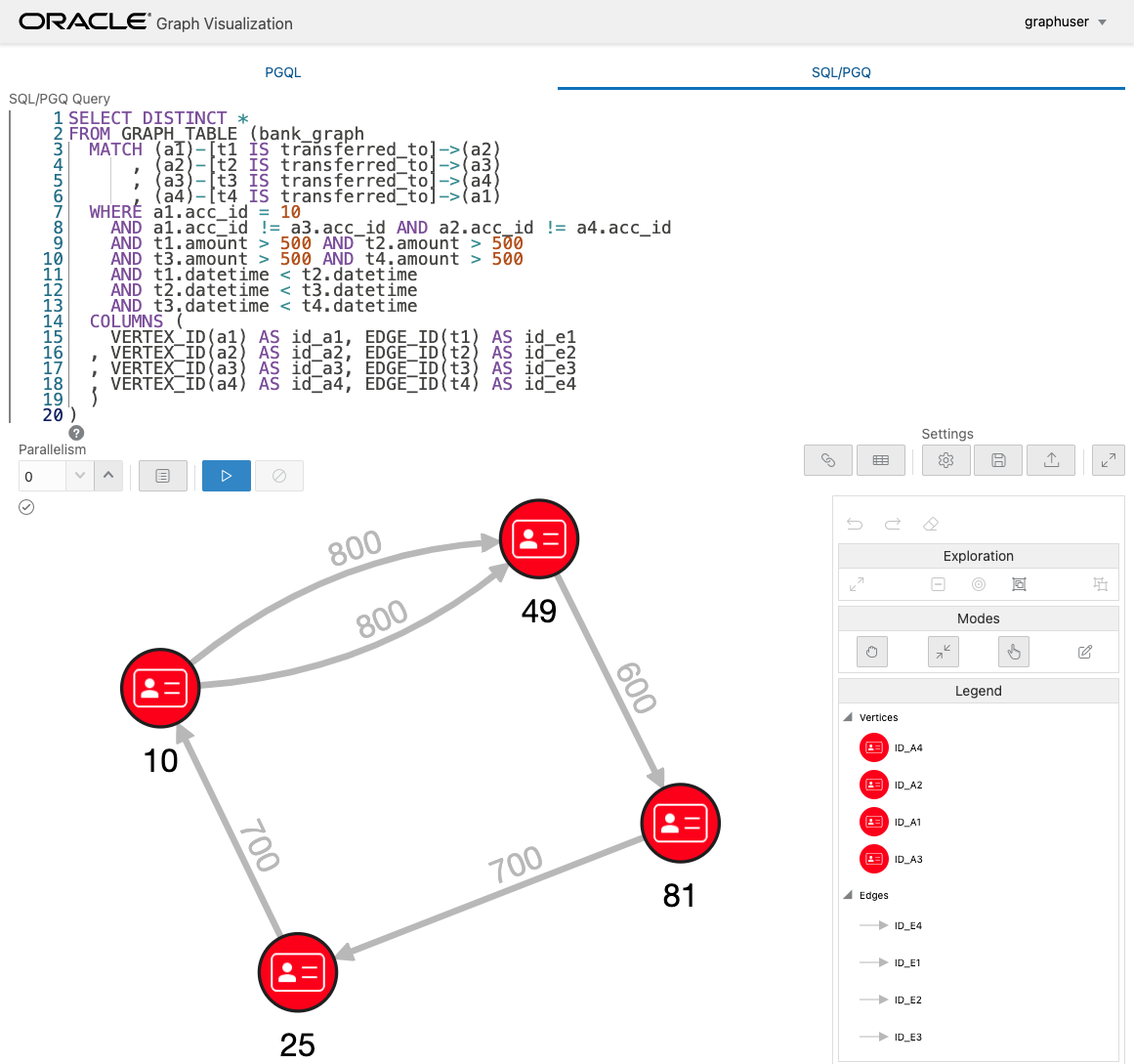
4 ホップの場合にも、このようなパターンがひとつだけ存在することがわかります。
GROUP BY を使った集計も可能です。例えば、10/1 から 12/1 までの期間に 500 未満の少額の送金を多く受け取った口座を検索してみます。
SELECT t.acc_id, COUNT(acc_id) AS num_of_txn
FROM GRAPH_TABLE (bank_graph
MATCH (a1)-[t IS transferred_to]->(a2)
WHERE t.datetime >= TIMESTAMP '2020-10-01 00:00:00'
AND t.datetime < TIMESTAMP '2020-12-01 00:00:00'
AND t.amount < 500.00
COLUMNS (
a2.acc_id
)
) t
GROUP BY t.acc_id
