Azure Data Factory でAzure Databricks Delta Lakeをソース、シンクにする際の利用方法と挙動の考察
はじめに
Azure Data Factory (以下、ADF)で Azure Databrikcsで作成したDelta Lake テーブルをソース、シンクにする際の利用方法について、注意ポイントや、データアクセスの流れを考察します。
Azure Databricks Delta Lake との間でデータをコピーする - Azure Data Factory | Microsoft Docs
ADFはMapping DataflowというSpark環境からDelta Lakeのデータにアクセス可能ですが、今回の記事では対象外
(2020/12時点の情報です。)
Delta Lakeについて参考リンク
今注目のストレージ層技術で、データレイク中心のデータ基盤でデータの管理・統合を行うためのAPIが提供されるフォーマットです。
※ストレージをDBMSのように扱える。
Delta Lake - 次世代型データレイク・データウェアハウス - Databricks
Delta Lakeを含む、データレイク上のSW技術に関してこちらを一読するのをおすすめ
大規模データ活用向けストレージレイヤソフトのこれまでとこれから(NTTデータ テクノロジーカンファレンス 2019 講演資料、2019/09/05)
ADF Copyの前提条件から考えるデータアクセス
以下のような記載になっており、ADFのDelta LakeコネクタでのCopyはAzure IRではなく、Azure Databrikcsがソースシンクに直接アクセスして実行されることがわかります。
この Azure Databricks Delta Lake コネクタを使用するには、Azure Databricks でクラスターを設定する必要があります。
- Delta Lake にデータをコピーする場合、コピー アクティビティは Azure Databricks クラスターを呼び出して、Azure Storage からデータを読み取ります。これは元のソースまたはステージング領域で、Data Factory が組み込みのステージング コピーを介してソース データを最初に書き込みます。 詳細については、「ソースとしての Delta Lake」を参照してください。
