* この記事の内容は以前の製品を基に書かれています。新しい製品(Oracle Database 23c および Graph Server 23.2)や新しい SQL 仕様を用いる場合にはこちらの記事を参照してください。

前回の記事では、銀行の送金データをグラフとして表現して活用するために、ノードやエッジの追加とそれに対してパターン・マッチングによる検索、というグラフ・データベースの API(= SQL に代わる PGQL)を利用する方法を示しました。今回は、既存のデータベーステーブル上のビューとしてグラフを作成するという、異なるアプローチを紹介します。その上で、PGQL による検索とその結果の可視化を試します。
グラフとしてデータを作成すべきか
パターン・マッチングの記法がクエリを簡略化できる一方で、もしかすると、データをノードやエッジとして追加していくことにはあまりメリットが感じられないのではないかと思います。その一つの理由は、このユースケースの特徴として、ノードやエッジの種類ははじめから決まっているので、新たな種類のノードやエッジを自由に追加できる(=スキーマレス)という特徴の恩恵を受けることがないからではないかと考えられます。
グラフ・データベースのユースケースを議論していると、このようなケースが多いのが実情です。結局、表とそのスキーマはあったほうがよいのではないかとなるわけです。アプリケーション開発のためにデータベースのスキーマが固定されていることが望ましいという(論理層の)理由もあれば、上の送金データのトランザクション表のように集計処理が発生する場合には表の索引やスキャンを使用するのが効率的であるという(物理層の)理由もあります。
グラフをビューとして作成(PG View)
