どうも、ryo_gridです。
おはこんばんちわ。
DQNで深層強化学習させたエージェント(まともなパフォーマンスを発揮する)を用いて、FX自動トレード(のシミュレーション)をするということにトライしています。
このテーマに関しては3記事目となりました。
深層強化学習でのFX自動トレード(のシミュレーション)がうまくいかないのでオレオレ手法を考えた - Qiita
【続】深層強化学習でのFX自動トレード(のシミュレーション)がうまくいかないのでオレオレ手法を考えた - Qiita
2本目の記事の方法では、掲載した結果の通りうまくいかず、同じ方向性で、stateへの過去のアクションの情報のエンコード方法を変えたり (与えるエピソード数だけ入力を増やして 0,1,2 とアクションに対応する値を渡したり、1エピソードごとに3入力用意して、選択したアクションに対する入力だけ1にして、他は0にする、といったことをしてみたり) してみましたが、うまくいかず、一本目の記事の実装で採用していた、stateは現在時点までの為替情報から求まる情報のみで、同じ足では常に同じ (学習データを一回先頭から終わりまで舐めて学習するのを1イテレーションと呼び、その各イテレーションで同じ、という意味) という stateの与え方に回帰して、そこをベースに修正を加えたところ、学習データでは、期待したパフォーマンスを得られるモデルをひとまず作ることができました。
本記事ではその、追加の修正の部分(追記部分まで含む1本目の記事、との差分)+ 省略するとあまりに読みにくくなる部分、について記述したいと思います。
それ以外については上記のリンク先2つをご参照下さい。
実装について
-
学習処理全体について
- 学習データでまともに動くことを確認するのが先決なので、テストデータの量は減らし3年分(5分足)から、半年(5分足) にしている
- 学習が進むにつれランダムなaction選択が減っていくグリーディー法を用いているが、変更前の実装だと、最適な行動が大半になる状態には、かなりのイテレーションが回らないと至らないようになっていたが、そもそも、どの程度のイテレーションが必要なのか良くわかっていない上に、変更前の実装でイテレーション数を減らすと序盤でのランダムな選択の確率が減って学習が進みにくくなるように見えたため、折衷案として、2イテレーションおきに、最適行動のみをとるイテレーションを挟むという、なんちゃってグリーディー法に変更した(最適行動のみをとるイテレーション以外は全てランダムというわけではなく、これまで同様、徐々にランダム選択の確率が減っていく計算式をそのまま用いている)
-
Q関数の基本的な考え方であるマルコフ連鎖の考え方に基づき、時系列的に後に続くstateも考慮した上で報酬の最大化を図るという、Q関数(を表現するNN)の更新式(ベルマン方程式から導かれるもの)を用いず、replay におけるNNの重みの更新では、action をとったあとに遷移した state における reward は見ず、ただ、replay で選択されたエピソードで得られたrewardをそのまま教師信号として与える。従って、この記事で説明している実装は、なんちゃってQ学習、なんちゃってDQNと呼ぶのが適切と思われる
