* この記事の内容は以前の製品を基に書かれています。新しい製品(Oracle Database 23c および Graph Server 23.2)や新しい SQL 仕様を用いる場合にはこちらの記事を参照してください。

この記事では Oracle Graph を使い始める第一歩として、銀行の送金データをグラフとして扱う方法と、それによってどのような分析ができるかを見ていきたいと思います。実際のところ、金融機関における不正検知は現時点においてグラフ・データベースの主要な活用ユースケースの一つと言えますし、マネーロンダリング対策といった観点でも期待されているため、今後も活用範囲が拡がるだろうと推測しています。
では、なぜ銀行送金のようなトランザクションをグラフとして扱うと便利になり得るのか、まずは机上で考えてみたいと思います。例えば、次のような、顧客テーブル、口座テーブル、取引テーブルで構成された銀行取引のデータセットがあるとして(おそらくとても一般的な)次の2つの質問に答えたいとします。
- Bob と Charlie の間にはお金の流れがあるか。直接の取引がなくても、他の口座を介して間接的にお金の流れがあると言える場合もあります。
- 取引のクラスターがあるか。つまり、一部のアカウントの間で頻繁に取引が行われ、それらのアカウントと他のアカウントの間では取引が少ないというパターンがあるかどうかです。
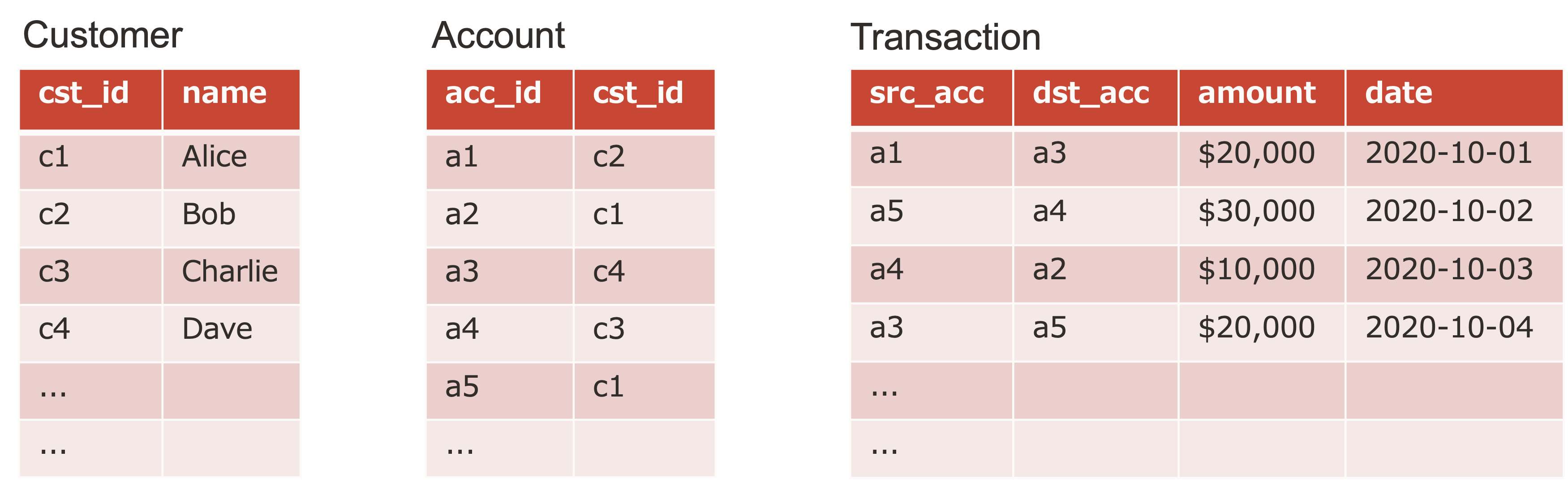
RDBMS を前提に考える場合、最初の質問に答えるには当然ながらテーブル同士の結合や自己結合が必要です。関連が見つかるまでのホップ数が多ければ、それだけ多くの結合が必要になります。2番目の質問に答えるのは難しく、おそらくグラフ構造を構築してクラスターを決定するための手続き型のコード(Oracle であれば PL/SQL)が必要になるでしょう。
それでは、グラフとして扱う場合を考えてみます。
グラフにはノードとエッジという2つの構造があるので、先の3つの表の情報をグラフとして表現する場合には、トランザクションをアカウント間のエッジとすることができます。その場合、次の図のように直感的な表現になるため、ひとつめ質問に答えるには、アカウント a1 から a3 、a5、そして a4 へとエッジを辿ればいいことがわかります。理想的には a1 と a4 の間のパスを検索するための効率的な手法が提供されているべきだろうと思います。

ふたつめの質問に答えるためには、グラフ・アルゴリズムを使ってトランザクションをもとにクラスターを検出する必要があります。このようなアルゴリズムは多く提案されており、コミュニティ検出とも呼ばれます。

まずは Oracle Graph の 2-tier deployment(= Graph Server を使わない構成)でデータの入出力を試してみたいと思います。既に Oracle Database で Oracle Graph が有効化されており、SQLcl に PGQL プラグインが追加されているという前提で記載します。
SQLcl でデータベースにログインし、PGQL モードに切り替えます。
PGQL AUTO ON
新しいグラフを作成します。バージョン 23.2 以降では OPTIONS (PG_SCHEMA) が必要なので注意してください。
CREATE PROPERTY GRAPH graph1 OPTIONS (PG_SCHEMA);
INSERT VERTEX 文を用いて、顧客と銀行口座の二種類のノードを追加します。
INSERT INTO graph1 VERTEX v LABELS ("CUSTOMER") PROPERTIES (v."CST_ID" = 'c1', v."FIRST_NAME" = 'Alice');
INSERT INTO graph1 VERTEX v LABELS ("CUSTOMER") PROPERTIES (v."CST_ID" = 'c2', v."FIRST_NAME" = 'Bob');
INSERT INTO graph1 VERTEX v LABELS ("CUSTOMER") PROPERTIES (v."CST_ID" = 'c3', v."FIRST_NAME" = 'Charlie');