ORDER BY num_of_txn DESC
FETCH FIRST 10 ROWS ONLY
ただし、集計の結果はグラフとして表現することはできませんので、表で確認することになります。
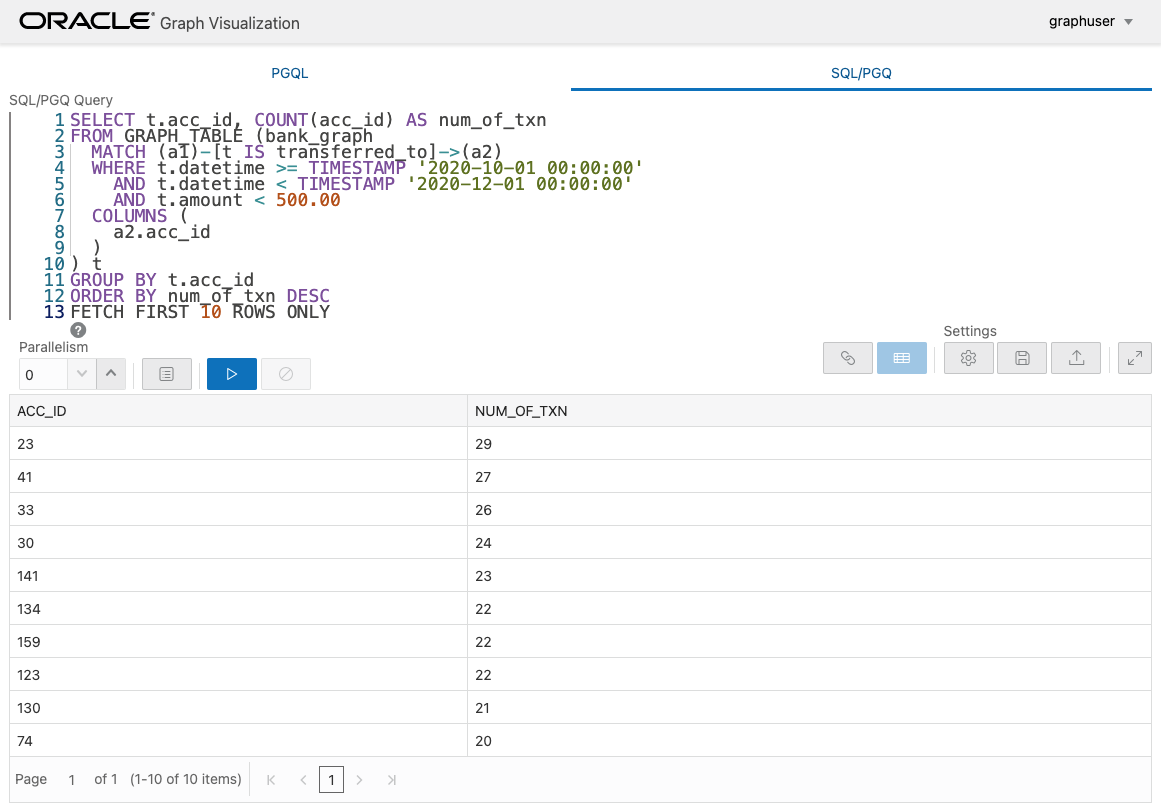
acc_id = 23 の口座は 29 回もの送金を受けていますので、これを可視化してみます。
SELECT *
FROM MATCH (a1)-[t:transferred_to]->(a2)<-[o:owns]-(c) ON graph2
WHERE t.datetime >= TIMESTAMP '2020-10-01 00:00:00'
AND t.datetime < TIMESTAMP '2020-12-01 00:00:00'
AND t.amount < 500.00
AND a2.acc_id = 23
取引を確認できます。
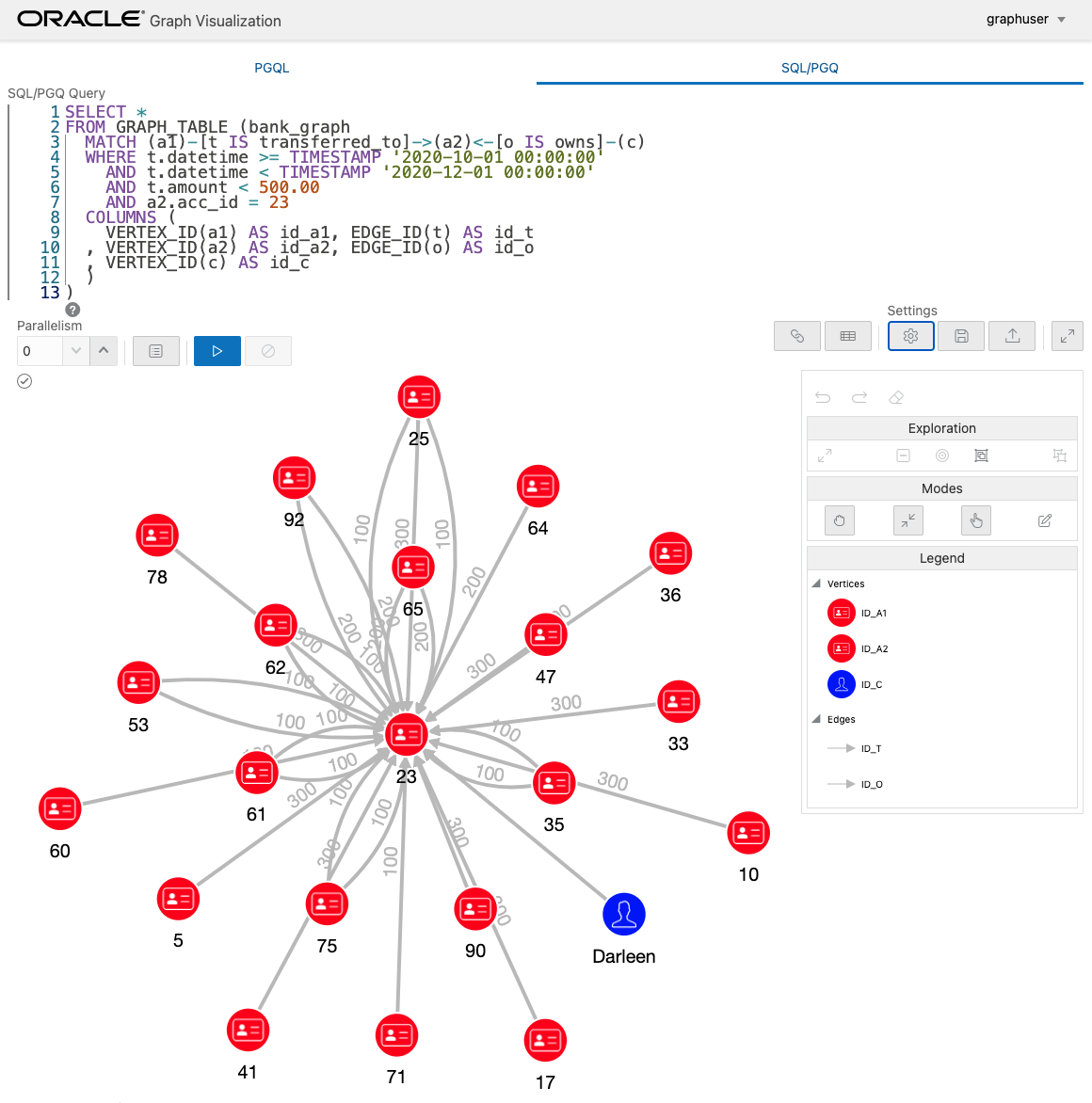
いかがでしょうか。表に格納されている銀行送金のようなトランザクションも CREATE PROPERTY GRAPH 文によってビューを作るだけで、グラフとして検索することが可能になることがわかるかと思います。これは、表の結合を CREATE PROPERTY GRAPH 文の中に隠蔽してしまうことによって、直感的で簡潔なクエリを書けるようにした、SQL の実行エンジンの進化と解釈することもできるかもしれません。
一方で、SQL は表として格納されたデータに対して実行されているため、これは「ネイティブの」グラフ・データベースではないという指摘もあるかもしれません。実のところ、グラフに最適化されたデータ構造を用いることで、グラフを辿るような一部のクエリの性能が向上したり、グラフ・アルゴリズムを効率的に実行できることがわかっています。これを実現する「Graph Server」を後編で紹介します。
※ 冒頭画像 Photo by Eduardo Soares on Unsplash(編集済み)