FXシストレ論文 「Learning to Trade via Direct Reinforcement」
http://dustwell.com/PastWork/MoodyRLTradingPresentation.pdf
http://people.idsia.ch/~juergen/rnnaissance2003talks/MoodySaffellTNN01.pdf
が、シミュレーション結果を見る限り爆勝ちしているので、この実装を再現させようとしているが、うまくいかない(同じような性能が得られない)。
要は価格の予測に応じてトレードするんじゃなくて、トレードしたら勝てるかどうか自体を直接予測すれば良いという内容だと思っているのだけど、その考えに従って、
のプログラムを修正したり、やはり時系列のレートデータ(なり、時系列での差分データ)を入力すれば良いのか、と思い、TensorFlowでRNN/LSTMを使って試したりしたがうまくいかず。
で、一層のNN (のはず) で、時系列データを入力する方法を試したら多少うまくいった。
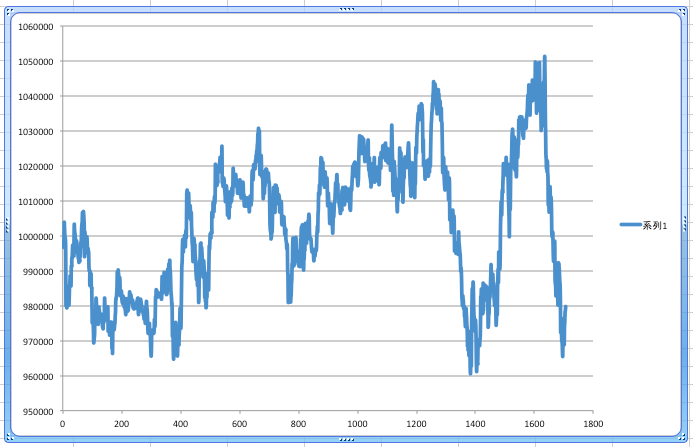
予測結果が五分五分だとすると、スプレッド手数料の分で、単調減少になるのだけど、そうなっていないということはいくらかは予測が当たっているものと思われる。多分。
1層のNN (のはず) に 5分足を12本入れて、スプレッド含めて取引したら勝てるかどうかを予測して、その結果に基いて単純に売買した結果。買いの予測結果が出たら買って、保有ポジションは勝てると予測したタイミング(予測を行うタイミングから固定時間)には必ず売るという単純なストラテジー。
PS:
可能性としては低いが、もしかして論文で評価が行われた期間と市場の動きが変わってしまっているとかあるのだろうか。例えば、証券会社にコンピュータを用いたトレードが普及したため、とか。
追記1:
論文を読み込んで、学習中およびトレード中に、一回前に出したシグナルの種別を、入力に加えないといけないことは分かった(その意味でこの論文は強化学習と言っているのだろう)。
しかし、このプログラムでそのような対応をするのは難しいというか、不可能なような。。。
TensorFlow先生に乗り換える感じかも。。。
としても、学習時間が膨大になるような。。。
という感じだが、同じ回帰なら似たような挙動になるだろうということで、NNではなくXgboostで書いてみた(KerasによるNNだと学習に時間がかかりそうだったので)。精度が出るかは不明。
