前回Kagglerになってみたが、それだとしっくりこなかったり、ほかのモデルを試してみてなかったりしたので
以下を参考にいろいろと試行錯誤してみた。
[Kaggle]0から本当に機械学習を理解するために学ぶべきこと~一流のデータサイエンティストを例に~
[part2]0から本当に機械学習を理解するために学ぶべきこと~一流のデータサイエンティストを例に~
[part3]0から本当に機械学習を理解するために学ぶべきこと~0からscikit-learnを使いこなす~
といっても、なんとなく思考をトレースしただけなので項目の追加などは特にせずに
今後使いまわしやすそうなコード構成に修正したぐらいだが。
全体的にやらないといけないことの流れはなんとなくわかった気がするので、次回別のデータセットで試してみるのもいいかもしれない。
で、いろいろなモデルをまとめて試してみた結果が以下。

こんな感じになったモデルから一番精度がよさそうなものをピックアップし、生成した予測データをアップロードしてみる。
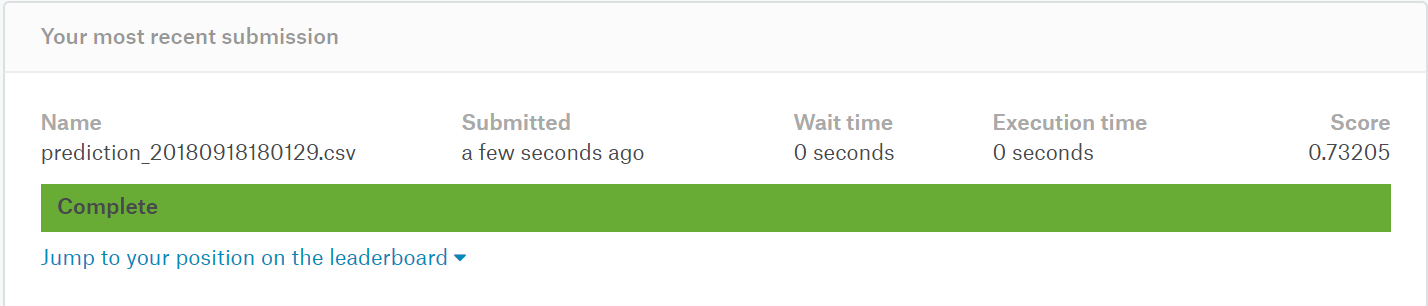
こんな感じ。

もうちょっと上がるのかと思ったけど、そうでもなかった。
これが訓練データに過剰適合してしまったということなのか?
ちなみに修正後のソースはこんな感じ
何かを修正するとしたら、評価の部分だと思う。
交差検証にしたい。
あとは各モデルのパラメータとかもあるんだろうなと思うし、特徴量についてもある程度はチューニングできるようにしたい。
# -*- coding: utf-8 -*-
# ---------------------------------------------------------------------------
# Python3
import pprint
import datetime
import pandas as pd
import numpy as np
# machine learning
from sklearn.linear_model import LogisticRegression
from sklearn.svm import SVC, LinearSVC
from sklearn.ensemble import RandomForestClassifier
from sklearn.neighbors import KNeighborsClassifier
from sklearn.naive_bayes import GaussianNB
from sklearn.linear_model import Perceptron
from sklearn.linear_model import SGDClassifier
from sklearn.tree import DecisionTreeClassifier
csv_train = r'C:\PJ\20180917_kaggle\kaggle_titanic\files\train.csv'
csv_test = r'C:\PJ\20180917_kaggle\kaggle_titanic\files\test.csv'
def read_dataset(df):
# サイズ
print("= size =")
pprint.pprint(df.shape)
# 統計量
print("= describe =")
pprint.pprint(df.describe())
# 欠損データ
print("= 欠損データ =")
pprint.pprint(kesson_table(df))
# 先頭データ
print("= head =")
pprint.pprint(df.head(10))
def read_datasets(df_train, df_test):
print("---> train ---")
read_dataset(df_train)
print("---> test ---")
read_dataset(df_test)
print("------------------------")
def kesson_table(df):
null_val = df.isnull().sum()
percent = 100 * df.isnull().sum()/len(df)
kesson_table = pd.concat([null_val, percent], axis=1)
kesson_table_ren_columns = kesson_table.rename(
columns = {0 : '欠損数', 1 : '%'})
return kesson_table_ren_columns
def distribution(df, column_name):
#平均・標準偏差・null数を取得する
Age_average = df[column_name].mean() #平均値
Age_std = df[column_name].std() #標準偏差
Age_nullcount = df[column_name].isnull().sum() #null値の数=補完する数
# 正規分布に従うとし、標準偏差の範囲内でランダムに数字を作る
rand = np.random.randint(Age_average - Age_std, Age_average + Age_std , size = Age_nullcount)
#Ageの欠損値
df[column_name][np.isnan(df[column_name])] = rand
pass
def pre_processing(df):
# 欠損値の補完
## 中央値を設定:median()で中央値が取得できる
df["Age"] = df["Age"].fillna(df["Age"].median())
# distribution(df, "Age")
## 最頻値を設定:pandas.Seriesに対してmode()で最頻値のSeriesが取得できるのでそれの先頭を使用
df["Embarked"] = df["Embarked"].fillna(df["Embarked"].mode()[0])
