(記事最下部に追記あり)
どうも、オリィ研究所 の ryo_grid です。
オリィ研究所と所属をつけても、以前はどこの会社?という感じの反応が多かったように思いますが、重度身体障害者の方を含む、障害者の方がOriHime(小さいのと大きいのがいる)という分身ロボットを用いて、遠隔から就労する分身ロボットカフェというものをやってから、ああ、あの分身ロボットとかってやつをやってるところね、という程度にはご存じの方も増えてきており、うれしく思う今日このごろです。
(宣伝目的という風にとられると、規約に反しそうなので、リンクは張りません)
閑話休題。個人ブログで申し訳ないですが、以下のような記事を書いたりしたように、Keras(TensorFlowバックエンド)の並列化の実装はどうなっているのか、気になっています。
【Need Help!】Keras(TensorFlowバックエンド)でのマルチコア・マルチプロセッサ並列化、GPU並列化はどんな実装になっているのだろう? - Ryoの開発日記Neo!
GPUの場合
で、fit_generatorを利用した場合の話ではないですが、GPUについては単体GPUを使う場合においては(複数GPUだとまた別かもしれないですが)、kaggler-ja Slack で教えてもらった内容と、cuDNNのドキュメントを照らし合わせると、私がブログに書いたような実装にはなっておらず、GPUメモリに重みデータと学習データをどかっと置いてしまって、その後にcuDNNのDNN向けに用意された抽象度の高い(レイヤの種別ごとに関数が用意してあったりする)ライブラリ関数を順次コールするというような実装になっているのだろうということは分かりました(※)。
※GPUメモリにデータを置きっぱなしにできるか、cuDNNやCUDAの仕様の詳細を調べたわけではないですが、fitを一度呼び出している間は少なくとも、置きっぱなしにできるのだろう、と思います。でなければ、ライブラリコールのたびにデータを置き直すはめになるわけですが、それはあまりにも遅そうだし、ライブラリ実装としても筋が悪い。また、DNNのベンチマーク的に利用されるDNN実装のアプリケーション(ResNet)を動かす場合NNのネットワーク規模が選択できる(ResNetでは50, 101, 152が少なくとも選べるみたい)ようですが、GPUメモリの搭載量が少ないと、大きなネットワーク規模のものは実行できなかったりする(参考記事)そうで、その話ともある程度、整合するのではないかと思っています。
CPUの場合 (fit_generatorを利用)
今回の投稿のメインの話です。
で、最初に書いておきますが、fit_generatorは(こんな勘違いをするのは私ぐらいかもしれませんが、)学習処理を並列に実行してくれるものではありません。あくまで、generatorとして渡した学習データをfeedする関数をプロセス並列で実行してくれるものです。
【ドキュメントを読んだ私】
日本語版の公式ドキュメント
ジェネレータは効率化のために,モデルを並列に実行します. たとえば,これを使えば CPU 上でリアルタイムに画像データを拡大しながら,それと並行して GPU 上でモデルを学習できます.
おっ、学習処理を並列実行してくれるのかな?
use_multiprocessingとか、worker (数を指定) とかって引数あるし。
【Kerasの実装をいくら読み直しても、学習処理の並列化をしているとすると処理がおかしい、も、もしかして?、と思って英語のドキュメントを読んだ私】
翻訳前の公式ドキュメント
The generator is run in parallel to the model, for efficiency. For instance, this allows you to do real-time data augmentation on images on CPU in parallel to training your model on GPU.