- 同様に、Delta Lake からデータをコピーする場合、コピー アクティビティは Azure Databricks クラスターを呼び出して、Azure Storage にデータを書き込みます。これは元のシンクまたはステージング領域で、Data Factory が引き続き組み込みのステージング コピーを介して最終的なシンクにデータを書き込みます。 詳細については、「シンクとしての Delta Lake」を参照してください。
Databricks クラスターは、Azure Blob または Azure Data Lake Storage Gen2 アカウントにアクセスできる必要があります。これは、ソース/シンク/ステージングに使用されるストレージ コンテナー/ファイル システムと、Data Lake テーブルを書き込むコンテナー/ファイル システムの両方です。
- Azure Data Lake Storage Gen2 を使用するには、Apache Spark 構成の一部として、Databricks クラスターで サービス プリンシパル または ストレージ アカウント アクセス キー を構成します。 「サービス プリンシパルを使用した直接アクセス」または「ストレージ アカウント アクセス キーを使用した直接アクセス」の手順に従います。
- Azure Blob Storage を使用するには、Apache Spark 構成の一部として、Databricks クラスターで ストレージ アカウント アクセス キー または SAS トークン を構成します。 「RDD API を使用した Azure Blob Storage へのアクセス」の手順に従います。
コピー アクティビティの実行中、構成したクラスターが終了した場合は、Data Factory によって自動的に開始されます。 Data Factory オーサリング UI を使用してパイプラインを作成する場合、データのプレビューなどの操作にはライブ クラスターが必要ですが、Data Factory によってクラスターが起動されることはありません。
イメージ

また、このアクセスの際にはマウントによるアクセスはテーブルを参照する場合にのみ実施されると考えられます。