INSERT INTO graph1 VERTEX v LABELS ("CUSTOMER") PROPERTIES (v."CST_ID" = 'c4', v."FIRST_NAME" = 'Dave');
INSERT INTO graph1 VERTEX v LABELS ("ACCOUNT") PROPERTIES (v."ACC_ID" = 'a1');
INSERT INTO graph1 VERTEX v LABELS ("ACCOUNT") PROPERTIES (v."ACC_ID" = 'a2');
INSERT INTO graph1 VERTEX v LABELS ("ACCOUNT") PROPERTIES (v."ACC_ID" = 'a3');
INSERT INTO graph1 VERTEX v LABELS ("ACCOUNT") PROPERTIES (v."ACC_ID" = 'a4');
INSERT INTO graph1 VERTEX v LABELS ("ACCOUNT") PROPERTIES (v."ACC_ID" = 'a5');
COMMIT;
INSERT EDGE 文を用いて、口座の所有(OWNS)と口座間の送金(TRANSFERRED_TO)の二種類のエッジを追加します。この際、各エッジの始点と終点となるノードを探してきて、それらの間にエッジを追加していることがわかるかと思います。このコストを省くために、ノードとエッジを一度の INSERT 文で追加する記法もありますが、ここではシンプルにエッジごとに INSERT 文を発行することにします。
INSERT INTO graph1 EDGE e BETWEEN src AND dst LABELS ("OWNS") FROM MATCH ((src), (dst)) ON graph1 WHERE src."CST_ID" = 'c1' AND dst."ACC_ID" = 'a2';
INSERT INTO graph1 EDGE e BETWEEN src AND dst LABELS ("OWNS") FROM MATCH ((src), (dst)) ON graph1 WHERE src."CST_ID" = 'c1' AND dst."ACC_ID" = 'a5';
INSERT INTO graph1 EDGE e BETWEEN src AND dst LABELS ("OWNS") FROM MATCH ((src), (dst)) ON graph1 WHERE src."CST_ID" = 'c2' AND dst."ACC_ID" = 'a1';
INSERT INTO graph1 EDGE e BETWEEN src AND dst LABELS ("OWNS") FROM MATCH ((src), (dst)) ON graph1 WHERE src."CST_ID" = 'c3' AND dst."ACC_ID" = 'a4';
INSERT INTO graph1 EDGE e BETWEEN src AND dst LABELS ("OWNS") FROM MATCH ((src), (dst)) ON graph1 WHERE src."CST_ID" = 'c4' AND dst."ACC_ID" = 'a3';
INSERT INTO graph1 EDGE e BETWEEN src AND dst LABELS ("TRANSFERRED_TO") PROPERTIES (e."AMOUNT" = '20000') FROM MATCH ((src), (dst)) ON graph1 WHERE src."ACC_ID" = 'a1' AND dst."ACC_ID" = 'a3';
INSERT INTO graph1 EDGE e BETWEEN src AND dst LABELS ("TRANSFERRED_TO") PROPERTIES (e."AMOUNT" = '20000') FROM MATCH ((src), (dst)) ON graph1 WHERE src."ACC_ID" = 'a3' AND dst."ACC_ID" = 'a5';
