先日、とあるAI系の勉強会?説明会?でいくつか話を聞いてきたのだが、その中の一つとしてkaggleなるものを知った。
で、面白そうだったので早速試してみることにした。
※ゼロから作るDeep Learningあたりを読み途中だったので読み切ってからのほうがいいかなとも思ったが、やる気になったときに初めてみるのがいいかなと思ったのと、わからなかったら本に戻ってくればいいかなと。
kaggleって何?
kaggleって何というのはこの辺を参照してみてください。
https://www.codexa.net/what-is-kaggle/
データサイエンス版のgit hubみたいなものというのが感覚的には一番わかりやすいかも。
カグってみる
何はなくともまずはアカウント作成

- どれでも大差ないとは思うが、Facebookのアカウントを使ってサインアップすることにする。

- IDを何にする?と聞かれる。
どうやらこのIDを使ってマイページっぽいものを作りそうなのでgit hubのアカウントと一緒にしておく。
規約っぽいものを聞かれるのでハイハイとOK
 で、これだけでNoviceがいっちょ出来上がりである
で、これだけでNoviceがいっちょ出来上がりである
- 認証もすませておく
SMS verify your accountをクリックして電話番号を入れる
国番号入りなので先頭に[+81]をつける
一つ試してみる
アカウントを作っておしまいというのもつまらないので一つ何かを試してみることにする。
どうやらTitanic : Machine Learning from Disasterが一般的なチュートリアルらしいのでそれをやってみることにする
※ここから先は以下のサイトを参照しながら進めていく。
https://www.codexa.net/kaggle-titanic-beginner/
データのDLとデータ内容の把握
- データをDLする

とりあえず全部DL。
Rules acceptanceへ飛ばされるのでOKして改めてDL
で、Data Descriptionに目を通しつつ、DLしたファイルの中身を見てみる。
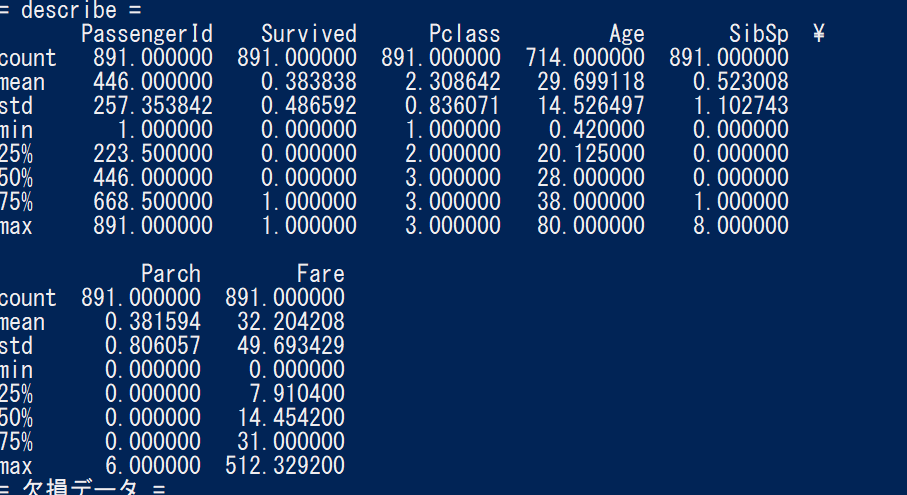
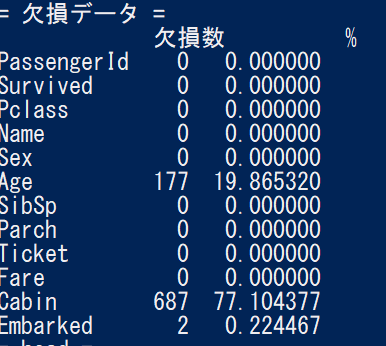
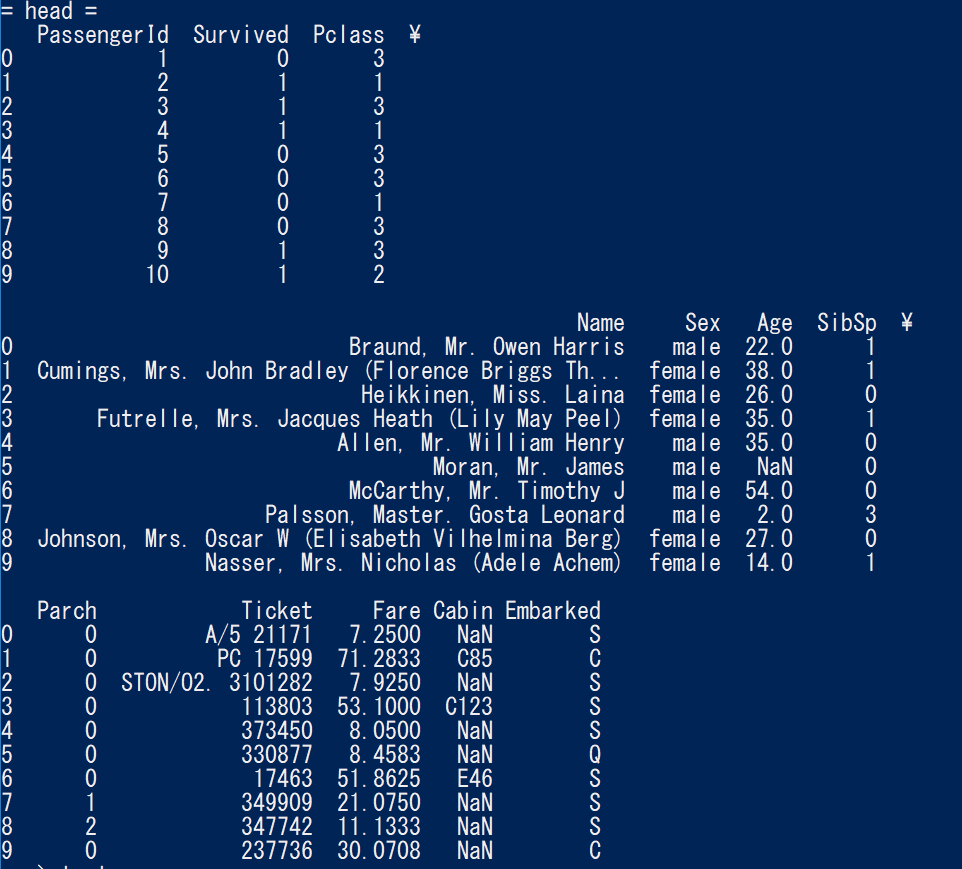
describeで表示される内容については以下を参照
https://pandas.pydata.org/pandas-docs/stable/generated/pandas.DataFrame.describe.html
ざっと記載するとこんな感じ。
件数(count)、平均値 (mean)、標準偏差 (std)、最小値(min)、第一四分位数 (25%)、中央値 (50%)、第三四分位数 (75%)、最大値 (max)