このようなケースで、グラフを(主に検索と分析で)活用するためには、表とグラフを併用するしかありませんし、今までもグラフ・データベースは RDBMS と共に使われてきました。そこで Oracle Graph が提供しているのが、CREATE PROPERTY GRAPH 文による表からグラフへの宣言的なマッピングとこれを用いて表データの上にグラフをビューとして作成するという機能です。この発想であれば、ETL 処理の追加やデータの二重持ちを避けることができます。
それでは試してみましょう。まずは通常の表を作成します。
DROP TABLE bank_account;
DROP TABLE bank_customer;
DROP TABLE bank_transaction;
CREATE TABLE bank_account (
acc_id NUMBER NOT NULL
, cst_id NUMBER NOT NULL
, CONSTRAINT account_pk PRIMARY KEY (acc_id)
);
CREATE TABLE bank_customer (
cst_id NUMBER NOT NULL
, first_name VARCHAR2(255)
, last_name VARCHAR2(255)
, CONSTRAINT customer_pk PRIMARY KEY (cst_id)
);
CREATE TABLE bank_transaction (
acc_id_src NUMBER
, acc_id_dst NUMBER
, txn_id NUMBER
, datetime TIMESTAMP
, amount NUMBER
, CONSTRAINT transaction_pk PRIMARY KEY (txn_id)
);
INSERT 文を用いたデータファイル(bank_account.sql, bank_customer.sql, bank_transaction.sql)を保存(右クリックでリンクを保存)して、これらをデータベースにロードします。CSV データをロードする場合にはこちら(bank_account.csv, bank_customer.csv, bank_transaction.csv)をお使いください。