- 理由は過去の記事でも簡単に書いているのですが、改めて書くと、今回のプログラムでは、学習過程で学習データを時系列になめていきますが、stateの遷移先 が agent のアクションによって変化しないために、state の遷移は常に変わらず一本道になります(何回なめても、毎回同じ)。ここで、Q関数の一般的な更新式の直感的な意味を考えると、未来の state と そこで得られた reward に基づき、ある未来において得られるであろう報酬の期待値が、ある時点(state および action)を起点にとらえた場合、そこに一定割合加算されるということで、それを agent が トライアンドエラーによって繰り返すことで各stateでのactionの報酬が適切な値に変化していく、というものです。ただし、それはとったactionによって未来が変わる場合の話で、未来が agentのとったactionに関係なく、一本道となってしまう場合、更新式の想定から外れてしまうので、Q関数の出力は適切な reward に更新されて行かないだろう、と考えたためです
-
state
-
現在価格、前の足からの変化率(符号あり)、各種テクニカル指標
-
action
- タスクをできるだけ単純にするため、ポジションはロングのみ扱うようにしている
- BUY
- BUYのアクションをした場合、設定した分割数(保有可能な取引通貨の塊の数。以降読みにくいので一つの塊のことをポジションと呼称する)で、ポジションの状態になっているものも含めた総資産を分割した額の分、ロングポジションを購入する(厳密には記述されたような値にはならないが、それに近い額になるようにはしてある)。今回の実装では分割数は100
- 保有しているBUYポジション(≒ロングポジション)の数が規定数(本時期の実装では100)を超えると、BUYのアクションをとっても購入は行われない
- 学習を進めていった結果、設定した塊を保有したままずっとHOLDするという挙動が発生したため、Q学習の手法とは本来相いれない手段ではあるが、BUYアクションをとり、BUYポジションが100個に到達した場合は、次のactionで必ずCLOSEするよう environment がagent に通知を返す
- DONOT
- 何もしない
- ただし、BUYと条件を揃えないと、学習していった結果、DONOTばかりが発生する、つまりDONOTのrewardばかりが大きくなるということが起きていたため、BUYをしないということは、売りをするのと同じようなものであると見なして、environment側では仮想的なショートポジション(以降、DONOTポジションと呼称)を購入したものとして扱う
- BUYの場合と同様に、DONOTポジションが100個に到達した場合は、次のactionで必ずCLOSEするよう environment が agent に通知を返す
- 仮想的なポジションであるため、資産額や総獲得価格差分の算出には影響を与えない
- CLOSE
- 全てのポジションを決済する
- 詳細は reward の説明のところで記述する
-
reward
- BUY
- 0が与えられるが、続くエピソードでCLOSEが発生した際に値が更新される
- DONOT
- 0が与えられるが、続くエピソードでCLOSEが発生した際に値が更新される
- CLOSE
- -100を必ず与える。本記事での実装では、NNの重み更新時の教師シグナルは、replayで選択された episode における rewardのみであり、次に遷移する先の state からのrewardが加算されることがないため、-100から変化しない。-100を与える意味は、基本的にはBUYかDONOTの2択にして、CLOSEされていないポジション数が保有可能数の上限(DONOTポジションも、BUYのアクションをとった際のロングポジションと同様の上限を設ける。本記事での実装では100個)に達したらCLOSEするという振る舞いにして、rewardの多寡で選択されるか競うアクション種別を同じ条件(後述)で求めているBUYとDONOTに限定するため
