はじめに
Microsoft Fabric には、統合したデータ(Delta Lake 形式)について自動的に Iceberg メタデータを生成する機能と、OneLake Table API により REST Catalog を公開する機能があります。今回はこれらを試してみます。
なお、以前の Microsoft Fabric での Iceberg 利用の記事は以下です。
Microsoft Fabric における Iceberg 仮想化機能
Microsoft Fabric の OneLake には、Apache XTable を使用して Iceberg メタデータを生成する機能があります。

これにより、Snowflake などの Iceberg と統合可能なデータプラットフォームとの相互運用性を実現できます。
また、Iceberg REST Catalog(IRC)仕様に対応した Table API を使用することで、Iceberg クライアントからより効率的に Iceberg テーブルを参照できます。
検証
テナント設定の確認
テナント設定で、Delta Lake から Apache Iceberg へのテーブル形式の仮想化を有効にする (プレビュー)を有効にしておきます。

データの用意
二つの種類のデータを使ってみたいと思います。
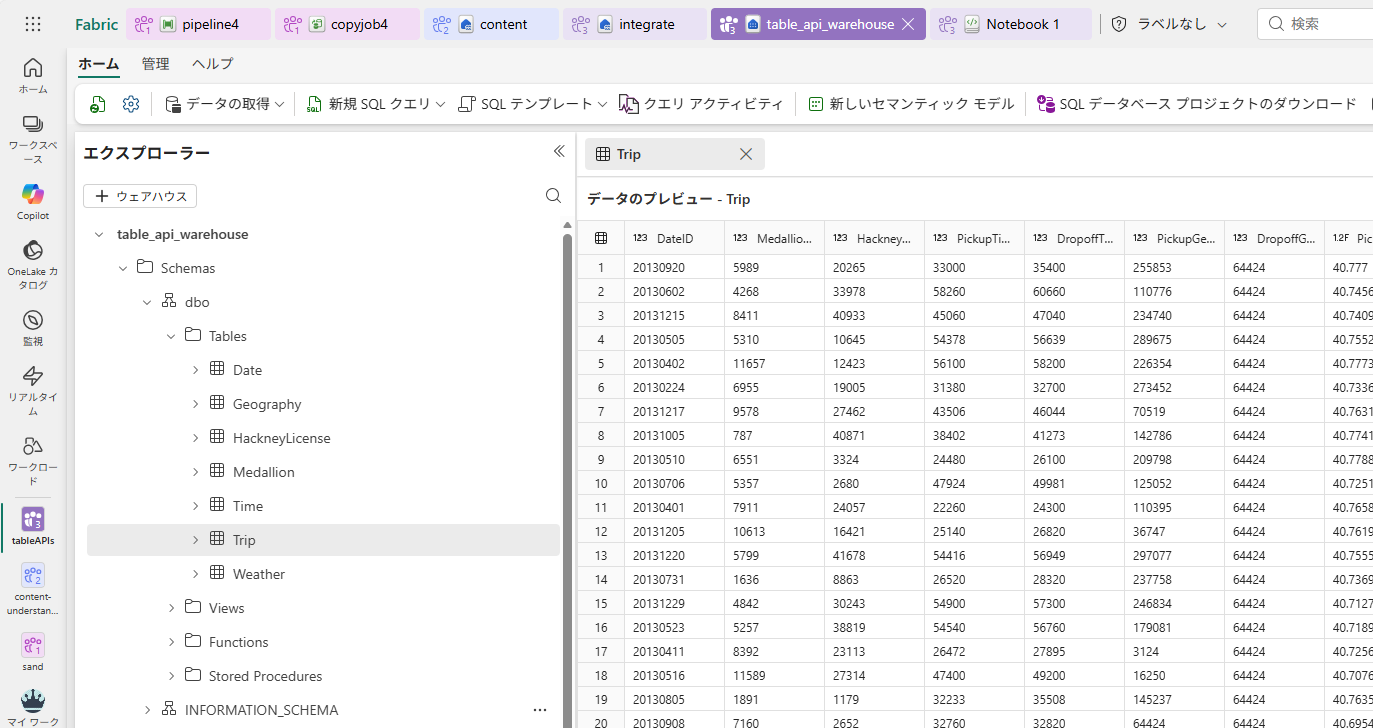
Fabric ウェアハウス
ウェアハウスサンプル を参考に、ウェアハウスとして OneLake 上でサンプルデータを展開します。
BigQuery
クイックスタート:データの読み込みとクエリ にしたがって、Big Query 上にサンプルデータを展開します。

データ統合
BigQuery ミラーリング
チュートリアル: Google BigQuery のミラーリングを設定する (プレビュー) を実施します。
-
アイテム作成にてミラーリングアイテムを選択します
-
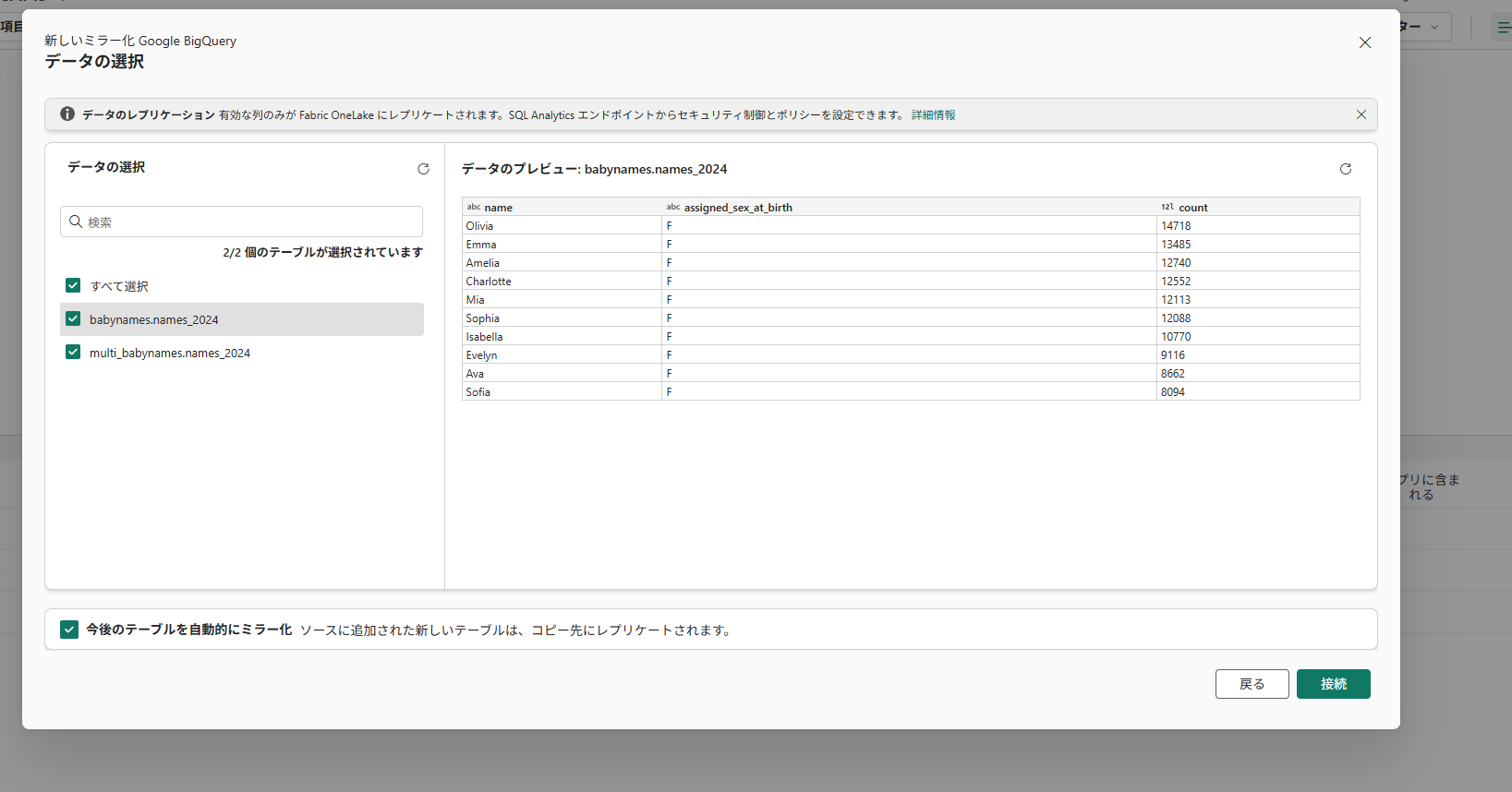
テーブルを選択します。
-
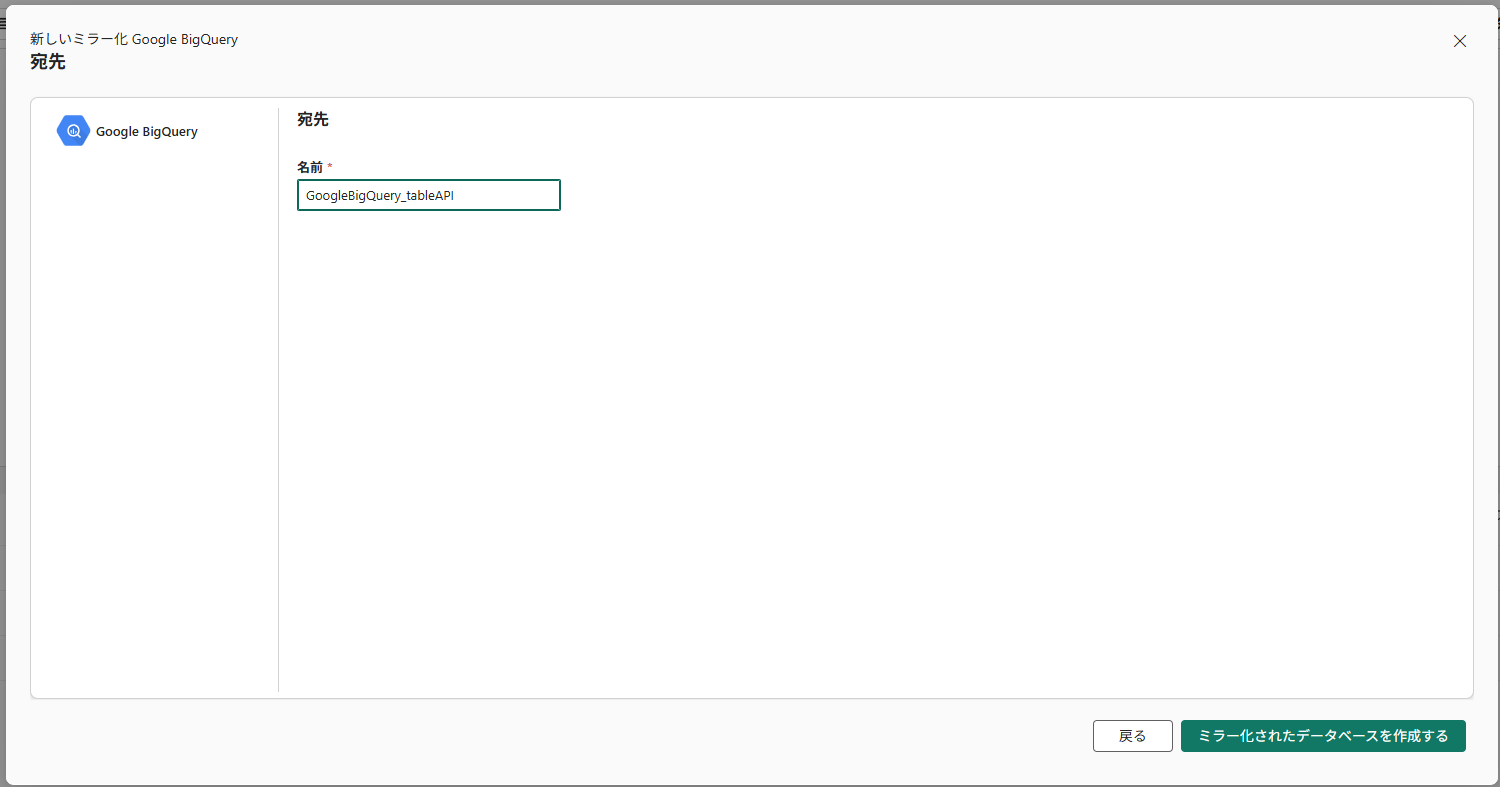
作成されるミラーリングアイテムの名称を決定し、作成します。
-
