備忘録です
機械学習による予測をするためには欠損値を取り扱う必要がある。
■欠損値を調べる
単純な調べ方
isnull() と sum() を組み合わせて調べる。
train_df.isnull().sum()
------------------
PassengerId 0
Survived 0
Pclass 0
Name 0
Sex 0
Age 177
SibSp 0
Parch 0
Ticket 0
Fare 0
Cabin 687
Embarked 2
person 0
deck 687
family 0
dtype: int64
欠損値の割合・値のバリエーションを調べる
それぞれのカラム毎にどのくらいのnullが存在し、また値のバリエーションを調べてみる。
def null調べ(df):
for i in df.columns:
print("■■■ " + i )
print("NULL数:" + str(df[i].isnull().sum() )+
" NULL率:" + str((df[i].isnull().sum()/len(df)).round(3)) +
" データの種類数:" + str(df[i].value_counts().count()))
null調べ(train_df)
----------------------
■■■ PassengerId
NULL数:0 NULL率:0.0 データの種類数:891
■■■ Survived
NULL数:0 NULL率:0.0 データの種類数:2
■■■ Pclass
NULL数:0 NULL率:0.0 データの種類数:3
■■■ Name
NULL数:0 NULL率:0.0 データの種類数:891
■■■ Sex
NULL数:0 NULL率:0.0 データの種類数:2
■■■ Age
NULL数:177 NULL率:0.199 データの種類数:88
■■■ SibSp
NULL数:0 NULL率:0.0 データの種類数:7
■■■ Parch
NULL数:0 NULL率:0.0 データの種類数:7
■■■ Ticket
NULL数:0 NULL率:0.0 データの種類数:681
■■■ Fare
NULL数:0 NULL率:0.0 データの種類数:248
■■■ Cabin
NULL数:687 NULL率:0.771 データの種類数:147
■■■ Embarked
NULL数:2 NULL率:0.002 データの種類数:3
これらで、null率が高いものを調べる
■欠損値の扱い
欠損値がどのような理由で生まれているかによって、アプローチが異なる
欠損に意味がないパターン
MCAR(Missing completely) : ランダムな欠損
欠損が意味があるパターン
MAR(Missing at random) : データの他の特徴量に依存して欠損
MNAR(Missing not at random) : 欠損となった値自体に依存して欠損
くわしくは機械学習のための欠損値処理まとめが参考になる
1 欠損値を単純に処理する(削除する、一意の値を入れる)
データ量が十分に確保できる場合は単純に削除でよい
data.dropna() #nullが含まれる行を削除する
train_df.fillna(0) #nullに0をいれる
2 欠損値に値を補完する
データ量が少ない場合は単純に削除すると、データ量が減ってしまい、データがムダになる・妥当性にムラがでる。
そこで、削除するのではなく、なにかしらデータを補完する必要がでてくる。
それぞれデータを眺めたあと、どのような形で補完するかを決定するのがよい。
単純に平均値/最頻値を入れる
単純に平均値/最頻値をいれてしまう方法
train_df["Age"] = train_df["Age"].fillna(train_df["Age"].mean())
plt.hist(train_df_original["Age"].dropna(), alpha=0.2,color="r") #もともとのグラフを赤で描画
plt.hist(train_df["Age"],alpha=0.2,color="b") #平均値をいれたグラフを青で描画
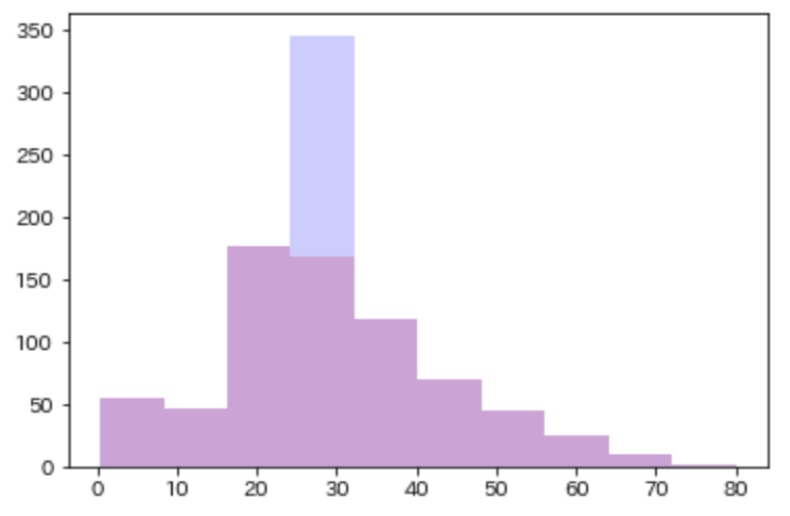
平均からばらつきを考慮して補完する
平均値から標準偏差でばらつきを考慮して補完する
# 平均・標準偏差・null数を取得する
Age_average = train_df["Age"].mean() #平均値
Age_std = train_df["Age"].std() #標準偏差
Age_nullcount = train_df["Age"].isnull().sum() #null値の数=補完する数
# 正規分布に従うとし、標準偏差の範囲内でランダムに数字を作る
rand = np.random.randint(Age_average - Age_std, Age_average + Age_std , size = Age_nullcount)
# Ageの欠損値
train_df["Age"][np.isnan(train_df["Age"])] = rand
# グラフ描画
plt.hist(train_df_original["Age"].dropna(), alpha=0.2,color="r")
plt.hist(train_df["Age"],alpha=0.2,color="b")
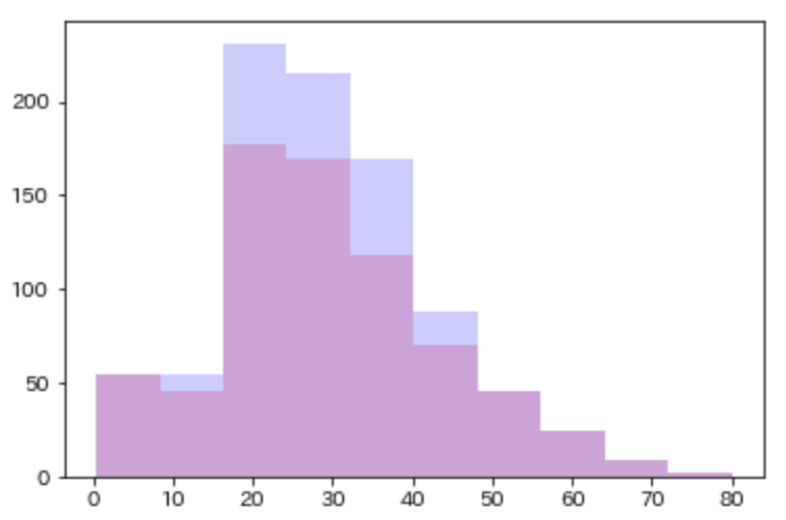
k近傍法
(のちに勉強する)
3 欠損値という値として扱う
参考:
Python pandas 欠損値/外れ値/離散化の処理
機械学習のための欠損値処理まとめ
欠損値を含むデータをどう解析するか?
外れ値や欠損値のあるデータの解析
kaggle kernel "A Journey through Titanic"