SQL> @bank_account.sql
SQL> @bank_customer.sql
SQL> @bank_transaction.sql
SQLcl でデータベースにログインし、PGQL モードに切り替えます。
SQL> PGQL AUTO ON
ここが今回の記事で最も重要なポイント、表からグラフへのマッピングの書き方です。VERTEX TABLES と EDGE TABLES というブロックで、それぞれノードとエッジの情報源となる表とマッピング先のラベルを指定しています。
ここで、ノードについては顧客表から顧客ノード、口座表から口座ノードを作成しているだけなのでシンプルです。エッジについては、トランザクション表が保持する関係性に送金した(transferred_to)というラベルを付けて、口座表からはどの顧客がその口座を所有しているか(owns)というラベルの関係性を抜き出しています。
CREATE PROPERTY GRAPH graph2
VERTEX TABLES (
bank_customer
KEY (cst_id)
LABEL customer
PROPERTIES (cst_id, first_name, last_name)
, bank_account
KEY (acc_id)
LABEL account
PROPERTIES (acc_id)
)
EDGE TABLES (
bank_transaction
KEY (txn_id)
SOURCE KEY(acc_id_src) REFERENCES bank_account
DESTINATION KEY(acc_id_dst) REFERENCES bank_account
LABEL transferred_to
PROPERTIES (txn_id, datetime, amount)
, bank_account
KEY (acc_id)
SOURCE KEY(cst_id) REFERENCES bank_customer