やっぱり、そうやんけ・・・
ということがあったので、少なくとも翻訳が怪しい場合は原文にあたることをお勧めします。
フィードするデータの生成処理をプロセス並列で実行してくれるものだと踏まえて fit_generator の実装を読む
【前提知識】
**・**fit_generatorにおけるプロセス並列による並列化は標準ライブラリであるmultiprocessingモジュールを用いて実装されています
- multiprocessingモジュールについては理解しているものとし、基本的には説明しません
- プロセス並列およびスレッド並列での並列化に利用できるモジュールとしてはconncurrent.futuresモジュールというものもあるようですが、こちらは利用していないようです(プロセス並列による並列化のために利用した場合は、内部ではmultiprocessingモジュールを利用しているのではないかと思いますが)
- ちなみに、fit_generatorでも use_multiprocessing引数はデフォルトがFalseで、Falseの場合はPythonのスレッド実装(Pythonにおける通常のスレッド)で並列化を行うようです。I/O処理が中心である場合など、実行時にGILを手放してくれる類の関数呼び出しが、フィードするデータの生成処理(ジェネレータが行う処理)において中心的である、ということを想定しているのかもしれません
読んだソースコード
始めに、読んだコードは以下の2つがメインになります。
(**今更ですが、TensorFlowに取り込まれたtensorflow.kerasモジュールではなく、本家(?)Kerasのコードです。**ただ、コードを追っていくと、TensorFlowバックエンドの場合、内部では tensorflow.kerasモジュール以下のモジュールに含まれる関数やクラスを利用していたりして、既に TensorFlowバックエンドの場合は、tensorflow.kerasモジュールのラッパーに近い状態になっている部分も多いようです)
fit_gneratorを含むソースファイル
並列化に関する主なところと司るEnqueuereクラス(今回読んだのはOrderedEnquerer)
注: 2020年3月7日時点のmasterのHEADです
一つづつ処理を追っていくと大変なので、ざっくり書きます。
おおまかな流れを説明することが目的なので、使用したオブジェクトの後処理などについては説明しません。
【実行時の前提条件】
fit_generatorの引数において、generator引数には keras.utils.Sequenceクラスを継承したクラスのオブジェクトが指定されている。use_multiprocessing=True。workers引数は無指定でも構わないが、コア数程度の数が指定されている。
以下、ソースコードの抜粋です。
説明でポイントすることが必要な箇所には
# <-(番号)
という形でコメントを追加してあります。
- fit_generatorメソッドの並列化に関連する主な部分(at keras.engine.trainging_generator)
def fit_generator(model,
generator,
steps_per_epoch=None,
epochs=1,
verbose=1,
callbacks=None,
validation_data=None,
validation_steps=None,
validation_freq=1,
class_weight=None,
max_queue_size=10,
workers=1,
use_multiprocessing=False,
shuffle=True,
initial_epoch=0):
"""See docstring for `Model.fit_generator`."""
# --------- (略) -------------
if workers > 0:
if use_sequence_api:
enqueuer = OrderedEnqueuer(
generator,
use_multiprocessing=use_multiprocessing,
shuffle=shuffle) # <- (1)
else:
enqueuer = GeneratorEnqueuer(
generator,
use_multiprocessing=use_multiprocessing)
enqueuer.start(workers=workers, max_queue_size=max_queue_size) # <- (3)
output_generator = enqueuer.get() # <- (14)
else:
if use_sequence_api:
output_generator = iter_sequence_infinite(generator)
else:
output_generator = generator
callbacks.model.stop_training = False
# Construct epoch logs.
epoch_logs = {}
while epoch < epochs:
model.reset_metrics()
callbacks.on_epoch_begin(epoch)
steps_done = 0
batch_index = 0
while steps_done < steps_per_epoch:
generator_output = next(output_generator) # <- (16)
if not hasattr(generator_output, '__len__'):
raise ValueError('Output of generator should be '
'a tuple `(x, y, sample_weight)` '
'or `(x, y)`. Found: ' +
str(generator_output))
if len(generator_output) == 2:
x, y = generator_output
sample_weight = None
elif len(generator_output) == 3:
x, y, sample_weight = generator_output
else:
raise ValueError('Output of generator should be '
'a tuple `(x, y, sample_weight)` '
'or `(x, y)`. Found: ' +
str(generator_output))
if x is None or len(x) == 0:
# Handle data tensors support when no input given
# step-size = 1 for data tensors
batch_size = 1
elif isinstance(x, list):
batch_size = x[0].shape[0]
elif isinstance(x, dict):
batch_size = list(x.values())[0].shape[0]
else:
batch_size = x.shape[0]
# build batch logs
batch_logs = {'batch': batch_index, 'size': batch_size}
callbacks.on_batch_begin(batch_index, batch_logs)
outs = model.train_on_batch(x, y,
sample_weight=sample_weight,
class_weight=class_weight,
reset_metrics=False) # <- (17)
outs = to_list(outs)
for l, o in zip(out_labels, outs):
batch_logs[l] = o
callbacks._call_batch_hook('train', 'end', batch_index, batch_logs)