同期の完了を待ち、SQL 分析エンドポイント上でデータを確認します。



これで OneLake 上に BigQuery データがレプリケーションされました。
OneLake ショートカット
OneLake 上に保存されているデータは OneLake ショートカットにより仮想統合が可能です
-
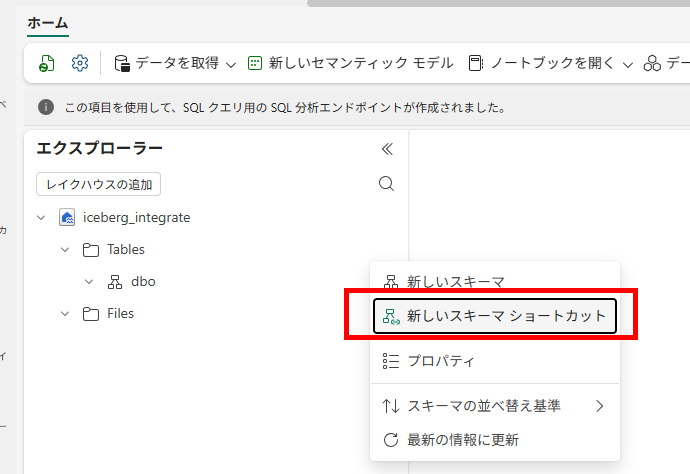
レイクハウスを作成し、ウェアハウス用のスキーマショートカットを作成します。
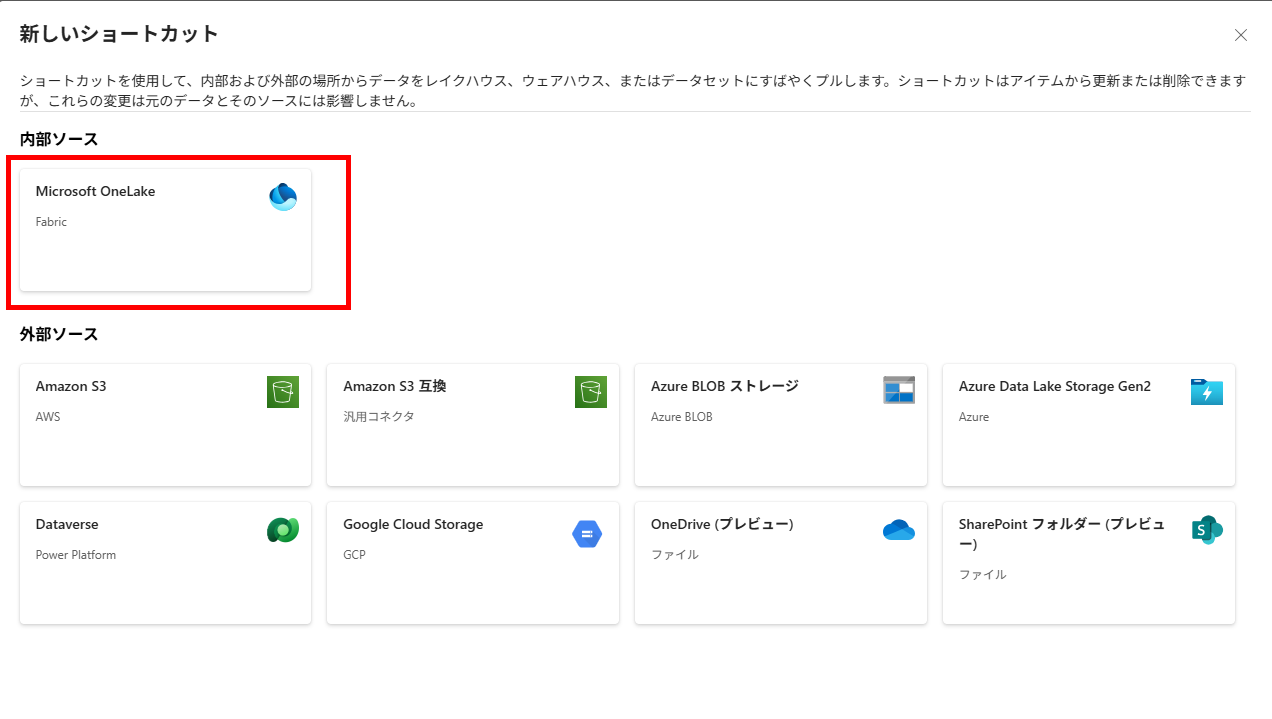

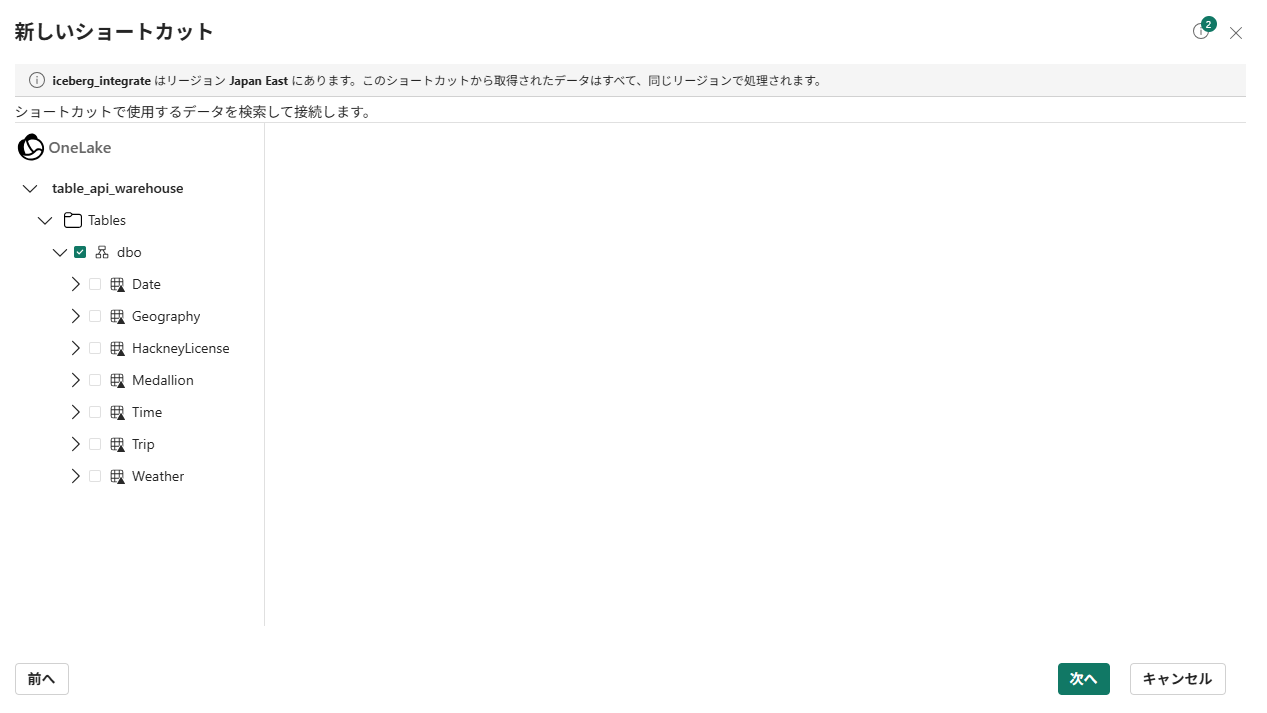

-
データを確認します。
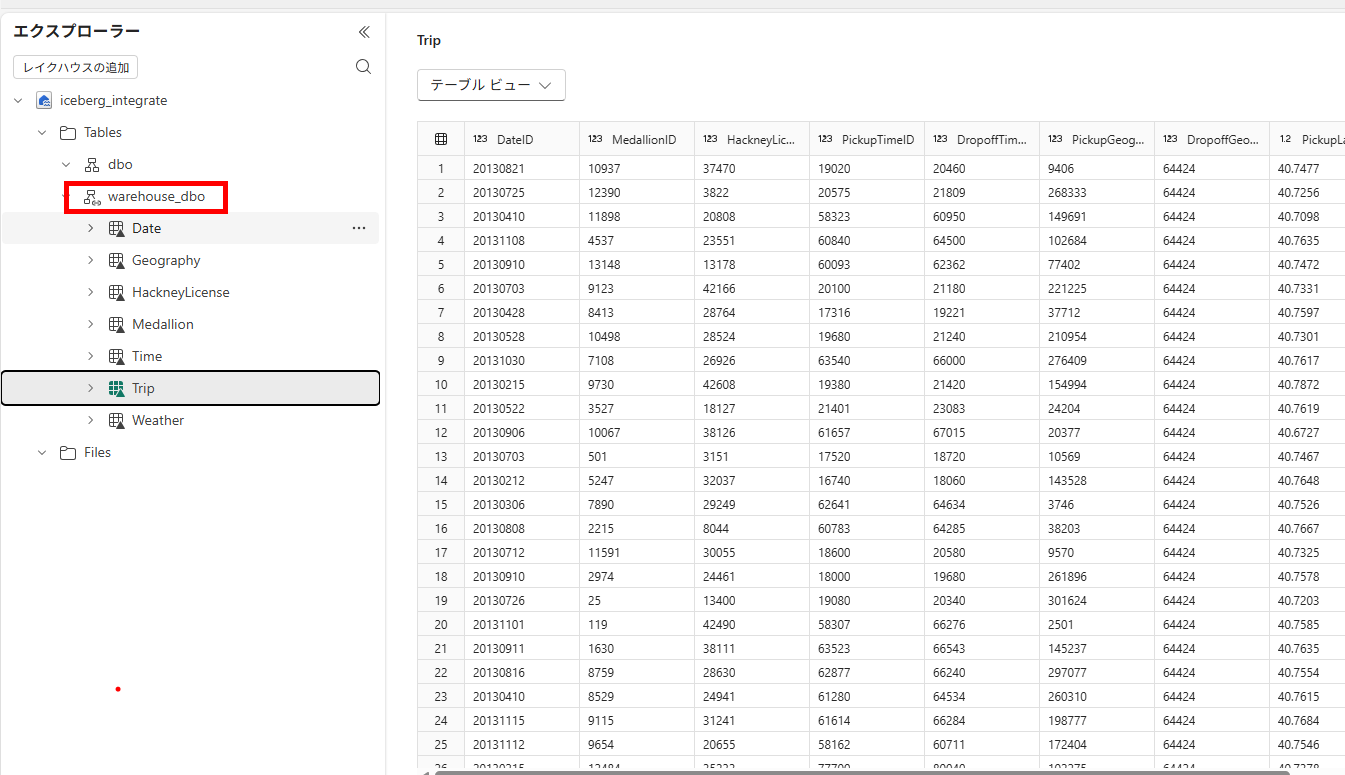
-
Iceberg メタデータが作成されていることも確認できます。
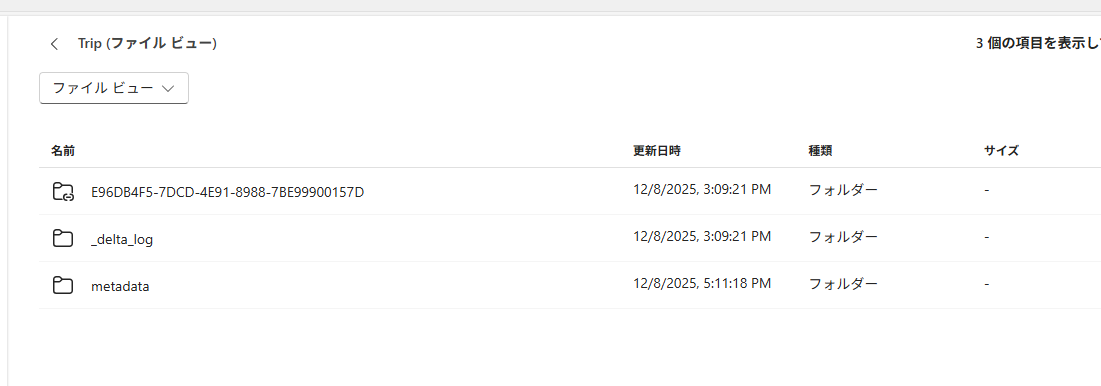
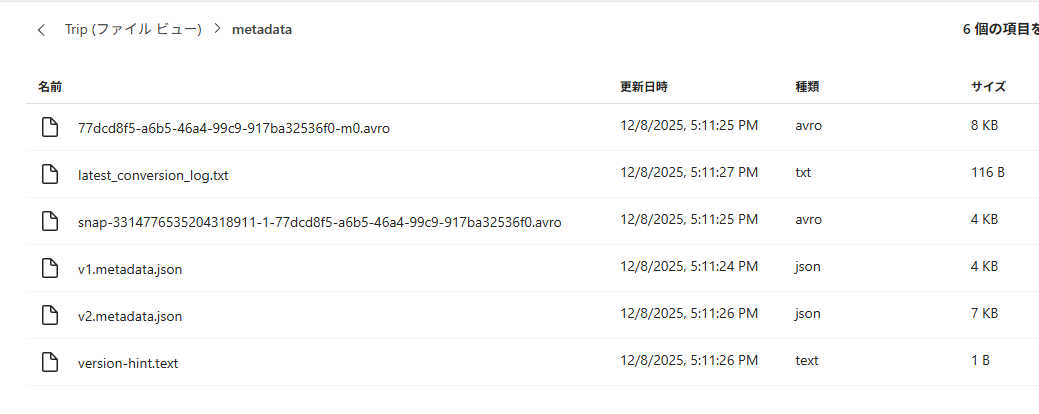
-