DESTINATION KEY(acc_id) REFERENCES bank_account
LABEL owns
)
OPTIONS (PG_VIEW)
;
更に最後に OPTIONS (PG_VIEW) というオプションを付けることで、このグラフをビューとして作成しています。このオプションを付けない場合には、パート1で作成したグラフと同様に(PG スキーマと呼んでいる形式で)スキーマレスなグラフとして表に格納されます。ただし、グラフをスキーマレスで扱う必要のある場合を除いてはビューを使うことを推奨します。ビューであればデータを二重に持たずとも、グラフとしての API を使うことができるからです。
Graph Visualization ツールでこのグラフにアクセスできることを確認します。このビューはデータベース上に作成されたものなので、Advanced Options から接続先として「Database」を選択します。

クエリ対象の Graph として GRAPH2 を選択して、PGQL クエリを試してみましょう。
settings.json を保存(右クリックでリンクを保存)して、Load Settings ボタンからアップロードするとアイコンを次のように変更できます。
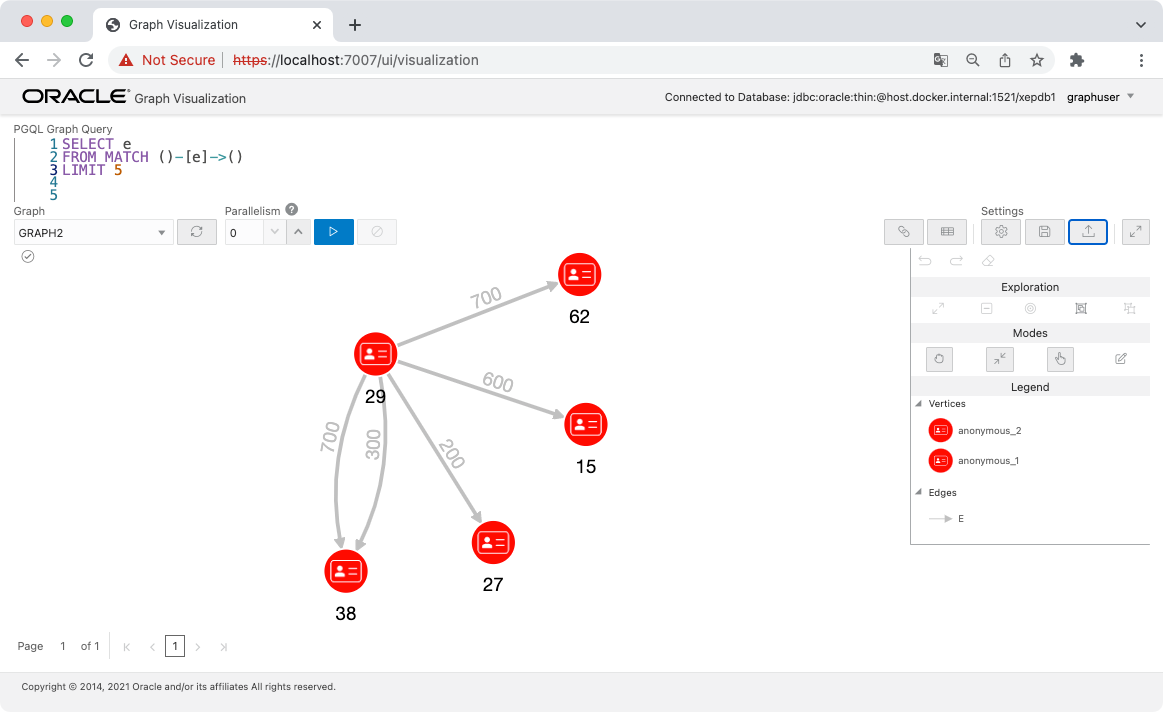
PGQL クエリで検索と可視化
それでは、せっかくなのでいくつか PGQL クエリによる検索とその結果の可視化を試してみたいと思います。Graph Visualization を使う場合には対象のグラフを既に指定しているので、クエリの中の ON graph2 は省いて実行することもできます。
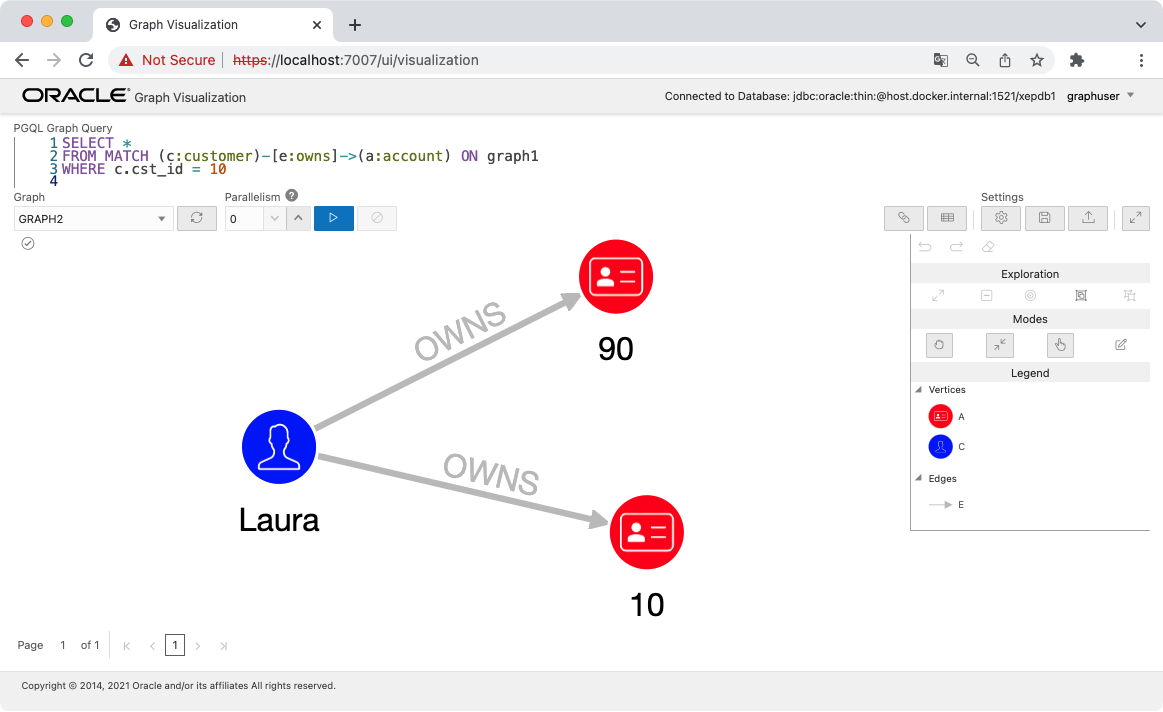
まずは、CST_ID = 10 の顧客が持っている口座を確認します。
SELECT *
FROM MATCH (c:customer)-[e:owns]->(a:account) ON graph2