https://github.com/ryogrid/fx_systrade/blob/4d644a05f4ffe5fa4aad466c51105bb559c22edf/xgboost_direct_rl_trade.py
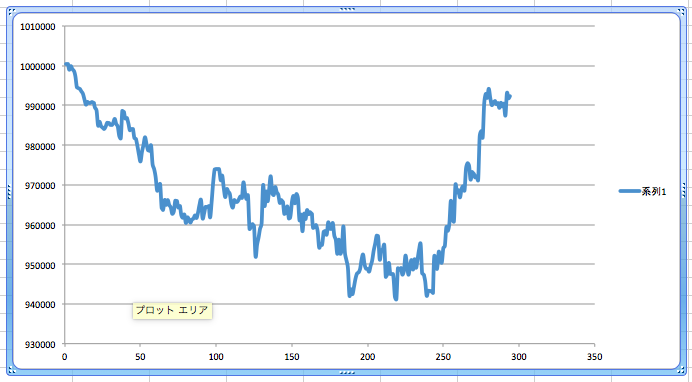
結果。
下落幅が小さくなっている分、改善したように思われる。
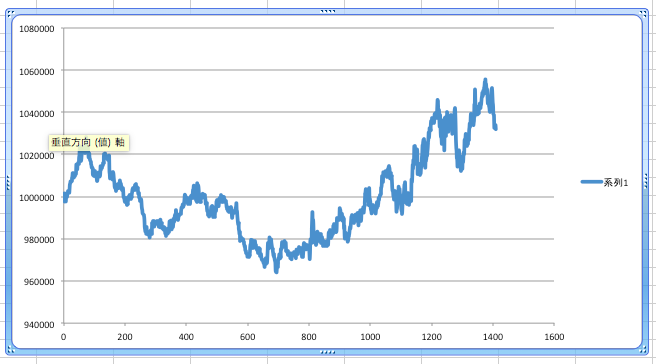
追記2:
追記1では、1時刻前の出力(予測結果)を入力に与えるという方法で精度が上がったようだったので、従来のテクニカル指標を入力して、ポジションの買いと解消も独自ストラテジーでするプログラムに、同様の仕組みを入れてみた。現在学習中。
https://github.com/ryogrid/fx_systrade/blob/cc65692fae0da92af793c72d2287c8659b18c381/xgboost_direct_rl_trade_v2.py
結果。元本割れしなくなっただけマシだが、既存プログラムは同じ期間(約7年間)で、+40%なので、全然期待はずれ。うーん。
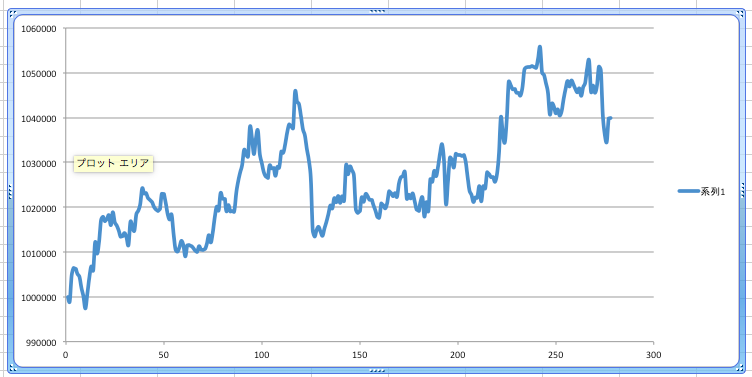
ポジションを持つかの判断をするところでpredected_probaという変数を介して予測の信頼度を見ているが、そこを90%から50%まで落としたら、もう少しパフォーマンス上がった。
(上のもそうだけど、おおむね安定して増加傾向なので、レバレッジをかければ実運用でも使えるかも?。ただ、後者はまだマシだが、一ヶ月とか数ヶ月とかトレードしない期間が発生したりしているので、もっと頻度が多くなるようなプログラムにしないと厳しいか)
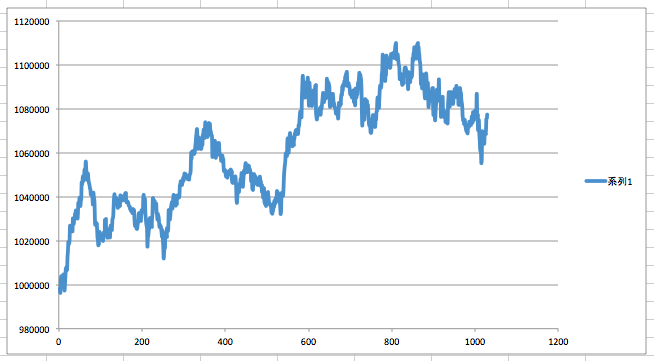
学習データ数を8倍の8000まで増やしたらさらに良さげなパフォーマンスに(なお、学習時間の増加は単純に8倍では済まない)。
この調子で増やせばパフォーマンス改善していくのだろうか(既存コードは8万なのでさらに10倍しないと。。。)。。。
でも、8000データの時点で学習時間に2日近くかかっているので、10倍で20日。実際は10倍できかないだろうから30日とか、かかるのかなあ。辛い。
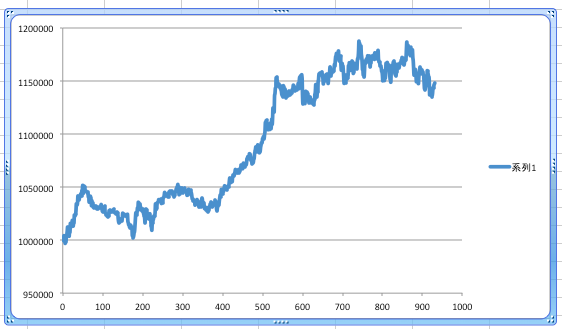
40000データ。最終イテレーションまでは、Xgboostのround数を1/3に減らしている。
とりあえず、データを増やせばいいというものではないようだ(途中のround数を減らした影響がなければ良い結果が得られた可能性もあるかもしれない)。