batch_index += 1
steps_done += 1
# Epoch finished.
if (steps_done >= steps_per_epoch and
do_validation and
should_run_validation(validation_freq, epoch)):
# Note that `callbacks` here is an instance of
# `keras.callbacks.CallbackList`
if val_gen:
val_outs = model.evaluate_generator(
val_enqueuer_gen,
validation_steps,
callbacks=callbacks,
workers=0)
else:
# No need for try/except because
# data has already been validated.
val_outs = model.evaluate(
val_x, val_y,
batch_size=batch_size,
sample_weight=val_sample_weights,
callbacks=callbacks,
verbose=0)
val_outs = to_list(val_outs)
# Same labels assumed.
for l, o in zip(out_labels, val_outs):
epoch_logs['val_' + l] = o
if callbacks.model.stop_training:
break
callbacks.on_epoch_end(epoch, epoch_logs)
epoch += 1
if callbacks.model.stop_training:
break
if use_sequence_api and workers == 0:
generator.on_epoch_end()
if recompute_steps_per_epoch:
if workers > 0:
enqueuer.join_end_of_epoch()
# recomute steps per epochs in case if Sequence changes it's length
steps_per_epoch = len(generator)
# update callbacks to make sure params are valid each epoch
callbacks.set_params({
'epochs': epochs,
'steps': steps_per_epoch,
'verbose': verbose,
'do_validation': do_validation,
'metrics': callback_metrics,
})
finally:
try:
if enqueuer is not None:
enqueuer.stop()
finally:
if val_enqueuer is not None:
val_enqueuer.stop()
callbacks._call_end_hook('train')
return model.history
- OrderedEnqueuerクラスと、その親クラスである SequenceEnqueuerクラス (ソースファイル上の位置とは上下を入れ替えてあります)。加えて、並列処理の実装上重要なグローバル変数とグローバル関数 (at keras.utils.data_utils)
# --------- (略) -------------
# Global variables to be shared across processes
_SHARED_SEQUENCES = {}
# We use a Value to provide unique id to different processes.
_SEQUENCE_COUNTER = None
# --------- (略) -------------
def init_pool(seqs):
global _SHARED_SEQUENCES
_SHARED_SEQUENCES = seqs
def get_index(uid, i): # <- (12)
"""Get the value from the Sequence `uid` at index `i`.
To allow multiple Sequences to be used at the same time, we use `uid` to
get a specific one. A single Sequence would cause the validation to
overwrite the training Sequence.
# Arguments
uid: int, Sequence identifier
i: index
# Returns
The value at index `i`.
"""
return _SHARED_SEQUENCES[uid][i]
class OrderedEnqueuer(SequenceEnqueuer):
"""Builds a Enqueuer from a Sequence.
Used in `fit_generator`, `evaluate_generator`, `predict_generator`.
# Arguments
sequence: A `keras.utils.data_utils.Sequence` object.
use_multiprocessing: use multiprocessing if True, otherwise threading
shuffle: whether to shuffle the data at the beginning of each epoch
"""
def __init__(self, sequence, use_multiprocessing=False, shuffle=False):
super(OrderedEnqueuer, self).__init__(sequence, use_multiprocessing)
self.shuffle = shuffle
self.end_of_epoch_signal = threading.Event()
def _get_executor_init(self, workers): # <- (10)
"""Get the Pool initializer for multiprocessing.
# Returns
Function, a Function to initialize the pool
"""
return lambda seqs: mp.Pool(workers,
initializer=init_pool,
initargs=(seqs,))
def _wait_queue(self):
"""Wait for the queue to be empty."""
while True:
time.sleep(0.1)
if self.queue.unfinished_tasks == 0 or self.stop_signal.is_set():
return
def _run(self): # <- (5)
"""Submits request to the executor and queue the `Future` objects."""