WHERE c.cst_id = 10
この顧客の名前は Laura でふたつの口座を持っていることがわかります。
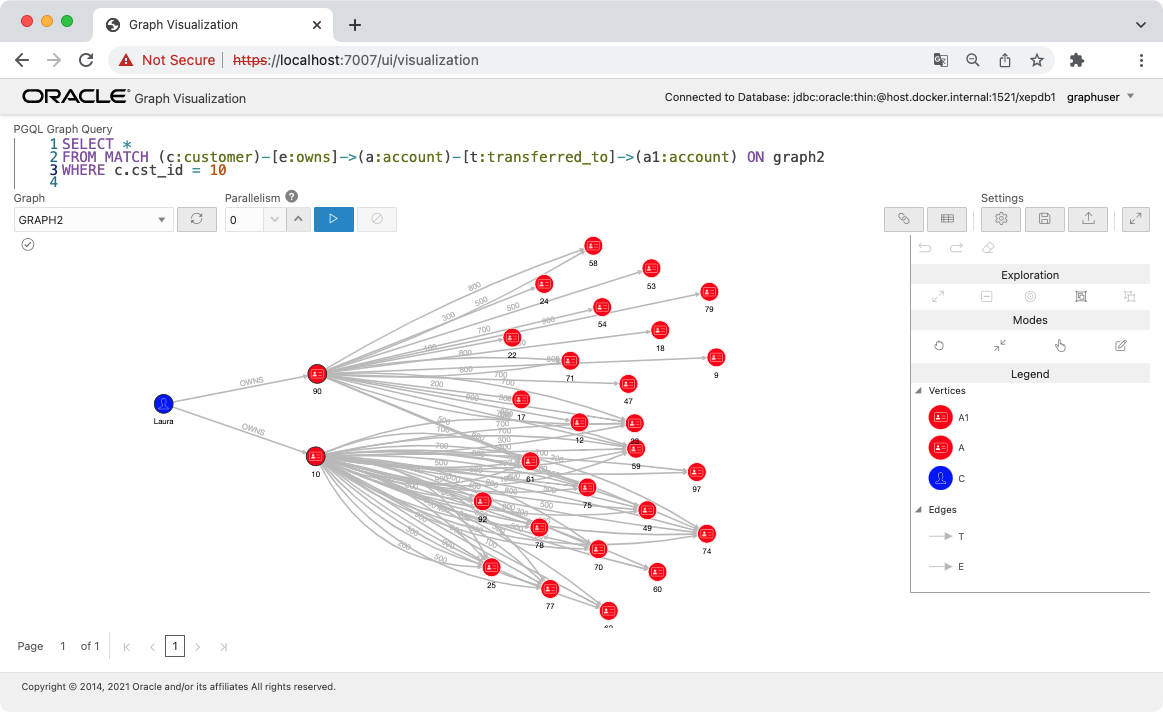
次に Laura の送金先を全て表示してみます。マッチングのパターンにもう 1ホップぶんのエッジとノードを増やすことになります。パターンの中にアカウントが 2つ出てくるので a と a1 のように別の変数を使っています。
SELECT *
FROM MATCH (c:customer)-[e:owns]->(a:account)-[t:transferred_to]->(a1:account) ON graph2
WHERE c.cst_id = 10
いくつかの口座に対しては、ふたつの口座の両方から送金をしていることがわかります。
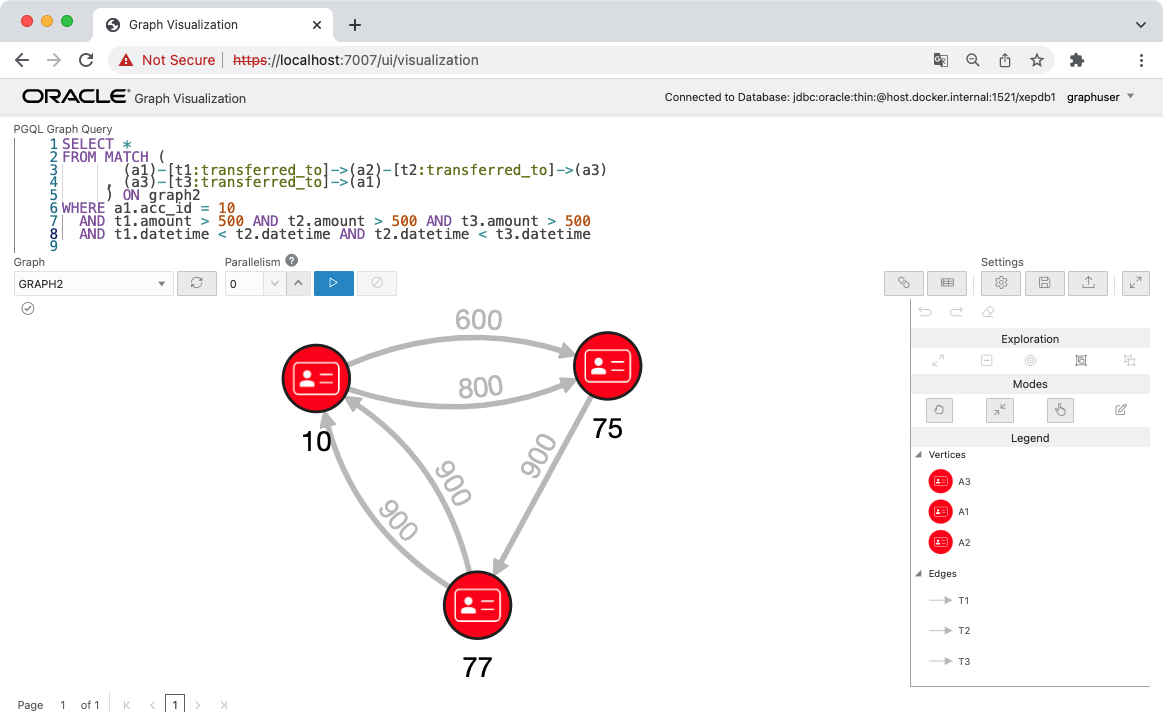
それでは、口座間の送金だけに着目して、acc_id = 10 のアカウントから 3ホップで戻ってくるようなパターンを探してみます。さらに、これらの送金は時間的にもこの順序で、送金額は常に 500 以上という条件も付けてみます。
SELECT *
FROM MATCH (
(a1)-[t1:transferred_to]->(a2)-[t2:transferred_to]->(a3)
, (a3)-[t3:transferred_to]->(a1)
) ON graph2
WHERE a1.acc_id = 10
AND t1.amount > 500 AND t2.amount > 500 AND t3.amount > 500
AND t1.datetime < t2.datetime AND t2.datetime < t3.datetime
acc_id が 10 > 75 > 77 というパスのみ、このようなパターンが存在することがわかりました。