同様にBigQuery ミラーリングへのショートカットを作成します。
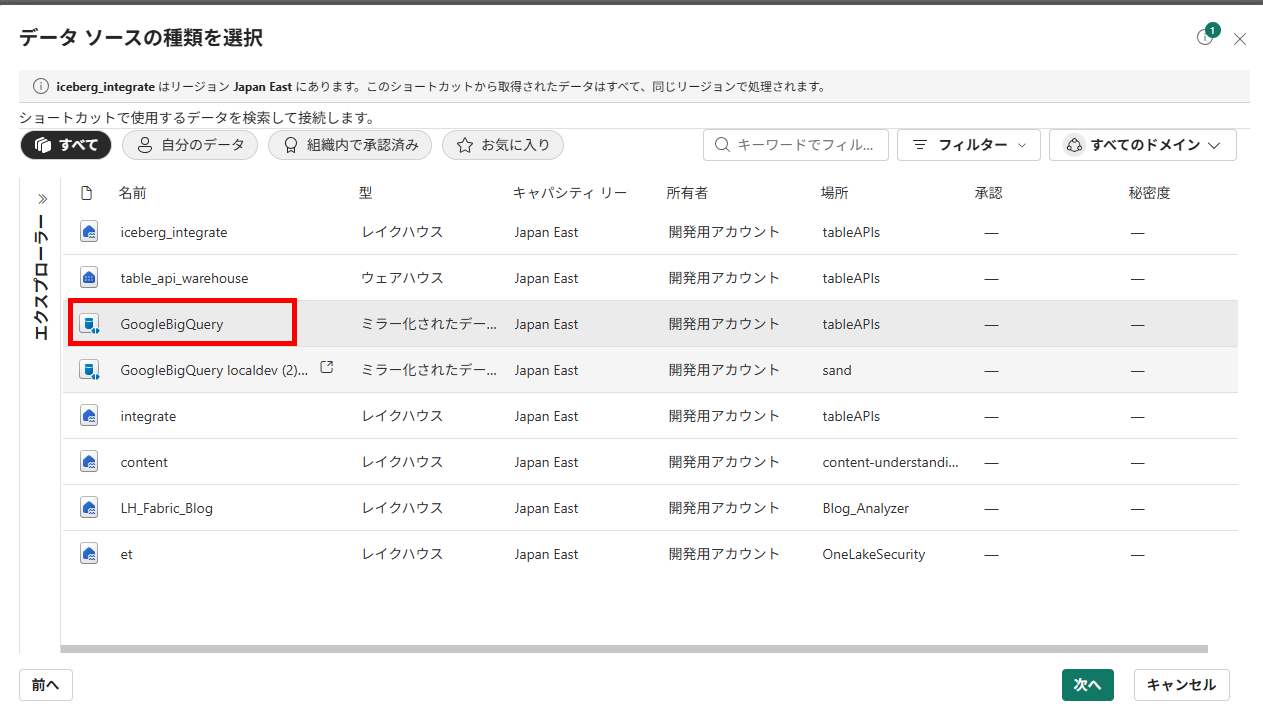
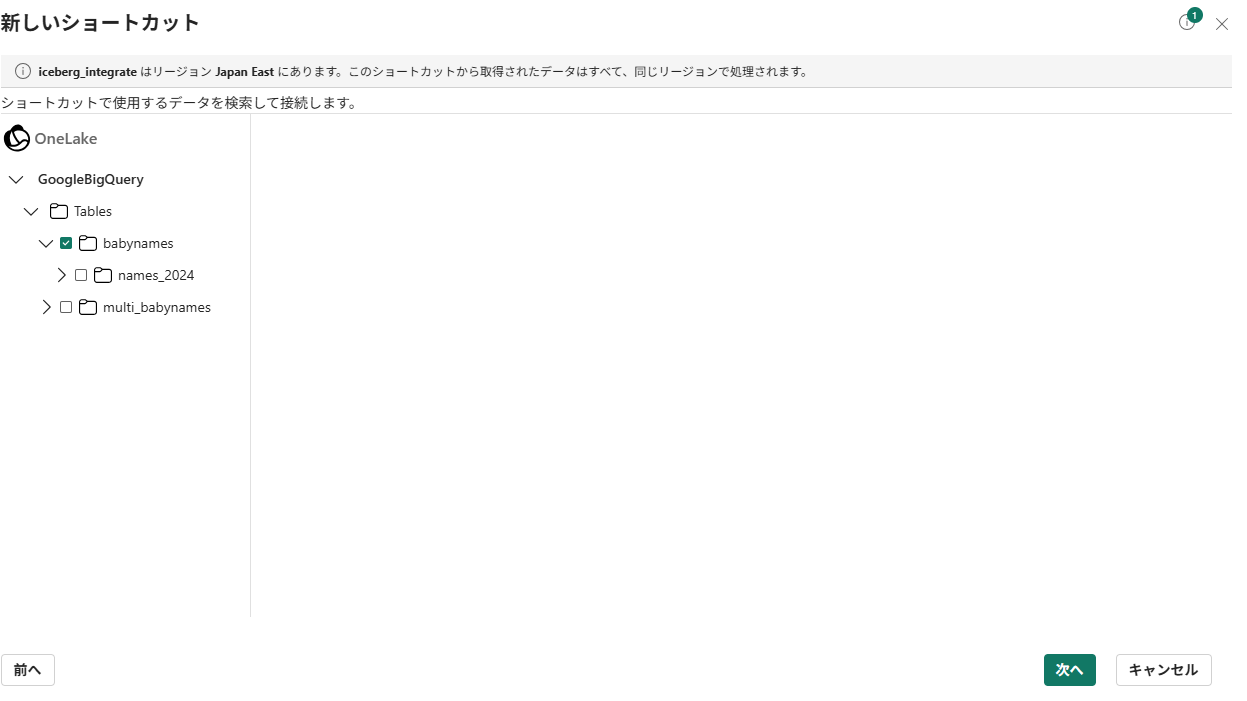
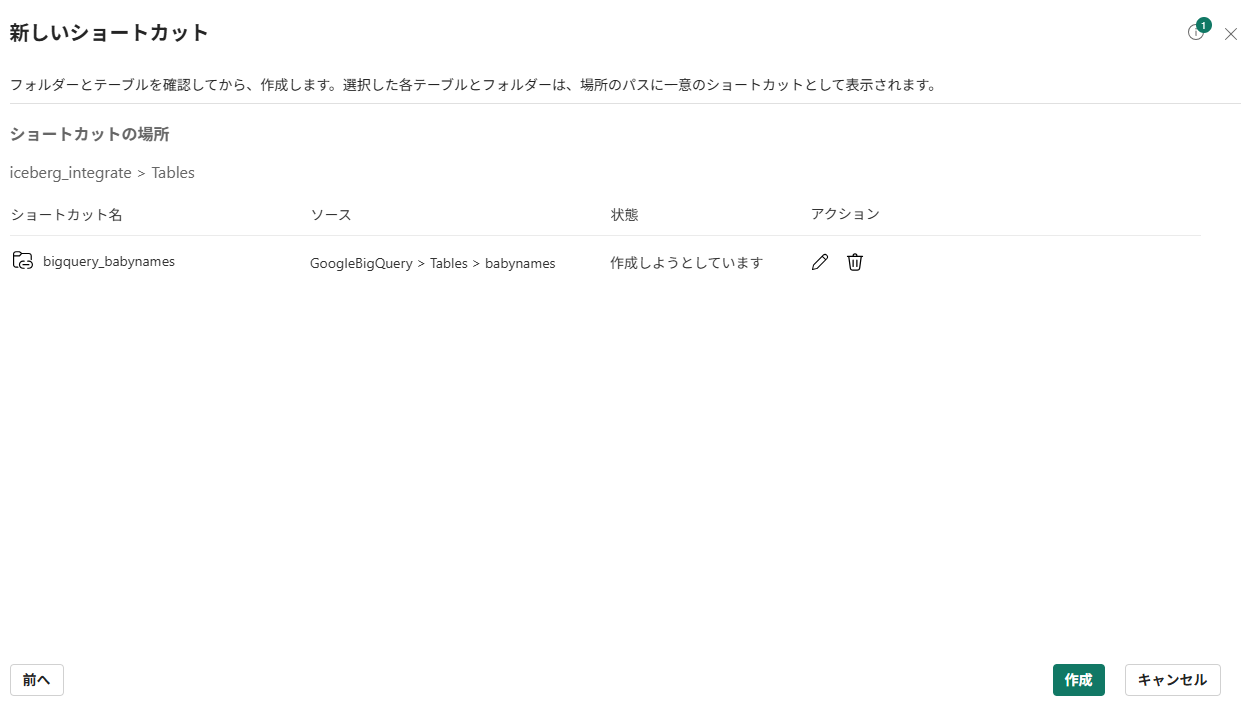
-
データを確認します。

-
Iceberg メタデータが作成されていることも確認できます。


Iceberg クライアントでの読取
Iceberg の OneLake テーブル API の使い始め方 を参考にしています。
Pyiceberg での読取
-
Python ノートブックで pyiceberg をインストールします
python!pip install pyiceberg
duck DB でのクエリ
-
DuckDBをインストールします。
python!pip install --upgrade "duckdb>=1.3.0" notebookutils.session.restartPython()Fabric Python Runtimeにはあらかじめ DuckDB がインストールされていますが、1.2系のため、Iceberg REST カタログに対応したバージョンにアップグレードします。