- CLOSEアクションは保有ポジション全てを決済し、その際に保有していたポジション個別での獲得pipsを求めて(DONOTポジションはショートポジションと見なして獲得pipsを算出)、各ポジションの識別子とともに返す(environment側の挙動)
- agent側は、CLOSEアクションをとった場合、返ってきたポジション個別の獲得pipsで、memory に記録してある対応するBUY, DONOTアクションのエピソード情報の reward を更新する(※)
- このようにすることで、BUY、DONOTアクションのrewardを後追いで求める。NNの重みの更新はランダムreplayでのみ更新されるので、そのうち変更されたrewardが NNで表現されるQ関数に反映される、という目論見
- このような reward の設計だと、一度CLOSEで全てのポジションが決済された後は、BUYがトータルで100回に達するか、DONOTがトータルで100回に到達するかしないと、CLOSEアクションが起きないことになるが、Q関数が複数イテレーションでの学習を経て、様々なタイミングでCLOSEが行われた場合(最短でアクションをとったエピソードの次のエピソード。最長はBUYとDONOTの、一方が99回、他方が100回を迎えた次のエピソードなので、198エピソード先)のrewardから、各時点におけるBUYとDONOTの平均reward(※)が求まっているとすれば、BUY or DONOTで適切なアクションをとってさえいてくれれば、CLOSEするタイミングは、取引回数が多ければ、このような決め方でも獲得利益は平均的にはプラスになる、と考えた
- BUY
-
ソースコード
-
リポジトリ(の作業ブランチ): github
-
ソースファイル: agent, environment
※:
stateに保有ポジションや過去のアクションの情報を含めない場合、agentがとったactionに関わらず、stateの遷移は一本道になってしまうため、同じテスト期間を何周もさせる場合、同じstateで異なるrewardを得るということが発生する。
その場合、同じstate、遷移先stateというパラメータで、異なるrewardが教師信号の算出に用いられるということが発生するが、それは、(私の理解したと思っている)Q学習の考え方としておかしいのではないかと考えた。
そこで、state に為替データから算出されるもの以外の何か、が含まれない場合、イテレーション(周回)を跨いで、過去に同じ state x action で得た全てのrewardの平均値を求められるようにして、上記のCLOSEアクション時の reward の更新において用いる
学習データとテストデータの期間のUSD/JPYの為替推移(OPENの値)
※今更ですが、本記事での実装においては、ロングポジションの価格ははOPENの値 + 0.0015円、ショートポジションの価格は OPENの値 - 0.0015円です。決済する場合は、両者を逆にした価格です
2001-2008の8年間における推移
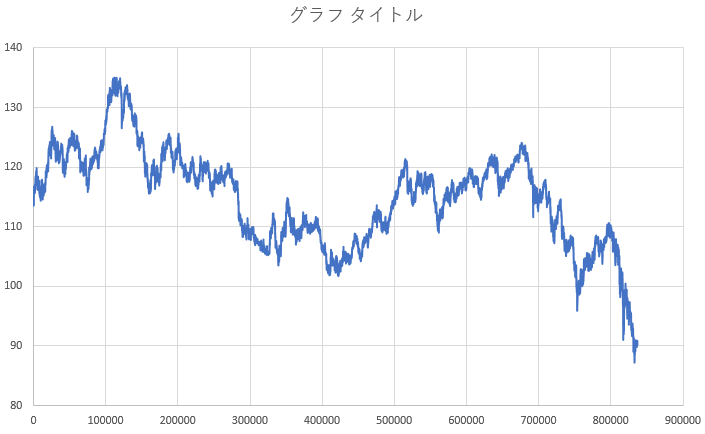
2001年の推移(前期の半年が学習データ)
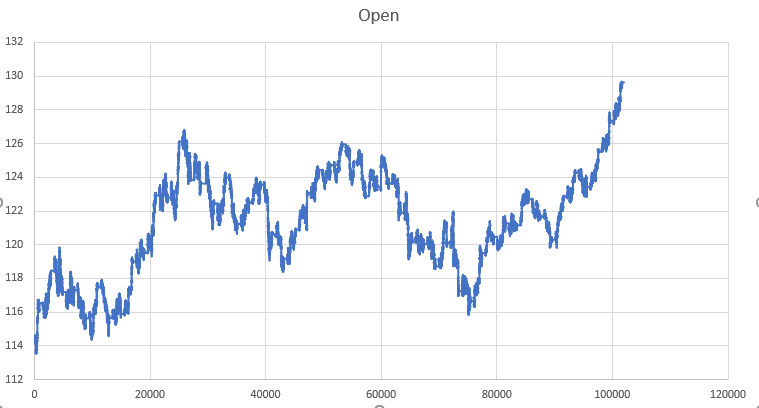
