どうも、ryo_gridです。
おはこんばんちわ。
DQNで深層強化学習させたエージェント(まともなパフォーマンスを発揮する)を用いて、FX自動トレード(のシミュレーション)をするということにトライしています。
このテーマに関しては4記事目となりました。
深層強化学習でのFX自動トレード(のシミュレーション)がうまくいかないのでオレオレ手法を考えた - Qiita
【続】深層強化学習でのFX自動トレード(のシミュレーション)がうまくいかないのでオレオレ手法を考えた - Qiita
【成功】深層強化学習でのFX自動トレード(のシミュレーション)がうまくいかないのでオレオレ手法を考えた - Qiita
前回の記事で、学習データにおいてはまとも(と私は認識している)なパフォーマンスを出すモデルが作れたのですが、このテーマに取り組むにあたってサーベイした論文では、扱っている対象が時系列データであるということもあり、入力データ(environment が 返す state)を、(これについては詳細の記述が無かったのでNNの設計や実装は不明ですが)畳み込みしている (convolution) ものや、LSTM をNNに組み込んだりしているものがありました(どの論文も何かしら時系列データであることを意識した設計にはなっていたように記憶しています)。
そこで、前回の記事での実装の汎化性能を上げるのではなく、その実装にLSTMを導入して、それをメイン版と据えて、汎化性能を上げるといったことをやっていこうと考えました。
(なお、前回の実装で学習期間を3年にしたところ、その後5年間のパフォーマンスは若干の減少は見られたものの、ほぼ初期資産を維持、といった結果でした。半年のデータで学習させたモデルで7年半を戦わせるというのをやはり無茶があったようです)
で、いきなりですが、ソースコードは以下です。
- ソースコード
- リポジトリ(の作業ブランチ): github
- ソースファイル: agent, environment
- ※environmentのコードで、各特徴量を求めるメソッドの中でリストをreverseしている場合がありますが、それはバグでした。
LSTM自体をNNに加えて(正しく)動かすというだけでも大分苦労したのですが(※)、ちゃんと学習しているであろう結果が得られるものができたので、整理の意味も込めて、記事化しました。
前回の記事での実装と大きく異なる点および、特殊な実装になってるかも?という点は以下です。
- (当たり前かもしれませんが)environment が、ある時点でのエピソードを扱っている場合、その時点と過去の時点のものを含めて、LSTM導入前で言う32時点(今、利用しているパラメータであって、変更の可能性は十分あり)のstate (特徴量ベクトル) を2次元リストで返す
- 学習開始時に学習データの要素数(= 足の数)x アクション数(BUY, CLOSE, DONOT の3つ)の2次元リストを確保し、そこに、全イテレーションを通しての平均rewardを保持するようにした
- 最初は 0.0 ばかりだが(CLOSEのrewaardは -100固定なので、そこは最初から埋まっている)、学習を進めていくとだんだんと値が埋まっていき、各値もある時点であるアクションをとった場合の期待獲得pipsに収束していくはず
- 前回の記事の※のところに書いたところは、stateとactionを文字列化して結合したものをキーとしてハッシュで管理していたが、それがリストの形になっただけ
- リストにすることで時系列である区間のデータをとる、ということが可能になる。またある時点での、全ての actionについて、個々の平均rewardをとることが可能になる
- replayを行う際は、memory内のエピソード情報内に記録されている agent が選択した action についてだけではなく、他の2つの action についても教師シグナルを与える(一つ上のポチのリストが存在するので、このようなことが可能となる)。これによって学習の進行速度を上げたいという目論見
-