# distribution(df, "Embarked")
## 最頻値を設定
df["Fare"] = df["Fare"].fillna(df["Fare"].mode()[0])
# distribution(df, "Fare")
# 文字列→数字化
df['Sex'] = df['Sex'].map({ 'male':0, 'female':1})
df['Embarked'] = df['Embarked'].map({ 'S':0, 'C':1, 'Q':1})
# df['Sex'] = df['Sex'].map({ 'male':1, 'female':0})
# df['Embarked'] = df['Embarked'].map({ 'S':1, 'C':2, 'Q':0})
def output_file(prediction, df_test, filename):
# PassengerIdを取得
PassengerId = np.array(df_test["PassengerId"]).astype(int)
# prediction(予測データ)とPassengerIdをデータフレームへ落とし込む
df_solution_tree = pd.DataFrame(prediction, PassengerId, columns = ["Survived"])
# csvファイルとして書き出し
df_solution_tree.to_csv(filename, index_label = ["PassengerId"])
pass
def get_data():
# ファイル読み込み
df_train = pd.read_csv(csv_train)
df_test = pd.read_csv(csv_test)
# データの確認
# read_datasets(df_train, df_test)
return df_train, df_test
def evaluation(model, features, target):
"""
とりあえず結果を評価してみる
"""
evaluation_score = round(model.score(features , target) * 100, 2)
print(" -- evaluation : {}".format(evaluation_score))
return evaluation_score
def create_model_DecisionTree(predictor_var, response_var):
# 決定木の作成とアーギュメントの設定
max_depth = 10
min_samples_split = 5
# model_DecisionTree = tree.DecisionTreeClassifier(max_depth = max_depth, min_samples_split = min_samples_split, random_state = 1)
model_DecisionTree = DecisionTreeClassifier(max_depth = max_depth, min_samples_split = min_samples_split, random_state = 1)
model_DecisionTree = model_DecisionTree.fit(predictor_var, response_var)
return model_DecisionTree
def create_model_LogisticRegression(predictor_var, response_var):
# ロジスティック回帰
model_LogisticRegression = LogisticRegression()
model_LogisticRegression.fit(predictor_var, response_var)
# Y_pred = logreg.predict(X_test)
return model_LogisticRegression
def create_model_SVM(predictor_var, response_var):
# Support Vector Machines
model_SVC = SVC()
model_SVC.fit(predictor_var, response_var)
return model_SVC
def create_model_KNeighbors(predictor_var, response_var):
# k近傍法(KNN)
model_KNeighbors = KNeighborsClassifier()
model_KNeighbors.fit(predictor_var, response_var)
return model_KNeighbors
def create_model_GaussianNB(predictor_var, response_var):
# 単純ベイズ分類器またはナイーブベイズ分類器
model_GaussianNB = GaussianNB()
model_GaussianNB.fit(predictor_var, response_var)
return model_GaussianNB
def create_model_Perceptron(predictor_var, response_var):
# パーセプトロン
model_Perceptron = Perceptron()
model_Perceptron.fit(predictor_var, response_var)
return model_Perceptron
def create_model_RandomForest(predictor_var, response_var):