while True:
sequence = list(range(len(self.sequence)))
self._send_sequence() # Share the initial sequence # <- (6)
if self.shuffle:
random.shuffle(sequence)
with closing(self.executor_fn(_SHARED_SEQUENCES)) as executor: # <- (8)
for i in sequence:
if self.stop_signal.is_set():
return
future = executor.apply_async(get_index, (self.uid, i)) # <- (11)
future.idx = i
self.queue.put(future, block=True) # <- (13)
# Done with the current epoch, waiting for the final batches
self._wait_queue()
if self.stop_signal.is_set():
# We're done
return
# Call the internal on epoch end.
self.sequence.on_epoch_end()
# communicate on_epoch_end to the main thread
self.end_of_epoch_signal.set()
def join_end_of_epoch(self):
self.end_of_epoch_signal.wait(timeout=30)
self.end_of_epoch_signal.clear()
def get(self): # <- (15)
"""Creates a generator to extract data from the queue.
Skip the data if it is `None`.
# Yields
The next element in the queue, i.e. a tuple
`(inputs, targets)` or
`(inputs, targets, sample_weights)`.
"""
try:
while self.is_running():
try:
future = self.queue.get(block=True)
inputs = future.get(timeout=30)
except mp.TimeoutError:
idx = future.idx
warnings.warn(
'The input {} could not be retrieved.'
' It could be because a worker has died.'.format(idx),
UserWarning)
inputs = self.sequence[idx]
finally:
self.queue.task_done()
if inputs is not None:
yield inputs
except Exception:
self.stop()
six.reraise(*sys.exc_info())
class SequenceEnqueuer(object):
"""Base class to enqueue inputs.
The task of an Enqueuer is to use parallelism to speed up preprocessing.
This is done with processes or threads.
# Examples
```python
enqueuer = SequenceEnqueuer(...)
enqueuer.start()
datas = enqueuer.get()
for data in datas:
# Use the inputs; training, evaluating, predicting.
# ... stop sometime.
enqueuer.close()
```
The `enqueuer.get()` should be an infinite stream of datas.
"""
def __init__(self, sequence,
use_multiprocessing=False): # <- (2)
self.sequence = sequence
self.use_multiprocessing = use_multiprocessing
global _SEQUENCE_COUNTER
if _SEQUENCE_COUNTER is None:
try:
_SEQUENCE_COUNTER = mp.Value('i', 0)
except OSError:
# In this case the OS does not allow us to use
# multiprocessing. We resort to an int
# for enqueuer indexing.
_SEQUENCE_COUNTER = 0
if isinstance(_SEQUENCE_COUNTER, int):
self.uid = _SEQUENCE_COUNTER
_SEQUENCE_COUNTER += 1
else:
# Doing Multiprocessing.Value += x is not process-safe.
with _SEQUENCE_COUNTER.get_lock():
self.uid = _SEQUENCE_COUNTER.value
_SEQUENCE_COUNTER.value += 1
self.workers = 0
self.executor_fn = None
self.queue = None
self.run_thread = None
self.stop_signal = None
def is_running(self):
return self.stop_signal is not None and not self.stop_signal.is_set()
def start(self, workers=1, max_queue_size=10): # <- (4)
"""Start the handler's workers.
# Arguments
workers: number of worker threads
max_queue_size: queue size
(when full, workers could block on `put()`)
"""
if self.use_multiprocessing:
self.executor_fn = self._get_executor_init(workers) # <- (9)
else:
# We do not need the init since it's threads.
self.executor_fn = lambda _: ThreadPool(workers)
self.workers = workers
self.queue = queue.Queue(max_queue_size)
self.stop_signal = threading.Event()
self.run_thread = threading.Thread(target=self._run)
self.run_thread.daemon = True
self.run_thread.start()
def _send_sequence(self): # <- (7)
"""Send current Iterable to all workers."""
# For new processes that may spawn
_SHARED_SEQUENCES[self.uid] = self.sequence
def stop(self, timeout=None):
"""Stops running threads and wait for them to exit, if necessary.
Should be called by the same thread which called `start()`.
# Arguments
timeout: maximum time to wait on `thread.join()`
"""
self.stop_signal.set()
with self.queue.mutex:
self.queue.queue.clear()
self.queue.unfinished_tasks = 0
self.queue.not_full.notify()
self.run_thread.join(timeout)
_SHARED_SEQUENCES[self.uid] = None
@abstractmethod
def _run(self):
"""Submits request to the executor and queue the `Future` objects."""
raise NotImplementedError
@abstractmethod
def _get_executor_init(self, workers):
"""Get the Pool initializer for multiprocessing.