事前処理
・欠損データを補う
今回はAgeとEmbarkedの欠損を補うことにする模様。Cabinは使わない。
何で補うかはとりあえずなので適当でいいらしい。
# 欠損値の補完
## 中央値を設定:median()で中央値が取得できる
df_train["Age"] = df_train["Age"].fillna(df_train["Age"].median())
## 最頻値を設定:pandas.Seriesに対してmode()で最頻値のSeriesが取得できるのでそれの先頭を使用
df_train["Embarked"] = df_train["Embarked"].fillna(df_train["Embarked"].mode()[0])
元サイトからはちょっとだけ変えた。
最頻値を探すのがめんどくさかったのでDataFrameの機能をそのまま使った。
・文字列を数字にする
train["Sex"][train["Sex"] == "male"] = 0
train["Sex"][train["Sex"] == "female"] = 1
train["Embarked"][train["Embarked"] == "S" ] = 0
train["Embarked"][train["Embarked"] == "C" ] = 1
train["Embarked"][train["Embarked"] == "Q"] = 2
事前処理を関数化してそっちで変換(挿入)してたら警告が出た
A value is trying to be set on a copy of a slice from a DataFrame
とりあえず以下のオプションをNoneにしておけば表示はされなくなる。
pd.options.mode.chained_assignment = None
http://pandas.pydata.org/pandas-docs/stable/indexing.html#indexing-view-versus-copy
出てた警告を出さなくしているだけなので、解決策としてあっているのかどうかは全く自信がない。
妥協案として、ここの処理の間だけは明示的にこの警告がでなくていいとするのであれば、こんな感じになるのかなと思う。
# pre_processing
pd.options.mode.chained_assignment = None
pre_processing(df_train)
pre_processing(df_test)
pd.options.mode.chained_assignment = 'warn'
予測してみる
とりあえず書いてある通りにやってみる。
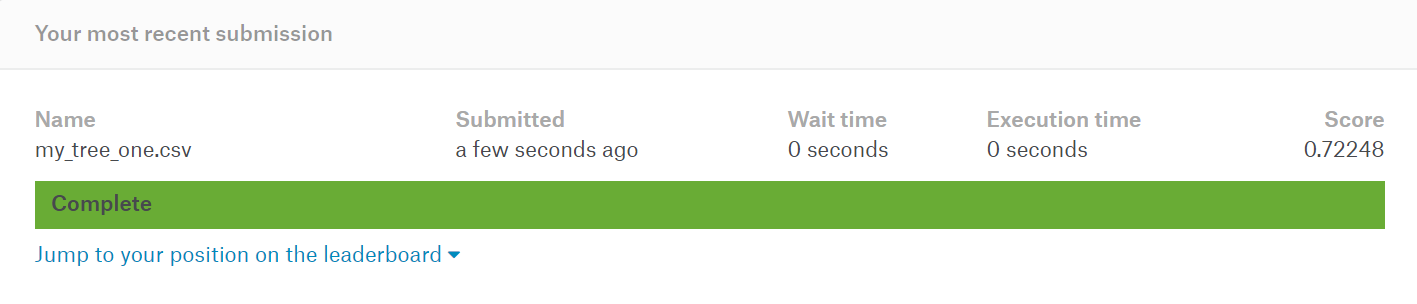
こんな感じの結果になる。
これはすごい。というか意味が分からないうちに分析できるのは大丈夫なんだろうか?