# Random Forest
model_RandomForest = RandomForestClassifier(n_estimators=100)
model_RandomForest.fit(predictor_var, response_var)
return model_RandomForest
if __name__ == '__main__':
print("start")
# データ取得
df_train, df_test = get_data()
# 前処理:pre_processing
# pd.options.mode.chained_assignment = None
for df in [df_train, df_test]:
pre_processing(df)
# pd.options.mode.chained_assignment = 'warn'
# 変換後データの確認
# read_datasets(df_train, df_test)
# 特徴量の対象とする項目を決定
lst_params = ["Pclass", "Sex", "Age", "SibSp", "Parch", "Fare", "Embarked"]
# lst_params = ["Pclass", "Sex", "Age", "Fare"]
# 目的変数の値を取得
response_var = df_train["Survived"].values
# 説明変数の値を取得:追加となった項目も含めて予測モデルで使う値を抽出
predictor_var = df_train[lst_params].values
# テストからも説明変数の値を取得:実際の予測に使用するデータ
test_predictor_var = df_test[lst_params].values
# それぞれの結果格納用のDataFrameを用意する
model_index = ["model_name","score","model"]
df_models = pd.DataFrame(index=[], columns=model_index)
# 確認するモデルリストを作成
model_list = [ "DecisionTree",
"LogisticRegression",
"Support Vector Machines",
"k近傍法(KNN)",
"Gaussian Naive Bayes",
"Perceptron","Random Forest"
]
for index, name in enumerate(model_list):
print(index, name)
model = None
# print(index)
if(name == "DecisionTree"):
# 決定木
model = create_model_DecisionTree(predictor_var, response_var)
elif(name == "LogisticRegression"):
# ロジスティック回帰
model = create_model_LogisticRegression(predictor_var, response_var)
elif(name == "Support Vector Machines"):
# Support Vector Machines
model = create_model_SVM(predictor_var, response_var)
elif(name == "k近傍法(KNN)"):
# k近傍法(KNN)
model = create_model_KNeighbors(predictor_var, response_var)
elif(name == "Gaussian Naive Bayes"):
# 単純ベイズ分類器またはナイーブベイズ分類器(Gaussian Naive Bayes)
model = create_model_GaussianNB(predictor_var, response_var)
elif(name == "Perceptron"):
# パーセプトロン
model = create_model_Perceptron(predictor_var, response_var)
elif(name == "Random Forest"):
model = create_model_RandomForest(predictor_var, response_var)
else:
print("Don't Exist Model")
continue
evaluation_score = evaluation(model, predictor_var, response_var)
df_models = df_models.append(pd.Series([name, evaluation_score, model], index=model_index),ignore_index=True)
# scoreでソート
df_sorted_models = df_models.sort_values(by='score', ascending=False)
pprint.pprint(df_sorted_models)
# 一番精度が高そうなモデルを使って、テストデータに対して予測
model = df_sorted_models.iloc[0]["model"]
prediction = model.predict(test_predictor_var)
# 予測結果をファイルに出力
output_file(prediction ,df_test , "prediction_{0:%Y%m%d%H%M%S}.csv".format(datetime.datetime.now()))
print("end")
githubの方も更新しておく。
https://github.com/RyoNakamae/kaggle_titanic
※これ、更新しちゃうと前回の記事の意味がわからなくなるな・・・