INSERT INTO graph1 EDGE e BETWEEN src AND dst LABELS ("TRANSFERRED_TO") PROPERTIES (e."AMOUNT" = '30000') FROM MATCH ((src), (dst)) ON graph1 WHERE src."ACC_ID" = 'a5' AND dst."ACC_ID" = 'a4';
INSERT INTO graph1 EDGE e BETWEEN src AND dst LABELS ("TRANSFERRED_TO") PROPERTIES (e."AMOUNT" = '10000') FROM MATCH ((src), (dst)) ON graph1 WHERE src."ACC_ID" = 'a4' AND dst."ACC_ID" = 'a2';
COMMIT;
それでは、早速これらのデータに PGQL クエリで検索をかけてみます。まずは Bob の持っている銀行口座を求めます。
SELECT c.first_name, a.acc_id
FROM MATCH (c:customer)-[:owns]->(a:account) ON graph1
WHERE c.first_name = 'Bob';
FIRST_NAME ACC_ID
_____________ _________
Bob a1
次にこの銀行口座からの送金先の口座を調べます。
SELECT c.first_name, a.acc_id AS a1, t.amount, a2.acc_id AS a2
FROM MATCH (c:customer)-[:owns]->(a:account)-[t:transferred_to]->(a2:account) ON graph1
WHERE c.first_name = 'Bob';
FIRST_NAME A1 AMOUNT A2
_____________ _____ _________ _____
Bob a1 20000 a3
同様に送金先の口座の持ち主もわかるはずです。
SELECT c.first_name AS c1, a.acc_id AS a1, t.amount, a2.acc_id AS a2, c2.first_name AS c2
FROM MATCH (c:customer)-[:owns]->(a:account)-[t:transferred_to]->(a2:account)<-[:owns]-(c2:customer) ON graph1
WHERE c.first_name = 'Bob';
C1 A1 AMOUNT A2 C2
______ _____ _________ _____ _______
Bob a1 20000 a3 Dave
さらに、到達可能性を評価するクエリを用いれば、送金のパスの長さを1〜3のように指定することができます。すると、Charlie がつながっていることがわかります。
SELECT c.first_name AS c1, a.acc_id AS a1, a2.acc_id AS a2, c2.first_name AS c2
FROM MATCH (c:customer)-[:owns]->(a:account)-/:transferred_to{1,3}/->(a2:account)<-[:owns]-(c2:customer) ON graph1
WHERE c.first_name = 'Bob';
C1 A1 A2 C2
______ _____ _____ __________
Bob a1 a5 Alice
Bob a1 a3 Dave
Bob a1 a4 Charlie
ここまで、ほんの少しではありますが、トランザクションを「グラフとして扱う」データベースの発想が PGQL という API を通して掴めて頂けたのではないかと思います。
しかしその一方で、おそらくいくつかの疑問が残ります。このような新しい API を使うために、私達は全てのデータをグラフとして扱わないといけないのでしょうか。また、仮にグラフとしてデータを保持した場合、パスを検索する、もしくはコミュニティを検出する、といった操作はどのような実装によって可能になるのでしょうか。
※ 冒頭画像 Photo by Eduardo Soares on Unsplash(編集済み)