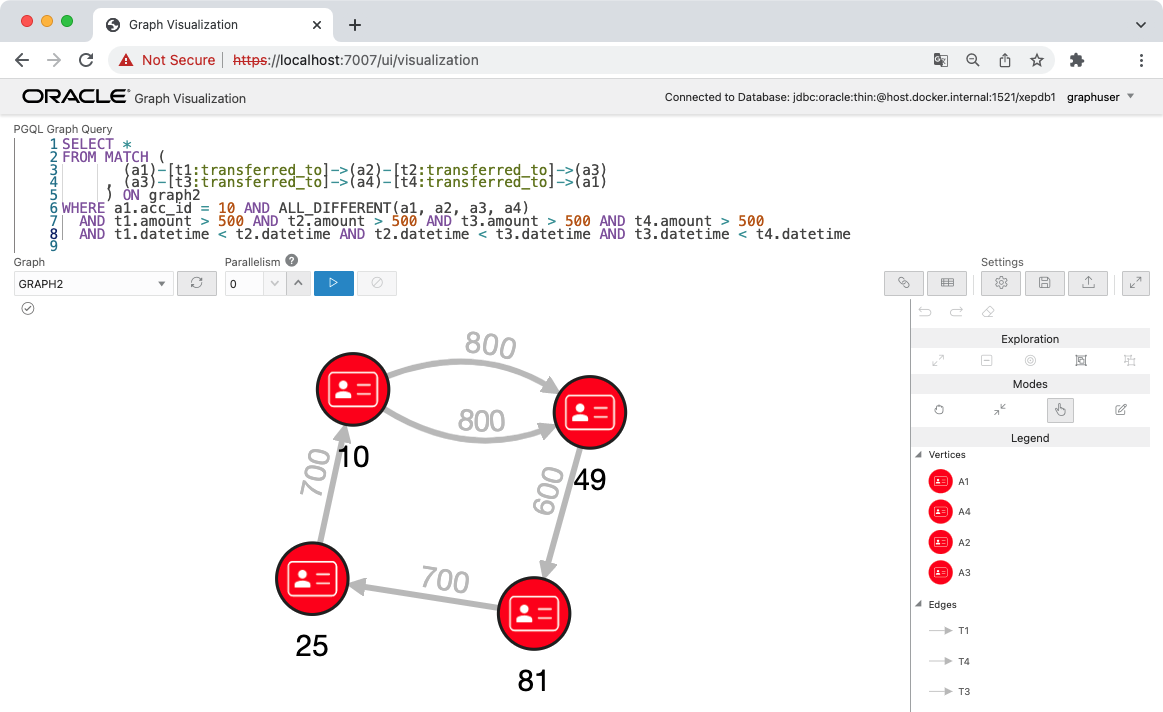
同様に 4ホップのときも試してみます。だんだんクエリは長くなってきましたが、SQL と比較するとずっと簡潔に書くことができます。
SELECT *
FROM MATCH (
(a1)-[t1:transferred_to]->(a2)-[t2:transferred_to]->(a3)
, (a3)-[t3:transferred_to]->(a4)-[t4:transferred_to]->(a1)
) ON graph2
WHERE a1.acc_id = 10 AND ALL_DIFFERENT(a1, a2, a3, a4)
AND t1.amount > 500 AND t2.amount > 500 AND t3.amount > 500 AND t4.amount > 500
AND t1.datetime < t2.datetime AND t2.datetime < t3.datetime AND t3.datetime < t4.datetime
4ホップの場合にも、このようなパターンがひとつだけ存在することがわかります。
GROUP BY を使った集計も可能です。例えば、10/1 から 12/1 までの期間に 500 未満の少額の送金を多く受け取った口座を検索してみます。
SELECT a2.acc_id AS acc_id, COUNT(a2) AS num_of_txn
FROM MATCH (a1)-[t:transferred_to]->(a2) ON graph2
WHERE t.datetime >= TIMESTAMP '2020-10-01 00:00:00'
AND t.datetime < TIMESTAMP '2020-12-01 00:00:00'
AND t.amount < 500.00
GROUP BY a2 ORDER BY num_of_txn DESC LIMIT 10