-
lakehouse の ID と workspace の ID を設定します。 Table API は それらの ID に基づいて構成されます。
pythonfabric_workspace_id = "<groups/<id> となっているURLから確認し、取得>" fabric_data_item_id = "<lakehouses/<id> となっているURLから確認し、取得>" -
Catalog をアタッチします。
pythonimport duckdb from azure.identity import DefaultAzureCredential # Iceberg API base URL at the OneLake table API endpoint table_api_url = "https://onelake.table.fabric.microsoft.com/iceberg" # Entra ID token token = notebookutils.credentials.getToken("storage") # Client configuration options warehouse = f"{fabric_workspace_id}/{fabric_data_item_id}" # Connect to DuckDB con = duckdb.connect() # Install & load extensions con.execute("INSTALL iceberg; LOAD iceberg;") con.execute("INSTALL azure; LOAD azure;") con.execute("INSTALL httpfs; LOAD httpfs;") con.execute("UPDATE EXTENSIONS;") # --- Auth & Catalog --- # 1) Secret for the Iceberg REST Catalog (use existing bearer token) con.execute(f""" CREATE OR REPLACE SECRET onelake_catalog ( TYPE ICEBERG, TOKEN '{token}' ); """) # 2) Secret for ADLS Gen2 / OneLake filesystem access via Azure extension # (access token audience must be https://storage.azure.com; account name is 'onelake') con.execute(f""" CREATE OR REPLACE SECRET onelake_storage ( TYPE AZURE, PROVIDER ACCESS_TOKEN, ACCESS_TOKEN '{token}', ACCOUNT_NAME 'onelake' ); """) # 3) Attach the Iceberg REST catalog con.execute(f""" ATTACH '{warehouse}' AS onelake ( TYPE