(意味があるのか正直なところ自信がないが)、fitする際に与えるサンプル(8サンプルのミニバッチにはしているが)の対応する時間(足)が1つのイテレーションを通して1ずつずれるようにするため、ミニバッチ数分のエピソード(今の実装では8)が経過するまでは、replayを行わない
※: インターネッツを探しても、(少なくともKerasベースでは) 単純なスカラ値を一時点の特徴量とする時系列データ入力から、その先の1時点やN時点のスカラ値を予測するという例ばかりで、複数要素からな成る特徴量ベクトルを時系列で並べたリストを入力とし、複数要素のスカラ値から成る出力を1つ得る、という例は見つからず(英語圏のページも探しましたが、ただ見落とした、検索キーワードが悪かった、という可能性はもちろんあります)、LSTMの理解が浅いこともあり(今は最初よりは大分詳しくなったとは思いますが)、トライアンドエラーを何度も繰り返すはめになりました
NNの構成は以下の通りです
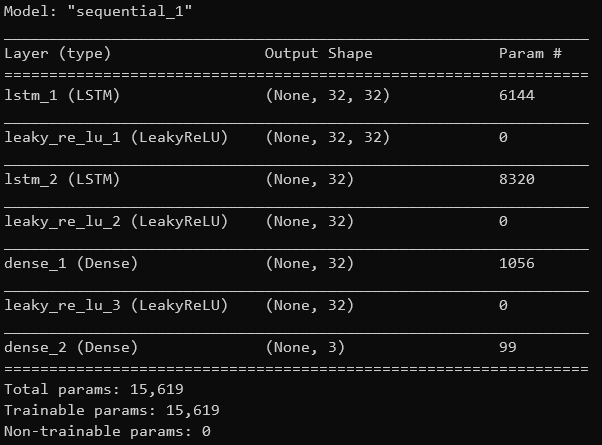
Activation関数がReLUから、LeakyReLUに変わっているのはサーベイした論文のうち、LSTMを用いたと書いてあったものに、LeakeyReLUを採用したと書いてあったためです。
・参考にした論文
"Deep Reinforcement Learning for Trading,", Zihao Zhang & Stefan Zohren & Stephen Roberts, 2019. Papers 1911.10107, arXiv.org.
また、LSTMを入れて試していたら出力やlossがnanになってしまうということが起きて、何故だろうかと悩んでいた時に、weight decay(重み減衰)や勾配クリッピングを行わないと、再帰構造を持つネットワークは簡単に勾配や重みが発散してしまうよ、というアドバイスを有識者である知人にいただき、オプティマイザ(Adam)には、勾配クリッピングのためにclipvalue=5.0 というキーワードパラメータを与えています(キーワードと参考ページを教えていただきましたが、設定したパラメータは私が適当に決めた値です)。アドバイスを頂いた知人の方に感謝します。
(weight decay も最初は入れましたが、それがNNに及ぼす効果がいまいち予測がつかなかったのと、勾配クリッピングでひとまず nan になることは回避できたので、今は取り除いています)
ハイパーパラメータ等は現状、以下です。
- 学習率: 0.0001
- NNの各レイヤのユニット数: 32
- 予測において考慮する時系列の長さ: 32
- ミニバッチのサイズ: 8
- 学習データのサイズ: 約36000足 (5分足で、およそ半年。取引不可な時間帯のデータは含まない)
- 保持可能なポジション数(通貨の塊): 30 (前回の記事では100になっていました)
- NN構造: 参考にした論文では64ユニットと32ユニットのLSTMレイヤで2層とあったが、この記事での実装では、ユニット数はどちらも32とし、32ユニットのDenseを一つ加えています
なお、この実装では、学習データにおいても、単調増加に近い、(私の考える)理想的なパフォーマンスは確認されていないのでご注意下さい。現在、絶賛、学習処理実行中です。
(テストデータで単調増加が難しいのは当然承知しています)
以上です!
20/06/05追記:
上記とはいくらか実装もパラメータも変わっていますが、LSTM導入版での学習データにおけるバックテストで、非LSTM利用版よりも良い感じのパフォーマンス(推移の仕方的に)が確認されていたので載せておきます。
-
ソースコード
-
リポジトリ(のスナップショット): github
-
ソースファイル: agent, environment
-
※environmentのコードで、各特徴量を求めるメソッドの中でリストをreverseしている場合がありますが、それはバグでした。以下の結果は、そのバグが存在している状態での結果です。
-
データ: 学習期間は5分足で半年、以下のバックテストを行った期間も同じ期間
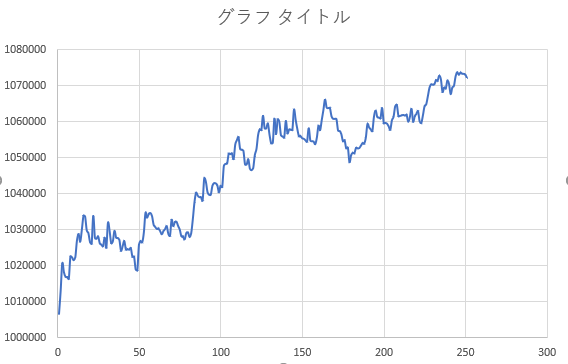
なお、現在の実装はここからも大きく変化しています。
それについては近々、記事にする予定です。