# Returns
Function, a Function to initialize the pool
"""
raise NotImplementedError
@abstractmethod
def get(self):
"""Creates a generator to extract data from the queue.
Skip the data if it is `None`.
# Returns
Generator yielding tuples `(inputs, targets)`
or `(inputs, targets, sample_weights)`.
"""
raise NotImplementedError
ソースコードの説明(誤りがあれば指摘お願いします ●刀乙)
各箇条書きの番号はコード中にコメントで入れておいたポインタに対応します。
2つのファイルで行ったり来たりする部分も多々ありますが、ご容赦ください。
-
- fit_generatorが呼び出されたのち、プロセス並列でジェネレータ(※2)の処理を行ってデータを渡してくれるOrderedEnqueuerクラスの生成処理を走らせる
-
- OrderednEqueuerのコンストラクタが呼び出され、その親クラスであるSequenceEnqueuerのコンストラクタが呼びされる
- グローバル変数である_SEQUENCE_COUNTERに multiprocessingモジュールによるプロセス並列で共有メモリを実現する multiprocessing.Value クラスのオブジェクトを生成し、設定する。この変数はプロセスごとにユニークなIDを持つためのもののようであるが、今回見ていくルートでは、マスタープロセスの uid として参照およびインクリメントするだけで、ワーカープロセスでは参照していないよう(共有メモリをアロケートしているので一応説明)
-
- OrderedEnqueuerオブジェクトの生成が終わり、fit_generatorに戻ると、OrderEnqueuerオブジェクトのstartメソッドが呼び出される
-
- startメソッド。OrderedEqueuerではなく、親クラスのSequenceEnqueuerに定義されている。各種フィールドの初期化ののち、XXXXXEnqueuerクラスが並列処理におけるマスター(今回はマスタープロセス)として動作できるように、self._runメソッドを渡してスレッドを立ち上げる(_runメソッドは子クラスで実装される)
-
- OrderedEnqueuerの_runメソッド。4) で記述したように専用のスレッドで実行されている
-
- self._send_sequenceメソッドの呼び出し
-
- _send_sequenceメソッド。グローバル変数である_SHARED_SEQUENCESに自身の uid に対応する要素に、fit_generatorが受け取ったジェネレータを設定する。これは後ほど、ワーカーに配るため
- 8)_runメソッドに戻り、multiprocessingモジュールを利用した場合によく見る形で、ワーカに処理を依頼する。が、with文の中で "self.executor_fn(_SHARED_SEQUENCES)" という謎のメソッド呼び出しがあるのでその中を追う(結局のところ、引数を受けてmultiprocessing.Poolオブジェクトを生成する関数である)
-
- あえて詳述しなかったのであるが、startメソッドの中で self.executor_fnを設定していた。self._get_executor_initメソッドへ。
-
- self._get_executor_initメソッド。Sequenceクラスのオブジェクトを引数にとり、multiprocessing.Poolクラスのオブジェクトを返す無名関数を返す。Poolクラスのコンストラクタにはinit_pool関数とその引数としてseqsを渡す形になっている。つまり、各ワーカは立ち上げられた際に、init_pool(seqs)を呼び出す。init_pool関数は_SHARED_SEQUECEにseqsを設定するものである。8) の内容と突き合わせると、各ワーカはマスタープロセスが保持していたジェネレータ(※2)を起動時に持った状態になる
-