実際に、準備の中で、直接アクセス用のsparkConfを設定しない場合、エラーが発生します。

検証
準備
ADFとストレージアカウントとDatabricksを利用します。
ストレージアカウント
ストレージアカウントは二つのコンテナを用意しておきます。
- adf: ADFで出力、読み取りするコンテナ
- databricks: Databricksで出力、読み取りするコンテナ
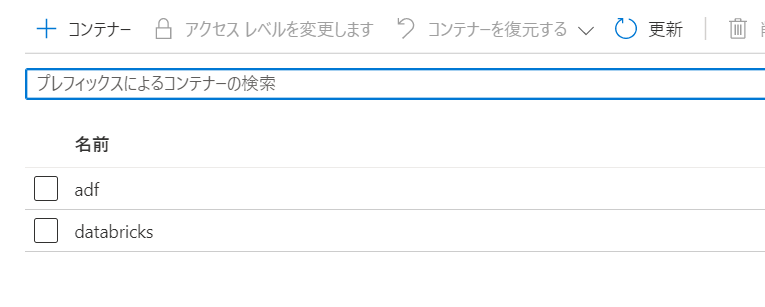
datafactory にはadfコンテナのみ権限をあたえます。

Azure Databricks
クイック スタート - Azure portal を使用して Azure Databricks ワークスペースで Spark ジョブを実行する | Microsoft Docsを参考にクラスタを作成します。
このとき、後述のクラスター構成、およびRDD APIでの直接アクセス設定に従って、spark configを設定します。
クラスター構成でsecretを利用する方法は不明でした。。
spark.databricks.delta.optimizeWrite.enabled true
spark.databricks.delta.autoCompact.enabled true
fs.azure.sas.<コンテナ名>.<ストレージアカウント名>.dfs.core.windows.net sasurl例:https://<ストレージアカウント名>.dfs.core.windows.net/コンテナ名/?sv=xxxx
※blob.coreはADLSが相手先の場合はdfs.coreに変更

ストレージアカウントをマウント
# 対象
storageAccount = "ストレージアカウント名"
containerName = "databricks"
# key 取得
accountKey = "アカウントキー"
try:
dbutils.fs.unmount("/mnt/databricks")#すでにマウントされていればアンマウント
print('Unmount!')
except:
print('Already Unmount!')
result=dbutils.fs.mount(