以下の評価において初期資産額は1000000円。決済するごとに手元の資産に利益が入り、その上で次の取引が行われるため、複利で資産は変化します。スプレッドは考慮していますが、利益に対する課税は考慮していません。
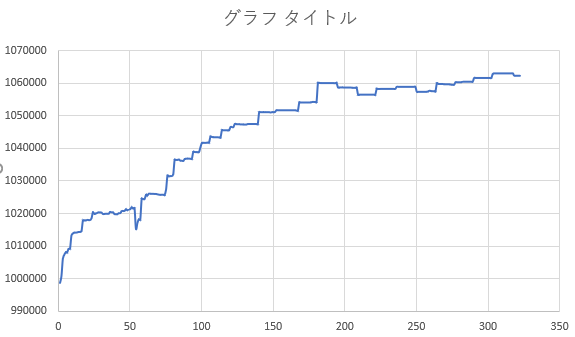
結果(学習データ期間でのバックテスト)
※今更ですが、学習データはUSD/JPYの5分足で2001年の前半半年です
※CLOSEした際のログを抽出してプロットしているため、横軸は正確な時間軸(半年)とはなっていないです。ただ、おおむね整合している思います
56イテレーションの途中
187イテレーションの途中
226イテレーションの途中
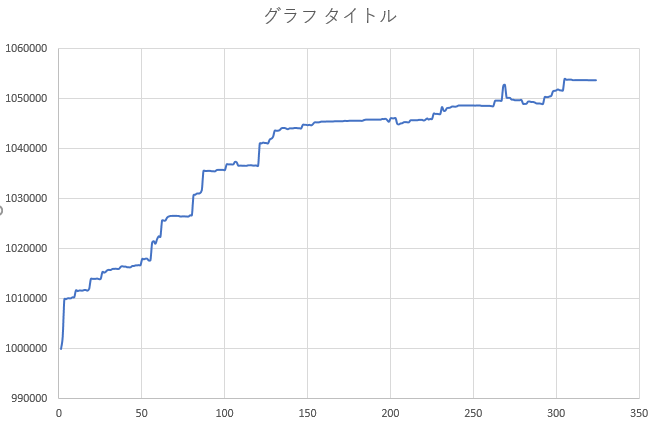
総獲得価格差分 614.736円(1銭を1pipsとすれば、61474 pips を半年で獲得した計算)
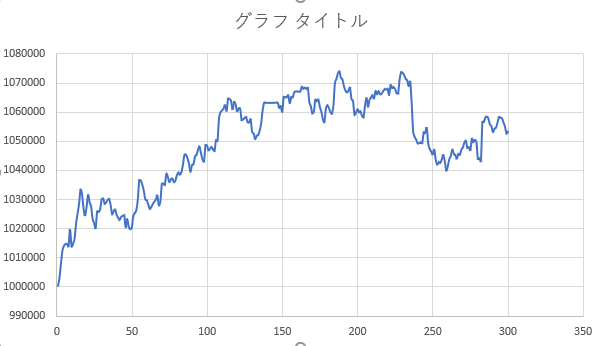
結果(テストデータ期間でのバックテスト)
学習した期間に続く7年間半でのパフォーマンス
※テストデータはUSD/JPYの5分足のデータで、学習データの期間に続く2001年の後半から2008年末までの期間です
※CLOSEした際のログを抽出してプロットしているため、横軸は正確な時間軸(7年半)とはなっていないです。ただ、おおむね整合している思います
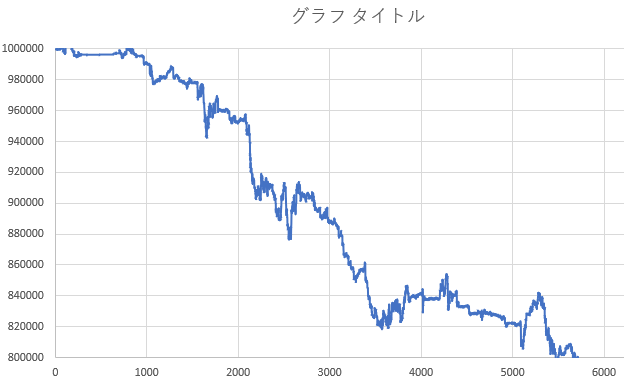
結果の考察
- 学習データについては、226イテレーション途中の結果において、ほぼほぼ単調増加のパフォーマンスとなっており、過去同数程度のイテレーションを回すと特定の action だけが起きるといった学習結果になっていたのに対し、それも起きていなかったため、学習データにおいては、まともなモデル(≒モデルを構築する学習および、そのモデルを用いたアクションの推論を行うプログラム)が書けたと認識しています
- 学習データにおいてまともなパフォーマンスを出すことを最優先にしたため、汎化性能はネットワーク構成においてほとんど考慮していませんし、過学習も起きていると思います。従って、テストデータでパフォーマンスが出ないのは想定の範囲内、という感じです
- テストデータが7年半であるのに対して、学習データの期間が半年というのがそもそも無茶、という話もあると思います
- テストデータでのパフォーマンスはおおむね、ダメダメな感じですが、最初の一年三か月程度だけはどうにか踏ん張っているように見えます。これも想定からは大きく外れてはおりません。というのは、過去に強化学習ではなく、教師あり学習による為替のUP/DOWNの予測結果を参考に、ヒューリスティクスベースのオレオレ取引ロジックで取引をするというシミュレーションを試していましたが、同じ通貨ペアでも、期間が異なると、もっと言えば、学習した期間から離れるとパフォーマンスが出ない傾向が見られていました。その経験からすると、整合する結果だと言えるかと思います
- 参考: FXシステムトレードのプログラムをいくつか作ってみて分かった課題とその解決法について - Qiita
というわけで、続いて、学習データのサイズ(≒期間)を大きくすること(単純に大きくするだけで済めば良いですが、他のパラメータの調整が必要になる可能性もありそうな気がしています)、汎化性能の向上、を行っていきたいと思います!
(あとはLSTMを用いるバージョンも試しているので、パフォーマンスが上がるようであれば取り込みたいと考えています)
以上!