- _runメソッドに戻る。ポイントしている箇所では、マスタープロセスから、ワーカプールにいる一つのワーカプロセスに非同期で "get_index(self.uid, i)" の実行を依頼する。返り値は非同期呼び出しのためFutureオブジェクトとなる。同期呼び出しの場合、ワーカーに実行させた関数の返り値が戻ってくることを考えると、別プロセスであっても、Futureオブジェクトに結果が格納された場合は、通信やデータ共有などを意識せずとも、マスター側でそれを取得できるものと思われる。では、get_index関数とは何するものか
-
- get_index関数。ワーカプール生成時に各ワーカがマスタから受け取った、マスタが保持していた_SHARED_SEQUENCESの内容で初期化されている_SHARED_SEQUENCESから、指定された要素を取得するだけの処理、に見えるが、ここが分かりにくいというか、工夫されているか、というところで、_SHARED_SEQUENCES[uid] は Sequenceクラスを継承したクラスのオブジェクトとなっており、インデックスアクセス(引数のiがワーカに担当させるミニバッチの箇所を指している、はず)でデータ生成の処理が走るようになっている(公式ドキュメントに実装例として挙げられているCIFAR10Sequenceクラスなどを参照のこと)。従って、ワーカプロセスはここで呼び出されるデータの生成処理を並列に行い、依頼を受けた時点ではその結果が格納されるFutureオブジェクトが返される、ということになる
-
- _runメソッドに戻る。依頼した処理結果が格納されるFutureオブジェクトを self.queueに追加しておく
-
- fit_generatorメソッドに戻る。生成し、startメソッド呼び出して、multiprocessingによるプロセス並列でのデータ生成処理を開始させた、OrderEnqueuerオブジェクトのgetメソッドを呼び出す
-
- OurderedEnqueuerのgetメソッド。メソッドの最後のあたりでyildを呼び出していることから分かるように、ジェネレータを返すメソッドである。ジェネレータが返すのはself.queueに詰めておいた各ワーカプロセスに依頼した処理に対応するFutureオブジェクトに処理完了で格納されたデータである。Futureオブジェクトをいじっているのは、future変数が現れる当たりである。ジェネレータが返すデータは、以下で説明していくが、train_on_batchメソッドに渡されているので、1ミニバッチに対応するデータなのだと思われる
-
- 14)で取得したジェネレータを用いて、生成されたミニバッチのデータを取得していく。OrderedEnqueuerの利用側は、ここまで来たら、特に何も考えずに、ジェネレータから得られるデータを使っていけばよい
-
- 16)で記述したように、ジェネレータで取得したミニバッチのデータを利用してtrain_on_batchを行う
※2:
正確には今回のルートでは keras.utils.Sequenceクラスを継承しているオブジェクト
コードの説明は以上です。
効率的かと言うと微妙な気がしますが、巧みな実装になっているなあという感想です。
Kerasの自動並列化について
冒頭でGPUでの並列化については多少推測も含むもののどのような実装になっているか述べましたが、GPUは自動で使ってくれる(Kerasの公式ページにもそうあります)のに、マルチコアCPUの場合に、並列化を行ってくれないというのはおかしいと思い、手元にある学習と推論の処理両方を含むプログラム(強化学習であるため、推論処理も同時に行っています)の実行時のCPUの使用率を見てみました。
実行環境は以下の通り
- Windows10 64it
- Python3.7 64bit
- keras 2.3.1
- tensorflow 2.1.0
結果、よく観察すると、6コア(HTで12コア)のプロセッサですが、1プロセスしか起動していないにも関わらず、同じタイミングで全てのコアの使用率が上がっていることが分かりました。
以下はリソースモニタの使用率表示ですが、fitが走るタイミングで全てのプロセッサ(コア)の使用率が上がっています。
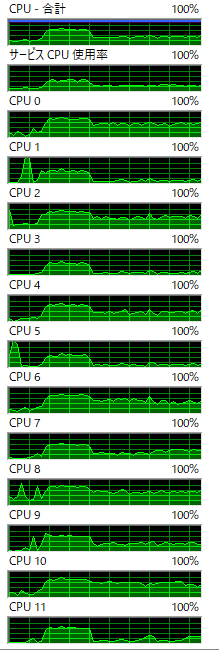
また、タスクマネージャでプロセス内のスレッド数(カーネルスレッド)が表示されますが、当該プロセスは37スレッドを常時動作させており、さすがに多いのではないかと考えています。(python単体をreplのモードで起動すると4スレッドしか立ち上がりません)。なお、I/Oは起動時と、定期的にモデルのダンプをするぐらいで、常時複数ファイルへのI/Oが走っているといったことはありません。