source = "wasbs://" + containerName + "@" + storageAccount + ".blob.core.windows.net/",
mount_point = "/mnt/databricks",
extra_configs = {"fs.azure.account.key."+storageAccount+".blob.core.windows.net":accountKey}
)
print('Mount!')
次に外部テーブルを作成
delta_route = "/mnt/databricks/delta/"
delta_path_sink= delta_route +"sink/"
delta_path_source=delta_route +"source/"
spark.sql("DROP TABLE IF EXISTS delta_Table_sink")
spark.sql(
"""
CREATE TABLE delta_Table_sink (
battery_level long
,02_level long
,ca2 string
,ca3 string
,n string
,evice_id long
,evice_name string
,umidity long
,p string
,atitude double
,cd string
,ongitude double
,cale string
,temp long
,timestamp long
)
using DELTA
LOCATION '{}'
""".format(delta_path_sink)\
)
spark.sql("DROP TABLE IF EXISTS delta_Table_source")
spark.sql(
"""
CREATE TABLE delta_Table_source (
battery_level long
,02_level long
,ca2 string
,ca3 string
,n string
,evice_id long
,evice_name string
,umidity long
,p string
,atitude double
,cd string
,ongitude double
,cale string
,temp long
,timestamp long
)
using DELTA
LOCATION '{}'
""".format(delta_path_source)\
)
作成後、以下のようになります。
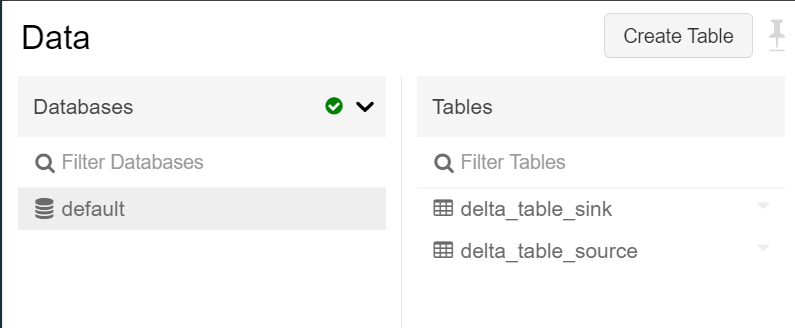
データ登録をして準備完了
df = spark.read.json("dbfs:/databricks-datasets/iot/iot_devices.json")
df.write.insertInto("delta_Table_source")
# display(df)
Azure Data Factory
最後に、ADFのlinked Serviceを構成しておきます。

Databricksについては、先ほど作成したクラスターを利用するように指定します。
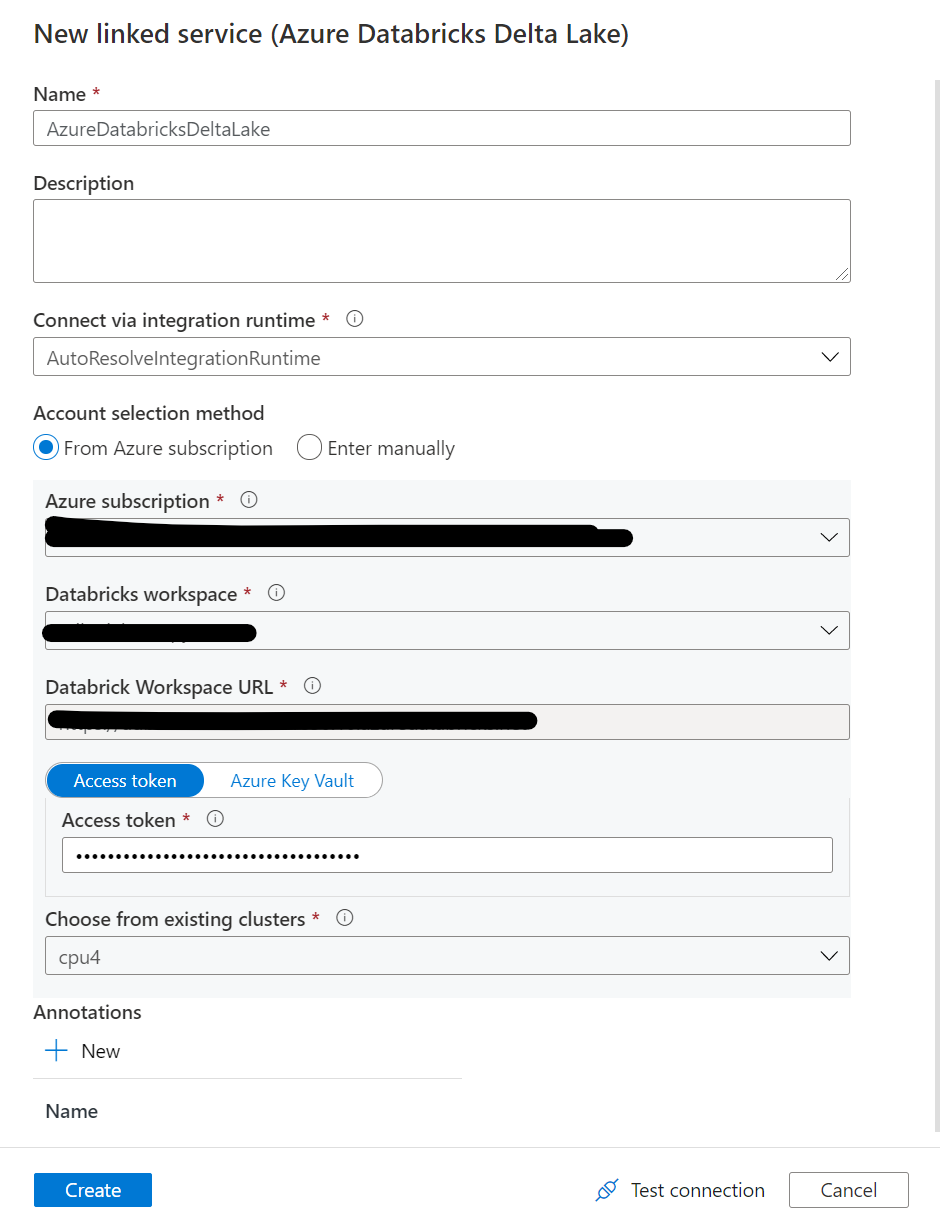
Copy Delta Lake -> Storage
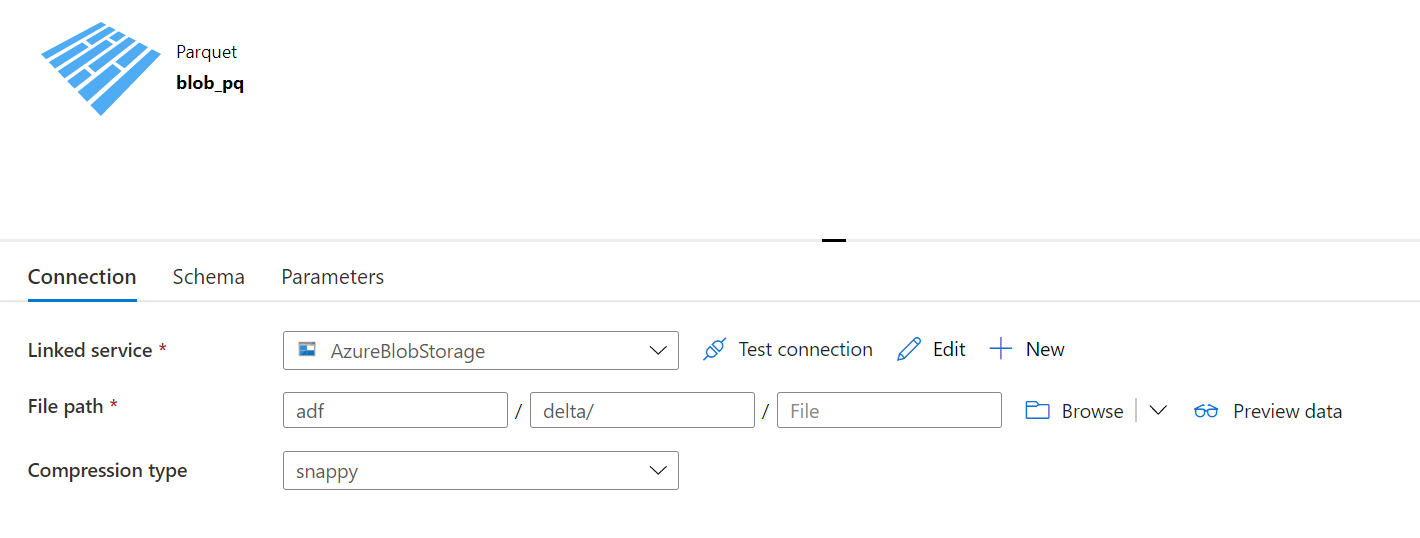
ソースデータセット
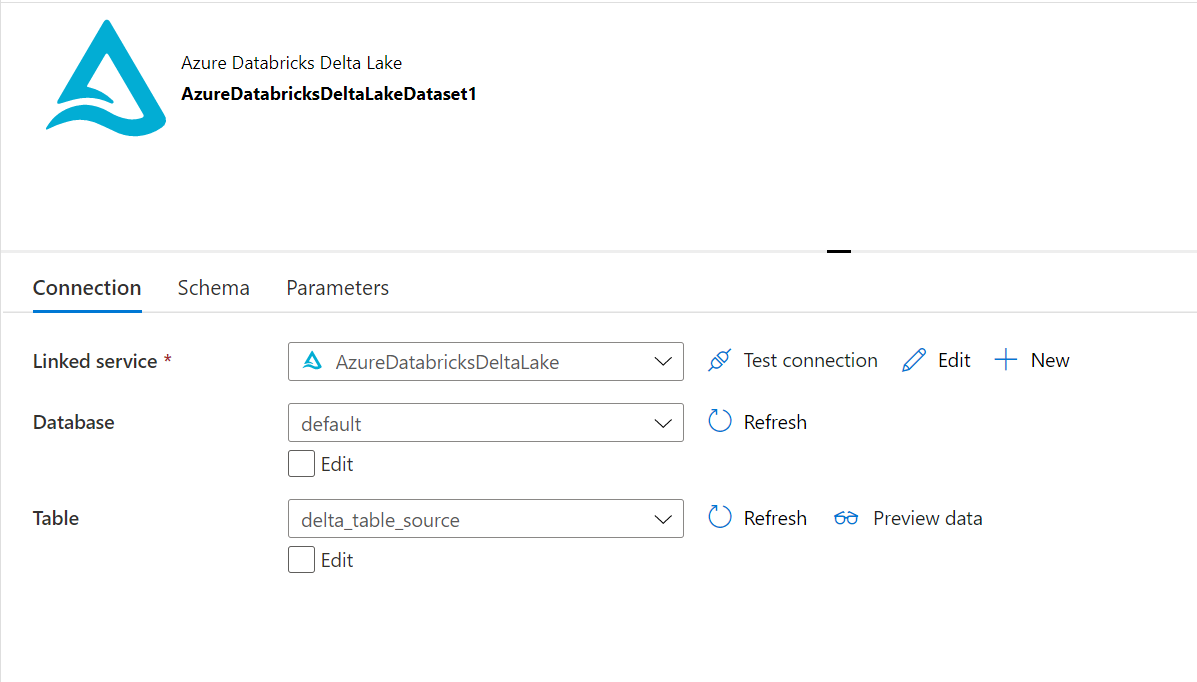
シンクデータセット
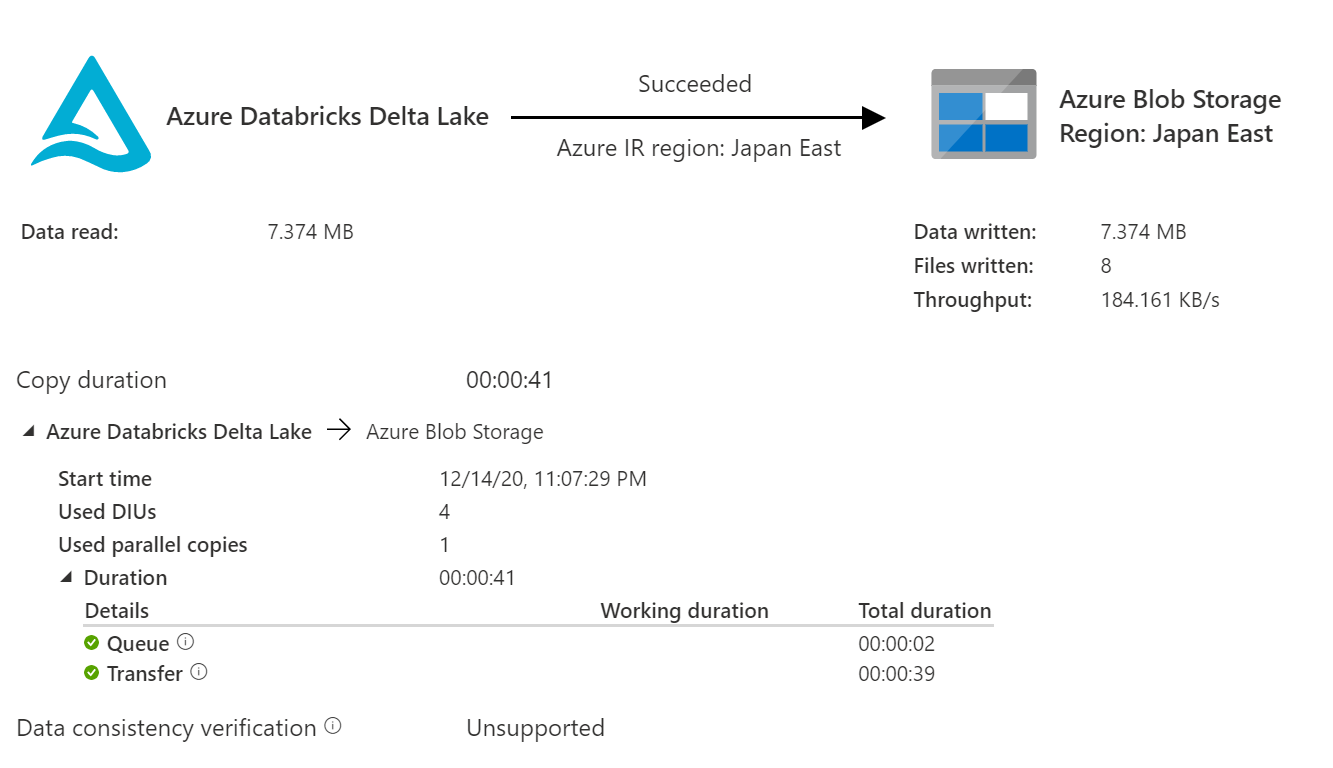
結果
Copy Storage -> Delta Lake
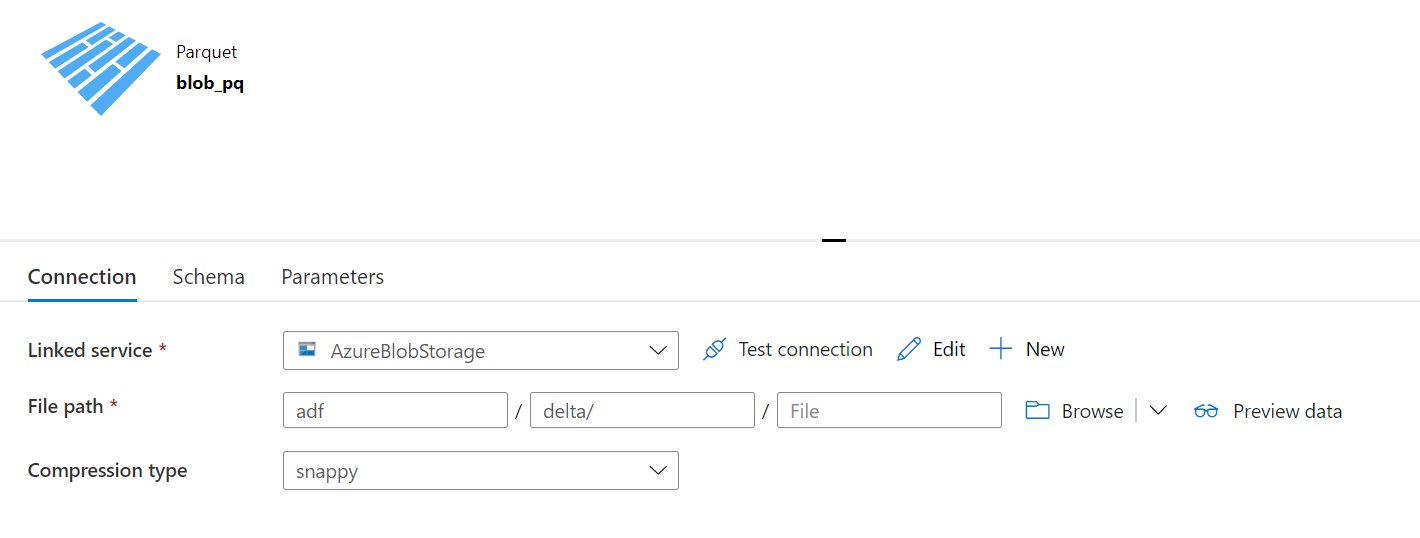
ソースデータセット
シンクデータセット

結果(直接コピー)
直接コピーの場合、Wildcard folder pathは指定できません。

結果

結果(ステージングコピー)
ステージングコピーが現実的でしょう

結果

トラブルシューティング
pythonで直接アクセスを設定してもうまくいかない
以下はnotebook上でのdata frame API、RDD API用の構成設定ですが、クラスターが停止されると保持されない設定のため、ADFからの実行だと使えません
spark.conf.set(
"fs.azure.account.key.<storage-account-name>.blob.core.windows.net",
"<storage-account-access-key>")
%scala
// Using an account access key
spark.sparkContext.hadoopConfiguration.set(
"fs.azure.account.key.<storage-account-name>.blob.core.windows.net",
"<storage-account-access-key>"
)
RDDでのspark conf設定
spark.hadoop.fs.azure.sas.<コンテナ名>.<ストレージアカウント名>.blob.core.windows.net sasurl例:https://<ストレージアカウント名>.blob.core.windows.net/コンテナ名/?sv=xxxx
エラーメッセージ全文
※ストレージアカウント名はxxxに置換
ErrorCode=AzureDatabricksCommandError,Hit an error when running the command in Azure Databricks. Error details: shaded.databricks.org.apache.hadoop.fs.azure.AzureException: shaded.databricks.org.apache.hadoop.fs.azure.AzureException: Container adf in account xxx.blob.core.windows.net not found, and we can't create it using anoynomous credentials, and no credentials found for them in the configuration. Caused by: shaded.databricks.org.apache.hadoop.fs.azure.AzureException: Container adf in account xxx.blob.core.windows.net not found, and we can't create it using anoynomous credentials, and no credentials found for them in the configuration..