ただし、集計の結果はグラフとして表現することはできませんので、表で確認することになります。
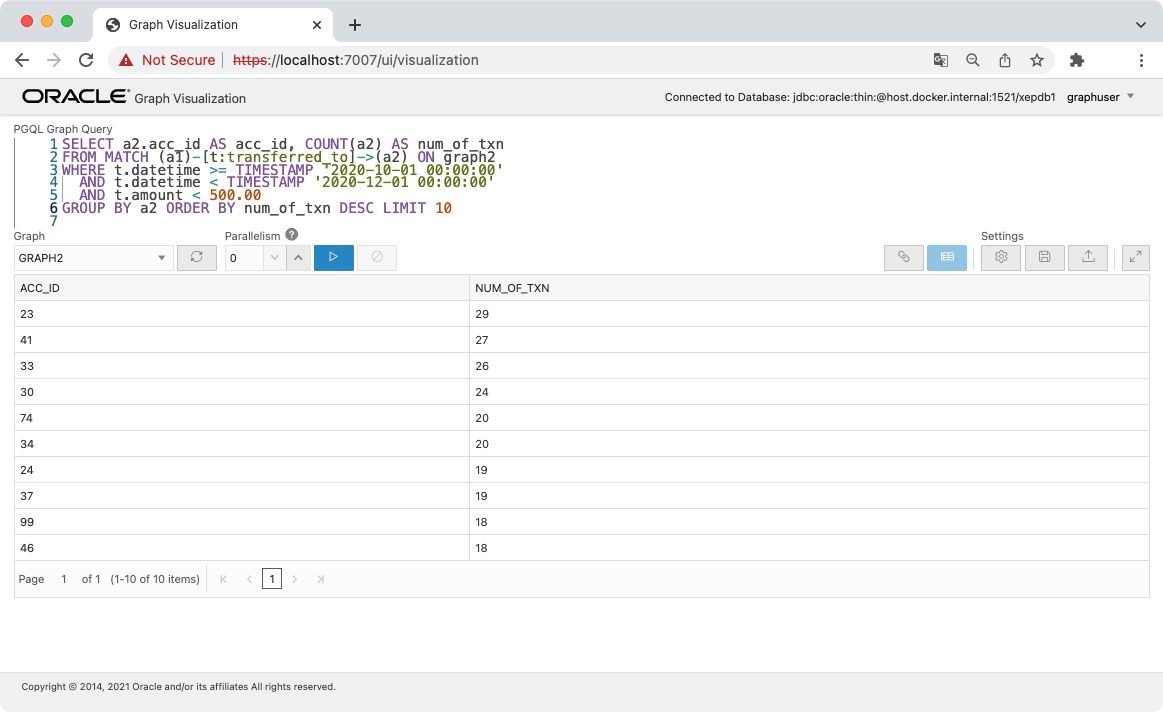
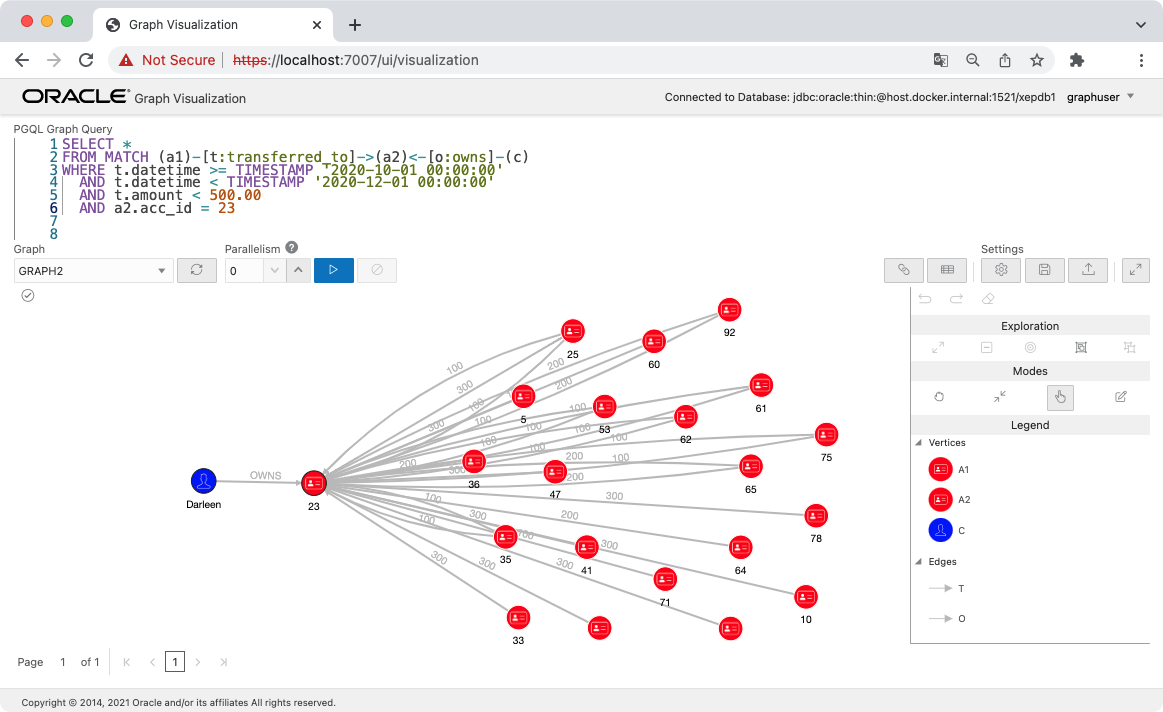
acc_id = 23 の口座は 29 もの送金を受けていますので、これを可視化してみます。
SELECT *
FROM MATCH (a1)-[t:transferred_to]->(a2)<-[o:owns]-(c) ON graph2
WHERE t.datetime >= TIMESTAMP '2020-10-01 00:00:00'
AND t.datetime < TIMESTAMP '2020-12-01 00:00:00'
AND t.amount < 500.00
AND a2.acc_id = 23
これらの送金を確認できました。
いかがでしょうか。表に格納されている銀行送金のようなトランザクション・データも CREATE PROPERTY GRAPH 文によってビューを作るだけで、グラフとして検索することが可能になることがわかるかと思います。これは、テーブル結合を CREATE PROPERTY GRAPH 文の中に隠蔽してしまうことによって、直感的で簡潔な PGQL クエリを書けるようにした、と解釈することもできるかもしれません。SQL という API は今後 PGQL のような言語とも統合されることで、まだまだ進化する余地があるのだろうと実感します。
一方で、PG ビューという仕組みでは、PGQL は SQL に変換されて実行されていますので、グラフを用いることによるクエリ性能の向上が期待できるわけではありません。この仕組みの上でグラフ・アルゴリズムを実行することも効率的ではありません。次回パート3では、それを克服するための 3-tier 構成について紹介します。
※ 冒頭画像 Photo by Eduardo Soares on Unsplash(編集済み)