自分が「何かを理解して分析させた」という感覚がまるでない。
scikit-learnの各処理の意味を理解しないといけなさそうな感じかな。
※追記
違和感がわかった。
自分が「何を作った」のかがよくわからないからだ。
「モデル」を作らないといけない気がするのだが、できあがったのは「予測結果」なんだよな。
「モデル」
この辺がまだしっくりこない。
人のを見てみる
https://www.kaggle.com/percydiego/titanic-predictions
単純にソースの書き方が参考になる。
chained_assignmentの警告が出てたところはこんな感じで記載するとそもそもすっきりする。
df['Sex'] = df['Sex'].map({ 'male':0, 'female':1})
df['Embarked'] = df['Embarked'].map({ 'S':0, 'C':1, 'Q':1})
もう少し条件を付ける場合はこんな感じか
df['Fare_Cat']=0
df.loc[df['Fare']<=7.01,'Fare_Cat']=1
df.loc[(df['Fare']>7.01) & (df['Fare']<=7.88),'Fare_Cat']=2
df.loc[(df['Fare']>7.88) & (df['Fare']<=69.4),'Fare_Cat']=3
df.loc[(df['Fare']>69.4) & (df['Fare']<=77),'Fare_Cat']=4
df.loc[df['Fare']>77,'Fare_Cat']=5
処理的にはヒートマップが出てくる以降はなんのために何をしているのかがさっぱりわからない。
いずれ理解できる日が来るのだろうか。
自分で作ったのをいろいろ弄ってみる
- 文字列→数字の値を変えてみる
上記でこんな感じにしたものを
df['Sex'] = df['Sex'].map({ 'male':0, 'female':1})
df['Embarked'] = df['Embarked'].map({ 'S':0, 'C':1, 'Q':2})
値の順番を変えてみる
df['Sex'] = df['Sex'].map({ 'male':1, 'female':0})
df['Embarked'] = df['Embarked'].map({ 'S':1, 'C':2, 'Q':0})
単純に考えるとこれで予測結果が変わるとは思えないのだが、Survivedの値はそれなりに変更されている。
文字列→数字の値を代えただけで生死予測が変わるというのがすごい不思議。
-
欠損値を変えてみる
欠損値を適当に中央値や最頻値にしているのでここをもう少し変更すると精度が高い予測?になるような気もするので
実際のデータの分布に合わせてもう少しばらけさせてみることにする。def distribution(df, column_name):
#平均・標準偏差・null数を取得する
Age_average = df[column_name].mean() #平均値
Age_std = df[column_name].std() #標準偏差
Age_nullcount = df[column_name].isnull().sum() #null値の数=補完する数# 正規分布に従うとし、標準偏差の範囲内でランダムに数字を作る rand = np.random.randint(Age_average - Age_std, Age_average + Age_std , size = Age_nullcount) #Ageの欠損値 df[column_name][np.isnan(df[column_name])] = rand
参考
https://qiita.com/taka000826/items/e859622583dc2ab78fea
なんか「それっぽい値」をぶち込むようになった気もするのだが、randintを使っているせいでデータ/予測結果が毎回変わる。
果たしてこれは「予測処理」として正しいのだろうか?
そういう意味でここの処理については「単純な中央値」に戻してみる。
- モデルに設定する項目の順番を変えて見る
lst_params = ["Pclass", "Age", "Sex", "Fare", "SibSp", "Parch", "Embarked"]
↑を↓にしてみる
lst_params = ["Pclass", "Sex", "Age", "SibSp", "Parch", "Fare", "Embarked"]
→さすがにこれで結果が変わるということはない模様。
- [Age]だけではなく[Fare]も含めて全部「標準偏差範囲内のランダム値」になるようにしてみる。
→パラメータを変えるとPassengerId:913の人が死んだり生き返ったりするのが「概念として」ちょっと面白い。この人、死んだり生き返ったりしてるなーと。。
なんとなく遊んで満足したので今回はこれでおしまいにする。
せっかくなのでgithubにもあげておく。
https://github.com/RyoNakamae/kaggle_titanic
今後
-
scikit-learnを知ったほうがよさそう。
https://dev.classmethod.jp/machine-learning/introduction-scikit-learn/ -
違うデータセットで遊んでみる
犬猫ってのがあるみたい
https://www.kaggle.com/c/dogs-vs-cats
※画像での分類もやってみたいというのもある。