ICEBERG, SECRET onelake_catalog, ENDPOINT '{table_api_url}' ); """) # --- Explore & Query --- display(con.execute("SHOW ALL TABLES").fetchdf())
-
warehouse からショートカットしたテーブルをクエリします。
pythondf = con.execute(f""" SELECT * FROM onelake.warehouse_dbo.Trip LIMIT 10 ; """).fetchdf() display(df)
-
BigQuery ミラーリングからショートカットしたテーブルをクエリします。
pythondf = con.execute(f""" SELECT * FROM onelake.bigquery_babynames.names_2024 LIMIT 10 ; """).fetchdf() display(df)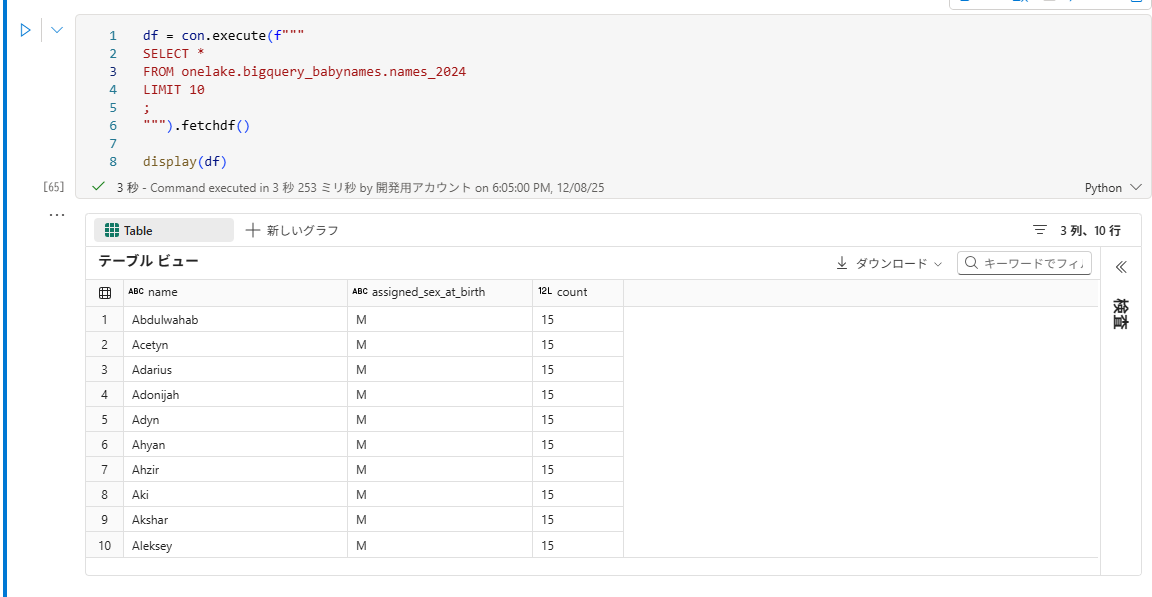
以上、参考になれば幸いです。