以上のことから、Kerasを用いている場合、マルチコアCPUでも自動並列化が行われていると考えています。
Pythonの場合、Pythonのスレッドを複数立ち上げてもGILが存在するため、コンピューティングバウンドな処理をスレッド並列化しても、同時には一つしか動作できず、並列化の恩恵を受けることはできません。ただし、ネイティブコードを叩くライブラリの場合、意図的にGILを無視するなり、解放するなりして、スレッドを動作させることで、この制約を回避することは可能なようです。(Numpy・SciPyの例)
というわけで、次はTensorFlowのマルチコア並列化の実装がどのようになっているか、(手を出してみて読めそうであったら)読んでみようと思っています。
(Kerasはネイティブコードを叩くようなレイヤはバックエンドにお任せという設計なので、TensorFlowの方を読む必要があるのだろうと考えています)
余談
・Keras(TensorFlowバックエンド)の自動並列化も良し悪しで、プログラム一般として、並列化すれば必ず速くなるというものでもないので、勝手に並列化されて遅くなるという場合もあります。私がここ数日で経験した例だと、上でも挙げた 学習と推論の処理両方を含むプログラム はGPUをセットアップすることで、学習時間が倍遅くなりました
・一方で、これは困った、と思い、えいやとバッチサイズを64から1024に変えてみると、GPU搭載前より学習速度が6倍高速化しました
・NNのネットワーク規模が並列化においてスケールするかの主たるファクターだと考えていましたが、さして大きくないサイズのモデルでもバッチサイズを大きくすれば、(必ずとは言えないですが)スケールするということが分かりました
・ただし、バッチサイズを大きくした場合、学習率をその分大きくしたとしても、学習を進めた結果のパフォーマンスが、バッチサイズを大きくする前とさほど変わらない水準になるかは、モデル次第だろうと思います
・なお、上で挙げた手元のモデルではうまくいっているようです
- バッチサイズを大きくするとうまくいかなくなる例
・【失敗談】学習処理や推論処理も重いが、学習処理で与えるデータの生成処理も遅いということが分かって、これといって時間のかかる処理はしてないのだけどなあ、と思ってCProfileを使ってパフォーマンスプロファイル(どの関数が時間食ってるか)を採取してみっところ、ハッシュのキーとして用いる目的で何気なく特徴量 + α を文字列化している箇所が2か所ほどあったのですが、そこが時間を食っているということが分かり。既に不要な処理でもあったので取り除いたら、生成処理の時間はほとんどかからなくなりました・・・。高速化を考えるときはとりあえずプロファイルをとってみるというのは大事ですね。(LSTMを導入したりした関係で、fit や predict で渡す1サンプルの特徴量がタイムステップ分増えて64倍のデータ量になっていたのですが、それが思わぬところに影響を及ぼしていました・・・)
謝辞
・いつも有益なアドバイスを頂いているkaggler-ja Slackの皆様に感謝いたします
・いつも有益なアドバイスを頂いている takashyx氏 に感謝します
・いつも有益なアドバイスを頂いている argmax氏 に感謝します
・趣味プログラミングで行っている内容にも関わらず、勤務時間内での自己学習・研究の時間において、本調査等、機械学習関連の調査・学習・実装を許可していただいているオリィ研究所(勤務先)に感謝します
以上です!
20/03/9 8:00 追記:
GPUをdisableにした上で、バッチサイズを1024にして動作させたところ、GPUほどではないののの、学習処理が高速化されました。4倍弱程度。これだけ見ると、GPUを使った方が良いように思われますが、今取り組んでいるプログラムは深層強化学習であるため、replay時のミニバッチに相当するデータをためて、1イテレーションで一回だけfitを呼ぶという形にして、fitのオーバヘッドを減らしたとしても、1イテレーションで1サンプルだけ与える形でのpredictを数万回呼ばねばならず、その場合の実行時間はGPUを用いない方が速いようです。従って、あくまで私が取り組んでいるタスクで設計したNN構成においてでですが、学習処理+推論処理のトータル時間で見ると、CPUだけで実行した方が速い、という結果になっている感じがしており(厳密に時間を計測したわけではありません)、折角アクセラレータとして利用できるようにNVIDIA系のグラボに買い替えたのですが、GPUは今いじってるプログラムの学習・推論においては利用せず、CPUだけでやることにしました・・・・